Автор: Денис Аветисян
Новое исследование выявило серьезные проблемы в проведении и отчетности экспериментов по предсказанию дефектов программного обеспечения с использованием машинного обучения.

Аудит 101 недавнего исследования показал широкое распространение проблем с дизайном экспериментов, отчетностью и воспроизводимостью результатов.
Несмотря на широкое применение алгоритмов машинного обучения для предсказания дефектов программного обеспечения, надежность полученных результатов напрямую зависит от качества экспериментальной методологии и отчетности. В данной работе, ‘An Audit of Machine Learning Experiments on Software Defect Prediction’, представлен анализ 101 недавнего исследования в этой области, выявивший значительные различия в подходах к проектированию экспериментов, статистическому анализу и представлению результатов. Основной вывод заключается в том, что почти половина изученных работ содержит недостаточно деталей для воспроизведения, что ставит под сомнение достоверность опубликованных выводов. Какие шаги необходимы для повышения прозрачности и надежности исследований в области предсказания дефектов программного обеспечения и обеспечения воспроизводимости полученных результатов?
Прогнозирование дефектов: Между теорией и суровой реальностью
Прогнозирование дефектов программного обеспечения (SDP) играет ключевую роль в обеспечении высокого качества конечного продукта, однако эта задача сопряжена с рядом фундаментальных трудностей. Эффективное выявление потенциальных ошибок на ранних стадиях разработки позволяет существенно снизить затраты на исправление, повысить надежность и улучшить пользовательский опыт. Тем не менее, сложность заключается в динамичном характере программных проектов, разнообразии типов дефектов и необходимости анализа огромных объемов данных. Кроме того, точность прогнозирования часто ограничена неполнотой информации о проекте, субъективностью оценок и постоянным изменением кода. Успешное применение методов SDP требует комплексного подхода, включающего выбор подходящих метрик, алгоритмов машинного обучения и стратегий валидации, а также постоянного мониторинга и адаптации к меняющимся условиям разработки.
В области прогнозирования дефектов программного обеспечения серьезную проблему представляет собой дисбаланс данных — ситуация, когда количество дефектных компонентов значительно уступает количеству корректно функционирующих. Это несоответствие создает трудности для алгоритмов машинного обучения, поскольку они склонны отдавать предпочтение преобладающему классу (недефектным компонентам), игнорируя редкие, но критически важные дефекты. В результате, модели могут демонстрировать высокую общую точность, но при этом плохо обнаруживать реальные ошибки в коде. Для решения этой проблемы исследователи применяют различные методы, такие как передискретизация (oversampling) миноритарного класса, недодискретизация (undersampling) мажоритарного класса, а также алгоритмы, специально разработанные для работы с несбалансированными данными, например, алгоритмы, взвешивающие ошибки классификации.
Репозиторий Promise, широко используемый в качестве эталонного набора данных для оценки методов прогнозирования дефектов программного обеспечения, несмотря на свою популярность, зачастую оказывается источником проблем с воспроизводимостью исследований. Несмотря на то, что репозиторий предоставляет стандартизированные данные, различия в используемых инструментах, параметрах конфигурации, а также подходах к предварительной обработке данных приводят к существенным расхождениям в полученных результатах. Это создает трудности для сравнительного анализа эффективности различных методов прогнозирования и затрудняет объективную оценку прогресса в данной области. Более того, отсутствие четкой документации и стандартизации процесса воспроизведения экспериментов усугубляет проблему, требуя от исследователей значительных усилий для обеспечения надежности и валидности полученных результатов. Необходимость повышения прозрачности и стандартизации в использовании репозитория Promise является критически важной для обеспечения достоверности и сопоставимости исследований в области прогнозирования дефектов программного обеспечения.
Статистическая строгость: Между желаемым и действительным
В рамках проведенного вычислительного эксперимента для оценки достоверности полученных результатов применялось статистическое тестирование значимости. Данный подход позволил количественно определить вероятность получения наблюдаемых результатов при отсутствии реальной связи между исследуемыми переменными. Использовались стандартные статистические тесты, такие как t-тест и ANOVA, с целью проверки гипотез о различиях между группами и корреляциях между признаками. Уровень значимости был установлен на отметке 0.05, что означает, что вероятность ложноположительного результата (ошибки первого рода) составляет 5%. Принятие или отклонение нулевых гипотез основывалось на p-значениях, полученных в ходе тестирования.
Традиционные метрики, такие как F1-мера, демонстрируют неустойчивость при работе с несбалансированными наборами данных. Это связано с тем, что F1-мера является гармоническим средним точности и полноты, и в ситуациях, когда один класс значительно преобладает над другим, даже небольшое изменение в классификации преобладающего класса может существенно влиять на итоговое значение F1-меры, вводя в заблуждение относительно реальной эффективности модели. В результате, высокая F1-мера может быть достигнута за счет правильной классификации преобладающего класса, в то время как модель может быть неэффективна в определении редкого, но важного класса. Это делает F1-меру непригодной для оценки производительности моделей в задачах, где важна корректная классификация всех классов, особенно редких.
В задачах классификации, особенно при работе с несбалансированными наборами данных, традиционные метрики, такие как F1-мера, могут давать искаженные результаты и не отражать истинную эффективность модели. Для более точной оценки предсказательной силы рекомендуется использовать метрики, устойчивые к дисбалансу классов. AUC (Area Under the Curve), или площадь под ROC-кривой, оценивает способность модели различать классы, не завися от выбранного порога классификации. MCC (Matthews Correlation Coefficient) является коэффициентом корреляции между фактическими и предсказанными значениями, который учитывает все четыре возможные комбинации истинных и предсказанных классов, что делает его особенно полезным при работе с несбалансированными данными и позволяет избежать оптимизации только по преобладающему классу.
Для контроля за ложным уровнем обнаружения (False Discovery Rate, FDR) в ходе проведения множественных статистических сравнений был применен метод Бенджамини-Хохберга. Данный метод позволяет корректировать p-значения, полученные в результате каждого теста, с целью уменьшения вероятности получения ложноположительных результатов. В отличие от более строгой коррекции Бонферрони, процедура Бенджамини-Хохберга обеспечивает большую статистическую мощность, особенно при большом количестве проводимых тестов, сохраняя при этом приемлемый уровень контроля над ошибками первого рода. Процедура включает в себя упорядочивание p-значений по возрастанию и сравнение каждого p-значения с пороговым значением, зависящим от его ранга и общего числа тестов. Применение метода Бенджамини-Хохберга позволило повысить надежность полученных результатов и снизить вероятность ошибочных выводов.
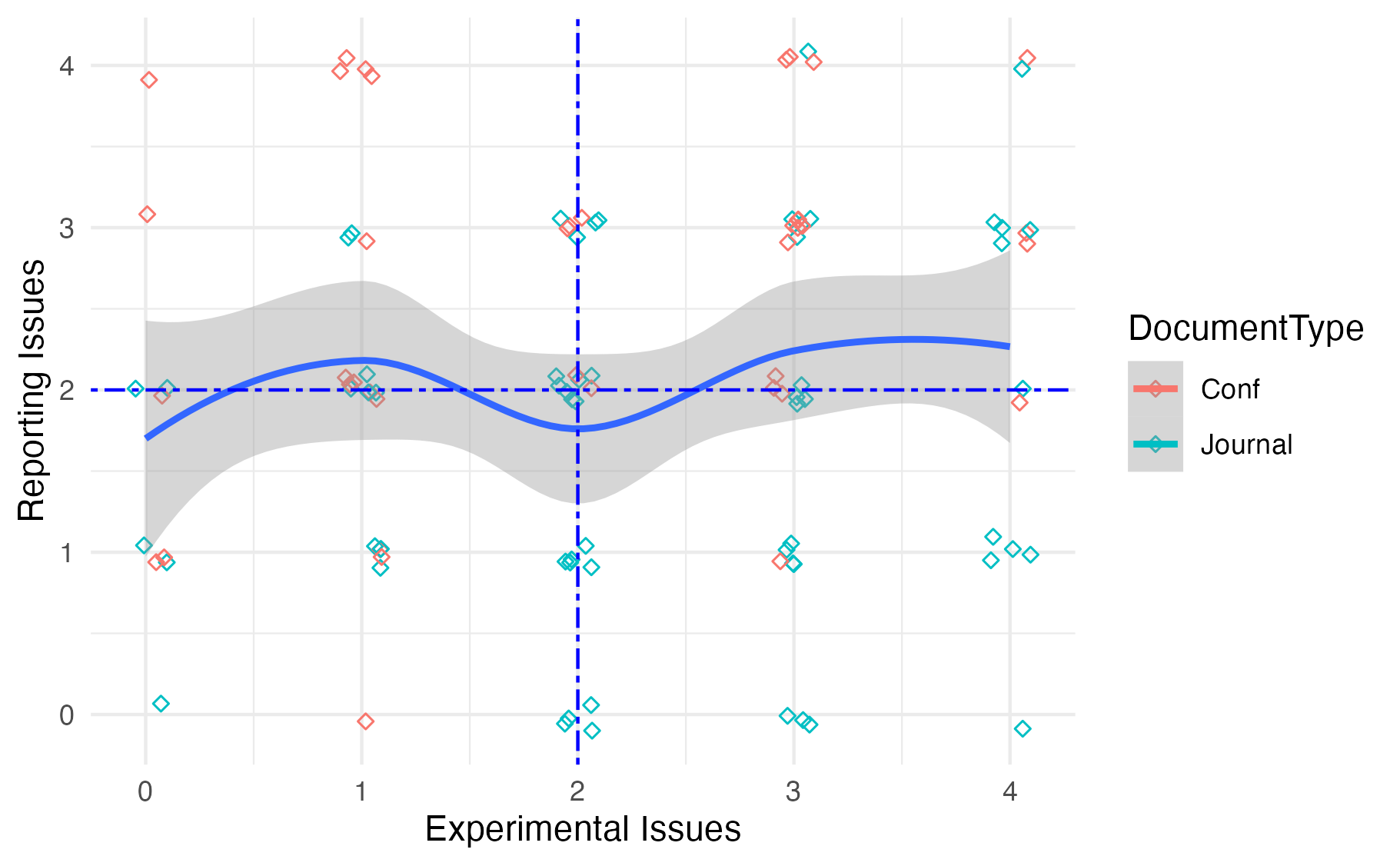
Воспроизводимость исследований: Когда благие намерения тонут в хаосе методологии
Для оценки воспроизводимости опубликованных исследований в области прогнозирования дефектов программного обеспечения (SDP) был проведен анализ воспроизводимости. В рамках данного анализа систематически оценивалась возможность повторения результатов, используя инструмент ‘González-Barahona & Robles Instrument’. Данный инструмент позволяет проводить стандартизированную оценку воспроизводимости, основываясь на четко определенных критериях, что обеспечивает объективность и сравнимость результатов оценки для различных исследований в области SDP. Использование данного инструмента позволило выявить проблемные области в методологии и отчетности, влияющие на возможность воспроизведения результатов исследований.
В ходе исследования были выявлены случаи “Paper Mill Activity” — публикации низкокачественных или сфабрикованных исследований — в литературе по прогнозированию дефектов программного обеспечения (SDP). Данное явление характеризуется массовой генерацией статей с минимальным научным вкладом, часто с использованием поддельных или скомпрометированных данных, и направлено на искусственное увеличение числа публикаций и, как следствие, повышение показателей цитируемости авторов и организаций. Выявленные случаи указывают на необходимость усиления контроля качества публикаций и разработки механизмов выявления и пресечения подобных практик в научной среде.
Для обеспечения полноты обзора релевантных исследований в области предсказания дефектов программного обеспечения была использована база данных Scopus. Scopus является крупнейшей базой данных аннотированных цитирований и рефератов, предоставляющей широкий охват научной литературы. Выбор Scopus обусловлен ее широким охватом публикаций в области компьютерных наук и возможностью проведения комплексного поиска по ключевым словам и параметрам, что позволило идентифицировать 101 исследование для последующего анализа на предмет воспроизводимости и качества проведения эксперимента.
Аудит 101 исследования в области предсказания дефектов программного обеспечения выявил распространенные проблемы с качеством. Медианное значение количества выявленных проблем составило 4 на одну статью, что указывает на необходимость улучшения методологии эксперимента и практик отчетности в данной области. Из проанализированных работ только одна статья не содержала каких-либо выявленных проблем, что подчеркивает масштаб существующей проблемы с воспроизводимостью и надежностью исследований в данной области.
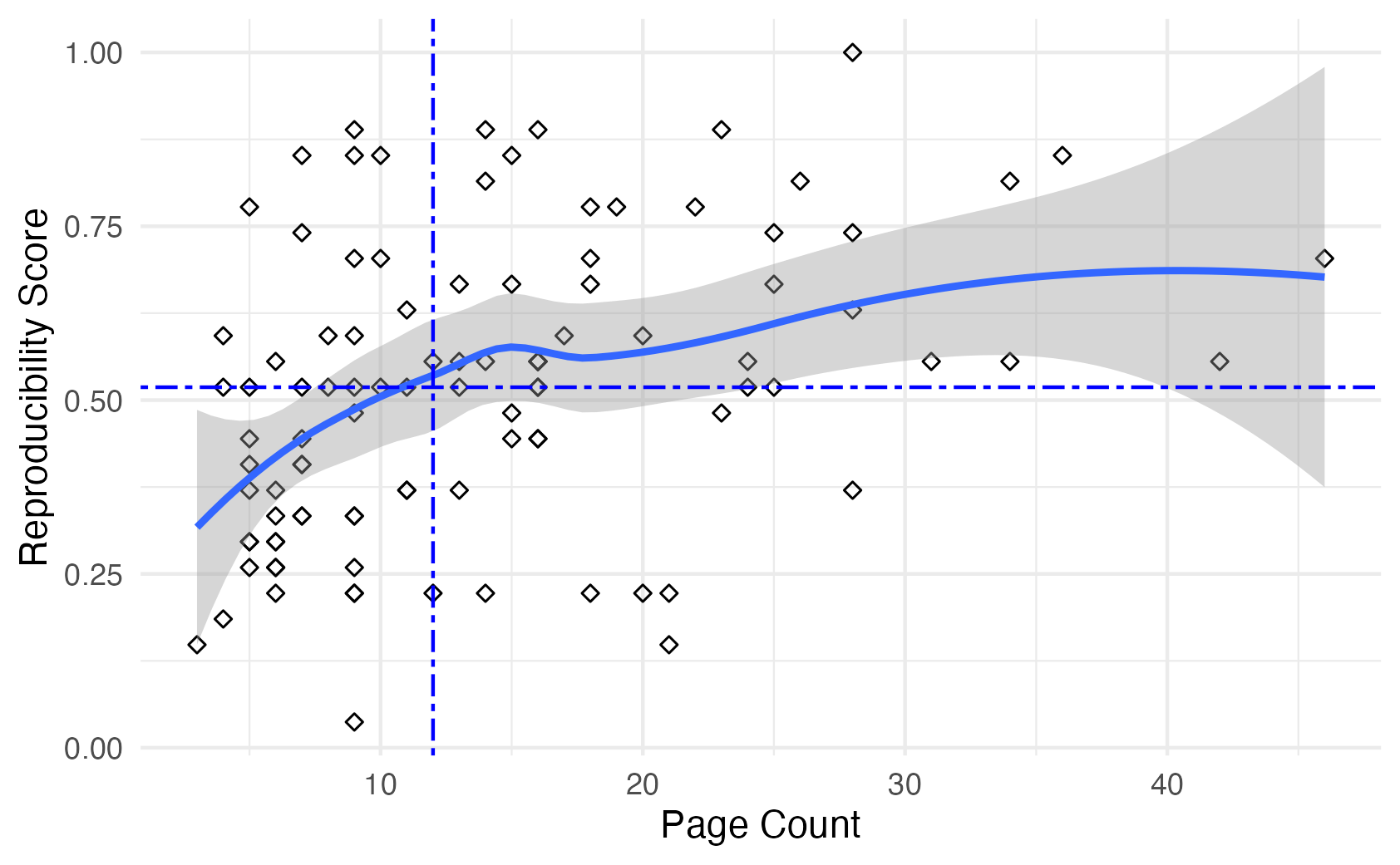
За горизонтом стандартных бенчмарков: Продвинутые стратегии прогнозирования
Исследование продемонстрировало значительный потенциал межпроектного прогнозирования для повышения обобщающей способности и устойчивости моделей прогнозирования дефектов в разработке программного обеспечения. Вместо обучения на данных одного конкретного проекта, модели обучались на совокупности данных из нескольких проектов, что позволило им выявлять более общие закономерности, связанные с возникновением дефектов. Такой подход особенно полезен в ситуациях, когда данных в рамках отдельного проекта недостаточно для построения надежной модели, или когда необходимо прогнозировать дефекты в новых, ранее не встречавшихся проектах. Использование данных из разных проектов способствует созданию моделей, менее подверженных переобучению и более способных к адаптации к новым условиям, что в конечном итоге повышает эффективность процесса разработки и снижает затраты на исправление ошибок.
Исследования показали, что использование методов прогнозирования “точно в срок” (JIT) значительно повышает точность выявления дефектов программного обеспечения. В основе этой стратегии лежит анализ данных, упорядоченных во времени, что позволяет учитывать эволюцию проекта и изменения в кодовой базе. Вместо использования усредненных данных за весь период разработки, JIT-прогнозирование фокусируется на самых актуальных данных, отражающих текущее состояние проекта. Такой подход позволяет модели более эффективно адаптироваться к изменениям и предсказывать дефекты на ранних стадиях разработки, что особенно важно для динамично развивающихся проектов. Анализ временных рядов, входящий в состав JIT-прогнозирования, позволяет выявлять закономерности и тренды, которые невозможно обнаружить при использовании традиционных методов.
Анализ подтверждает, что использование данных из нескольких проектов в сочетании с учётом временной информации значительно повышает надёжность моделей предсказания дефектов программного обеспечения. Вместо того чтобы ограничиваться данными одного проекта, исследование показало, что обучение модели на разнообразном наборе проектов позволяет ей лучше обобщать и выявлять закономерности, применимые к новым, ранее не встречавшимся случаям. Более того, учёт временной последовательности изменений в коде позволяет выявить тенденции и предвидеть потенциальные проблемы, которые могли бы остаться незамеченными при статическом анализе. Это особенно важно для выявления дефектов, которые проявляются со временем или связаны с эволюцией кодовой базы, что в конечном итоге приводит к более точным и полезным моделям предсказания.
Для оценки эффективности разработанных моделей прогнозирования дефектов и предотвращения переобучения использовался метод кросс-валидации. Данный подход предполагает разделение исходного набора данных на несколько подмножеств, последовательную тренировку модели на части данных и проверку её производительности на оставшейся, неиспользованной ранее части. Многократное повторение этой процедуры с различными комбинациями обучающих и тестовых подмножеств позволяет получить более надежную и объективную оценку способности модели обобщать полученные знания и корректно работать с новыми, ранее не встречавшимися данными. Кросс-валидация, таким образом, является ключевым инструментом для обеспечения достоверности и практической применимости моделей прогнозирования, гарантируя, что полученные результаты не являются случайными или обусловленными особенностями конкретного набора данных.
Аудит ста с лишним исследований в области предсказания дефектов программного обеспечения выявил закономерную картину: блестящие теоретические построения неизбежно сталкиваются с суровой реальностью реализации. Как отмечал Давид Гильберт: «В математике нет трамплина». Этот принцип, к сожалению, применим и к эмпирической разработке программного обеспечения. Исследователи часто демонстрируют статистическую значимость результатов, не уделяя достаточного внимания воспроизводимости экспериментов. В конечном итоге, это приводит к накоплению технического долга в области знаний, где каждая новая «инновация» оказывается лишь переупакованной версией старых проблем. Вместо стремления к архитектурным изыскам, возможно, стоит сосредоточиться на базовой надёжности экспериментальной методологии.
Что дальше?
Аудит, представленный в данной работе, выявил закономерности, которые, откровенно говоря, не удивляют человека, повидавшего несколько «революций» в области разработки программного обеспечения. Каждая новая методика предсказания дефектов, каждое «cloud-native» решение — это, по сути, переупакованная старая проблема. Недостаток воспроизводимости, неполнота отчётности, ошибки в статистическом анализе — это не провалы отдельных исследователей, а системная ошибка всей дисциплины. Если система стабильно падает, значит, она хотя бы последовательна.
Будущие исследования, вероятно, сосредоточатся на автоматизации проверки воспроизводимости, создании более строгих стандартов отчётности и, возможно, даже на разработке инструментов, способных выявлять статистические манипуляции. Однако, не стоит питать иллюзий: проблемы не в инструментах, а в людях. Мы не пишем код — мы просто оставляем комментарии будущим археологам, которые будут пытаться понять, почему мы так делали.
В конечном счёте, успех в области предсказания дефектов, вероятно, будет зависеть не от сложности алгоритмов, а от способности признать, что идеального решения не существует. Попытки создать «самообучающуюся» систему, способную предсказывать все возможные ошибки, обречены на провал. Лучшее, на что можно надеяться, — это создать систему, которая будет предсказывать достаточно ошибок, чтобы оправдать её стоимость и сложность. И, возможно, научиться смириться с тем, что некоторые ошибки всё равно останутся.
Оригинал статьи: https://arxiv.org/pdf/2601.18477.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Квантовый скачок в обработке радиоастрономических данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-27 20:55