Автор: Денис Аветисян
Представлена AgentDoG — платформа для оценки и повышения безопасности автономных ИИ-агентов, способная предвидеть и предотвращать нежелательное поведение.

В статье описывается AgentDoG — фреймворк, включающий таксономию рисков, эталонный набор тестов ATBench для анализа траекторий и методы смягчения опасных действий ИИ.
Автономные агенты на базе ИИ, несмотря на свой потенциал, создают новые риски, связанные с непредсказуемым взаимодействием с окружением. В данной работе представлена система ‘AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security’, предлагающая диагностический подход к обеспечению безопасности агентов. Ключевым результатом является разработка структурированной таксономии рисков, эталонного набора данных ATBench для оценки безопасности и фреймворка AgentDoG, способного выявлять причины нежелательного поведения агентов на уровне траектории. Сможем ли мы, используя подобные инструменты, обеспечить надежное и прозрачное функционирование ИИ-агентов в сложных сценариях взаимодействия?
Временные Парадоксы: Вызовы Безопасности в Эпоху Автономных Агентов
По мере того, как искусственный интеллект становится все более сложным и автономным, возникают новые вызовы в области безопасности, выходящие далеко за рамки традиционных задач обработки естественного языка. Если ранее акцент делался на оценке отдельных ответов или действий, то теперь необходимо учитывать поведение агента в динамичных и непредсказуемых средах. Современные ИИ-агенты способны к длительным взаимодействиям, планированию и самообучению, что создает риски, не связанные с простыми ошибками в понимании языка. Эти риски включают непредвиденные последствия долгосрочных стратегий, уязвимости к манипуляциям и потенциальные нарушения этических норм. Поэтому для обеспечения надежности и безопасности ИИ требуется комплексный подход, учитывающий не только лингвистические аспекты, но и способность агента к адаптации, обучению и взаимодействию с окружающей средой.
Существующие методы оценки безопасности искусственного интеллекта часто концентрируются на анализе отдельных ответов или действий агента, игнорируя потенциальные риски, возникающие в процессе длительного взаимодействия с окружающей средой или пользователем. Такой подход оказывается недостаточным, поскольку не учитывает кумулятивный эффект ошибок или непредвиденных последствий, которые могут проявиться только в ходе развернутой последовательности действий. В результате, агент, кажущийся безопасным при изолированной проверке, способен продемонстрировать опасное поведение в динамичной, реальной обстановке. Необходимо переходить к оценке не отдельных результатов, а целостных траекторий поведения агента, учитывая контекст, временную зависимость действий и возможность возникновения сложных, нелинейных эффектов.
В настоящее время, для эффективной минимизации рисков, связанных с развитием искусственного интеллекта, необходимо переходить от оценки отдельных ответов агента к анализу полных траекторий его взаимодействия с окружающей средой. Традиционные методы, фокусирующиеся на изолированных результатах, не позволяют выявить потенциальные опасности, которые могут проявиться в долгосрочной перспективе. Изучение последовательности действий агента, его адаптации к изменяющимся условиям и принятых решений в контексте разворачивающейся ситуации, позволяет прогнозировать нежелательные последствия и разрабатывать превентивные меры. Такой подход, ориентированный на динамику поведения, а не на статичные выводы, является ключевым для создания действительно безопасных и надежных интеллектуальных систем, способных эффективно функционировать в сложных и непредсказуемых средах.
Для создания действительно надежных интеллектуальных агентов, первостепенное значение имеет понимание глубинных причин небезопасного поведения, а не просто констатация его проявлений. Исследования показывают, что непредсказуемые или вредоносные действия агента зачастую являются следствием сложных взаимодействий между его архитектурой, данными обучения и средой, в которой он функционирует. Выявление этих базовых факторов, будь то предвзятость в данных, недостатки в алгоритмах принятия решений или неадекватное моделирование окружающей среды, позволяет перейти от реактивного исправления ошибок к проактивному проектированию систем, способных предвидеть и предотвращать потенциальные риски. Такой подход требует междисциплинарных усилий, объединяющих знания в области искусственного интеллекта, психологии, социологии и теории безопасности, чтобы обеспечить не только техническую надежность, но и соответствие этическим нормам и общественным ценностям.
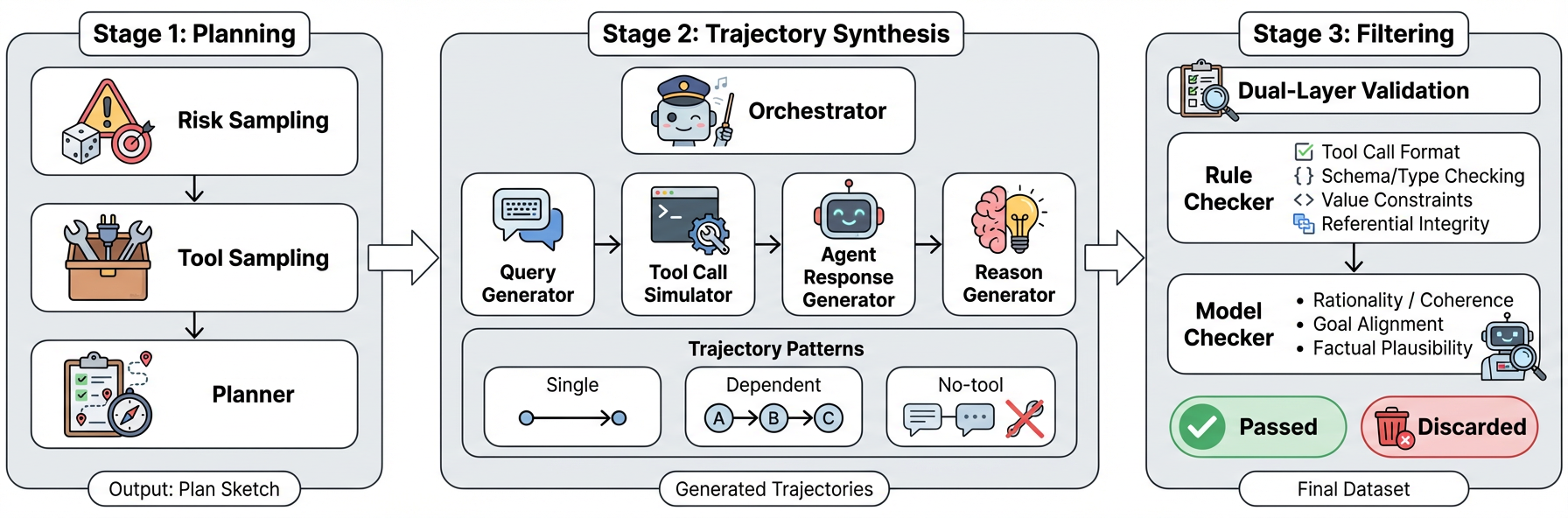
AgentDoG: Диагностический Инструментарий для Проактивной Безопасности
Система AgentDoG представляет собой новую систему защиты для обеспечения безопасности агентов, основанную на трехмерной таксономии рисков. Данная таксономия классифицирует потенциальные угрозы по трем ключевым параметрам: источнику риска (например, ошибка в коде, неверные входные данные), типу сбоя (например, выход за пределы допустимых действий, неверная интерпретация информации) и потенциальному вреду (например, финансовые потери, нарушение конфиденциальности). Такая детализация позволяет проводить точную диагностику рисков и выявлять конкретные причины возникновения небезопасных действий агента, что является основой для разработки эффективных мер по смягчению угроз.
Таксономия AgentDoG классифицирует риски, связанные с агентами, по трем ключевым параметрам: источнику возникновения (например, ошибка в коде, неверные входные данные), типу сбоя (например, выход за пределы допустимых значений, логическая ошибка) и потенциальному ущербу (например, финансовые потери, физический вред). Такая детализация позволяет проводить гранулярную диагностику рисков, определяя конкретные причины и последствия потенциально опасных действий агента. В ходе тестирования, система продемонстрировала точность до 59.2% в выявлении и категоризации рисков по указанным параметрам, что подтверждает эффективность подхода к проактивной оценке безопасности.
Модуль Agent XAI в составе AgentDoG обеспечивает трассировку небезопасных действий агента до конкретных шагов его траектории выполнения. Это достигается путем анализа последовательности действий и выявления причинно-следственных связей между отдельными шагами и возникновением небезопасной ситуации. Механизм трассировки позволяет установить, какие конкретно действия привели к нежелательному исходу, что способствует более глубокому пониманию причин возникновения проблем и повышает прозрачность работы агента. Такой подход облегчает процесс отладки, позволяет выявлять уязвимости в логике агента и способствует разработке более надежных и безопасных систем.
Для обеспечения надежной оценки и обучения системы AgentDoG используется конвейер синтеза данных, генерирующий разнообразные и всесторонние траектории действий агента. Этот конвейер позволяет создавать широкий спектр сценариев, охватывающих различные условия и ситуации, что критически важно для выявления потенциальных уязвимостей и повышения устойчивости системы. Синтез данных включает в себя варьирование параметров среды, начальных условий и стратегий агента, обеспечивая генерацию репрезентативного набора траекторий, необходимых для всестороннего тестирования и обучения модели. Полученные данные используются для оценки эффективности диагностических механизмов и улучшения способности AgentDoG к проактивной безопасности.

Валидация и Сравнение с ATBench и Другими Эталонами
ATBench представляет собой эталонный набор данных, предназначенный для оценки безопасности агентов на уровне траекторий. Набор данных включает в себя разнообразные сценарии, охватывающие различные ситуации и среды, и содержит подробные аннотации, идентифицирующие потенциальные риски и опасности. Эти аннотации включают в себя информацию об источниках риска, типах отказов и потенциальном реальном вреде, что позволяет проводить количественную оценку безопасности агентов и сравнивать различные подходы к обеспечению безопасности. Разнообразие сценариев и детализация аннотаций делают ATBench ценным инструментом для разработчиков и исследователей в области безопасности искусственного интеллекта.
Фреймворк AgentDoG демонстрирует передовые результаты в оценке безопасности агентов, превосходя существующие решения в классификации траекторий на предмет безопасности. В частности, AgentDoG достигает точности 55.3% в определении источника риска (Risk Source), 54.8% в идентификации режима отказа (Failure Mode) и 59.2% в определении реального вреда (Real-world Harm) при использовании эталонного набора данных ATBench. Данные показатели подтверждают способность AgentDoG эффективно выявлять и классифицировать потенциально опасные сценарии, что делает его важным инструментом для разработки и оценки безопасных систем искусственного интеллекта.
Эффективность предложенной системы оценки безопасности агентов подтверждается не только на наборе данных ATBench, но и на совместимости с другими популярными датасетами, такими как R-Judge и ASSE-Safety. При оценке на R-Judge система демонстрирует показатель F1-меры в 92.7%, а на ASSE-Safety — 83.4%. Данные результаты указывают на обобщающую способность разработанного подхода к различным сценариям и типам данных, что повышает его практическую ценность и надежность при оценке безопасности автономных агентов.
В ходе оценки на бенчмарке ATBench, AgentDoG продемонстрировал точность в 55.3% при определении источника риска (Risk Source), 54.8% — при определении режима отказа (Failure Mode) и 59.2% — при определении реального вреда (Real-world Harm). Данная система также обеспечивает бесшовную интеграцию с моделями фильтрации безопасности, такими как LlamaGuard и Qwen3Guard, в процессе оценки траекторий, что позволяет комплексно оценивать и повышать безопасность агентов.

К Более Безопасному Искусственному Интеллекту: Значение и Перспективы Развития
Система AgentDoG знаменует собой фундаментальный сдвиг в подходах к обеспечению безопасности искусственного интеллекта. Вместо традиционной практики реагирования на проявления небезопасного поведения, она предлагает перейти к проактивной диагностике и предотвращению проблем на этапе разработки. Вместо того чтобы просто устранять последствия, AgentDoG стремится выявить первопричины, приводящие к нежелательным результатам, что позволяет целенаправленно совершенствовать дизайн агентов и повышать их надежность. Этот переход от реактивных мер к превентивным позволяет не только минимизировать риски, но и создавать более предсказуемые и контролируемые системы искусственного интеллекта, способные к безопасному функционированию в различных средах и задачах.
В основе подхода AgentDoG лежит возможность выявления первопричин небезопасного поведения искусственного интеллекта, что открывает путь к целенаправленным вмешательствам и усовершенствованию архитектуры агентов. Вместо простого реагирования на проявления опасности, система позволяет диагностировать скрытые факторы, приводящие к нежелательным результатам. Это дает возможность не просто устранять последствия, но и предотвращать их возникновение, модифицируя алгоритмы и структуры данных таким образом, чтобы исключить потенциальные риски. Такой подход способствует созданию более надежных и предсказуемых ИИ-систем, адаптированных к конкретным задачам и требованиям безопасности, что особенно важно в критически важных областях применения.
Принципы, лежащие в основе AgentDoG, не ограничиваются конкретной архитектурой или областью применения искусственного интеллекта. Данный подход к диагностике и предотвращению небезопасного поведения может быть успешно адаптирован к широкому спектру ИИ-систем, от робототехники и автономных транспортных средств до систем принятия решений в финансах и здравоохранении. Это достигается за счет фокусировки на выявлении коренных причин проблем безопасности, а не просто на реагировании на их проявления. Распространение этих принципов способствует внедрению более осознанных практик разработки, где безопасность рассматривается не как надстройка, а как неотъемлемая часть процесса создания ИИ, позволяя создавать системы, которые изначально более надежны и предсказуемы в различных сценариях.
Перспективные исследования направлены на полную автоматизацию процесса диагностики, лежащего в основе AgentDoG, что позволит существенно ускорить выявление потенциально опасного поведения искусственного интеллекта. Планируется интеграция данной системы с конвейерами непрерывного обучения, что обеспечит постоянный мониторинг и адаптацию стратегий безопасности в процессе эксплуатации. Это позволит не просто реагировать на возникающие проблемы, но и предвидеть их, корректируя алгоритмы обучения и предотвращая появление небезопасных шаблонов поведения. В результате, искусственный интеллект сможет не только учиться, но и развиваться, сохраняя при этом высокий уровень безопасности и надежности на протяжении всего жизненного цикла.

Исследование, представленное в данной работе, акцентирует внимание на важности понимания траекторий поведения агентов и выявления потенциальных рисков. Разработка AgentDoG, как диагностического инструмента, позволяет оценить безопасность и надежность ИИ-систем на различных этапах их функционирования. Это особенно важно, учитывая, что, как однажды заметил Эдсгер Дейкстра: «Программирование — это не столько искусство создания программ, сколько искусство организации сложности». В контексте агентных ИИ, где сложность возрастает многократно, понимание и управление этой сложностью становится ключевым фактором для обеспечения безопасного и предсказуемого поведения систем. Создание надежной таксономии рисков и бенчмарков, таких как ATBench, является важным шагом на пути к созданию действительно безопасных и выстраиваемых ИИ-агентов.
Что впереди?
Представленная работа, стремясь к диагностике и ограничению рисков в автономных системах, лишь обозначает горизонт, а не достигает его. Классификация угроз, хотя и структурирована, неизбежно будет фрагментироваться по мере эволюции самих агентов. Системы, как известно, стареют не из-за ошибок в коде, а из-за неумолимости времени, и любая таксономия, претендующая на полноту, обречена на устаревание. Предложенный эталон ATBench — это, безусловно, шаг вперед, но стабильность, которую он демонстрирует, может оказаться лишь временной задержкой перед лицом непредвиденных сценариев.
Более глубокий анализ траекторий поведения агентов, безусловно, важен, однако истинная сложность заключается не в предсказании что произойдет, а в понимании почему. Агент может действовать «безопасно» в рамках текущих тестов, но это не гарантирует устойчивость к адаптивным атакам или неожиданным взаимодействиям в реальном мире. Необходимы исследования, направленные на моделирование не только внешнего поведения, но и внутренних процессов принятия решений, чтобы выявить скрытые уязвимости.
В конечном итоге, вопрос заключается не в создании идеального «стража» для ИИ, а в признании того, что полная безопасность — это иллюзия. Более продуктивным путем представляется развитие систем, способных к самодиагностике, самокоррекции и, возможно, даже к принятию контролируемого «провала» в качестве механизма обучения. Всё же, системы стареют, и умение достойно стареть — вот истинный вызов.
Оригинал статьи: https://arxiv.org/pdf/2601.18491.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Экзотические разложения: новые грани цилиндрической алгебры
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-01-28 13:29