Автор: Денис Аветисян
Новый подход к машинному обучению позволяет повысить надежность анализа медицинских изображений, полученных в разных клиниках и на различном оборудовании.

В статье представлена новая глубокая нейронная сеть с квантовым расширением для улучшения обобщающей способности моделей классификации медицинских изображений в условиях межцентровой вариативности.
Несмотря на достигнутые успехи в области искусственного интеллекта для анализа медицинских изображений, их обобщающая способность часто снижается при переходе от единого центра к многоцентровой практике. В данной работе, озаглавленной ‘Domain Generalization with Quantum Enhancement for Medical Image Classification: A Lightweight Approach for Cross-Center Deployment’, предложен новый фреймворк глубокого обучения, использующий квантовое улучшение признаков для повышения устойчивости к смещению доменов. Предложенный подход, основанный на архитектуре MobileNetV2 и включающий симуляцию смещения доменов, состязательное обучение и квантовый слой улучшения признаков, демонстрирует значительное превосходство над существующими методами в задачах классификации изображений. Может ли предложенная парадигма гибридных квантово-классических систем стать ключом к созданию более надежных и универсальных инструментов диагностики в медицинской практике?
Шепот Хаоса: Вызовы Обобщения в Медицинской Визуализации
Глубокое обучение демонстрирует впечатляющие результаты в классификации медицинских изображений, однако его эффективность часто снижается при применении к данным, полученным в различных медицинских учреждениях. Эта проблема представляет собой серьезное препятствие для широкого внедрения технологии в клиническую практику. Несмотря на высокую точность на обучающих данных, модели зачастую показывают значительно худшие результаты при анализе изображений, полученных с использованием отличающихся протоколов сканирования или на пациентах с иными демографическими характеристиками. Такое снижение производительности подчеркивает важность разработки методов, обеспечивающих устойчивость и обобщающую способность алгоритмов глубокого обучения в условиях реальной клинической практики, где данные неизбежно отличаются от тех, на которых модель была обучена.
Неспособность моделей глубокого обучения успешно адаптироваться к данным из различных медицинских центров напрямую связана с явлением, известным как “смещение домена”. Различия в протоколах визуализации — будь то настройки оборудования, параметры сканирования или методы обработки изображений — приводят к существенным расхождениям между данными, используемыми для обучения модели, и данными, получаемыми в реальной клинической практике. Более того, вариации в характеристиках пациентов — возраст, пол, этническая принадлежность, стадия заболевания — также вносят свой вклад в эти расхождения. В результате модель, прекрасно работающая на обучающем наборе, может демонстрировать значительно сниженную производительность при анализе изображений, полученных в другом медицинском учреждении, что подчеркивает необходимость разработки методов, устойчивых к таким изменениям в данных.
Традиционные модели глубокого обучения часто сталкиваются с трудностями при извлечении признаков, не зависящих от конкретной области получения данных, что существенно ограничивает их применимость в реальной клинической практике. Это связано с тем, что стандартные алгоритмы склонны “запоминать” специфические характеристики обучающей выборки, включая особенности протоколов визуализации и демографические данные пациентов, а не выявлять общие закономерности, присущие патологии. В результате, при использовании модели на данных из другого медицинского центра, где протоколы или популяция пациентов отличаются, точность прогнозов резко снижается. Таким образом, разработка надежных методов, позволяющих моделям извлекать доменно-инвариантные признаки, становится критически важной задачей для успешного внедрения глубокого обучения в клиническую диагностику и лечение.
Искусство Обмана: Создание Доменно-Инвариантных Кодировщиков Признаков
Домен-инвариантные энкодеры признаков предназначены для извлечения признаков, нечувствительных к изменениям в областях получения изображений. Это достигается путем минимизации различий в представлении признаков между различными доменами, такими как изображения, полученные с использованием разного оборудования, в разных условиях освещения или с разных углов обзора. В результате, модель может обобщать знания, полученные из одного домена, на другие, не требуя переобучения или адаптации для каждого нового домена. Это критически важно для приложений, где данные могут поступать из разнообразных источников и областей, обеспечивая надежность и точность анализа независимо от особенностей получения изображений.
Метод состязательного обучения для доменной инвариантности предполагает использование градиентного слоя обратного распространения (Gradient Reversal Layer, GRL). GRL функционирует как функция идентичности во время прямого прохода, позволяя градиентам течь как обычно. Однако, во время обратного прохода, GRL инвертирует знак градиента, поступающего от дискриминатора домена. Это заставляет энкодер признаков учиться извлекать признаки, которые не позволяют дискриминатору отличить исходный домен изображения, эффективно минимизируя расхождения в представлении признаков между разными доменами. По сути, энкодер обучается обманывать дискриминатор, создавая доменно-инвариантные признаки.
При построении доменно-инвариантных кодировщиков признаков, архитектуры с небольшим количеством параметров, такие как MobileNetV2, часто используются в качестве базовых сетей (backbones). Это обусловлено необходимостью достижения баланса между производительностью и вычислительной эффективностью, особенно при работе с ограниченными ресурсами или в режиме реального времени. MobileNetV2 использует глубинные свертки и инвертированные остаточные блоки для уменьшения числа параметров и операций, сохраняя при этом достаточную точность. Применение таких архитектур позволяет снизить потребление памяти и энергии, что критично для развертывания моделей на мобильных устройствах или встраиваемых системах, а также ускорить процесс обучения и инференса.
Квантовый Шепот: Усиление Признаков для Надежности
Улучшение выразительности признаков с использованием квантовых вычислений основывается на применении принципов квантовой механики для преобразования исходных признаков изображения. В частности, используются квантовые алгоритмы для создания более сложных и информативных представлений, позволяющих лучше различать различные объекты и паттерны. Этот подход позволяет кодировать больше информации в признаках, что повышает устойчивость к шуму и вариациям в данных, а также улучшает общую производительность алгоритмов машинного обучения при обработке изображений.
Для повышения выразительности признаков изображений используются вариационные квантовые схемы, которые осуществляют отображение этих признаков в многомерное гильбертово пространство. Этот процесс основан на использовании квантовой запутанности, позволяющей создавать более сложные и информативные представления данных. В отличие от классических методов, где размерность признакового пространства ограничена, квантовое отображение позволяет эффективно кодировать информацию в экспоненциально большем пространстве состояний, что способствует более тонкому различению объектов и повышению устойчивости к изменениям в данных.
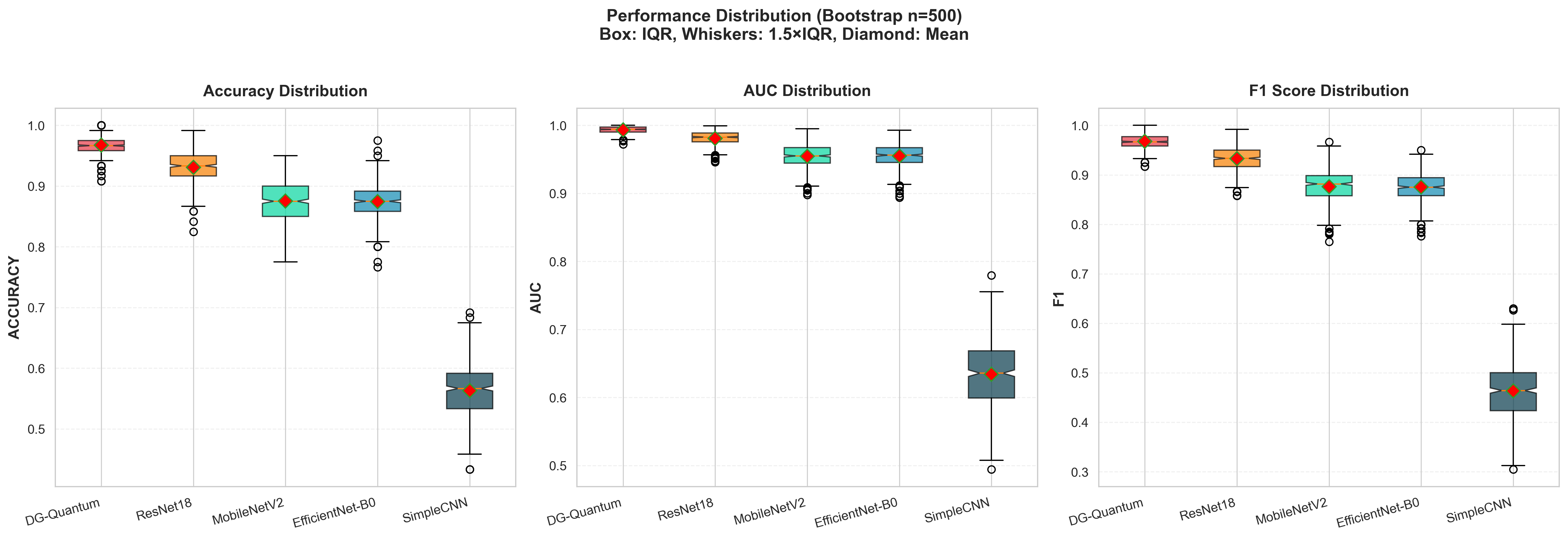
Данный подход расширяет возможности традиционного глубокого обучения за счет интеграции квантово-вдохновленных механизмов, направленных на улучшение моделирования признаков и повышение устойчивости к смещению домена. В ходе симуляции многоцентровой медицинской классификации изображений, была достигнута пиковая точность в 0.967, с 95% доверительным интервалом, составляющим приблизительно 0.81-0.93. Это указывает на потенциал повышения робастности и обобщающей способности моделей при работе с данными, полученными из различных источников.
От Зеркала к Реальности: Оценка и Адаптация в Новых Доменах
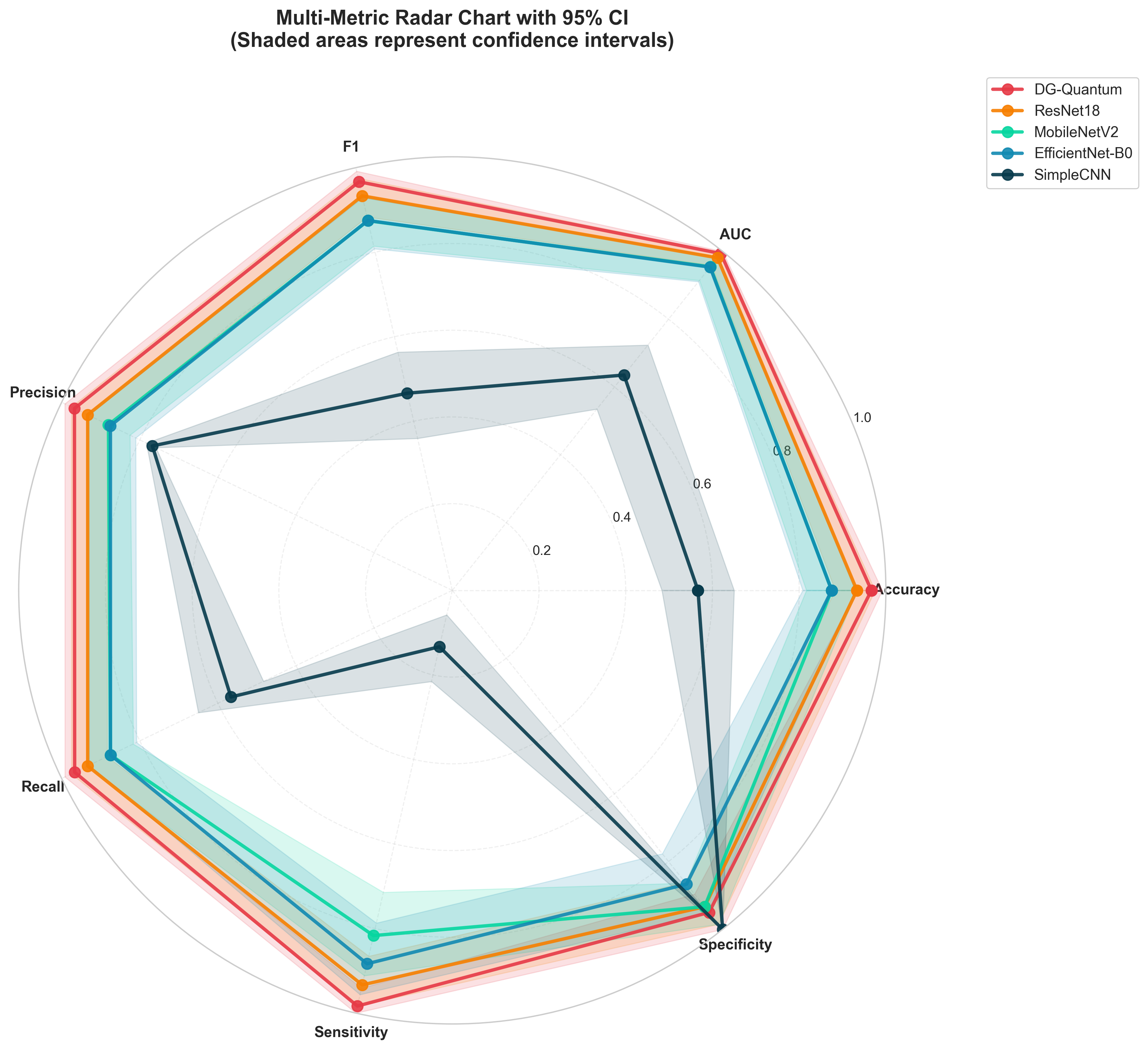
Оценка производительности рассматриваемых моделей обычно осуществляется с использованием метрик, таких как площадь под ROC-кривой (AUC) и точность (Accuracy). ROC-кривые, визуализирующие зависимость между истинно-положительной и ложно-положительной долями, позволяют наглядно оценить способность модели к различению классов. Для объективной оценки эффективности, результаты сравниваются с показателями базовых архитектур, включая ResNet18, EfficientNet-B0 и SimpleCNN, что позволяет выявить преимущества предлагаемого подхода и его способность превосходить существующие решения в задачах классификации изображений. Такой сравнительный анализ обеспечивает надежную основу для оценки и дальнейшей оптимизации разработанных моделей.
Представленная квантово-усиленная архитектура продемонстрировала впечатляющие результаты, достигнув пикового значения AUC, равного 0.9936. Это значительно превосходит показатели, зафиксированные для традиционных сверточных нейронных сетей, таких как ResNet18 (AUC: 0.9811), MobileNetV2 (AUC: 0.9544) и EfficientNet-B0 (AUC: 0.9536). Особенно заметно превосходство над SimpleCNN, чей показатель AUC составил лишь 0.6353. Полученные данные свидетельствуют о потенциале квантовых методов для существенного повышения точности и эффективности в задачах классификации изображений, открывая новые возможности для применения в различных областях, требующих высокой степени распознавания и анализа визуальной информации.
Адаптация модели в процессе тестирования позволяет ей эффективно приспосабливаться к особенностям новой предметной области, не требуя переобучения. Этот процесс часто реализуется посредством техник, таких как пакетная нормализация, которая корректирует распределение данных, поступающих на вход, чтобы учесть специфические характеристики целевого домена. В результате модель способна сохранять высокую точность даже при работе с изображениями, полученными в условиях, отличающихся от тех, на которых она обучалась. Такая адаптивность особенно важна в медицинских приложениях, где данные могут существенно различаться в зависимости от используемого оборудования, протоколов сканирования и индивидуальных особенностей пациентов.
Использование многодоменного моделирования изображений играет ключевую роль в обучении моделей, обеспечивая их устойчивость к широкому спектру условий получения изображений. Этот подход позволяет искусственно генерировать разнообразные наборы данных, имитирующие различные типы оборудования, параметры съемки и артефакты, встречающиеся в реальных условиях. В процессе обучения модель подвергается воздействию этих синтетических данных, что позволяет ей научиться выделять значимые признаки и игнорировать вариации, связанные с условиями съемки. В результате, обученная модель демонстрирует повышенную обобщающую способность и надежность при обработке изображений, полученных в новых, ранее не встречавшихся условиях, что особенно важно для приложений, где данные могут поступать из различных источников и с разными характеристиками.
Исследование, посвящённое обобщению домена в медицинской визуализации, напоминает попытку укротить неуловимого зверя. Авторы стремятся создать модель, способную распознавать изображения, полученные в разных медицинских центрах, несмотря на различия в оборудовании и протоколах. Это не просто задача классификации, а скорее алхимический процесс — преобразование шума и разнообразия в надёжный результат. Как метко заметил Дэвид Марр: «Любая модель — это заклинание, которое работает до первого продакшена». И действительно, даже самая тщательно разработанная модель сталкивается с суровой реальностью, когда её применяют к данным, отличным от тех, на которых она обучалась. Квантовое усиление признаков, предложенное в работе, представляется попыткой добавить в это заклинание немного магии, чтобы оно работало чуть дольше, чуть надёжнее, в условиях постоянного хаоса реальных данных.
Что дальше?
Предложенный подход, использующий квантовые преобразования для улучшения обобщающей способности моделей медицинской визуализации, — это, скорее, попытка уговорить хаос, чем обуздать его. Данные, поступающие из разных центров, всегда будут нести в себе отпечаток конкретного оборудования и протоколов. Идея перенести квантовые вычисления в эту область — интересная, но иллюзия полной независимости от источника данных преследует исследователей, как тень. Если модель демонстрирует идеальную точность на кросс-валидации, стоит насторожиться: это лишь красивое враньё, замаскированное под закономерность.
Будущие исследования, вероятно, сосредоточатся на более глубоком понимании того, как квантовые представления взаимодействуют с особенностями различных доменов. Искать универсальную архитектуру бессмысленно; необходимо научиться адаптировать квантовые слои к конкретным задачам и типам изображений. Возможно, ключ кроется не в самом квантовом вычислении, а в способе использования шума — ведь шум, порой, это всего лишь правда, которой не хватает уверенности.
Обобщение между центрами остаётся сложной задачей, и любые успехи в этой области — это лишь временное затишье перед бурей новых, непредсказуемых искажений данных. Данные — это не цифры, а шёпот хаоса, и задача исследователя — не заглушить его, а научиться слушать.
Оригинал статьи: https://arxiv.org/pdf/2601.17862.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Квантовый скачок в обработке радиоастрономических данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-27 19:01