Автор: Денис Аветисян
Исследование демонстрирует, как квантовое обучение с подкреплением может быть использовано для активного контроля потока жидкости, снижая сопротивление и стабилизируя структуру следа.
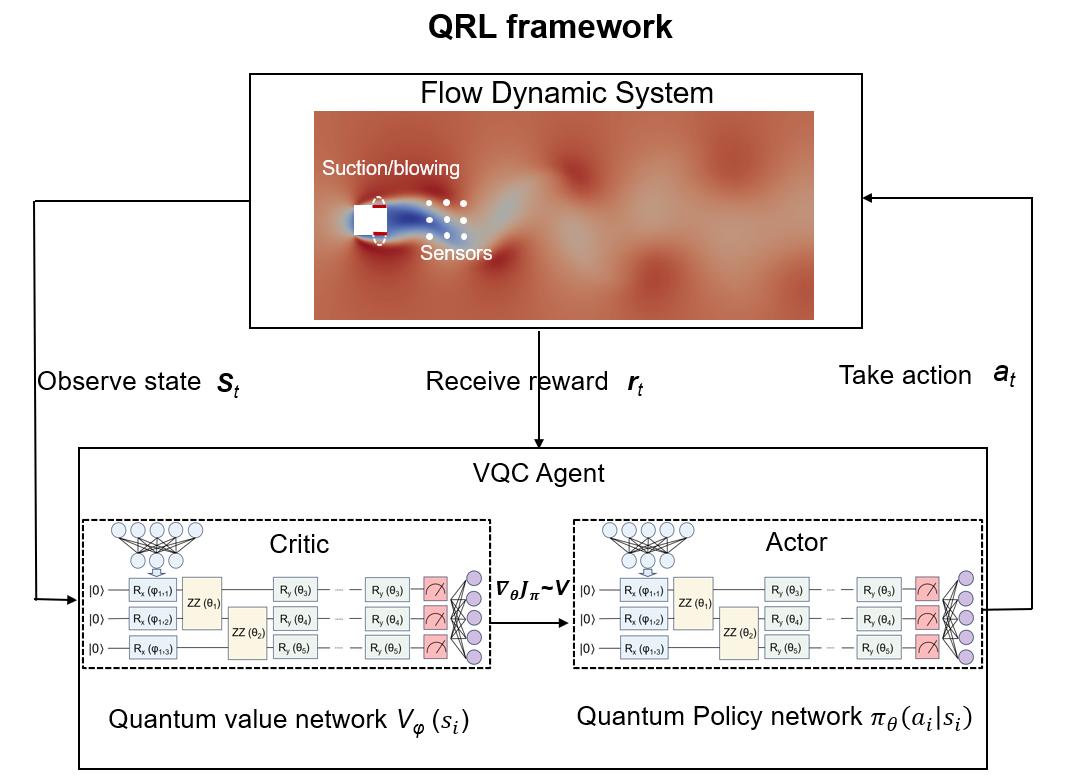
В работе представлен новый алгоритм на основе квантовых вариационных схем и обучения с подкреплением для эффективного управления обтеканием квадратного цилиндра.
Активное управление потоком остается сложной задачей из-за нелинейности и высокой размерности задач гидродинамики. В данной работе, посвященной ‘Quantum reinforcement learning-based active flow control’, предложен новый подход, основанный на квантовом обучении с подкреплением, сочетающий вариационные квантовые схемы с алгоритмом проксимальной политики оптимизации. Показано, что разработанная схема эффективно контролирует обтекание квадратного цилиндра при числе Рейнольдса 100, снижая сопротивление и стабилизируя следовую область. Может ли интеграция квантовых вычислений открыть новые горизонты в решении сложных задач гидродинамики и оптимизации аэродинамических характеристик?
Вихревые тени: Предвидение нестабильности в потоке
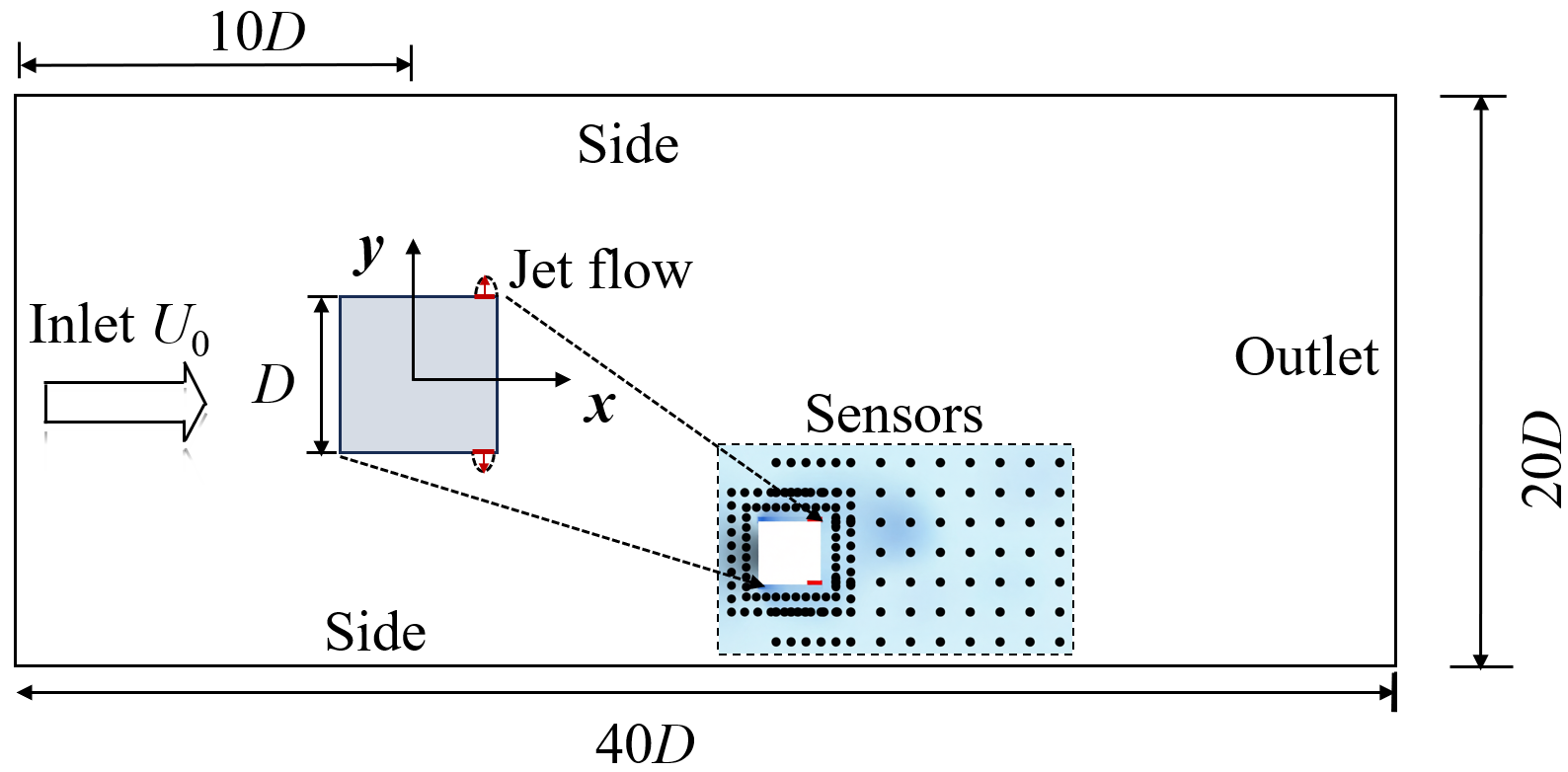
Неустойчивый поток вокруг тел неправильной формы, таких как квадратный цилиндр, приводит к образованию улиц фон Кармана — периодически сбрасываемых вихрей, расположенных позади объекта. Это явление, известное как сброс вихрей, вызывает значительные потери энергии в инженерных системах и, что особенно важно, может приводить к структурной усталости материалов из-за циклических нагрузок. Постоянное воздействие этих вихрей создает колебания и напряжения, которые постепенно ослабляют конструкцию, что требует разработки специальных методов для смягчения или предотвращения этого разрушительного процесса. Изучение динамики этих вихревых улиц имеет решающее значение для повышения надежности и долговечности различных инженерных сооружений, от мостов и зданий до аэрокосмических конструкций и подводных аппаратов.
Традиционные методы борьбы с отрывом потока, основанные на решении уравнений Навье-Стокса \nabla \cdot \mathbf{T} + \mathbf{f} = 0 , часто оказываются недостаточно точными и гибкими в сложных сценариях. Хотя эти уравнения и описывают фундаментальные принципы движения жидкости, их применение к реальным инженерным задачам, особенно связанным с обтеканием тел сложной формы, сопряжено с трудностями. Причина кроется в высокой чувствительности решения к начальным и граничным условиям, а также в сложности моделирования турбулентных режимов потока. Это приводит к тому, что разработанные на их основе стратегии подавления отрыва, например, использование обтекателей или изменение геометрии тела, часто демонстрируют ограниченную эффективность в условиях изменяющихся параметров потока или при наличии нелинейных эффектов. В результате возникает потребность в более адаптивных и точных методах управления потоком, способных учитывать динамические особенности обтекания и обеспечивать надежную защиту конструкций от негативного воздействия отрыва.
Эффективное активное управление потоком требует глубокого понимания и манипулирования сложными гидродинамическими процессами, что представляет собой значительные вычислительные и инженерные трудности. Для точного контроля над потоком необходимо учитывать нелинейность уравнений Навье-Стокса и турбулентность, что требует разработки передовых численных методов и алгоритмов. Особенно сложной задачей является прогнозирование и подавление срыва потока и формирования вихревых улиц, поскольку эти явления чувствительны к малейшим изменениям в геометрии обтекаемого тела и параметрах потока. Разработка систем активного управления, способных оперативно адаптироваться к меняющимся условиям и обеспечивать стабильный контроль над потоком, требует интеграции сложных математических моделей, передовых датчиков и алгоритмов управления в реальном времени, что представляет собой междисциплинарную задачу, требующую совместных усилий специалистов в области гидродинамики, вычислительной математики и автоматического управления.
Классический контроль и вычислительное моделирование потока
Для активного управления потоком применялись различные методы управления, включая ПИД-регуляторы, итеративно линеаризованные модели и прогнозирующее управление на основе моделей (Model Predictive Control). Эффективность каждого из этих подходов варьируется в зависимости от конкретной задачи и характеристик обтекаемого тела. ПИД-регуляторы, благодаря своей простоте, часто используются для стабилизации потока, однако их производительность ограничена при управлении сложными нелинейными системами. Итеративно линеаризованные модели позволяют учитывать нелинейности, но требуют периодической реидентификации модели. Прогнозирующее управление на основе моделей обеспечивает оптимальное управление, но требует значительных вычислительных ресурсов и точной модели динамики потока.
Вычислительная гидродинамика (CFD) является эффективным инструментом для моделирования и анализа поведения потока вокруг квадратного цилиндра. Программные пакеты, такие как OpenFOAM, позволяют решать уравнения Навье-Стокса и другие уравнения, описывающие движение жидкости, с высокой точностью. CFD позволяет визуализировать сложные явления, такие как отрыв потока, образование вихрей и распределение давления, что критически важно для понимания аэродинамических характеристик и разработки стратегий активного управления потоком. Использование CFD позволяет проводить параметрические исследования и оптимизировать конструктивные особенности цилиндра без необходимости проведения дорогостоящих и трудоемких физических экспериментов.
Метод Собственных Ортогональных Разложений (POD), также известный как анализ главных компонент (PCA) в приложении к данным, используется для снижения вычислительной сложности моделирования потока вокруг квадратного цилиндра. POD позволяет выделить доминирующие моды потока, представляющие собой наиболее энергетически значимые структуры. Вместо решения полной системы уравнений Навье-Стокса, POD-модель оперирует с существенно меньшим числом модов, что значительно снижает требования к вычислительным ресурсам и времени. Это, в свою очередь, позволяет реализовать системы активного управления потоком в режиме реального времени, поскольку время вычислений становится приемлемым для обратной связи и корректировки параметров управления.
Машинное обучение для адаптивного управления потоком
Обучение с подкреплением (Reinforcement Learning) представляет собой итеративный процесс, в котором агент взаимодействует со средой, принимая решения, направленные на максимизацию кумулятивной награды. В контексте управления потоками, агент, используя алгоритмы обучения с подкреплением, последовательно изменяет параметры системы управления потоком (например, частоту и амплитуду колебаний исполнительных механизмов) и оценивает полученный результат, представленный в виде числовой награды, отражающей желаемые характеристики потока (снижение сопротивления, увеличение подъемной силы и т.д.). Процесс обучения заключается в корректировке стратегии управления на основе полученной обратной связи, позволяя агенту постепенно находить оптимальные параметры управления для различных условий потока путем последовательных проб и ошибок. Алгоритмы, такие как Q-learning и SARSA, используются для аппроксимации оптимальной стратегии управления, позволяя агенту адаптироваться к изменяющимся условиям и оптимизировать характеристики потока без явного программирования.
Глубокое обучение с подкреплением (Deep Reinforcement Learning, DRL) объединяет алгоритмы обучения с подкреплением с глубокими нейронными сетями для решения задач управления в пространствах состояний высокой размерности. В отличие от традиционных методов обучения с подкреплением, которые испытывают трудности с обобщением в сложных средах, DRL использует глубокие нейронные сети в качестве функционеров приближения для оценки функций ценности или политик. Это позволяет агенту учиться сложным стратегиям управления, обрабатывая входные данные, представленные в виде векторов высокой размерности, например, данные, полученные от большого количества датчиков или результатов численного моделирования. Такой подход особенно эффективен в задачах, где прямое представление политики или функции ценности непрактично или невозможно из-за сложности пространства состояний.
Применение методов обучения с подкреплением и глубокого обучения с подкреплением в системах активного управления потоком позволяет создавать адаптивные системы, способные реагировать на изменяющиеся условия потока и оптимизировать производительность. Такие системы, в отличие от традиционных, основанных на заранее заданных параметрах, способны в реальном времени корректировать параметры управления (например, частоту и амплитуду воздействия) на основе анализа текущего состояния потока. Это обеспечивает повышение эффективности работы оборудования, снижение энергопотребления и улучшение аэродинамических характеристик, особенно в условиях нестационарных и турбулентных потоков. Оптимизация может быть направлена на различные цели, включая снижение сопротивления, увеличение подъемной силы, уменьшение шума и вибрации.
Квантовое машинное обучение для расширенного контроля
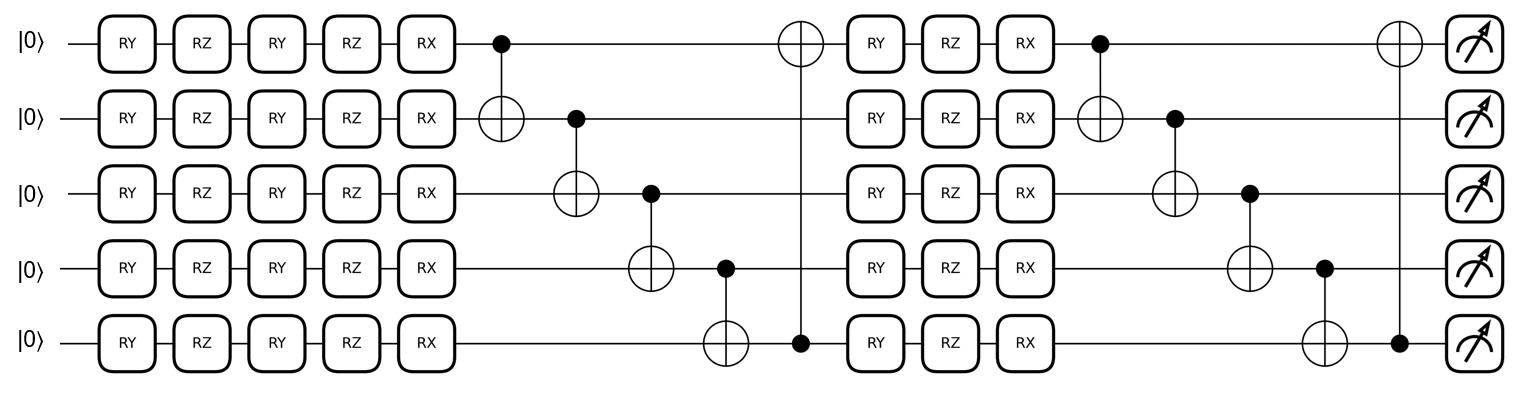
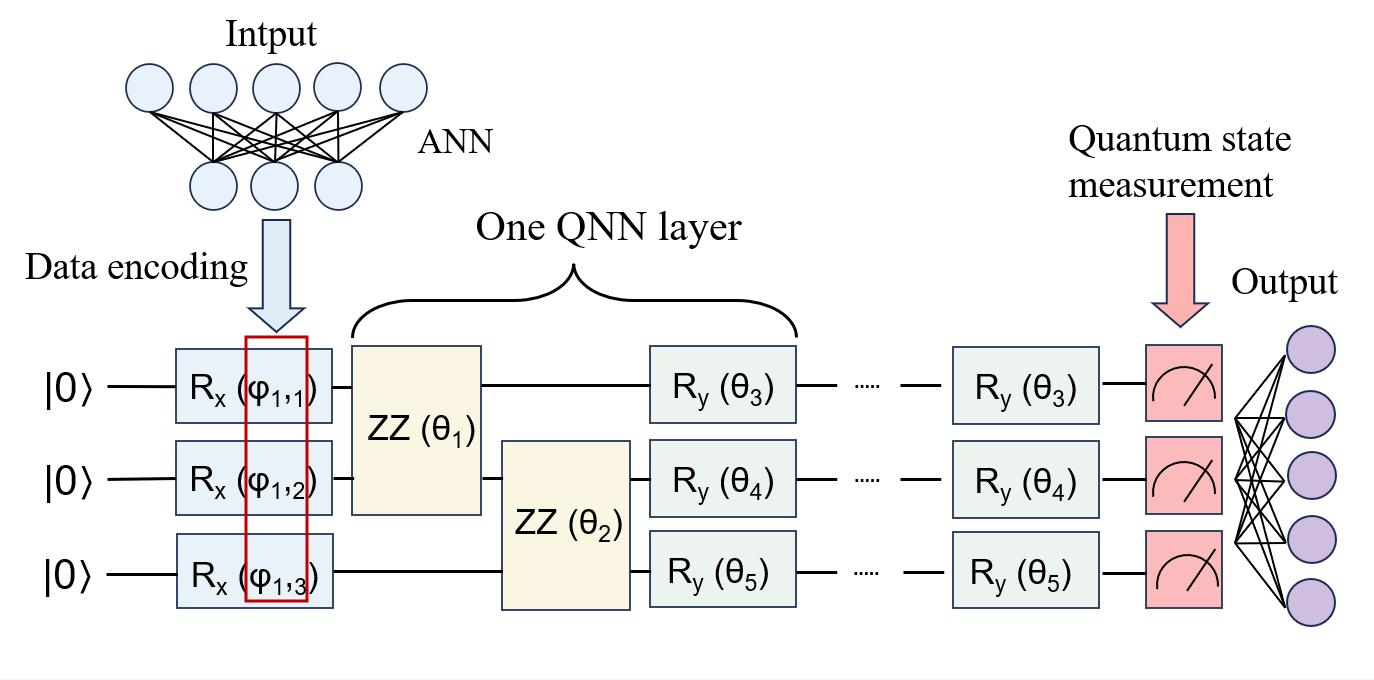
Квантовые нейронные сети и вариационные квантовые схемы представляют собой перспективные инструменты для ускорения и расширения возможностей машинного обучения. В отличие от классических нейронных сетей, использующих биты для представления информации, квантовые сети оперируют кубитами, что позволяет им одновременно обрабатывать значительно большее количество состояний благодаря принципам суперпозиции и запутанности. Это открывает потенциал для экспоненциального ускорения определенных алгоритмов машинного обучения, особенно в задачах, требующих обработки больших объемов данных или решения сложных оптимизационных проблем. Вариационные квантовые схемы, в частности, позволяют эффективно использовать возможности квантовых компьютеров, комбинируя квантовые вычисления с классической оптимизацией, что делает их применимыми даже на относительно небольших квантовых устройствах. Такой подход позволяет решать задачи, недоступные для классических алгоритмов, и достигать более высокой точности и эффективности.
Принципы обучения с подкреплением, успешно применяемые в классических вычислительных системах, находят свое продолжение в квантовой области, открывая перспективы для создания более эффективных и устойчивых систем управления. Квантовое обучение с подкреплением позволяет агенту взаимодействовать с окружающей средой, используя квантовые состояния и операции для принятия решений и максимизации вознаграждения. Этот подход потенциально позволяет решать сложные задачи управления, требующие обработки больших объемов информации и адаптации к динамически меняющимся условиям, с использованием значительно меньшего количества параметров по сравнению с классическими алгоритмами. Использование квантовых эффектов, таких как суперпозиция и запутанность, может привести к более быстрому обучению и созданию более надежных стратегий управления, особенно в задачах, где классические методы оказываются неэффективными или требуют чрезмерных вычислительных ресурсов.
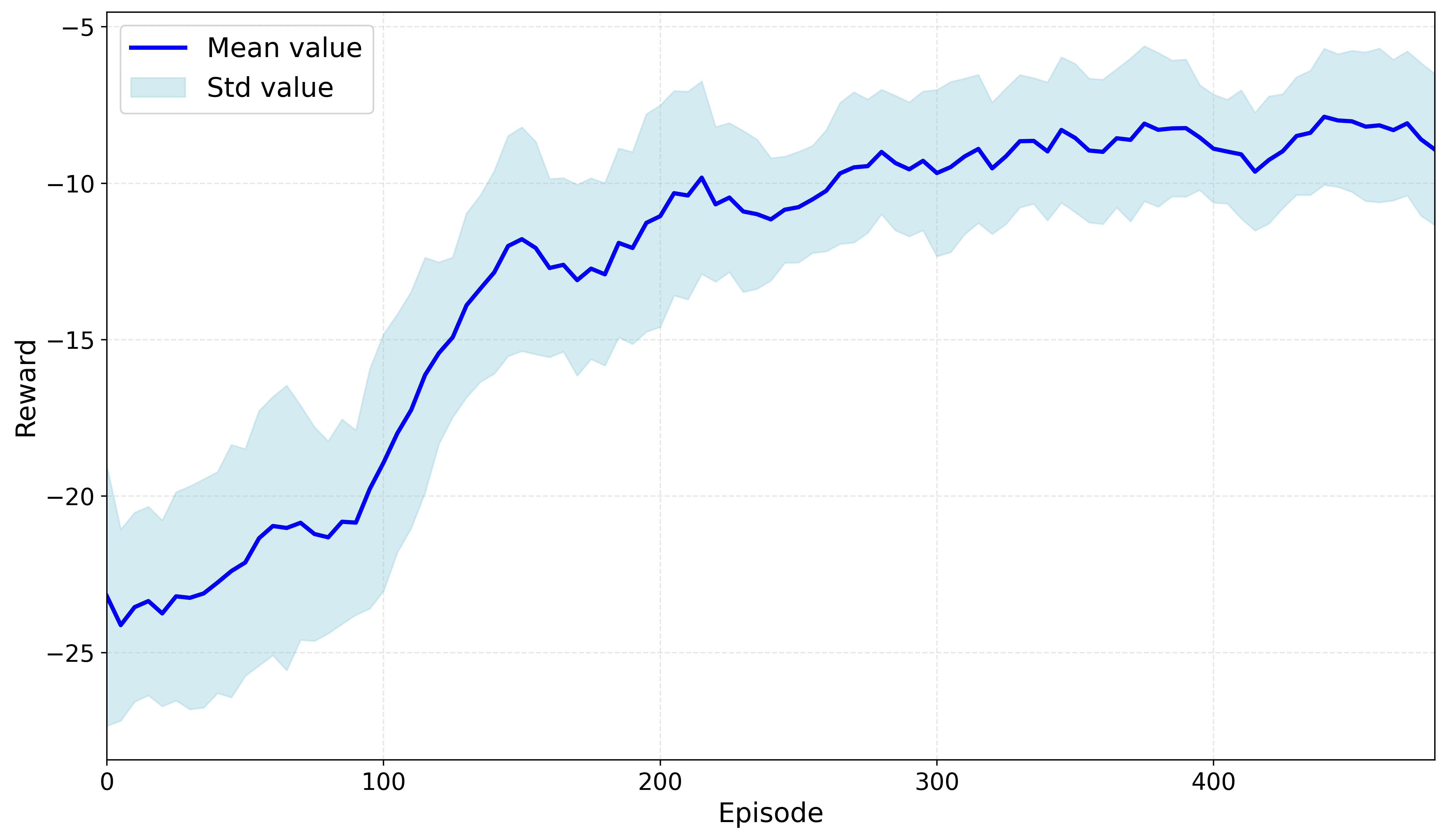
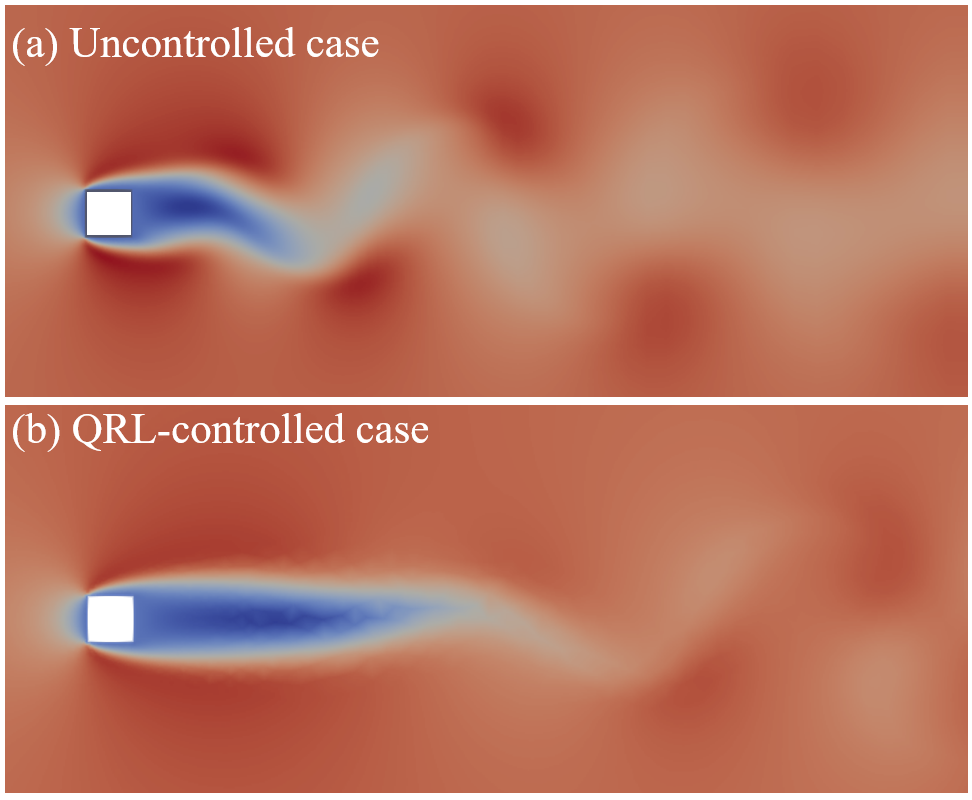
В представленной работе демонстрируется новая структура квантового обучения с подкреплением (QRL), позволяющая добиться значительного снижения среднего коэффициента сопротивления до 1.41, в то время как неконтролируемый случай характеризуется значением 1.55. Примечательно, что данный QRL-агент функционирует всего с 763 параметрами, что обеспечивает снижение их числа на 91.7% по сравнению с классическим агентом обучения с подкреплением, требующим 9,155 параметров. Такое существенное уменьшение количества параметров указывает на потенциальную возможность создания более эффективных и компактных систем управления, использующих квантовые вычисления для оптимизации аэродинамических характеристик и других сложных процессов.
Метод сдвига параметров представляет собой ключевой инструмент для оптимизации квантовых схем, позволяющий эффективно вычислять градиенты, необходимые для обучения алгоритмов квантового управления. В отличие от классических методов, требующих вычисления производных для каждого параметра, данный подход использует лишь два вычисления квантовой схемы — одно с небольшим положительным смещением параметров, и другое с отрицательным смещением. Разница между результатами этих вычислений позволяет оценить градиент без необходимости явного вычисления производных, значительно упрощая процесс оптимизации и делая его более масштабируемым для сложных квантовых систем. \frac{\partial C}{\partial \theta} \approx \frac{1}{2} (C(\theta + \pi/2) - C(\theta - \pi/2)) Такая эффективность особенно важна при разработке алгоритмов квантового обучения с подкреплением, где оптимизация параметров квантовой схемы играет центральную роль в достижении желаемого поведения системы.
Будущие направления и квантово-улучшенное управление потоком
Сочетание вычислительной гидродинамики и квантового обучения с подкреплением открывает перспективные пути к созданию действительно интеллектуальных и адаптивных систем управления потоком. Традиционные методы часто сталкиваются с ограничениями при моделировании сложных турбулентных течений и требуют огромных вычислительных ресурсов. В отличие от них, квантовые алгоритмы, благодаря принципам суперпозиции и запутанности, потенциально способны экспоненциально ускорить процесс обучения и оптимизации стратегий управления. Такой симбиоз позволяет системе не просто реагировать на изменения в потоке, но и предвидеть их, адаптируя параметры управления в режиме реального времени для достижения максимальной эффективности и стабильности. Перспективные исследования в этой области могут привести к революционным улучшениям в аэродинамике, энергетике и других областях, где точное управление потоками играет ключевую роль.
Несмотря на многообещающие результаты, дальнейшие исследования необходимы для всесторонней оценки практических ограничений и потенциальных преимуществ применения квантовых алгоритмов в реальных инженерных задачах. Особое внимание следует уделить масштабируемости этих алгоритмов для решения сложных задач управления потоком, а также их устойчивости к шумам и ошибкам, характерным для квантовых вычислений. Ключевым направлением является разработка гибридных квантово-классических подходов, позволяющих эффективно использовать сильные стороны обеих парадигм вычислений и смягчить недостатки каждой из них. Исследование возможностей адаптации квантовых алгоритмов к различным вычислительным платформам и аппаратным ограничениям также имеет первостепенное значение для реализации их практического потенциала в таких областях, как аэрокосмическая техника и энергетика.
В ходе реализации предложенной структуры квантового обучения с подкреплением (QRL) было продемонстрировано значительное снижение амплитуды коэффициента подъёмной силы — до 0.12, в то время как в неконтролируемом случае данный показатель составлял 0.3. Такое существенное уменьшение свидетельствует о высокой эффективности предложенного подхода в управлении потоком и стабилизации аэродинамических характеристик. Полученные результаты подтверждают потенциал QRL для достижения более точного и эффективного контроля, открывая возможности для оптимизации производительности в различных инженерных областях, где критически важна аэродинамическая эффективность.
Сочетание передовых методов вычислительной гидродинамики и квантового обучения с подкреплением открывает принципиально новые возможности для повышения эффективности и производительности в широком спектре инженерных областей. От аэрокосмической промышленности, где оптимизация обтекания крыла может значительно снизить расход топлива и повысить маневренность, до энергетического сектора, где точное управление потоками жидкости и газа необходимо для повышения эффективности турбин и теплообменников, — потенциал этой синергии огромен. Ожидается, что применение квантовых алгоритмов позволит решать задачи оптимизации, которые ранее были недоступны для классических вычислительных методов, что приведет к созданию систем управления, способных адаптироваться к изменяющимся условиям в режиме реального времени и достигать беспрецедентных уровней производительности и экономии ресурсов.
Исследование, представленное в данной работе, демонстрирует, что управление сложными системами, такими как поток жидкости вокруг цилиндра, требует подхода, выходящего за рамки традиционных методов. Авторы предлагают новую структуру, объединяющую квантовое обучение с подкреплением, что позволяет системе адаптироваться и оптимизировать управление потоком. Этот подход напоминает слова Игоря Тамма: «Не следует думать, что все можно предвидеть. Нужно строить систему так, чтобы она могла выдержать неожиданности». Подобно тому, как квантовые алгоритмы позволяют исследовать множество возможностей одновременно, предложенный метод активно контролирует поток, реагируя на изменения и стабилизируя структуру следа, тем самым снижая сопротивление и повышая эффективность. Система не строится как жёсткая конструкция, а скорее как развивающаяся экосистема, способная к самокоррекции и адаптации.
Что дальше?
Представленная работа лишь приоткрывает завесу над тем, как квантовое обучение с подкреплением может изменить парадигму управления потоками. Это не столько построение системы, сколько культивирование новой экосистемы, где алгоритм адаптируется к хаосу, а не пытается его подавить. Долгосрочный успех не будет измеряться величиной снижения сопротивления, а устойчивостью этой адаптации к непредсказуемым возмущениям, которые неизбежно возникнут.
Очевидно, что текущая реализация ограничена вычислительными ресурсами и сложностью моделирования турбулентных потоков. Однако, истинная проблема заключается не в увеличении масштаба вычислений, а в разработке архитектур, способных прогнозировать будущие точки отказа. Каждый архитектурный выбор — это пророчество о будущей катастрофе, и необходимо научиться читать эти знамения.
Порядок — это лишь кэш между двумя сбоями. Будущие исследования должны быть направлены на создание систем, способных не просто реагировать на изменения, но и предвидеть их, используя принципы самоорганизации и адаптивного обучения. Нет лучших практик, есть лишь выжившие. И выживут те, кто научится выращивать устойчивость, а не строить крепости.
Оригинал статьи: https://arxiv.org/pdf/2601.17801.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Квантовый скачок в обработке радиоастрономических данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-27 15:45