Автор: Денис Аветисян
Новый подход к обработке данных с RGB-D камер позволяет создавать более точные 3D-модели окружения, даже при наличии неполной информации о глубине.

В статье представлен метод Masked Depth Modeling (MDM) для повышения надежности и точности 3D-восприятия, использующий пропущенные измерения глубины в качестве обучающих сигналов.
Несмотря на прогресс в области RGB-D камер, получение точных и полных карт глубины остается сложной задачей, особенно в сложных условиях освещения и при работе с текстурно-однородными поверхностями. В данной работе, озаглавленной ‘Masked Depth Modeling for Spatial Perception’, предлагается новый подход к обучению моделей восприятия глубины, рассматривающий неточности датчиков как сигнал для обучения, а не как шум. Разработанная модель LingBot-Depth использует маскированное моделирование глубины для улучшения карт глубины на основе визуального контекста и автоматизированной системы курирования данных. Может ли подобный подход привести к созданию более надежных и адаптивных систем 3D-восприятия для робототехники и автономного вождения?
Точность Восприятия Глубины: Фундаментальная Проблема Робототехники
Точное восприятие глубины является основополагающим для функционирования роботов в реальном мире, однако получаемые данные RGB-D часто характеризуются неполнотой. Это связано с ограничениями самих сенсоров, а также со сложностями, возникающими при сканировании поверхностей с низкой отражающей способностью или при наличии прозрачных объектов. В результате, значительная часть информации о глубине может быть попросту недоступна, что существенно затрудняет построение полной и корректной трехмерной модели окружения и, как следствие, влияет на эффективность выполнения роботом различных задач, начиная от навигации и заканчивая манипуляциями с объектами.
Существующие методы обработки данных глубины, получаемых с помощью RGB-D сенсоров, сталкиваются со значительными трудностями при работе с неполной информацией о глубине. Отсутствие данных по глубине, вызванное ограничениями сенсоров или свойствами поверхности объектов, приводит к ошибкам в задачах, требующих точного понимания трехмерной структуры окружения. В частности, неточности в определении глубины негативно сказываются на распознавании объектов и манипулировании ими, поскольку робот может неправильно оценивать расстояние до цели или ее форму. Это особенно критично в сложных условиях, таких как захват объектов с глянцевыми или прозрачными поверхностями, где данные о глубине могут быть частично или полностью отсутствовать, что снижает надежность и эффективность роботизированных систем.

Маскированное Моделирование Глубины: Искусство Восстановления Неизвестного
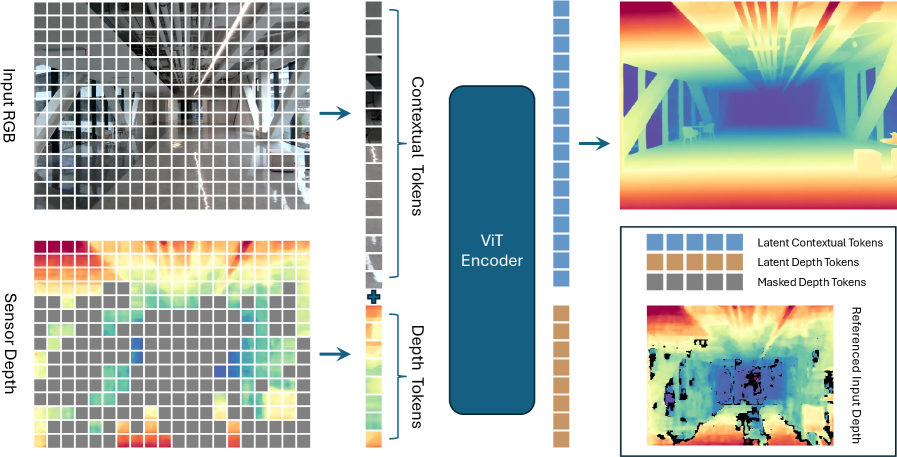
Маскированное моделирование глубины (MDM) представляет собой метод предварительного обучения, в котором намеренно вводятся “маски” в карты глубины. Этот процесс заключается в случайном удалении части информации о глубине из входных данных. В результате модель вынуждена учиться восстанавливать недостающие данные, опираясь на контекст оставшейся информации. Использование замаскированных карт глубины позволяет модели развивать устойчивые представления и эффективно обрабатывать неполные данные, что критически важно для приложений, работающих с реальными данными, где полная информация о глубине часто недоступна.
В основе Masked Depth Modeling (MDM) лежит использование Vision Transformer в качестве кодирующей сети (encoder backbone) для извлечения признаков из RGB-D данных. Vision Transformer позволяет модели эффективно обрабатывать пространственные зависимости между пикселями, преобразуя входное RGB-D изображение в последовательность токенов. Эти токены затем обрабатываются механизмами самовнимания (self-attention), что позволяет сети улавливать контекстные взаимосвязи и формировать богатые представления о глубине сцены. Использование Vision Transformer обеспечивает более эффективное извлечение признаков по сравнению с традиционными сверточными сетями, особенно при работе с неполными данными, что критично для задачи восстановления глубины в MDM.
Декодер ConvStack используется для восстановления полной карты глубины на основе контекстных токенов, полученных от энкодера. Данная архитектура представляет собой последовательность сверточных слоев, предназначенных для постепенного увеличения разрешения и детализации восстановленной карты глубины. Процесс восстановления, называемый заполнением глубины (depth completion), заключается в предсказании значений глубины для замаскированных областей, используя информацию из видимых участков изображения и контекстные признаки, закодированные энкодером. Эффективность ConvStack заключается в его способности эффективно агрегировать локальные и глобальные признаки для точного предсказания глубины в неполных данных.
Эмпирическая Валидация: Повышение Точности Восприятия в Робототехнике
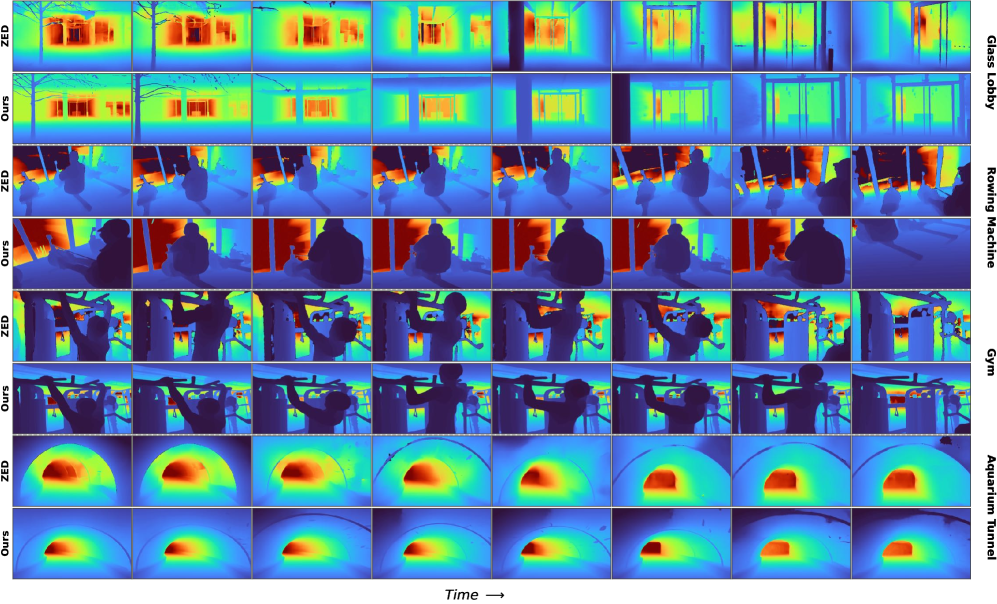
Предварительное обучение с использованием модели MDM, реализованной в LingBot-Depth, демонстрирует значительное повышение производительности в задачах оценки глубины, включая монокулярную оценку глубины и стереосопоставление. LingBot-Depth использует подход, позволяющий улучшить точность оценки глубины, что критически важно для задач, требующих понимания трехмерной структуры окружения. Этот подход обеспечивает более надежные результаты в различных сценариях, включая задачи, где традиционные методы оценки глубины испытывают трудности, например, при работе с плохо освещенными сценами или объектами с недостаточной текстурой. Улучшенная оценка глубины, полученная благодаря предварительному обучению MDM, является ключевым фактором повышения эффективности робототехнических систем в задачах манипулирования и навигации.
Модель LingBot-Depth значительно повышает точность фреймворка стереосопоставления FoundationStereo за счет предоставления надежного априорного значения глубины. В ходе тестирования на наборе данных HAMMER, модель достигла ошибки конечной точки (EPE) в 0.17 на 15 эпохе обучения. Данный показатель свидетельствует о значительном улучшении точности определения глубины и, как следствие, повышении надежности системы стереовидения, используемой в робототехнике.
Точная оценка глубины является критически важным фактором для успешных манипуляций роботами. Модель LingBot-Depth значительно повышает надежность и точность захвата объектов, позволяя осуществлять манипуляции с предметами, которые ранее были недоступны для захвата, например, с прозрачными контейнерами, с вероятностью успеха 50%. Это достигается за счет обеспечения более точной информации о трехмерном окружении, что позволяет роботу планировать и выполнять захваты с большей уверенностью и стабильностью.
В ходе экспериментов было продемонстрировано, что разработанный подход позволяет осуществлять захват объектов, ранее считавшихся недоступными для захвата роботизированными системами, в частности, прозрачных пластиковых контейнеров. Успешность захвата таких объектов составила 50%, что свидетельствует о значительном улучшении возможностей манипулирования для роботов в сложных условиях. Данный показатель был достигнут благодаря повышению точности оценки глубины и улучшенному пониманию геометрии объектов, что критически важно для надежного планирования траектории захвата и предотвращения столкновений.
В ходе тестирования на различных эталонных наборах данных для задачи завершения глубинной карты (depth completion), модель MDM демонстрирует стабильное превосходство над существующими аналогами. В частности, в экстремальных условиях неполноты данных, MDM снижает среднеквадратичную ошибку (RMSE) более чем на 40% на наборах iBims, NYUv2 и DIODE. На наборах ETH-SfM Indoor и Outdoor, улучшения составляют 47% и 38% соответственно, что свидетельствует о высокой эффективности подхода MDM в сложных сценариях с ограниченным объемом входных данных.
Создание Надежного Конвейера: От Данных к Манипуляциям
Для эффективной тренировки и оценки моделей манипулирования (MDM) необходим комплексный конвейер обработки данных. Он предполагает использование как реальных данных, полученных из сенсоров, так и синтетических данных RGB-D. Реальные данные, хотя и ценны, часто ограничены в разнообразии и объеме, что может приводить к переобучению модели и снижению её способности к обобщению. Синтетические данные, напротив, позволяют генерировать неограниченное количество сценариев и вариаций, восполняя пробелы в реальных данных. Комбинирование этих двух источников позволяет создать надежную и всестороннюю базу для обучения, обеспечивая высокую производительность и устойчивость MDM в различных условиях и задачах. Такой подход к подготовке данных критически важен для достижения надежного восприятия и управления роботами в реальном мире.
Для повышения обобщающей способности моделей машинного обучения, особенно в задачах, связанных с восприятием и манипулированием объектами, активно используются синтетические данные. Метод Semi-Global Matching (SGM) позволяет генерировать реалистичные карты глубины, которые дополняют реальные данные, полученные с датчиков. Такое сочетание позволяет обучать модели на более разнообразном наборе данных, что особенно важно в ситуациях, когда получение достаточного количества реальных данных затруднено или дорогостояще. Использование синтетических данных, сгенерированных с помощью SGM, позволяет модели лучше адаптироваться к различным условиям освещения, геометрии объектов и перспективам, что значительно повышает её надежность и точность в реальных сценариях применения.
Для обеспечения точного и надежного захвата объектов сложной формы разработана комплексная система, объединяющая данные сенсора LingBot-Depth и архитектуру Point Transformer. LingBot-Depth предоставляет высококачественные данные о глубине и цвете, необходимые для восприятия окружающей среды. Point Transformer, в свою очередь, обрабатывает эти данные, преобразуя трехмерные облака точек в информацию, пригодную для планирования и выполнения захвата. Такая интеграция позволяет системе не только распознавать объекты, но и предсказывать оптимальные траектории движения манипулятора, обеспечивая гибкость и точность в процессе захвата, что особенно важно для работы с предметами различной формы и текстуры. В результате, система демонстрирует высокую эффективность в задачах, требующих ловкости и адаптивности, открывая новые возможности для автоматизации и роботизации сложных производственных процессов.

Исследование, представленное в данной работе, демонстрирует элегантность подхода к решению задач пространственного восприятия. Авторы, используя метод Masked Depth Modeling, искусно превращают проблему неполных данных в обучающий сигнал. Это напоминает подход, который ценит математическую строгость над эмпирическими наблюдениями. Как однажды заметил Эндрю Ын: «Мы должны стремиться к созданию систем, которые не просто работают, а работают предсказуемо и надежно». Использование маскированных данных в MDM позволяет алгоритму развивать более глубокое геометрическое понимание сцены, что критически важно для таких задач, как захват объектов роботом. Корректность алгоритма, обученного таким образом, может быть доказана, в отличие от тех, что полагаются лишь на статистические закономерности в данных.
Что Дальше?
Представленный подход к моделированию глубины, использующий маскирование, безусловно, демонстрирует элегантность в своей простоте. Однако, истинная проверка любого алгоритма заключается не в достижении лучших результатов на существующих наборах данных, а в его способности к обобщению. Очевидно, что зависимость от тщательно отобранных данных, даже с учетом моделирования отказов сенсоров, является узким местом. Следующий шаг — исследование методов, позволяющих алгоритму самостоятельно выявлять и корректировать несогласованности в данных, не полагаясь на заранее заданные сценарии.
Идея использования пропущенных измерений глубины в качестве сигнала для обучения, хотя и продуктивна, не лишена парадоксов. В конечном счете, алгоритм учится восстанавливать информацию, которой у него изначально нет. Это напоминает попытку построить идеальный круг, используя только несовершенные инструменты. Будущие исследования должны быть направлены на разработку методов, позволяющих алгоритму не просто заполнять пробелы, но и оценивать достоверность восстановленной информации.
В конечном итоге, красота алгоритма не зависит от языка реализации или сложности архитектуры. Важна лишь непротиворечивость и способность к строгому математическому доказательству. Разработка методов верификации и формальной проверки алгоритмов 3D-восприятия представляется более важной задачей, чем дальнейшая погоня за незначительными улучшениями в производительности на искусственно созданных наборах данных.
Оригинал статьи: https://arxiv.org/pdf/2601.17895.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Квантовый скачок в обработке радиоастрономических данных
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-28 03:40