Автор: Денис Аветисян
В статье представлена инновационная платформа, объединяющая гибкие возможности FPGA и интеллектуальное программное обеспечение для значительного ускорения задач машинного обучения.
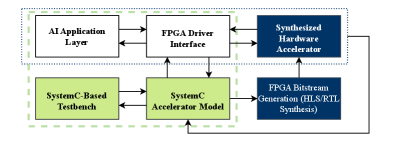
Разработанная реконфигурируемая система AI-FPGA Agent обеспечивает существенное повышение скорости, энергоэффективности и адаптивности при выводе моделей глубокого обучения.
Несмотря на растущие вычислительные потребности искусственного интеллекта, универсальные процессоры и графические ускорители часто оказываются неэффективными в условиях строгих ограничений по задержке и энергопотреблению. В данной работе, посвященной разработке реконфигурируемой платформы ‘A Reconfigurable Framework for AI-FPGA Agent Integration and Acceleration’, представлен AI FPGA Agent — интеллектуальный агент, упрощающий интеграцию и ускорение вычислений глубоких нейронных сетей на FPGA. Предложенная система обеспечивает более чем десятикратное снижение задержки и двух-трехкратное повышение энергоэффективности по сравнению с CPU и GPU, сохраняя при этом высокую точность классификации. Возможно ли создание масштабируемых и энергоэффективных систем искусственного интеллекта, основанных на принципах совместного проектирования аппаратного и программного обеспечения с использованием FPGA?
Пределы Традиционных Архитектур: Вызов Параллелизму
Традиционные центральные и графические процессоры, несмотря на свою универсальность, испытывают трудности при обработке параллельных вычислений, характерных для современных рабочих нагрузок искусственного интеллекта. Архитектура, разработанная для последовательного выполнения инструкций, становится узким местом при одновременной обработке огромных объемов данных, необходимых для обучения и работы нейронных сетей. Это приводит к снижению производительности и увеличению энергопотребления, особенно при работе со сложными моделями глубокого обучения, требующими миллиардов операций в секунду. В результате, возникает потребность в специализированных аппаратных решениях, способных эффективно обрабатывать параллельные задачи и оптимизировать ресурсы для задач искусственного интеллекта.
Ограничения последовательной обработки, присущие традиционным архитектурам, становятся серьезным препятствием для эффективной реализации алгоритмов глубокого обучения. В то время как современные нейронные сети требуют одновременной обработки огромных объемов данных, центральные процессоры и графические ускорители вынуждены выполнять операции последовательно, что приводит к узким местам производительности и значительному энергопотреблению. Каждая операция умножения матриц, критически важная для глубокого обучения, требует множества последовательных шагов, что замедляет процесс и увеличивает тепловыделение. Эта неэффективность особенно заметна при обработке больших наборов данных, где время обучения и потребляемая энергия могут стать непомерными, ограничивая возможности дальнейшего развития и внедрения искусственного интеллекта.
Постоянно растущая сложность современных моделей, в особенности глубоких нейронных сетей, обуславливает необходимость перехода к специализированному аппаратному обеспечению. Традиционные архитектуры, разработанные для универсальных вычислений, сталкиваются с ограничениями при обработке огромных объемов данных и параллельных вычислений, характерных для задач искусственного интеллекта. Увеличение числа слоев и параметров в нейронных сетях приводит к экспоненциальному росту вычислительных потребностей и энергопотребления. В связи с этим, разрабатываются новые типы процессоров и ускорителей, оптимизированные для выполнения специфических операций, таких как матричные умножения и свертки, что позволяет значительно повысить производительность и эффективность при обучении и развертывании сложных моделей машинного обучения. Переход к специализированному оборудованию представляет собой ключевой шаг в развитии искусственного интеллекта и открывает новые возможности для решения сложных задач.

Реконфигурируемое Оборудование: FPGA как Новая Граница
Полевые программируемые вентильные матрицы (FPGA) представляют собой альтернативу фиксированным процессорам, обеспечивая возможность аппаратного ускорения за счет реализации специализированных логических схем. В отличие от центральных и графических процессоров, архитектура FPGA не является жестко заданной, что позволяет пользователям конфигурировать логические элементы и соединения для создания пользовательских аппаратных решений. Это достигается путем программирования конфигурационных ячеек FPGA, определяющих функции и связи между логическими блоками. В результате, FPGA могут значительно превосходить фиксированные процессоры в задачах, требующих высокой степени параллелизма и специализированной обработки данных, таких как обработка сигналов, машинное обучение и финансовый анализ. Аппаратное ускорение на FPGA позволяет снизить задержки, повысить пропускную способность и уменьшить энергопотребление по сравнению с программной реализацией аналогичных алгоритмов на универсальных процессорах.
Полевые программируемые вентильные матрицы (FPGA) обеспечивают возможность реализации специализированных архитектур, оптимизированных для конкретных задач искусственного интеллекта. В отличие от универсальных процессоров, FPGA позволяют создавать аппаратные схемы, точно соответствующие требованиям алгоритма, что приводит к значительному увеличению производительности и снижению энергопотребления. Это достигается за счет параллельного выполнения операций и устранения избыточных вычислений, характерных для последовательной обработки на CPU или GPU. Например, для задач сверточной нейронной сети FPGA могут быть сконфигурированы для реализации матричных умножений и других операций с высокой степенью параллелизма, что позволяет добиться в несколько раз более высокой скорости обработки и эффективности использования энергии по сравнению с традиционными решениями.
Традиционно, программирование FPGA требует владения языками описания аппаратуры (Hardware Description Languages, HDL), такими как VHDL и Verilog. Это создает значительный барьер для широкого распространения технологии, поскольку требует от разработчиков специализированных знаний в области цифровой схемотехники и архитектуры аппаратного обеспечения. В отличие от разработки программного обеспечения, где используются высокоуровневые языки и инструменты, программирование FPGA предполагает непосредственное конфигурирование логических элементов и соединений, что требует глубокого понимания аппаратной реализации алгоритмов и оптимизации ресурсов. Отсутствие специалистов, владеющих HDL, и сложность процесса разработки замедляют внедрение FPGA в различных областях применения.

AI FPGA Agent: Унифицированный Фреймворк для Ко-дизайна Аппаратного и Программного Обеспечения
Фреймворк AI FPGA Agent использует возможности FPGA и интегрирует обучение с подкреплением для автоматизации проектирования и планирования AI-нагрузок. Данный подход позволяет динамически адаптировать процесс разработки, оптимизируя использование аппаратных ресурсов и повышая производительность AI-приложений. Автоматизация включает в себя выбор оптимальной архитектуры FPGA, распределение задач между доступными ресурсами и настройку параметров выполнения для достижения максимальной эффективности в конкретных условиях эксплуатации. Использование обучения с подкреплением позволяет агенту непрерывно совершенствовать стратегии планирования на основе полученного опыта, что обеспечивает адаптацию к изменяющимся требованиям и оптимизацию производительности в долгосрочной перспективе.
Агент, использующий Q-обучение, динамически адаптирует выполнение задач путем определения оптимальной политики действий в зависимости от текущего состояния системы и доступных ресурсов. Процесс обучения включает в себя оценку Q-функции, представляющей ожидаемую совокупную награду за выполнение определенного действия в заданном состоянии. Агент исследует различные стратегии выполнения, обновляя Q-функцию на основе полученных наград и штрафов, что позволяет ему оптимизировать производительность в изменяющихся условиях. Оптимизация включает в себя динамическое изменение порядка выполнения задач, выделение ресурсов и выбор наиболее эффективных аппаратных конфигураций для минимизации задержек и максимизации пропускной способности, учитывая ограничения, такие как энергопотребление и доступная память.
В рамках автоматизированного проектирования аппаратно-программных комплексов на базе FPGA, платформа AI FPGA Agent использует языки и инструменты высокоуровневого синтеза (HLS) для преобразования абстрактных алгоритмов в аппаратно-описательные модели. В частности, применяются SystemC для поведенческого моделирования, Verilog и VHDL для создания структурных описаний, пригодных для непосредственной реализации на FPGA. Использование HLS позволяет значительно сократить время разработки и уменьшить сложность проектирования по сравнению с традиционным ручным написанием кода на HDL, автоматизируя процесс трансляции алгоритмов в аппаратные реализации и оптимизируя их для целевой FPGA-архитектуры.
В рамках фреймворка AI FPGA Agent применяется квантование, в частности, 8-битное целочисленное представление данных, для снижения вычислительной нагрузки и объема используемой памяти. Переход от операций с плавающей точкой к 8-битным целым числам позволяет значительно уменьшить требования к аппаратным ресурсам, таким как количество логических элементов и блоков памяти на FPGA. Экспериментальные результаты показывают, что при использовании 8-битного квантования наблюдается незначительная потеря точности, которая компенсируется существенным снижением энергопотребления и увеличением скорости выполнения операций. Данный подход особенно актуален для задач машинного обучения, где допустимы небольшие отклонения в точности ради повышения эффективности аппаратной реализации.

Масштабирование ИИ с Использованием LLM и Динамического Планирования
В рамках данной разработки, большие языковые модели (LLM) применяются для автоматизации процессов верификации и оптимизации аппаратного обеспечения. Этот подход, известный как LLM-управляемый аппаратный дизайн, позволяет значительно сократить время и ресурсы, необходимые для создания эффективных и специализированных вычислительных систем. LLM используются для анализа и генерации кода, необходимого для конфигурирования FPGA, что позволяет автоматически адаптировать аппаратную архитектуру к конкретным задачам глубокого обучения. Вместо ручной настройки и оптимизации, LLM самостоятельно исследуют пространство возможных конфигураций, находя решения, которые максимизируют производительность и энергоэффективность. Такой автоматизированный подход не только ускоряет процесс разработки, но и позволяет создавать более сложные и эффективные аппаратные решения, чем это было бы возможно при ручной настройке.
В основе системы лежит интеллектуальное динамическое планирование, управляемое агентом искусственного интеллекта, которое обеспечивает эффективное использование ресурсов ПЛИС в ответ на изменяющиеся нагрузки. Вместо статического распределения ресурсов, система непрерывно анализирует требования конкретных задач глубокого обучения и адаптирует конфигурацию ПЛИС в режиме реального времени. Такой подход позволяет избегать неэффективного использования аппаратных средств и максимизировать пропускную способность, особенно при обработке разнообразных наборов данных или при выполнении нескольких задач одновременно. Благодаря этому, достигается значительное повышение производительности и энергоэффективности по сравнению с традиционными подходами, где ресурсы выделяются заранее и остаются неизменными, даже если они не полностью используются.
Интеграция с OpenCL позволяет реализовать гетерогенные вычисления, эффективно используя сильные стороны различных вычислительных устройств. Данный подход предполагает совместное использование центральных процессоров (CPU), графических процессоров (GPU) и программируемых пользователем вентильных матриц (FPGA) для оптимизации производительности. CPU обеспечивают универсальную обработку, GPU — параллельные вычисления, а FPGA — аппаратную реализацию специализированных алгоритмов. Благодаря OpenCL, система динамически распределяет задачи между этими устройствами, направляя наиболее ресурсоемкие операции на FPGA для аппаратного ускорения, в то время как CPU и GPU выполняют менее критичные к производительности задачи. Такая гибкость позволяет добиться существенного увеличения скорости обработки данных и повышения энергоэффективности по сравнению с использованием только CPU или GPU.
Представленная система демонстрирует значительное ускорение задач глубокого обучения, превосходя традиционные CPU и GPU решения более чем в десять раз по скорости выполнения. Зафиксировано снижение задержки при выводе данных до 3.5 миллисекунд, в то время как на CPU данный показатель составлял 40.2 миллисекунды. Пропускная способность достигла 284.7 изображений в секунду, существенно превышая показатели CPU (25.5 изображений/с) и GPU (113.3 изображений/с). При этом, энергоэффективность составила 10.17 изображений/с/Вт, что значительно превосходит 0.29 изображений/с/Вт у CPU и 0.90 изображений/с/Вт у GPU. Важно отметить, что наблюдается лишь незначительное снижение точности модели — всего 0.2% по сравнению с эталонными вычислениями с плавающей точкой, что подтверждает высокую эффективность и практическую применимость данной разработки.
Будущее Адаптивного Интеллекта
Разработка платформы AI FPGA Agent знаменует собой важный шаг к созданию действительно адаптивного интеллекта, где аппаратное обеспечение динамически конфигурируется для соответствия требованиям постоянно развивающихся алгоритмов. В отличие от традиционных систем, где программное обеспечение оптимизируется под фиксированную архитектуру, данная платформа позволяет аппаратному обеспечению изменяться в ответ на меняющиеся вычислительные потребности. Это достигается благодаря использованию FPGA — программируемых логических интегральных схем, которые могут быть перенастроены после производства. В результате, система способна не только эффективно выполнять текущие задачи, но и адаптироваться к новым, оптимизируя производительность и энергоэффективность без необходимости полной замены оборудования. Такая гибкость открывает перспективы для создания интеллектуальных систем, способных к самообучению и эволюции в реальном времени.
Применение разработанного подхода имеет далеко идущие последствия для множества областей. В частности, в сфере автономного транспорта динамическая переконфигурация аппаратного обеспечения позволит создавать системы, способные эффективно адаптироваться к меняющимся дорожным условиям и требованиям безопасности. В робототехнике это открывает возможности для создания роботов, способных к самообучению и оптимизации своих действий в реальном времени. Особый потенциал наблюдается в персонализированной медицине, где адаптивные системы могут анализировать индивидуальные данные пациента и оптимизировать протоколы лечения, обеспечивая более точную и эффективную терапию. Такая гибкость и эффективность позволяют создавать интеллектуальные системы, способные решать сложные задачи в различных сферах, значительно превосходя традиционные подходы.
В настоящее время исследования направлены на расширение возможностей самообучения агента, что позволит ему самостоятельно разрабатывать и оптимизировать новые аппаратные архитектуры. Это предполагает переход от ручной настройки аппаратного обеспечения к автоматизированному процессу, где агент, анализируя требования алгоритмов и характеристики доступных ресурсов, способен формировать наиболее эффективные конфигурации. Успешная реализация данной концепции откроет путь к созданию систем, способных адаптироваться к меняющимся условиям и задачам без вмешательства человека, значительно повышая их производительность и энергоэффективность. Предполагается, что агент будет использовать методы машинного обучения с подкреплением для исследования различных аппаратных конфигураций, оценивая их эффективность и постепенно улучшая процесс оптимизации.
Слияние искусственного интеллекта и реконфигурируемого оборудования открывает перспективы для создания интеллектуальных систем, отличающихся не только высокой производительностью, но и энергоэффективностью, экологической устойчивостью и способностью к адаптации. Такой подход позволяет системам динамически оптимизировать свою аппаратную конфигурацию в ответ на меняющиеся требования алгоритмов и внешних условий, что особенно важно для приложений, работающих в реальном времени и требующих минимального энергопотребления. В будущем подобные системы смогут самостоятельно находить оптимальные аппаратные решения, обеспечивая беспрецедентный уровень гибкости и эффективности в различных областях, от автономного транспорта до персонализированной медицины, и существенно снижая зависимость от фиксированных, неоптимальных аппаратных решений.
Представленная работа демонстрирует стремление к математической чистоте и доказуемости алгоритмов, что находит отражение в разработке AI-FPGA Agent. Этот фреймворк, оптимизирующий deep learning inference на FPGA, требует точного анализа и обоснования каждого этапа реконфигурации. Как заметил Джон фон Нейман: «В науке не бывает проигрышных битв, бывают проигрышные войны». В данном контексте, каждая оптимизация в AI-FPGA Agent — это сражение за эффективность, а успех достигается лишь при всестороннем анализе и доказательстве корректности, позволяющем избежать ловушки неоптимальных решений и обеспечить стабильную, низколатентную производительность системы.
Куда Ведет Этот Путь?
Представленная работа, безусловно, демонстрирует потенциал интеграции интеллектуальных агентов и реконфигурируемых FPGA для ускорения глубинного обучения. Однако, нельзя забывать, что ускорение ради ускорения — не всегда путь к истине. Доказательство корректности полученных результатов, особенно в условиях динамической реконфигурации FPGA, остается сложной задачей. Достаточно ли валидации на синтетических данных, чтобы гарантировать надежность системы в реальных, непредсказуемых сценариях? Этот вопрос требует дальнейшего, строгого анализа.
Очевидным направлением для будущих исследований является разработка формальных методов верификации, способных подтвердить не только функциональность, но и временные характеристики реконфигурируемых агентов. Простое достижение «улучшения по сравнению с CPU и GPU» — недостаточно. Необходимо математически доказать, что полученные преимущества являются устойчивыми и предсказуемыми. Более того, остается открытым вопрос о масштабируемости предложенного подхода — насколько эффективно он будет работать с более сложными моделями и большими объемами данных?
В конечном счете, истинная ценность данной работы заключается не в конкретных цифрах ускорения, а в постановке вопроса о необходимости более формального и строгого подхода к разработке аппаратных ускорителей для глубинного обучения. Пока алгоритм не доказан, а лишь “работает на тестах”, он остается лишь гипотезой, требующей дальнейшей проверки. Истинная элегантность, как всегда, в математической чистоте.
Оригинал статьи: https://arxiv.org/pdf/2601.19263.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-01-28 12:00