Автор: Денис Аветисян
Исследователи представили модель DeFM, позволяющую роботам эффективно обучаться на данных о глубине и адаптироваться к различным условиям без дополнительной настройки.

DeFM — это самообучающаяся модель, извлекающая надежные признаки глубины для задач робототехники и обеспечивающая перенос обучения из симуляции в реальный мир.
Несмотря на широкое распространение датчиков глубины в робототехнике и успехи в симуляции, обучение представлений для данных о глубине отстает от прогресса в обработке RGB-изображений. В данной работе, ‘DeFM: Learning Foundation Representations from Depth for Robotics’ представлена модель DeFM — самообучаемая базовая модель, предназначенная для извлечения надежных признаков из данных о глубине для задач робототехники. Используя самодистилляцию в стиле DINO на тщательно подобранном наборе данных из 60 миллионов изображений глубины, DeFM осваивает геометрические и семантические представления, обобщающиеся на различные среды, задачи и сенсоры. Сможет ли DeFM стать универсальным инструментом для разработки более адаптивных и эффективных робототехнических систем, способных к обучению в реальных условиях без сложной настройки?
По ту сторону RGB: К глубине как к основе восприятия
Традиционные системы компьютерного зрения, опирающиеся на анализ RGB-изображений, часто сталкиваются с серьезными трудностями при изменении освещения или угла обзора. Любые колебания в интенсивности света или незначительное смещение перспективы могут существенно исказить интерпретацию изображения, приводя к ошибкам в распознавании объектов и сцен. Например, тень, падающая на объект, может быть ошибочно воспринята как изменение его формы или даже как присутствие другого объекта. Подобная чувствительность к внешним факторам ограничивает надежность и применимость таких систем в реальных условиях, где освещение и положение камеры редко остаются постоянными. В результате, разработка методов, устойчивых к этим вариациям, является ключевой задачей в области компьютерного зрения.
Информация о глубине предоставляет фундаментальное трехмерное понимание окружающего мира, что значительно повышает устойчивость систем компьютерного зрения к изменениям освещения и угла обзора. В отличие от традиционных двухмерных изображений, данные о глубине позволяют алгоритмам воспринимать объекты как таковые, а не просто как проекции на плоскость. Это открывает новые возможности для развития робототехники, позволяя роботам более надежно ориентироваться в пространстве, распознавать объекты и манипулировать ими с высокой точностью. Например, автономные транспортные средства, использующие данные о глубине, способны более безопасно перемещаться в сложных условиях, а промышленные роботы — выполнять сложные задачи сборки и манипуляции с повышенной эффективностью. Использование информации о глубине — это шаг к созданию действительно интеллектуальных систем, способных понимать и взаимодействовать с миром так, как это делает человек.
Для эффективного использования данных о глубине в компьютерном зрении необходимы принципиально новые базовые модели, способные к обобщению. Традиционные алгоритмы, разработанные для обработки двухмерных изображений, часто оказываются неэффективными при анализе трехмерных данных, поскольку не учитывают специфику представления глубины и не способны извлекать значимые признаки из этой информации. Разработка таких моделей требует инновационных подходов к архитектуре нейронных сетей и методам обучения, позволяющих им эффективно работать с различными типами датчиков глубины и адаптироваться к изменяющимся условиям окружающей среды. Успешное создание таких моделей откроет путь к более надежным и гибким системам компьютерного зрения, способным решать широкий спектр задач, от автономной навигации роботов до детального анализа трехмерных сцен.

DeFM: Основа для глубокого понимания сцен
Модель DeFM представляет собой новую основу для задач, связанных с глубиной, предварительно обученную на крупномасштабном наборе данных изображений глубины. Целью предварительного обучения является получение обобщенных представлений, которые могут быть эффективно перенесены и применены к широкому спектру последующих задач обработки изображений. В отличие от моделей, обученных для конкретных задач, DeFM стремится выучить базовые характеристики глубины, которые применимы к различным сценариям, таким как оценка глубины, сегментация и 3D-реконструкция. Такой подход позволяет значительно сократить время и ресурсы, необходимые для обучения моделей для новых задач, используя предварительно обученные веса в качестве отправной точки.
В процессе обучения DeFM используется метод самодистилляции, позволяющий передавать знания от более крупных и сложных моделей к DeFM. Этот подход предполагает, что большая модель, уже обученная на большом объеме данных, выступает в роли «учителя», а DeFM — в роли «ученика». DeFM обучается не только предсказывать глубину, но и имитировать выходные данные «учителя», что позволяет ему эффективно извлекать более качественные признаки и улучшать обобщающую способность, несмотря на меньший размер модели. Самодистилляция способствует повышению точности и эффективности DeFM в задачах, требующих извлечения признаков глубины.
Архитектура DeFM представлена в нескольких вариантах: DeFM-L/14, DeFM-S/14 и DeFM-ResNet-18, что позволяет подобрать оптимальный баланс между производительностью и вычислительной эффективностью. Модель DeFM-L/14, основанная на архитектуре Vision Transformer, демонстрирует передовые результаты в задачах, связанных с оценкой глубины, превосходя существующие аналоги по ключевым метрикам. Вариант DeFM-S/14 обеспечивает более высокую скорость работы при незначительном снижении точности, а DeFM-ResNet-18 представляет собой альтернативу, использующую классическую сверточную сеть ResNet-18, для задач, где требуется меньшее количество параметров.
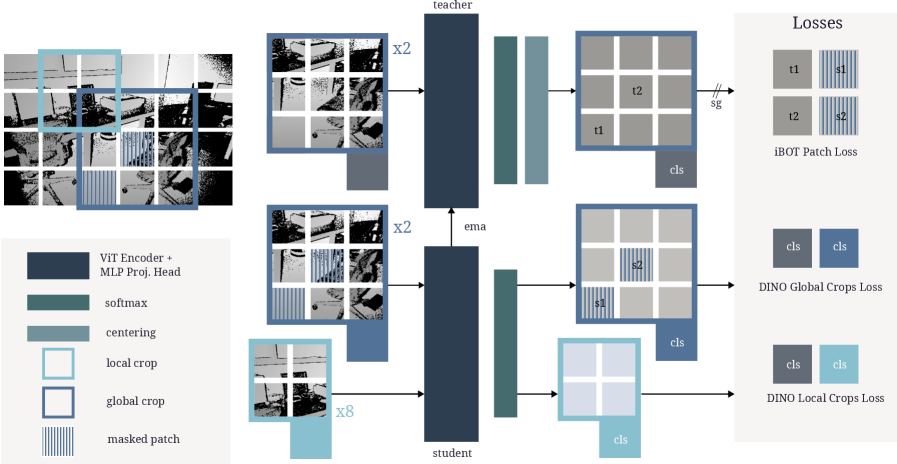
Проверка DeFM: Робототехнические приложения и бенчмарки
Оценка возможностей DeFM проводилась на широком спектре задач робототехники. В рамках исследований использовались платформы и симуляторы, включающие ANYmal для задач локомоции, DexTRAH для манипуляций и Habitat для навигации. Такой подход позволил проверить эффективность представлений, полученных с помощью DeFM, в различных сценариях, охватывающих как передвижение робота, так и взаимодействие с объектами и ориентацию в пространстве. Разнообразие примененных задач обеспечило комплексную оценку применимости DeFM в робототехнических приложениях.
Вариант DeFM, использующий архитектуру ResNet-18 и BiFPN для улучшения представления пространственных признаков, показал высокую эффективность в различных задачах робототехники. BiFPN (Bidirectional Feature Pyramid Network) позволяет эффективно объединять признаки из разных уровней сети, что особенно важно для понимания сцены и взаимодействия с окружением. В ходе тестирования на задачах передвижения (платформа ANYmal), манипулирования (DexTRAH) и навигации (Habitat) данный вариант DeFM продемонстрировал стабильные и надежные результаты, подтверждая его применимость в реальных робототехнических системах.
На бенчмарке ImageNet-Depth-1K модель DeFM достигла точности Top-1 KNN в 84.79% и точности Top-5 KNN также в 84.79%, что свидетельствует о высокой эффективности извлекаемых признаков. Кроме того, при использовании линейного зондирования на том же бенчмарке, DeFM показала точность в 71.72%, подтверждая способность модели к обобщению и передаче знаний для решения задач классификации изображений на основе глубины.
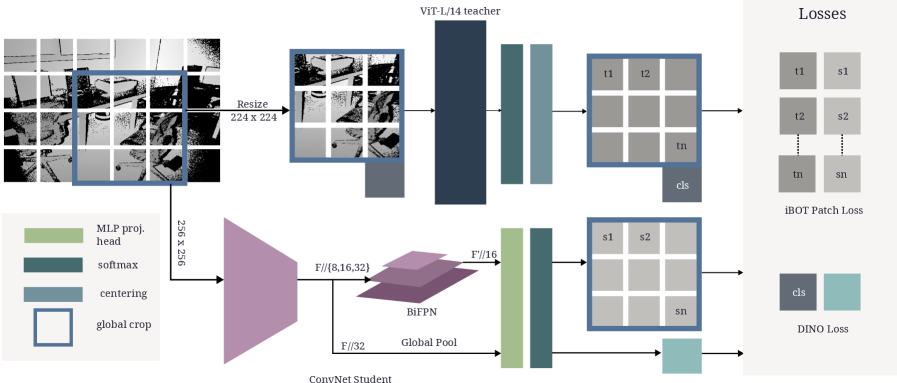
DeFM в сравнении с передовыми решениями: Анализ влияния
Исследования показывают, что DeFM, в отличие от моделей, обученных на RGB-изображениях, таких как DINOv2 и DINOv3, демонстрирует сопоставимые или превосходящие результаты в задачах робототехники, основанных на данных о глубине. Этот прогресс достигается благодаря специфической стратегии предварительного обучения DeFM, которая позволяет более эффективно извлекать и использовать информацию о трехмерной структуре окружения. В условиях, когда робот должен ориентироваться и взаимодействовать с объектами, используя исключительно данные о глубине, DeFM демонстрирует повышенную точность и надежность, что делает его перспективным инструментом для широкого спектра приложений, включая навигацию, захват объектов и манипулирование ими.
Альтернативные подходы к дистилляции признаков, представленные в моделях Theia и C-RADIOv3, демонстрируют различные стратегии извлечения полезной информации из данных. В то время как эти модели используют собственные методы для упрощения и обобщения визуальных представлений, DeFM отличается своей стратегией предварительного обучения. Она позволяет модели изначально усвоить более широкий спектр признаков, что, в свою очередь, обеспечивает повышенную устойчивость и эффективность в задачах, связанных с робототехникой. Такой подход позволяет DeFM превосходить аналогичные модели в сложных сценариях, требующих точного восприятия и адаптации к изменяющимся условиям окружающей среды.
В ходе выполнения сложной задачи восхождения по лестнице, система DeFM продемонстрировала впечатляющий уровень успеха, достигнув 90.14%. Этот результат наглядно подтверждает способность DeFM эффективно функционировать в условиях, требующих высокой точности и адаптации к изменяющейся обстановке. Способность системы успешно справляться с подобными сценариями, где необходимо учитывать трехмерную структуру окружения и координировать движения, указывает на её потенциал для применения в различных областях робототехники, включая логистику, инспекцию и помощь человеку.

Будущее восприятия роботами: К обобщенному интеллекту
Успех DeFM демонстрирует значительный потенциал восприятия на основе данных о глубине для развития роботизированного интеллекта. В отличие от традиционных методов, полагающихся на обработку изображений в двухмерном пространстве, DeFM позволяет роботам более точно и эффективно оценивать окружающую среду, извлекая информацию о форме, размере и расположении объектов. Это особенно важно для задач, требующих понимания трехмерного мира, таких как навигация в сложных условиях, манипулирование предметами и взаимодействие с окружающей средой. Полученные результаты указывают на то, что глубинное восприятие может стать ключевым компонентом систем искусственного интеллекта, позволяя роботам действовать более автономно и эффективно в реальных условиях, приближая их к уровню когнитивных способностей человека.
Дальнейшие исследования направлены на расширение возможностей DeFM путем обработки значительно больших объемов данных, что позволит повысить точность и надежность восприятия роботами окружающей среды. Особое внимание уделяется интеграции DeFM с другими сенсорными данными, такими как визуальная информация и тактильные ощущения. Такой мультимодальный подход позволит роботам формировать более полное и детальное представление об окружающем мире, объединяя преимущества различных источников информации. Ожидается, что подобная интеграция приведет к созданию систем, способных адаптироваться к различным условиям освещения, различным типам поверхностей и сложным сценариям взаимодействия с объектами, приближая роботов к действительно автономной работе в реальных условиях.
Стремление к обобщенным признакам в восприятии является ключевым фактором для раскрытия полного потенциала роботов в автономной работе в сложных, реальных условиях. Разработка алгоритмов, способных выделять фундаментальные характеристики объектов и сцен, а не просто запоминать конкретные примеры, позволит роботам адаптироваться к незнакомым ситуациям и эффективно функционировать в динамично меняющейся среде. Такая способность к обобщению позволит роботам не только распознавать объекты, но и понимать их взаимосвязи, предсказывать их поведение и принимать обоснованные решения, приближая их к уровню интеллекта, необходимому для полноценной автономной работы в самых разнообразных областях — от промышленных предприятий до домашних хозяйств и спасательных операций.
Представленная работа демонстрирует стремление к редукции сложности в области восприятия роботами. Модель DeFM, обучаясь из глубинного представления данных, извлекает фундаментальные признаки, необходимые для эффективной работы в различных условиях. Это соответствует принципу, высказанному Тимом Бернерсом-Ли: «Связи, а не содержащиеся в них данные, являются ценностью». Иными словами, модель фокусируется не на детальном анализе каждого пикселя, а на установлении взаимосвязей между элементами окружения, что позволяет достичь обобщения и устойчивости к изменениям в сенсорных данных. Упор на самообучение и извлечение базовых признаков является ключевым для создания интеллектуальных систем, способных адаптироваться к новым задачам без необходимости переобучения.
Что дальше?
Представленная работа, как и многие другие, склонна к созданию всеобъемлющих “оснований” — словно сама сложность проблемы может быть решена путем ее же усложнения. Они назвали это “фундаментальной моделью глубины”, чтобы скрыть панику перед необходимостью действительно понять, что робот должен видеть, а не просто регистрировать. Очевидно, что извлечение признаков — лишь первый шаг. Настоящая задача — в интеграции этих признаков с механизмами принятия решений, способными к адаптации и самообучению в реальном времени.
Ограничение текущего подхода — зависимость от “глубины” как единственного источника информации. В мире, где сенсоры разнообразны и часто несовершенны, необходимо развивать методы, способные извлекать полезные знания из неполных и зашумленных данных. Необходимо учиться извлекать суть, а не просто обрабатывать пиксели. И, конечно, стоит задуматься о том, что “обобщение” — это не просто хорошая производительность на новых данных, а способность к пониманию и предвидению.
В конечном итоге, успех в области робототехники будет определяться не сложностью алгоритмов, а их элегантностью. Простота — признак зрелости. Возможно, стоит отложить в сторону стремление к созданию всеобъемлющих моделей и сосредоточиться на решении конкретных, четко определенных задач. Тогда, возможно, и удастся создать робота, способного не просто выполнять команды, но и понимать их смысл.
Оригинал статьи: https://arxiv.org/pdf/2601.18923.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Робот-исследователь: новый подход к автономной навигации
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Самообучающиеся признаки: новый подход к машинному обучению
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Искусственный интеллект: хрупкость визуального мышления
2026-01-28 20:11