Автор: Денис Аветисян
В статье представлена обобщенная платформа для оценки предсказания эффективности запросов, учитывающая как сами запросы, так и используемые модели ранжирования.
Исследование показывает, что предсказать наилучшую модель ранжирования для конкретного запроса сложнее, чем определить сложность самого запроса для фиксированной модели.
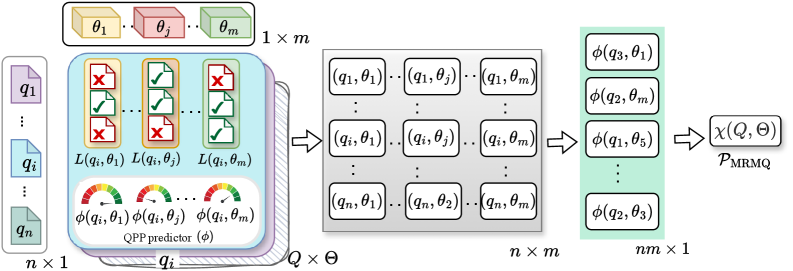
Традиционные подходы к предсказанию производительности запросов (QPP) часто фокусируются на оценке самих запросов, упуская из виду важность выбора оптимальной модели ранжирования. В данной работе, представленной под названием ‘Breaking Flat: A Generalised Query Performance Prediction Evaluation Framework’, предложена обобщенная схема оценки QPP, рассматривающая три сценария взаимодействия запросов и моделей ранжирования. Полученные результаты показывают, что предсказание наиболее эффективной модели ранжирования для конкретного запроса значительно сложнее, чем оценка сложности самого запроса для заданной модели. Какие новые метрики и подходы могут быть разработаны для более точной оценки QPP в условиях разнообразия моделей ранжирования и типов запросов?
Точность предсказаний: ключ к эффективному поиску
Точная оценка производительности запросов играет ключевую роль в эффективном извлечении информации, оказывая непосредственное влияние на пользовательский опыт и масштабируемость системы. Задержки в обработке запросов напрямую коррелируют с неудовлетворенностью пользователей, что может привести к снижению лояльности и переходу к конкурентам. Кроме того, возможность прогнозировать время выполнения запросов позволяет оптимизировать распределение ресурсов, избегая перегрузок и обеспечивая стабильную работу системы даже при пиковых нагрузках. Таким образом, совершенствование методов предсказания производительности запросов является не просто технической задачей, но и важным фактором, определяющим конкурентоспособность и успешность современных информационно-поисковых систем.
Традиционные методы предсказания производительности поисковых запросов сталкиваются со значительными трудностями при работе с современной сложностью ранжирующих моделей и разнообразием характеристик запросов. Устаревшие подходы, как правило, не учитывают тонкие взаимодействия между многочисленными факторами, влияющими на ранжирование, включая семантическое содержание запроса, сложность используемых алгоритмов и особенности индексации данных. Это приводит к неточностям в прогнозировании времени выполнения запроса и, как следствие, к неоптимальному распределению ресурсов системы. В частности, модели, разработанные для более простых систем, часто не способны адекватно оценить влияние новых, более сложных признаков и алгоритмов машинного обучения, используемых в современных поисковых системах. Неточное предсказание производительности не только ухудшает пользовательский опыт, но и препятствует масштабируемости и эффективности всей системы поиска.
В связи со сложностью современных систем поиска и разнообразием запросов пользователей, возникает потребность в разработке более надежных и адаптивных методов прогнозирования производительности запросов (QPP). Традиционные подходы зачастую оказываются неэффективными, поскольку не учитывают тонкости, связанные с современными моделями ранжирования и динамически меняющимися характеристиками запросов. Новые QPP-техники должны обладать способностью к самообучению и адаптации к различным типам запросов, а также учитывать контекст поиска и индивидуальные предпочтения пользователей. Разработка таких методов позволит значительно повысить эффективность информационного поиска, улучшить пользовательский опыт и обеспечить масштабируемость поисковых систем, что особенно важно в условиях постоянно растущего объема данных и увеличивающейся нагрузки.

Неконтролируемые методы оценки качества ранжирования
Несколько методов неконтролируемой оценки качества ранжирования (QPP) используют внутренние свойства функций ранжирования, такие как дисперсия оценок (NQC, sigmaMax) и агрегированный прирост информации (WIG). Метод NQC (Normalized Quantile Discount) оценивает качество ранжирования, основываясь на нормализованной квантильной скидке, вычисляемой на основе дисперсии оценок релевантности. SigmaMax использует максимальную дисперсию оценок для определения качества ранжирования, предполагая, что более высокая дисперсия указывает на более эффективное разделение релевантных и нерелевантных документов. WIG (Weighted Information Gain) агрегирует прирост информации, полученный при перемещении релевантных документов вверх в ранжированном списке, для оценки качества ранжирования. Эти подходы позволяют оценить качество без использования размеченных данных, что делает их привлекательными в ситуациях, когда размеченные данные недоступны или их получение дорогостояще.
Неконтролируемые методы оценки качества ранжирования (QPP), несмотря на свою вычислительную эффективность, демонстрируют чувствительность к шумам в данных и могут испытывать трудности с обобщением на различные модели ранжирования. Это связано с тем, что они опираются на внутренние свойства функции ранжирования, которые могут сильно варьироваться в зависимости от конкретной модели и набора данных. Наличие выбросов или нерелевантных документов в исходном наборе данных может существенно исказить оценки, полученные такими методами. Кроме того, параметры, оптимальные для одной модели ранжирования, могут быть неэффективны при применении к другой, что снижает переносимость и требует повторной настройки для каждого нового случая.
Методы UEF, RSD и SMV направлены на повышение устойчивости оценки качества ранжирования (QPP) за счет усреднения оценок или рассмотрения подмножеств документов. UEF (Uncertainty Estimation Framework) использует оценку неопределенности для повышения надежности, в то время как RSD (Rank-Sublist Deviation) и SMV (Sublist Maximum Variance) анализируют отклонения и дисперсию в подсписках документов для выявления потенциальных проблем с ранжированием. В задаче Single-Ranker Multi-Query (SRMQ) эти методы демонстрируют высокую производительность, превосходя некоторые подходы, основанные на обучении с учителем, что свидетельствует об их эффективности в условиях ограниченных данных и вычислительных ресурсов.
Контролируемое предсказание QPP и модели на его основе
Методы контролируемого QPP (Query Performance Prediction), такие как NQA-QPP и BERTQPP, используют модели машинного обучения для прогнозирования эффективности запросов. В основе этих методов лежит анализ признаков (features) запросов и их векторных представлений (embeddings). Признаки могут включать статистические данные о запросе, характеристики документов, на которые он ссылается, и информацию о пользователе. Векторные представления, полученные с помощью моделей, таких как BERT, позволяют учитывать семантическое значение запроса и документов. На основе этих данных модель обучения предсказывает метрику эффективности, например, релевантность или вероятность клика, что позволяет оптимизировать ранжирование результатов поиска.
Подходы на основе контролируемого обучения (supervised QPP), такие как NQA-QPP и BERTQPP, демонстрируют повышенную точность предсказания производительности запросов по сравнению с неконтролируемыми методами. Однако, для эффективной работы этих моделей требуется значительный объем размеченных данных, включающих информацию о релевантности результатов поиска для каждого запроса. Процесс ручной разметки данных является трудоемким и требует значительных временных и финансовых затрат, что ограничивает масштабируемость и применимость данных подходов в условиях ограниченных ресурсов или при необходимости быстрой адаптации к новым типам запросов.
Комбинирование моделей предсказания с методами неконтролируемого обучения позволяет повысить точность прогнозирования качества поиска и смягчить проблему нехватки размеченных данных. В задаче Multi-Ranker Single-Query (MRSQ) подходы, основанные на анализе контента, такие как BERT-QPP и DM, демонстрируют более высокую производительность, что указывает на их эффективность в определении оптимальных ранжировщиков для конкретного запроса. Эти модели используют признаки, извлеченные из содержания запроса и документов, для выбора наиболее подходящего ранжировщика из набора доступных, обеспечивая тем самым улучшенные результаты ранжирования.
Оценка методов QPP: метрики и задачи
Для оценки корреляции методов QPP (Query Performance Prediction) с реальной производительностью запросов используются метрики, такие как коэффициент корреляции Кендалла (Kendall’s Tau), средняя точность на первых 50 результатах (AP@50) и нормализованная дисконтированная кумулятивная прибыль на первых 10 результатах (nDCG@10). Коэффициент Кендалла измеряет ранговую корреляцию между предсказанными и фактическими значениями производительности, AP@50 оценивает точность ранжирования первых 50 результатов, а nDCG@10 учитывает релевантность результатов и их позицию в ранжированном списке, дисконтируя менее релевантные результаты, находящиеся ниже в списке. Эти метрики позволяют количественно оценить способность QPP-моделей прогнозировать производительность запросов и сравнивать различные модели между собой.
Для всесторонней оценки методов QPP используются различные типы задач: Single-Ranker Multi-Query (SRMQ), Multi-Ranker Single-Query (MRSQ) и Multi-Ranker Multi-Query (MRSQQ). Задача SRMQ предполагает оценку одного ранжировщика по множеству запросов, что обеспечивает статистическую значимость результатов. Задача MRSQ, напротив, использует несколько ранжировщиков для одного запроса, позволяя оценить их сравнительную эффективность. Наиболее сложной является задача MRSQQ, сочетающая в себе множественные ранжировщики и множественные запросы, что позволяет выявить сильные и слабые стороны методов QPP в различных сценариях и оценить их обобщающую способность. Различия в сложности этих задач позволяют получить более полное представление о производительности и применимости различных методов QPP.
Комбинирование различных задач оценки (Single-Ranker Multi-Query, Multi-Ranker Single-Query, Multi-Ranker Multi-Query) и метрик (например, Tau Кендалла, AP@50, nDCG@10) позволяет провести всестороннюю оценку методов QPP, выявляя их сильные и слабые стороны в различных сценариях. Важно отметить, что корреляция между задачами SRMQ-PP и MRSQ-PP является низкой, что указывает на существенные различия в относительной эффективности QPP-моделей при их решении. Низкая корреляция подчеркивает необходимость проведения оценок, специфичных для каждой задачи, поскольку модель, показывающая хорошие результаты в одной задаче, может оказаться менее эффективной в другой.
Развитие QPP: разнообразные модели ранжирования и за его пределами
Оценка методов QPP (Query Performance Prediction) расширяется на разнообразные модели ранжирования, включая классический BM25, современные SPLADE и ColBERT, а также их комбинации. Такой подход необходим для обеспечения обобщающей способности моделей QPP — то есть, их способности точно предсказывать производительность ранжирования не только для конкретной модели, но и для широкого спектра алгоритмов. Исследователи стремятся создать системы, которые могут адаптироваться к различным архитектурам ранжирования и динамически оптимизировать процесс поиска информации, гарантируя высокую эффективность даже при использовании новых или незнакомых моделей. Использование различных моделей в процессе оценки позволяет выявить наиболее универсальные и надежные методы QPP, способные улучшить качество поиска в различных информационных системах.
Способность точно предсказывать производительность различных моделей ранжирования имеет решающее значение для создания адаптивных систем поиска информации. Такие системы способны динамически выбирать или комбинировать модели ранжирования в зависимости от характеристик запроса и доступных данных. Это позволяет значительно повысить релевантность результатов поиска, особенно в ситуациях, когда ни одна модель не является оптимальной для всех типов запросов. Динамическая оптимизация, основанная на предсказании производительности, позволяет системам автоматически настраивать параметры ранжирования и распределять ресурсы для достижения максимальной эффективности. Исследования в этой области направлены на разработку методов, которые могут эффективно оценивать потенциал различных моделей и быстро адаптироваться к изменяющимся условиям, что открывает возможности для создания интеллектуальных и самообучающихся систем поиска.
Продолжающиеся исследования направлены на преодоление трудностей, связанных с недостатком данных, устойчивостью моделей и возможностью переноса знаний, что открывает путь к созданию более эффективных систем информационного поиска. Полученные результаты, основанные на обобщенной оценочной рамке, демонстрируют, что подходы к QPP, основанные на анализе содержания запроса (BERT-QPP, DM), превосходно предсказывают наиболее эффективные ранжировщики для конкретного запроса. В то же время, методы, анализирующие оценки ранжирования (NQC, RSD), лучше справляются с определением сложности запроса для заданного ранжировщика, что позволяет адаптировать систему под конкретные условия и оптимизировать её работу.
Представленная работа демонстрирует стремление к упрощению оценки производительности поисковых систем. Авторы предлагают обобщенную структуру, позволяющую анализировать как сложность запросов, так и эффективность различных моделей ранжирования. В этой связи вспоминается высказывание Дональда Дэвиса: «Простота — высшая степень совершенства». Действительно, исследование показывает, что предсказание оптимальной модели ранжирования для конкретного запроса представляет собой более сложную задачу, чем определение сложности самого запроса для фиксированной модели. Стремление к ясности в оценке и понимании этих взаимосвязей является ключевым для развития более эффективных информационных систем.
Куда же дальше?
Представленная работа, обнажая сложность предсказания оптимальной модели ранжирования для конкретного запроса, косвенно указывает на предел упрощения. Долгое время усилия в области информационного поиска были направлены на создание универсальных метрик и алгоритмов. Однако, становится очевидным, что истинная эффективность системы определяется не абстрактной «трудностью» запроса или «качеством» модели, а их взаимной, контекстно-зависимой связью. Стремление к единому знаменателю, возможно, лишь заслоняет детали, необходимые для точной настройки.
Будущие исследования, вероятно, должны сместить фокус с обобщенных предсказаний на моделирование этой динамической взаимосвязи. Вместо попыток предсказать абсолютную производительность, представляется более плодотворным поиск методов, позволяющих оценить относительную эффективность различных моделей для данного запроса, учитывая его уникальные характеристики. Ирония заключается в том, что ключ к улучшению производительности может заключаться не в усложнении моделей, а в их более тонкой адаптации.
В конечном счете, задача предсказания производительности запросов — это не столько вопрос машинного обучения, сколько вопрос понимания самой сущности информации и того, как она структурируется в сознании ищущего. Упрощать — значит терять. Остаётся лишь отшлифовать то, что действительно важно.
Оригинал статьи: https://arxiv.org/pdf/2601.17359.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Акустический контроль квантовых точек: за пределами частотного резонанса
- Личность машины: как искусственный интеллект формирует самосознание
- БиоАгент: Проверка ИИ на прочность в мире геномики
- Квантовый скачок: от теории к практике
2026-01-28 01:54