Автор: Денис Аветисян
Новая методика позволяет создавать аргументированные ответы на замечания рецензентов, используя возможности больших языковых моделей.
Представлен фреймворк DRPG (Декомпозиция, Поиск, Планирование, Генерация) для автоматического формирования качественных ответов на академические рецензии.
Несмотря на растущую роль больших языковых моделей в научных исследованиях, автоматическая поддержка процесса подготовки ответов на рецензии, критически важного этапа академической коммуникации, остается слабо изученной. В настоящей работе представлена система DRPG (Decompose, Retrieve, Plan, Generate) — агентский фреймворк для автоматической генерации аргументированных ответов на рецензии, функционирующий посредством последовательного разложения замечаний, поиска релевантных доказательств, планирования стратегии ответа и генерации текста. Эксперименты на данных ведущих конференций показали, что DRPG значительно превосходит существующие подходы и достигает результатов, превышающих средний человеческий уровень, используя лишь модель с 8 миллиардами параметров. Может ли предложенный фреймворк DRPG стать эффективным инструментом для повышения качества академических дискуссий и оптимизации процесса рецензирования?
Вызов Длинного Рассуждения: Предел Возможностей Языковых Моделей
Научные статьи представляют собой серьезное испытание для больших языковых моделей (БЯМ) из-за их объема и сложности. В отличие от коротких текстов, требующих лишь поверхностного понимания, анализ академических работ предполагает глубокое осмысление взаимосвязанных аргументов, методологий и результатов. БЯМ часто испытывают трудности с удержанием в памяти и эффективной обработкой большого количества информации, представленной в длинных документах. Это проявляется в снижении точности при ответах на вопросы, требующие синтеза информации из разных частей статьи, и в неспособности выявить ключевые взаимосвязи между отдельными идеями. Таким образом, способность БЯМ эффективно работать с научными текстами является важным показателем их общего интеллектуального уровня и потенциала для применения в научных исследованиях.
Исследования показывают, что большие языковые модели (LLM) сталкиваются с существенными трудностями при обработке длинных текстов, проявляющимися в так называемом “эффекте потери в середине”. Данное явление заключается в том, что модели демонстрируют снижение точности и способности к извлечению информации из центральных частей объемных документов, в то время как информация в начале и конце текста обрабатывается более эффективно. Это не связано с фактической потерей данных, а скорее с особенностями архитектуры и механизмов внимания LLM, которые отдают предпочтение информации, расположенной ближе к началу и концу входной последовательности. В результате, критически важные детали и аргументы, находящиеся в середине длинных академических статей или отчетов, могут быть упущены из виду, что существенно снижает способность модели к комплексному анализу и синтезу информации.
Ограниченность контекстного окна больших языковых моделей (LLM) представляет собой существенную проблему при анализе длинных текстов. Данное ограничение, известное как «Вызов длинного контекста», препятствует способности модели эффективно обрабатывать информацию, расположенную на значительном расстоянии друг от друга в документе. Поскольку LLM способны учитывать лишь определенный объем текста одновременно, важные детали и связи, находящиеся за пределами этого окна, могут быть упущены из виду, что приводит к неполному или искаженному пониманию. Это особенно критично в академических работах, где аргументы и доказательства часто разворачиваются на протяжении всего текста, требуя от модели удержания и сопоставления информации из различных частей документа для формирования целостной картины.
DRPG: Декомпозируемый Подход к Генерации Опровержений
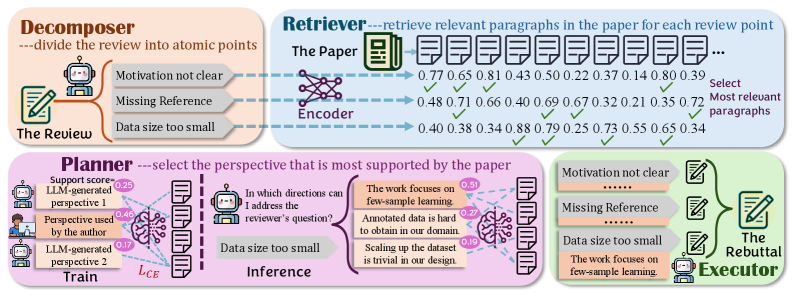
В основе фреймворка DRPG лежит новый подход к автоматической генерации опровержений, заключающийся в декомпозиции сложных отзывов на отдельные, управляемые пункты. Вместо обработки отзыва как единого целого, система разделяет его на конкретные утверждения и аргументы, что позволяет более точно и эффективно формировать ответные действия. Данная декомпозиция облегчает процесс поиска релевантной информации и планирования структуры опровержения, повышая общую эффективность системы и позволяя ей обрабатывать отзывы различной сложности и объема.
Архитектура DRPG (Decomposable Review Processing) основана на модульном агентном подходе, где каждый компонент выполняет специфическую функцию в процессе генерации опровержений. Ключевые модули включают в себя ‘Decomposer’ (Декомпозитор), разбивающий исходный отзыв на отдельные пункты для анализа; ‘Retriever’ (Извлекатель), отвечающий за поиск релевантной информации; ‘Planner’ (Планировщик), определяющий стратегию опровержения, и ‘Executor’ (Исполнитель), который формирует итоговый текст опровержения. Взаимодействие между этими модулями обеспечивает систематическую обработку каждого пункта отзыва, позволяя автоматизировать процесс генерации аргументированных ответов.
Компонент ‘Retriever’ в рамках DRPG использует метод ‘Dense Retrieval’ для значительного сокращения объема входных данных. Этот метод позволяет отбирать только наиболее релевантные абзацы из исходного текста, что приводит к снижению длины входных данных на 75%. Параллельно, компонент ‘Planner’ демонстрирует высокую точность — 98.64% — в определении точки зрения, используемой в эффективных, созданных человеком, опровержениях. Такой подход обеспечивает более эффективную обработку и генерацию аргументированных ответов на критические замечания.
Оценка Качества Опровержений с Помощью Модели “Судья”
Модель “Судья” (Judge Model) является ключевым компонентом в оценке качества сгенерированных ответов на замечания рецензентов, выступая в роли прокси для работы человека-эксперта. Она позволяет автоматизировать процесс оценки, заменяя трудоемкий анализ, выполняемый людьми, машинным анализом. Это достигается за счет обучения модели на большом объеме данных, что позволяет ей предсказывать качество ответа, аналогично оценке, которую дал бы человек. Использование модели “Судья” повышает эффективность и масштабируемость процесса оценки, позволяя быстро анализировать большое количество ответов и выявлять наиболее эффективные стратегии для решения замечаний.
Модель “Судья” обучается с использованием алгоритма ‘Group Relative Policy Optimization’ (GRPO), обеспечивающего устойчивость и надежность оценки. GRPO — это метод обучения с подкреплением, который оптимизирует политику модели, сравнивая ее производительность с группой других политик. Этот подход позволяет модели более эффективно различать качественные и некачественные опровержения, поскольку она учится не просто максимизировать абсолютную оценку, а превосходить другие модели в решении поставленной задачи. Использование GRPO позволяет добиться стабильных результатов и высокой степени согласованности оценок, что критически важно для автоматизированной оценки качества генерируемых опровержений.
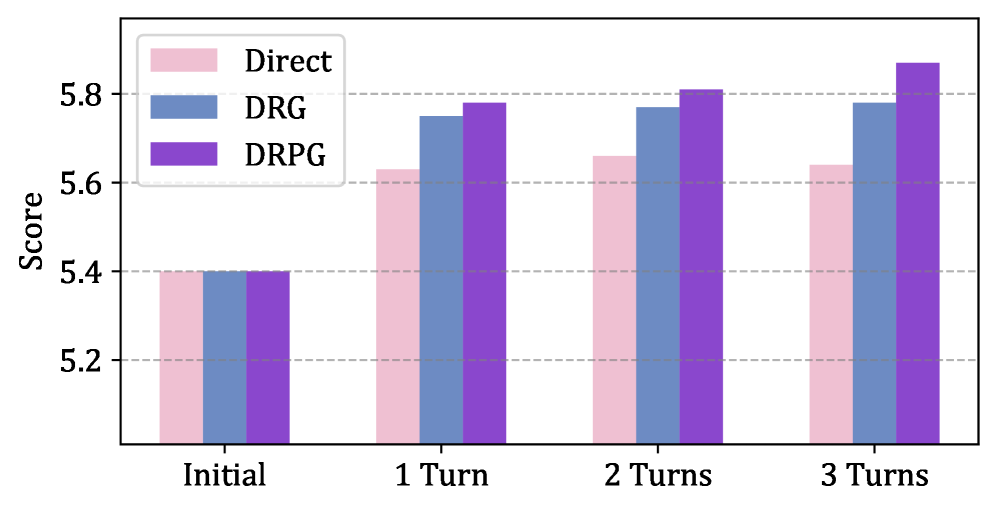
Для оценки качества генерируемых ответов на замечания рецензентов используется метрика Elo Score. В ходе экспериментов модель DRPG показала результат на 40 пунктов выше, чем существующие системы обработки замечаний, что свидетельствует о более высокой вероятности успешного разрешения вопросов, поднятых рецензентами. Кроме того, Judge Model демонстрирует значительное совпадение с оценками, данными людьми-аннотаторами, подтверждая её надежность и корреляцию с человеческим восприятием качества ответа.
DRPG Превосходит Базовые Методы: Новая Эра в Научной Дискуссии
Система DRPG демонстрирует значительное превосходство над подходом “Jiu-Jitsu Baseline”, который ограничен использованием заранее заданных шаблонов. В отличие от него, DRPG использует более сложную агентурную архитектуру, позволяющую ей генерировать ответы, адаптированные к конкретным аргументам и контексту. В то время как “Jiu-Jitsu Baseline” полагается на жесткие структуры, DRPG способна к динамической адаптации и созданию более убедительных опровержений, что делает её более эффективным инструментом для анализа и улучшения качества научных дискуссий. Такая гибкость позволяет DRPG преодолевать ограничения, присущие шаблонным подходам, и обеспечивать более глубокое и нюансированное понимание сложных аргументов.
В основе системы DRPG лежит сложная агентная архитектура, позволяющая генерировать более тонкие и убедительные опровержения, чем в традиционных подходах. Автоматизированная оценка, встроенная в систему, позволяет непрерывно совершенствовать качество генерируемых ответов, что подтверждается впечатляющим результатом — повышение рейтинга Elo на 40 пунктов по сравнению с существующими методами. Этот значительный прогресс демонстрирует способность DRPG не просто реагировать на аргументы, но и формировать убедительные контраргументы, открывая новые возможности для оптимизации процесса научной публикации и повышения качества научной дискуссии.
Улучшение, продемонстрированное системой DRPG, имеет далеко идущие последствия для упрощения процесса академического опубликования и повышения качества научной дискуссии. Автоматизация формирования более убедительных аргументов и опровержений позволяет значительно сократить время, затрачиваемое на рецензирование и редактирование научных работ. Это, в свою очередь, способствует более быстрому распространению новых знаний и повышению общей эффективности научного сообщества. Повышение качества дискуссии достигается за счет более тщательной проработки аргументации, что способствует выявлению слабых мест в исследованиях и стимулирует более глубокий анализ представленных данных. В перспективе, подобные системы могут стать незаменимым инструментом для поддержания высоких стандартов научной публикации и обеспечения достоверности научных результатов.
Представленная работа демонстрирует подход к автоматизации процесса ответов на рецензии, что особенно актуально в современной научной среде, перегруженной информацией. Этот фреймворк DRPG, разбивающий задачу на последовательные этапы — разложение, поиск, планирование и генерацию — напоминает о фундаментальной сложности систем. Как однажды заметил Джон фон Нейманн: «В науке нет готовых ответов, есть лишь более точные вопросы». Подобно тому, как DRPG стремится к более точным ответам на критические замечания, система, описанная в статье, демонстрирует стремление к оптимизации процесса обработки информации во времени, а не просто к её хранению. Эффективное планирование и извлечение релевантной информации, ключевые компоненты DRPG, позволяют системе адаптироваться к меняющимся условиям и поддерживать свою функциональность в течение длительного времени.
Что дальше?
Представленная работа, как и любая попытка автоматизировать интеллектуальный труд, лишь обнажает глубину нерешенных вопросов. Система DRPG, безусловно, демонстрирует потенциал в оптимизации процесса ответов на рецензии, но её истинная ценность не в скорости, а в возможности зафиксировать эволюцию аргументации. Каждая задержка в принятии окончательного решения — это цена углубленного понимания, а архитектура без истории, как известно, хрупка и скоротечна.
Очевидным направлением для дальнейших исследований представляется выход за рамки формального ответа на замечания рецензентов. Система должна стремиться к выявлению скрытых предпосылок, неявных противоречий и, возможно, даже предубеждений, лежащих в основе критики. Вопрос не в том, чтобы просто «отбиться» от замечаний, а в том, чтобы способствовать конструктивному диалогу и, в конечном итоге, повысить качество научной работы.
И, конечно, необходимо помнить, что любые автоматизированные системы, даже самые совершенные, — это лишь инструменты. Их эффективность напрямую зависит от качества исходных данных и критического осмысления полученных результатов. В конечном счете, старение любой системы неизбежно, вопрос лишь в том, делает ли она это достойно, оставляя после себя не только оптимизированные процессы, но и ценный опыт для будущих поколений исследователей.
Оригинал статьи: https://arxiv.org/pdf/2601.18081.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Квантовый скачок в обработке радиоастрономических данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-27 22:16