Автор: Денис Аветисян
Исследователи предлагают инновационный метод анализа архитектуры Трансформеров, позволяющий увидеть, как именно эти модели принимают решения.
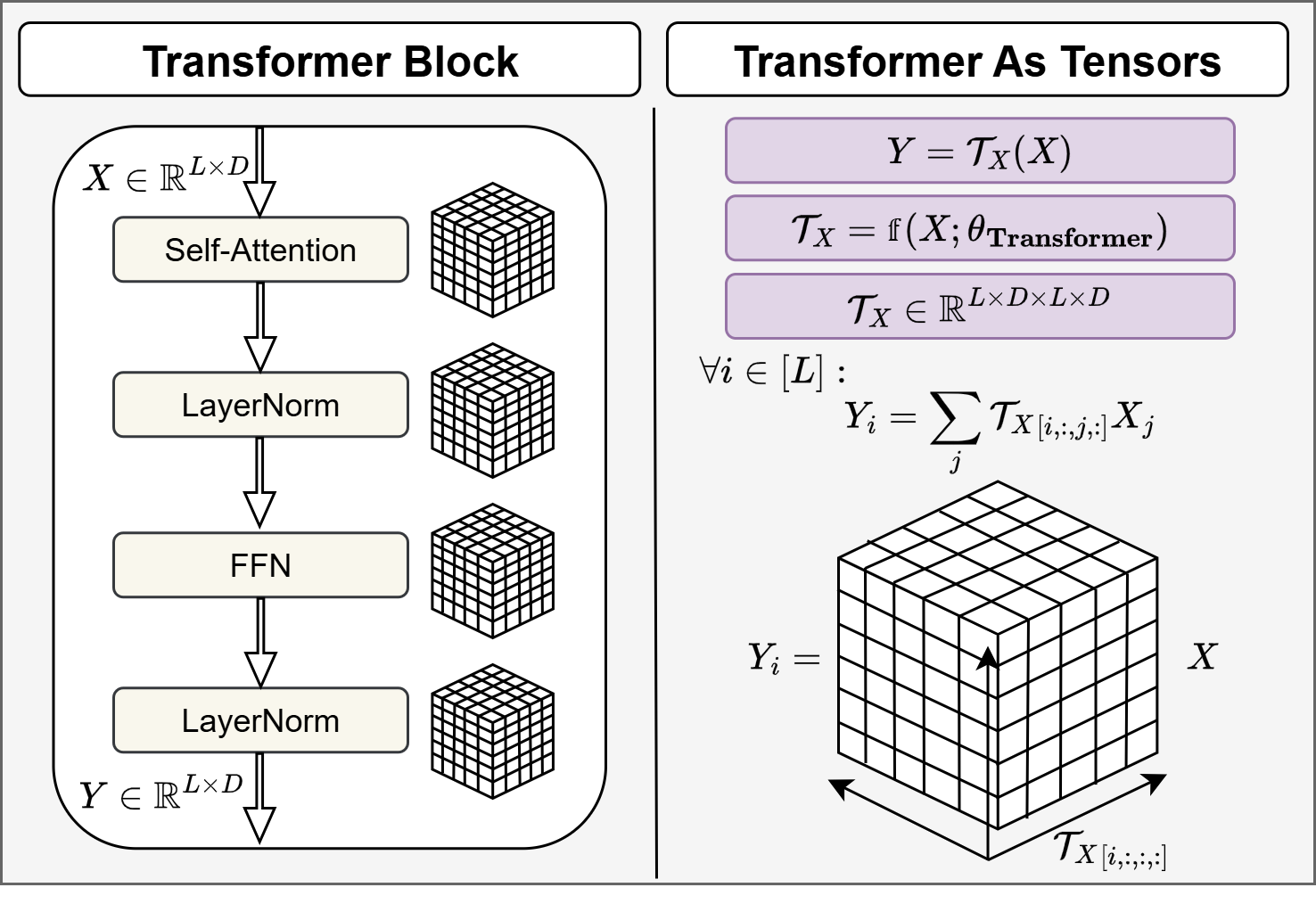
В статье представлен TensorLens — подход к анализу Трансформеров на основе представления всей модели как тензора высокого порядка для обеспечения более точной интерпретируемости.
Несмотря на фундаментальную роль матриц внимания в исследовании трансформеров, анализ часто ограничивается отдельными головами или слоями, упуская из виду глобальное поведение модели. В данной работе, ‘TensorLens: End-to-End Transformer Analysis via High-Order Attention Tensors’, предложен новый подход, представляющий всю архитектуру трансформера как единый линейный оператор, закодированный в тензоре высокого порядка, охватывающем внимание, FFN, активации и нормализации. Такое представление позволяет получить более полное и точное понимание внутренних механизмов модели, открывая возможности для интерпретируемости и механического анализа. Сможет ли предложенный тензор внимания стать основой для создания новых инструментов, углубляющих наше понимание трансформеров и их поведения?
Линейная алгебра Трансформеров: За гранью эффективности
Архитектура Transformer, несмотря на свою впечатляющую эффективность, базируется на сложных матричных операциях, которые становятся непомерно затратными по вычислительным ресурсам при увеличении масштаба обработки данных. Каждый слой Transformer включает в себя умножение матриц W на входные векторы, а также операции softmax и attention, требующие экспоненциального увеличения вычислительной мощности с ростом длины последовательности. Это особенно критично для задач обработки естественного языка, где современные модели работают с текстами, содержащими тысячи и даже миллионы токенов. Поэтому оптимизация этих матричных операций и поиск альтернативных подходов к обработке последовательностей являются ключевыми задачами в области машинного обучения и искусственного интеллекта, напрямую влияющими на практическую применимость Transformer-подобных моделей.
Архитектура Transformer, несмотря на свою эффективность, по сути представляет собой последовательность линейных преобразований, что позволяет рассматривать её как сложную систему матричных операций. Понимание этой структуры как серии линейных отображений критически важно для всестороннего анализа её возможностей и ограничений. Каждый слой Transformer можно представить как применение матрицы преобразования к входным данным, изменяя их представление в многомерном пространстве. Исследование этих матриц и их взаимодействия позволяет выявить ключевые факторы, определяющие производительность модели, а также определить потенциальные узкие места и направления для оптимизации. В частности, анализ сингулярного разложения этих матриц UΣV^T может раскрыть скрытые закономерности и упростить понимание того, как модель обрабатывает информацию и выполняет сложные задачи, такие как перевод или генерация текста. Именно этот подход позволяет не только углубить понимание принципов работы Transformer, но и разработать более эффективные методы для её улучшения и масштабирования.
Современные методы анализа, применяемые к архитектуре Transformer, зачастую оказываются недостаточными для полного понимания сложности происходящих линейных преобразований. Несмотря на значительные успехи в области машинного обучения, детальное раскрытие взаимосвязей внутри этих преобразований остается сложной задачей. Это затрудняет не только интерпретацию работы модели — понимание того, как именно она принимает решения — но и существенно ограничивает возможности оптимизации. Неспособность адекватно представить и проанализировать эти сложные преобразования приводит к неэффективному использованию вычислительных ресурсов и препятствует созданию более мощных и интерпретируемых моделей. \mathbb{R}^{n} \rightarrow \mathbb{R}^{m} отображения, лежащие в основе Transformer, требуют новых подходов к анализу, позволяющих выявить скрытые закономерности и оптимизировать процесс обучения.
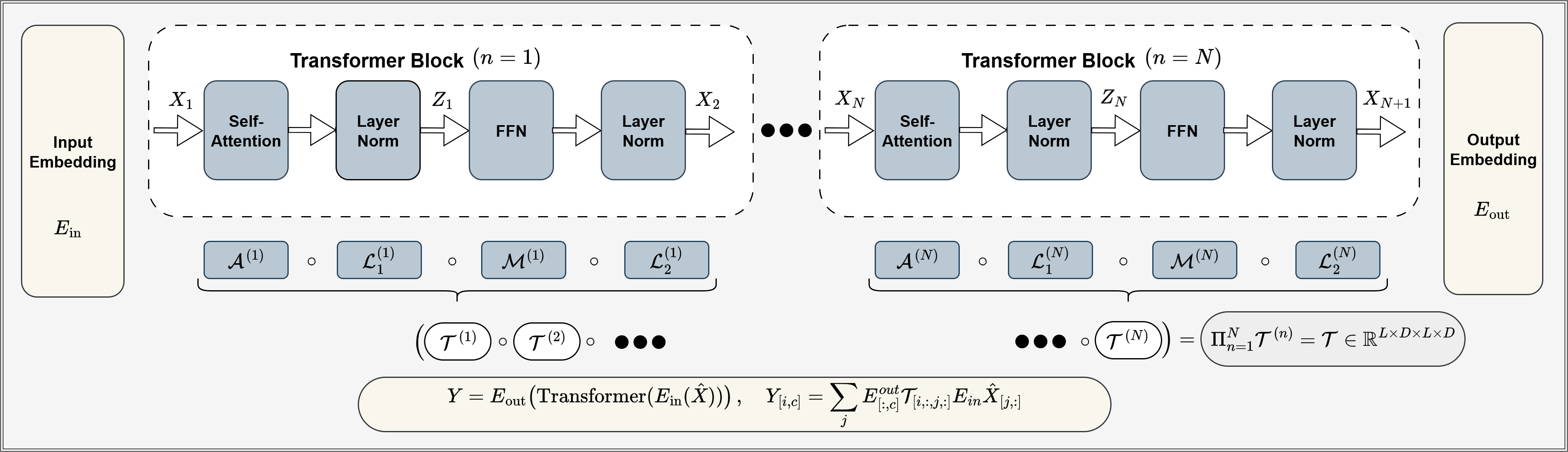
TensorLens: Единый линейный оператор для Трансформеров
TensorLens представляет собой трансформатор как тензор высокого порядка, что позволяет получить более компактное и эффективное представление модели. Вместо анализа отдельных слоев, TensorLens рассматривает всю архитектуру как единый тензор \mathcal{T} \in \mathbb{R}^{N \times N \times D \times D} , где N — длина последовательности, а D — размерность скрытого пространства. Такое представление позволяет снизить вычислительную сложность и объем памяти, необходимые для хранения и обработки модели. Компактность достигается за счет сведения операций над последовательностями к операциям над тензорами, что позволяет использовать оптимизированные тензорные вычисления и более эффективно использовать аппаратные ресурсы. Представление в виде тензора высокого порядка также упрощает анализ и оптимизацию модели, позволяя применять методы тензорной декомпозиции и другие инструменты для сокращения числа параметров и повышения производительности.
Представление Transformer как линейного оператора, управляемого данными, открывает возможности для нового типа анализа и оптимизации. Вместо рассмотрения слоев модели по отдельности, данный подход позволяет рассматривать Transformer как единое преобразование, описываемое матрицей \mathbf{W} , зависящей от входных данных \mathbf{x} . Это позволяет применять методы линейной алгебры для изучения свойств модели, такие как спектральный анализ и сингулярное разложение, что позволяет выявить важные характеристики, влияющие на производительность. Кроме того, параметризация модели через данные позволяет разрабатывать алгоритмы оптимизации, направленные на улучшение ее обобщающей способности и снижение вычислительной сложности.
Традиционный анализ архитектуры Transformer часто фокусируется на изучении отдельных слоев и их вкладе в общую производительность модели. Подход, реализованный в TensorLens, принципиально отличается, предоставляя возможность целостного анализа поведения Transformer как единого линейного оператора. Это позволяет исследовать взаимодействия между различными компонентами модели, выходя за рамки изолированного изучения отдельных слоев. Такой взгляд обеспечивает более глубокое понимание внутренних механизмов Transformer, выявляя зависимости и закономерности, которые остаются незамеченными при послойном анализе. В результате, становится возможным не только более эффективная оптимизация модели, но и разработка новых методов интерпретации и контроля ее поведения, а также выявление потенциальных узких мест и улучшение общей производительности.
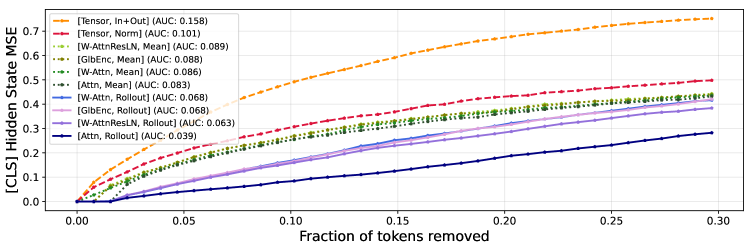
Проверка TensorLens: Декодирование взаимосвязей и анализ возмущений
Для оценки способности TensorLens моделировать линейные зависимости в вычислениях Transformer был использован метод Relation Decoding. В ходе тестирования TensorLens продемонстрировал более высокую точность по сравнению с базовым уровнем LRE, представленным в работе Hernandez et al. (2024). Данный метод позволяет количественно оценить, насколько хорошо TensorLens захватывает и воспроизводит линейные отношения между входными и выходными данными слоев Transformer, что является важным показателем его способности к интерпретации и пониманию внутренних механизмов модели.
Тесты на возмущениях подтверждают репрезентативную способность TensorLens, демонстрируя площадь под ROC-кривой (AUC) в 0.82. Данный показатель стабильно превосходит результаты, полученные с использованием базовых моделей. В частности, при проведении тестов на возмущениях модели BERT, TensorLens достиг значения AUC 0.158, что свидетельствует о более эффективном моделировании и интерпретации внутренних представлений по сравнению с существующими подходами.
Анализ матрицы Якоби, полученной на основе TensorLens, позволяет оценить чувствительность модели к изменениям входных данных. Данная матрица, представляющая собой частные производные выходных данных модели по отношению к входным данным, позволяет выявить, какие входные признаки оказывают наибольшее влияние на предсказания. Более высокие абсолютные значения элементов матрицы Якоби указывают на более сильную зависимость выходных данных от соответствующих входных признаков. Это обеспечивает возможность детального анализа влияния каждого входного токена на внутренние представления модели и финальный результат, что важно для интерпретируемости и отладки.
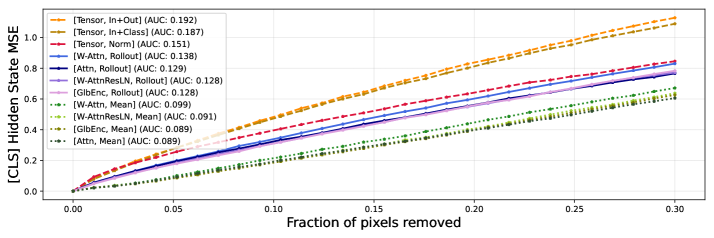
![Тесты на устойчивость к возмущениям показывают, что средняя квадратичная ошибка между последними скрытыми состояниями токена [CLS] в исходном и возмущенном тексте, используемая в качестве метрики, демонстрирует чувствительность RoBERTa-Base к изменениям входных данных (<span class="katex-eq" data-katex-display="false"> MSE </span> выше означает большую чувствительность).](https://arxiv.org/html/2601.17958v1/x6.png)
За пределами эффективности: Влияние на интерпретируемость и масштабируемость
TensorLens представляет собой инновационный подход к анализу работы трансформеров, позволяя исследователям получить более глубокое понимание процессов, происходящих внутри этих сложных нейронных сетей. В отличие от традиционных методов, фокусирующихся на статистическом анализе, TensorLens визуализирует и деконструирует ключевые тензорные представления, раскрывая логику принятия решений моделью. Это достигается путем преобразования многомерных данных в более наглядные и интерпретируемые формы, что позволяет выявить, какие конкретно элементы входных данных оказывают наибольшее влияние на выходные результаты. Таким образом, TensorLens не просто оценивает эффективность модели, но и проливает свет на её внутреннюю работу, открывая возможности для улучшения и оптимизации архитектуры, а также для выявления и устранения потенциальных смещений и ошибок.
Компактное тензорное представление, предложенное в данной работе, открывает новые возможности для масштабирования трансформерных моделей. Традиционные методы анализа внимания требуют значительных вычислительных ресурсов, что ограничивает размер моделей, которые можно эффективно исследовать. Благодаря сжатию информации в тензорной форме, TensorLens существенно снижает эти требования, позволяя обрабатывать более крупные и сложные архитектуры. Это, в свою очередь, создает предпосылки для разработки ещё более мощных языковых моделей, способных к более глубокому пониманию и генерации текста. Возможность анализа внимания в таких масштабах не только улучшает производительность, но и способствует более глубокому пониманию внутренних механизмов работы искусственного интеллекта.
Исследования показали, что сочетание методов, таких как Attention Rollout, с системой TensorLens позволяет значительно углубить понимание и повысить эффективность работы механизмов внимания в архитектуре Transformer. Attention Rollout, анализируя распространение влияния между различными частями входной последовательности, выявляет наиболее значимые связи, в то время как TensorLens обеспечивает компактное представление этих связей, упрощая их визуализацию и интерпретацию. Такой синергетический подход не только позволяет исследователям лучше понимать, какие аспекты входных данных оказывают наибольшее влияние на принятие решений моделью, но и открывает возможности для оптимизации и повышения производительности Transformer, особенно при работе с большими объемами данных и сложными задачами обработки естественного языка. Улучшенное понимание работы механизмов внимания способствует созданию более надежных и прозрачных моделей, что критически важно для областей, где требуется высокая степень доверия к результатам, например, в медицине или финансах.
Исследование представляет собой закономерную эволюцию подхода к интерпретируемости нейронных сетей. Авторы стремятся представить трансформер как единый тензор высшего порядка, что позволяет анализировать его внутреннее устройство с невиданной ранее точностью. Это напоминает попытки создать «чёрный ящик» из стекла, чтобы хоть как-то понять, что в нём происходит. Как заметил Роберт Тарьян: «Программирование — это искусство заставлять машину делать то, что вы хотите». В данном случае, авторы пытаются заставить модель «показать», как она работает, выстраивая её в понятную структуру. Хотя, конечно, всегда найдётся способ сломать даже самую элегантную теорию, нагрузив модель данными, которые она не видела при обучении. И тогда стеклянный ящик снова станет чёрным.
Что Дальше?
Представление трансформера как тензора высшего порядка — элегантное решение, конечно. Но, как показывает опыт, элегантность — это лишь вопрос времени до первого сгоревшего кластера. Эта работа, безусловно, продвигает инструментарий для анализа, но вопрос не в том, что модель делает, а в том, почему она это делает, остаётся открытым. Увеличение порядка тензора не гарантирует понимания — оно лишь увеличивает сложность визуализации и, соответственно, количество потенциальных точек отказа.
Вероятно, следующее поколение исследований сосредоточится на автоматизации процесса интерпретации этих тензоров. Простые «проходки внимания» (attention rollout) уже не удовлетворяют — требуется не просто выявить активные паттерны, но и связать их с конкретными функциями модели. Впрочем, не стоит забывать: каждая новая «интерпретация» — это ещё один слой абстракции, ещё одна возможность ошибиться. Иначе говоря, мы не приближаемся к пониманию — мы просто создаём более сложные легенды к чёрному ящику.
В конечном итоге, TensorLens — это ещё один шаг к более глубокому пониманию трансформеров. Но, как и все подобные инструменты, он не решает проблему полностью. Скорее, он лишь продлевает страдания продакшена, позволяя нам немного дольше откладывать неизбежное переписывание кода. И это, в общем-то, неплохо. Пока работает — работает.
Оригинал статьи: https://arxiv.org/pdf/2601.17958.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Квантовый скачок в обработке радиоастрономических данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-27 20:48