Автор: Денис Аветисян
Новый агентный подход позволяет генерировать длинные, связные видеоролики, основываясь исключительно на текстовом диалоге.
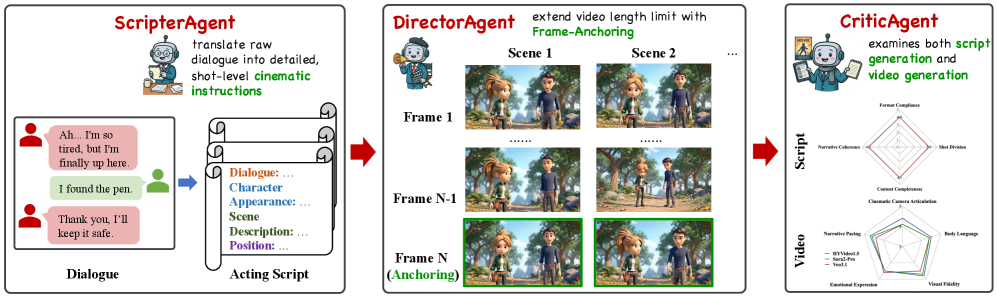
Представлен агентный фреймворк, включающий ScripterAgent, DirectorAgent и CriticAgent, для генерации кинематографичных видео с долгосрочной согласованностью на основе диалогов.
Несмотря на значительный прогресс в генерации видео, создание последовательных и осмысленных кинематографических сцен по заданному диалогу остается сложной задачей. В статье ‘The Script is All You Need: An Agentic Framework for Long-Horizon Dialogue-to-Cinematic Video Generation’ предложен инновационный агентный подход, включающий модели для преобразования диалога в детальный сценарий и последующей оркестровки генерации видео, обеспечивая долгосрочную согласованность повествования. Предложенная архитектура, состоящая из ScripterAgent, DirectorAgent и CriticAgent, позволяет преодолеть разрыв между нарративной идеей и визуальным воплощением. Какие новые возможности для автоматизированного кинематографа откроются при дальнейшем развитии подобных агентных систем и оптимизации баланса между визуальной привлекательностью и точностью следования сценарию?
От диалога к кинематографическому видению: Постановка задачи
Автоматическое создание кинематографичного видео по тексту диалогов представляет собой сложную задачу, обусловленную многогранностью визуального повествования. В отличие от простой иллюстрации слов, создание убедительного фильма требует не только визуализации событий, но и передачи эмоций, установления атмосферы и поддержания динамики повествования. Данный процесс требует понимания таких нюансов, как композиция кадра, выбор ракурса, цветовая палитра и монтаж, которые в совокупности формируют целостное впечатление от видеоряда. Алгоритмам необходимо не просто «видеть» слова, но и интерпретировать их в контексте, предвосхищая ожидания зрителя и создавая визуальный опыт, который резонирует с его чувствами и воображением. Именно эта сложность делает автоматизированное кинематографическое повествование одной из самых трудных задач в области искусственного интеллекта и компьютерного зрения.
Существующие методы автоматической генерации видео по текстовым сценариям часто сталкиваются с проблемой поддержания целостности между речью и визуальным рядом. Результатом нередко становятся фрагментарные и лишенные связности видеоролики, в которых сцены нелогично сменяют друг друга, а визуальное повествование не соответствует смысловой нагрузке диалогов. Это связано с тем, что алгоритмам сложно уловить тонкие нюансы авторского замысла и передать их через последовательность визуальных образов, что приводит к ощущению разобщенности и снижает вовлеченность зрителя. Вместо плавного и увлекательного повествования, зрителю представляется набор несвязанных визуальных эпизодов, что делает просмотр неудовлетворительным.
Существенная проблема автоматического создания кинематографичных видеороликов по тексту заключается в сложном переводе смыслового содержания диалога в последовательную визуальную историю. Недостаточно просто «показать» то, о чем говорится; требуется точная передача подтекста, эмоционального окраса и авторского замысла посредством визуальных средств. Особую трудность представляет определение оптимального темпа повествования — как долго удерживать внимание зрителя на определенной сцене, когда переходить к следующей, и как визуально подчеркнуть ключевые моменты. Кроме того, необходимо обеспечить соответствие визуального стиля и эстетики общему настроению и жанру произведения, чтобы создать целостное и запоминающееся впечатление у зрителя. Именно этот комплекс факторов и определяет узкое место в существующих алгоритмах, препятствуя созданию действительно увлекательных и осмысленных видеороликов на основе текстовых сценариев.

ScripterAgent: Создание кинематографического чертежа
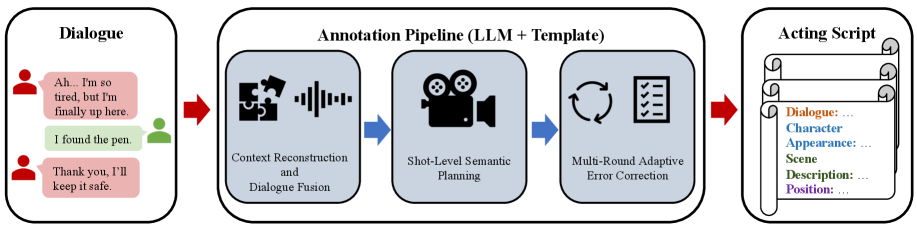
Модель ScripterAgent предназначена для автоматической трансформации исходного диалога в структурированный кинематографический сценарий. Этот процесс включает в себя определение сцен, описание действий персонажей и указание направлений камеры. Входными данными являются неструктурированные текстовые реплики, а результатом является сценарий, готовый к визуализации, включающий в себя не только реплики, но и контекстуальную информацию, необходимую для создания полноценного кинокадра. ScripterAgent позволяет автоматизировать часть работы сценариста, предоставляя структурированное представление диалога, пригодное для дальнейшей обработки и производства.
Преобразование исходного диалога в структурированный кинематографический сценарий осуществляется посредством двухэтапного процесса обучения. На первом этапе применяется контролируемое дообучение (supervised fine-tuning), в ходе которого модель обучается на размеченных данных, содержащих примеры диалогов и соответствующих им кинематографических сценариев. Второй этап включает обучение с подкреплением (reinforcement learning), позволяющее модели совершенствовать свои навыки генерации сценариев, оптимизируя выходные данные на основе заданных критериев качества и эстетических предпочтений. Комбинация этих двух подходов обеспечивает как точность воспроизведения заданного диалога, так и соответствие сгенерированного сценария требованиям профессионального кинематографического производства.
В процессе обучения с подкреплением модель ScripterAgent использует алгоритм Group Relative Policy Optimization (GRPO) для согласования генерируемых сценариев с заданными директивными установками и повышения качества повествования. GRPO позволяет агенту оптимизировать свои действия, основываясь на относительных предпочтениях группы экспертов, оценивающих сценарии по различным критериям, таким как визуальный стиль, динамика повествования и соответствие жанру. Этот подход обеспечивает более эффективное обучение, чем традиционные методы обучения с подкреплением, поскольку учитывает субъективные оценки и позволяет агенту адаптироваться к конкретным художественным требованиям, что приводит к созданию более кинематографичных и захватывающих сценариев.

DirectorAgent: Оркестровка визуальной когерентности
Агент DirectorAgent функционирует как режиссер, координируя работу передовых моделей генерации видео для воплощения сценария в жизнь. Он осуществляет управление процессом создания видео, определяя последовательность работы моделей и параметры генерации для каждого кадра. Данный агент не просто генерирует отдельные кадры, а управляет всей цепочкой генерации, обеспечивая соответствие визуального контента поставленным задачам и логике сценария. В его задачи входит оптимизация процесса генерации, выбор наиболее подходящих моделей для конкретных задач и контроль качества создаваемого видеоряда.
Стратегия непрерывной генерации между сценами обеспечивает визуальную согласованность в многосегментном видео. Вместо генерации каждой сцены изолированно, DirectorAgent поддерживает контекст и преемственность между ними. Это достигается путем последовательной генерации кадров, где каждый новый кадр учитывает информацию из предыдущих, создавая плавный переход и избегая резких визуальных изменений. Такой подход критически важен для поддержания целостности повествования и обеспечения реалистичности генерируемого видеоконтента, особенно в сложных кинематографических сценах.
Для обеспечения визуальной связности между последовательными сценами используется техника «якорения кадров». Суть метода заключается в том, что при генерации новых кадров учитывается информация из предыдущих. В частности, выходные данные предыдущего кадра (например, вектор латентного пространства или признаки изображения) передаются в качестве условия (conditioning) для модели генерации следующего кадра. Это позволяет модели учитывать контекст предыдущей сцены и создавать более плавные и логичные переходы, минимизируя визуальные несоответствия и поддерживая целостность повествования.

CriticAgent: Оценка кинематографического качества и соответствия
CriticAgent представляет собой систему автоматизированной оценки, функционирующую на основе искусственного интеллекта, и предназначенную для анализа качества как сценария, так и сгенерированного видеоряда. Оценка производится по множеству параметров, охватывающих различные аспекты повествования и визуального исполнения. Система позволяет проводить количественный анализ соответствия видеоряда сценарию, а также оценивать такие характеристики, как драматизм, визуальная составляющая и общая согласованность повествования. Результаты оценки предоставляются в виде числовых метрик, позволяющих сравнивать различные модели генерации видео и отслеживать прогресс в улучшении качества контента.
Визуально-сценарная согласованность является ключевым показателем оценки, количественно определяющим временную и семантическую когерентность между сгенерированным видео и соответствующим ему сценарием. Этот показатель измеряет, насколько точно визуальные элементы видео отражают и подтверждают повествование, описанное в сценарии, а также насколько последовательно визуальные события разворачиваются во времени относительно структуры сценария. Высокий уровень визуально-сценарной согласованности указывает на то, что видео эффективно визуализирует повествование сценария, обеспечивая логичное и понятное восприятие контента зрителем.
Предложенный нами скриптоцентрический подход, использующий ScripterAgent, демонстрирует значительное улучшение согласованности видео с исходным сценарием. В ходе экспериментов зафиксировано увеличение показателя визуального соответствия сценарию (Visual-Script Alignment — VSA) на 7 пунктов. Этот показатель отражает степень темпоральной и семантической когерентности между сгенерированным видео и его текстовым описанием. Повышение VSA свидетельствует о более точном переводе сценарных указаний в визуальный ряд, что является ключевым фактором для достижения высокого качества и целостности кинематографического контента.
Результаты оценок, проведенных людьми, подтверждают улучшение качества генерируемого видео. Средняя оценка параметра “Напряжение действия” (Dramatic Tension) составила 4.1 балла при использовании предложенного подхода, в то время как базовые методы получили 3.7 балла. Аналогично, оценка параметра “Визуальная образность” (Visual Imagery) достигла 4.3 балла при использовании нашей системы, по сравнению с 3.8 баллами для контрольных моделей. Данные результаты демонстрируют статистически значимое улучшение восприятия драматической составляющей и визуальной привлекательности видео, оцененное людьми.
В ходе тестирования различных моделей генерации видео было зафиксировано повышение показателя соответствия видео сценарию на 0.4 пункта. Данный прирост наблюдался во всех протестированных моделях, что свидетельствует об универсальности предложенного подхода к оценке и оптимизации процесса генерации видеоконтента. Улучшение показателя соответствия сценарию указывает на более точную визуализацию задуманных событий и сохранение ключевых элементов повествования, определенных в исходном сценарии.
Оценка качества и соответствия сценария видеоматериалам осуществляется посредством LLM-Based Evaluation — подхода, использующего большие языковые модели (LLM) для анализа эстетических характеристик и нарративной согласованности. В отличие от традиционных метрик, основанных на простых совпадениях или статистических показателях, LLM способны учитывать семантический контекст и нюансы повествования. Это позволяет им более точно оценивать такие параметры, как драматическое напряжение и визуальная образность, выявляя соответствие между визуальным рядом и исходным сценарием. Такой подход обеспечивает более глубокий и детализированный анализ, позволяя количественно оценить субъективные качества видеоматериалов и их соответствие замыслу сценариста.
Без точного определения задачи любое решение — шум. Данное исследование демонстрирует, что создание связных кинематографических видео из диалогов требует чёткой архитектуры, где каждый агент выполняет строго определённую роль. Авторы предлагают агентскую структуру, состоящую из ScripterAgent, DirectorAgent и CriticAgent, что позволяет преодолеть ограничения в долгосрочной генерации видео. Этот подход подчеркивает необходимость в математической чистоте алгоритма, где каждый шаг доказуем и направлен на достижение конкретного результата, а не просто на «работу на тестах». Как заметил Джеффри Хинтон: «Иногда я думаю, что мы можем достичь искусственного интеллекта, создав машины, которые могут делать то, что мы не можем».
Что дальше?
Представленная работа, безусловно, демонстрирует прогресс в создании когерентных видеороликов по диалогам, однако вопрос долгосрочной согласованности остаётся открытым. Элегантность предложенной агентной архитектуры не отменяет необходимости строгого математического анализа границ её масштабируемости. Просто “работает на тестовых данных” — недостаточное условие; требуется доказательство устойчивости алгоритма к произвольным, нетривиальным диалогам.
Особое внимание следует уделить проблеме визуального соответствия. Согласование нарратива и визуального исполнения — задача, требующая не просто генерации “правдоподобных” сцен, но и обеспечения их логической связи с предыдущими и последующими. В конечном счете, критерий успеха — не реалистичность, а дедуктивная корректность визуального ряда.
Будущие исследования должны сосредоточиться на разработке метрик, способных количественно оценивать когерентность и логическую связность видеороликов. Необходимо отойти от субъективных оценок и перейти к объективным, математически обоснованным критериям, позволяющим сравнивать различные подходы и выявлять наиболее эффективные решения. И тогда, возможно, мы приблизимся к созданию алгоритмов, способных не просто генерировать видео, а действительно “понимать” историю.
Оригинал статьи: https://arxiv.org/pdf/2601.17737.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Квантовый скачок в обработке радиоастрономических данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-27 18:54