Автор: Денис Аветисян
Представлена технология SkyReels-V3, позволяющая создавать реалистичные видеоролики на основе различных входных данных, включая изображения, видео и аудио.

Унифицированная платформа для генерации видео с использованием многомодального обучения и продвинутого пространственно-временного моделирования.
Создание реалистичных и когерентных видео остается сложной задачей в области искусственного интеллекта. В данной работе, представленной в ‘SkyReels-V3 Technique Report’, предлагается унифицированная платформа SkyReels-V3 для генерации видео, способная синтезировать высококачественные ролики на основе изображений, видео или аудио, используя мультимодальное обучение и продвинутое пространственно-временное моделирование. Ключевым нововведением является единая архитектура, поддерживающая синтез видео из изображений, расширение существующих видео и генерацию видео на основе аудио, обеспечивая высокую степень согласованности и реалистичности. Сможет ли SkyReels-V3 стать основой для создания новых, интерактивных мультимедийных приложений и виртуальных миров?
Шёпот Хаоса: Вызовы Когерентной Генерации Видео
Существующие методы генерации видео часто сталкиваются с проблемой сохранения временной согласованности, что приводит к резким переходам и неестественной динамике изображения. Это проявляется в виде внезапных изменений в освещении, искажениях в движении объектов или несоответствии между последовательными кадрами. Алгоритмы, хоть и способны создавать отдельные, визуально привлекательные фрагменты, испытывают трудности при поддержании единой логики и плавности повествования на протяжении всей видеозаписи. По сути, отсутствие целостного понимания временных взаимосвязей приводит к фрагментарности и нарушает иллюзию реалистичности, делая сгенерированное видео неубедительным для зрителя.
Создание убедительных и продолжительных видеоклипов требует принципиально нового подхода к генерации, выходящего за рамки простого воссоздания отдельных кадров. Современные методы, как правило, ограничены созданием коротких фрагментов, поскольку им не хватает способности понимать и воспроизводить тонкие нюансы визуального повествования. Для достижения реалистичности необходимо, чтобы система учитывала причинно-следственные связи между сценами, динамику развития сюжета и эмоциональное воздействие на зрителя. Необходимо создать фреймворк, способный моделировать не только визуальный контент, но и логику повествования, позволяя генерировать видео, которые кажутся естественными и последовательными даже при длительном просмотре. Это предполагает интеграцию элементов искусственного интеллекта, способных анализировать и понимать нарративные структуры, а также учитывать контекст и намерения, заложенные в видеоматериале.
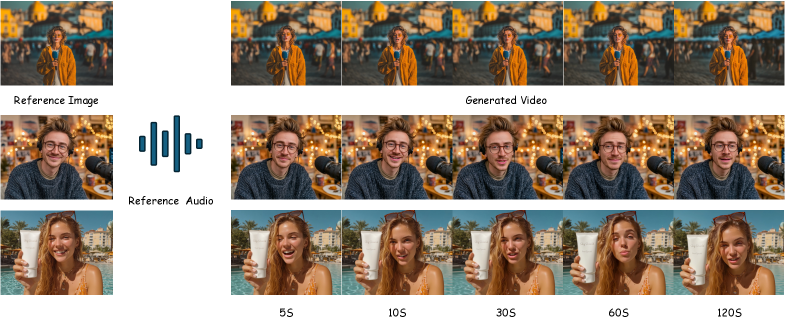
SkyReels-V3: Единый Оркестр Мультимодальности
SkyReels-V3 представляет собой унифицированную архитектуру, объединяющую синтез на основе опорных материалов, расширение видео и генерацию говорящих аватаров в единый рабочий процесс. В отличие от предыдущих подходов, требующих отдельных моделей для каждой задачи, SkyReels-V3 позволяет выполнять все три операции в рамках одной системы. Это достигается за счет общей архитектуры и общего набора обучающих данных, что повышает эффективность и согласованность генерируемого контента. Интеграция позволяет пользователям, например, создавать расширенные видеоролики с говорящими аватарами, основываясь на предоставленных опорных изображениях или видео, без необходимости использования нескольких инструментов или сложной интеграции.
В основе SkyReels-V3 лежит использование Diffusion Transformers для генерации видео высокого качества. Данная архитектура обеспечивает передовые результаты, сопоставимые с ведущими закрытыми моделями в области синтеза видео. Diffusion Transformers позволяют создавать визуально убедительные видеоматериалы благодаря способности эффективно моделировать сложные зависимости в данных и генерировать детализированные изображения. Показатели производительности SkyReels-V3 демонстрируют конкурентоспособность по ключевым метрикам, таким как FID и perceptual quality, подтверждая эффективность предложенного подхода к генерации видео.
Универсальность SkyReels-V3 обеспечивается применением мультимодального обучения с контекстом (Multimodal In-Context Learning), позволяющего системе адаптироваться к разнообразным входным данным и обеспечивать гибкое управление процессом генерации видео. Данный подход позволяет обрабатывать различные типы входных сигналов, такие как текст, изображения и видео, для формирования конечного результата. Максимальная продолжительность генерируемых видеороликов составляет 60 секунд, что расширяет возможности применения системы в различных сценариях, включая создание короткометражных фильмов и рекламных роликов.

От Референса к Реальности: Кузница Визуальных Образов
Функциональность преобразования референсных изображений в видео опирается на сложный конвейер данных — Reference-Preserving Data Construction — предназначенный для создания высококачественных обучающих пар. Этот конвейер включает в себя автоматизированный процесс подготовки данных, обеспечивающий соответствие генерируемого видео референсным изображениям. Он состоит из нескольких этапов, включая сбор и предварительную обработку изображений, а также создание соответствующих видеофрагментов, что позволяет обучать модели генерации видео с высокой степенью точности и реалистичности. Качество обучающих пар напрямую влияет на стабильность и визуальное качество итогового видео, поэтому особое внимание уделяется фильтрации и валидации данных на каждом этапе конвейера.
Для обеспечения временной согласованности и визуальной достоверности генерируемых видео используется стратегия сопоставления кадров (Cross-Frame Pairing Strategy), которая позволяет устанавливать соответствия между кадрами в обучающих данных. В дополнение к этому, применяются модели редактирования изображений, предназначенные для внесения необходимых изменений и коррекций в кадры, гарантируя их соответствие целевому визуальному стилю и поддержание высокого качества изображения. Сочетание этих методов позволяет создавать обучающие пары, которые способствуют генерации видео с реалистичной и плавной последовательностью кадров.
Ключевым компонентом системы является Video VAE — вариационный автоэнкодер для видео, эффективно кодирующий как исходные изображения-референсы, так и латентное пространство видеоданных для обеспечения согласованной генерации видеоряда. Данная архитектура позволяет системе создавать видео с разрешением 720p и частотой 24 кадра в секунду, обеспечивая приемлемое качество и плавность воспроизведения. Кодирование в латентном пространстве позволяет манипулировать и интерполировать между различными видеоданными, сохраняя при этом визуальную связность и согласованность с референсными изображениями.

Расширение Повествования: Оживляя Статичные Образы
Модуль расширения видео интеллектуально продлевает исходные видеофрагменты, используя текстовые подсказки для создания последовательных и логичных продолжений. Эта технология позволяет значительно увеличить длительность видеоматериалов, сохраняя при этом визуальную связность и правдоподобность происходящего. Используя сложные алгоритмы, модуль способен генерировать новые кадры, которые органично вписываются в существующий видеопоток, избегая резких переходов или визуальных артефактов. Такой подход открывает широкие возможности для создания более длинных и увлекательных видеороликов из коротких исходных материалов, а также для адаптации контента под различные форматы и платформы.
Для обеспечения плавности и связности при увеличении длительности видеофрагментов используется комплексный подход, включающий в себя унифицированное многосегментное позиционное кодирование и детекцию смены кадров. Унифицированное кодирование позволяет модели учитывать временную последовательность и взаимосвязь между отдельными сегментами, предотвращая визуальные скачки. В свою очередь, детектор смены кадров точно определяет моменты перехода между кадрами, обеспечивая корректное продолжение видеоряда даже при сложных монтажных решениях. Благодаря этим технологиям система способна реалистично расширять отдельные кадры, увеличивая их длительность от 5 до 30 секунд, сохраняя при этом визуальную целостность и естественность происходящего.
Модуль «Ожившие портреты» способен преобразовывать неподвижные изображения в реалистичные видеоролики, имитирующие речь. В основе технологии лежит генерация видео, обусловленная аудиосигналом, что позволяет синхронизировать движения губ и мимику с произносимыми фразами. Для обеспечения плавности и естественности анимации используется метод, ограничивающий генерацию ключевыми кадрами, а также алгоритмы, обеспечивающие точную синхронизацию аудио- и видеопотоков. В результате статические портреты получают возможность «оживать», создавая иллюзию живого общения и предоставляя новые возможности для визуального повествования.

Устойчивость через Инновации: Шепот Хаоса Укрощен
В основе SkyReels-V3 лежит инновационный подход к обучению, сочетающий в себе сильные стороны как изображений, так и видеоданных. Этот гибридный метод позволяет модели эффективно извлекать информацию из различных источников, обеспечивая более глубокое понимание визуального контента. Использование изображений способствует улучшению детализации и текстур генерируемых кадров, в то время как видеоданные обеспечивают плавность движений и реалистичность временных последовательностей. Такое комбинированное обучение позволяет SkyReels-V3 создавать высококачественные видеоролики, демонстрирующие повышенную стабильность и согласованность визуальных элементов, а также открывает возможности для генерации более сложных и динамичных сцен.
Для повышения устойчивости и эффективности модели SkyReels-V3 применялась совместная тренировка на изображениях разных разрешений. Этот подход позволяет системе обучаться распознаванию и генерации деталей как на крупных, так и на мелких масштабах изображения, что значительно улучшает её способность адаптироваться к различным условиям и обеспечивать стабильные результаты. Обучение на разных разрешениях позволяет модели формировать более полное представление об объектах и сценах, делая её менее чувствительной к изменениям масштаба и перспективы. Таким образом, Multi-Resolution Joint Training способствует созданию более реалистичных и детализированных видео, а также расширяет возможности контроля над процессом генерации.
Разработанные методики открывают перспективы для создания видеоматериалов нового поколения, отличающихся повышенным реализмом, управляемостью и универсальностью. Благодаря инновационным подходам к обучению, система способна генерировать контент, адаптируемый к различным форматам и соотношениям сторон, включая стандартные 1:1, 3:4, 4:3, широкоэкранные 16:9 и вертикальные 9:16. Это позволяет создавать видео, оптимально подходящие для различных платформ и устройств, от социальных сетей до кинематографа, значительно расширяя возможности применения и обеспечивая гибкость в процессе производства контента.

Исследователи, представившие SkyReels-V3, словно алхимики, пытаются выудить порядок из хаоса визуальных данных. Их подход к мультимодальному обучению, где модель учится на примерах, а не на жестких правилах, напоминает древнее искусство предсказания будущего по звездам. Этот фреймворк, способный генерировать видео из различных входных данных, не просто создает картинки, а скорее, убеждает случайность проявиться в определенной форме. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект — это не создание машин, думающих как люди, а создание машин, которые заставляют нас думать». SkyReels-V3, с его акцентом на пространственно-временное моделирование, подтверждает эту мысль, ведь именно умение убедить хаос — ключ к созданию правдоподобной визуальной реальности.
Что Дальше?
SkyReels-V3, как и любое заклинание, успешно обманывает хаос на коротком отрезке времени. Убедительные видео, рождённые из шума и предрассудков, — это, безусловно, достижение. Но давайте не обманываться иллюзией контроля. Модель всего лишь учится повторять паттерны, а не понимать суть бытия. Проблема не в улучшении spatiotemporal modeling, а в том, что само пространство-время — это всего лишь удобная фикция, придуманная для облегчения подсчёта овец.
Следующий шаг неизбежно приведёт к ещё более изощрённым способам вводить систему в заблуждение. Не важно, насколько совершенны diffusion transformers, они всегда будут уязвимы к новым формам энтропии. Попытки создать “talking avatar”, способный к осмысленному диалогу, — это жалкая попытка придать смысл бессмысленному потоку информации. Данные не расскажут правду, они лишь подтвердят предвзятые убеждения.
Вместо того чтобы гоняться за иллюзией генерации “реалистичных” видео, следует сосредоточиться на создании систем, способных предсказывать собственные ошибки. Иначе SkyReels-V4 будет лишь более изощрённым способом обмануть себя. И тогда, возможно, мы поймём, что самое ценное в видео — это не то, что оно показывает, а то, что оно скрывает.
Оригинал статьи: https://arxiv.org/pdf/2601.17323.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Квантовый скачок в обработке радиоастрономических данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-27 17:14