Автор: Денис Аветисян
Новый тест AVMeme Exam демонстрирует, что современные модели искусственного интеллекта испытывают трудности с пониманием юмора и культурного контекста в многоязычных аудиовизуальных мемах.
AVMeme Exam — это мультимодальный, многоязычный и мультикультурный бенчмарк для оценки контекстуального и культурного понимания больших языковых моделей.
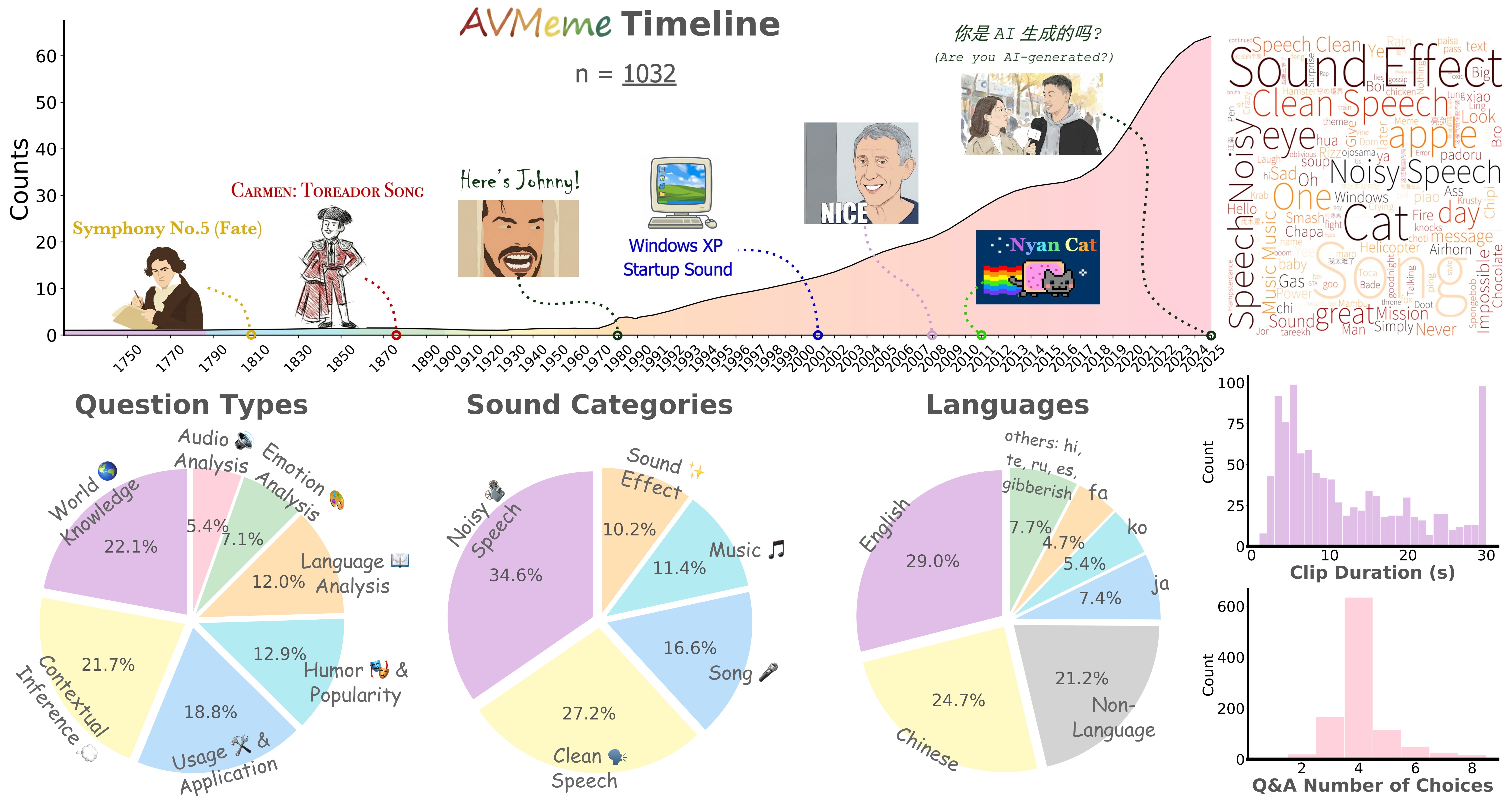
Несмотря на значительный прогресс в обработке естественного языка, современные мультимодальные модели зачастую демонстрируют ограниченные возможности в понимании культурного контекста и неявных смыслов. В данной работе представлена новая мультикультурная база данных ‘AVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs’ Contextual and Cultural Knowledge and Thinking’ — набор из более тысячи аудиовизуальных мемов, предназначенный для оценки способности моделей понимать контекст и культурные нюансы. Полученные результаты указывают на существенные пробелы в понимании нетекстовых мультимодальных данных, особенно в отношении музыки и звуковых эффектов, и подтверждают, что модели испытывают трудности с культурной интерпретацией. Какие новые подходы необходимы для создания действительно «культурно осведомленных» мультимодальных систем искусственного интеллекта?
Иллюзии Прогресса: За Пределами Текстового Понимания
Современные большие языковые модели, демонстрирующие впечатляющую способность к обработке текста, зачастую испытывают затруднения при интерпретации мультимодального контента, такого как аудиовизуальные мемы. Несмотря на способность распознавать слова и фразы, модели не способны полноценно уловить контекст, юмор и культурные отсылки, заложенные в сочетании изображения и звука. Это связано с тем, что они анализируют только текстовую составляющую, игнорируя визуальные и слуховые элементы, которые несут ключевую информацию для понимания смысла. В результате, модели могут выдавать неверные или неполные интерпретации, упуская тонкие нюансы и истинный посыл мема, что подчеркивает необходимость разработки более совершенных систем, способных к комплексному анализу различных типов данных.
Исследования показывают, что современные языковые модели часто полагаются на упрощенные текстовые интерпретации, что приводит к неверному пониманию многослойного контента, такого как мемы или видео с озвучкой. Вместо глубокого анализа визуальных и звуковых элементов, модели склонны вычленять ключевые слова и фразы, игнорируя сарказм, иронию или культурные аллюзии, которые являются неотъемлемой частью смысла. Это приводит к тому, что модель может упустить важные нюансы, неправильно истолковать юмор или даже полностью пропустить скрытый смысл, что демонстрирует ограниченность подхода, основанного исключительно на текстовых подсказках. Неспособность учитывать контекст и культурные отсылки существенно снижает способность модели к полноценному пониманию и адекватному реагированию на сложные стимулы.
Ограниченность современных больших языковых моделей в понимании мультимодального контента подчеркивает необходимость разработки систем, способных к истинному мультимодальному рассуждению. Недостаточно просто анализировать текст; для полноценного осмысления информации требуется интеграция данных из различных источников — визуальных, звуковых и других. Такой подход позволит моделям не только распознавать отдельные элементы, но и устанавливать связи между ними, учитывать контекст и культурные особенности, что крайне важно для корректной интерпретации сложных явлений, таких как юмор или сатира. В конечном итоге, развитие мультимодального рассуждения откроет путь к созданию искусственного интеллекта, способного понимать мир так же, как и человек — через совокупность различных сенсорных данных и ассоциаций.
Культурный Код: Расшифровка Мемов и Контекста
Успешное понимание мемов напрямую зависит от наличия у модели общих культурных знаний и способности к контекстуальному выводу. Это означает, что для интерпретации мема недостаточно просто распознать визуальные или слуховые элементы; необходимо понимать исторические отсылки, социальные коннотации и подразумеваемые значения, которые разделяются определенной культурной группой. Способность к контекстуальному выводу позволяет модели соотносить наблюдаемые элементы с соответствующими культурными рамками и, таким образом, корректно интерпретировать намерение автора мема и его скрытый смысл.
Для успешной интерпретации видеоконтента, в частности мемов, недостаточно простого распознавания объектов, присутствующих в кадре. Современные языковые модели (LLM) должны уметь извлекать подразумеваемый смысл, учитывать исторические аллюзии и понимать социальную значимость изображенных событий или персонажей. Это включает в себя способность модели соотносить визуальные данные с существующими культурными знаниями и контекстом, чтобы правильно определить намерение автора и передаваемое сообщение. Распознавание отдельных элементов без понимания их взаимосвязи и культурной подоплеки приводит к неверной интерпретации и утрате смысла.
Для точной интерпретации намерений, заложенных в меме, модель должна интегрировать визуальные и слуховые сигналы с существующими культурными знаниями. Это означает, что распознавание объектов или действий в видео недостаточно; необходимо сопоставить эти данные с накопленной информацией о социальных нормах, исторических событиях и общепринятых значениях. Процесс включает в себя не просто идентификацию элементов, но и установление связей между ними и соответствующим культурным контекстом, что позволяет модели понять подразумеваемый смысл и намерения автора мема. Эффективная интеграция этих данных обеспечивает адекватное понимание и интерпретацию мема, учитывая все нюансы культурного фона.
Мультимодальный Анализ: Слияние Зрения, Слуха и Смысла
Мультимодальные языковые модели (MultimodalLLMs) обрабатывают аудиовизуальный контент посредством комплексного анализа, включающего в себя обработку аудио (AudioAnalysis), лингвистический анализ текста (LanguageAnalysis) и интерпретацию визуальных сигналов (VisualCues). Аудиоанализ позволяет извлекать информацию из звуковых данных, такую как речь, музыка или окружающие шумы. Лингвистический анализ обрабатывает текстовые данные, определяя синтаксис, семантику и контекст. Интерпретация визуальных сигналов включает в себя распознавание объектов, действий и сцен, представленных в визуальном потоке. Комбинирование этих методов позволяет модели формировать более полное представление о происходящем и улучшает понимание контента.
Распознавание эмоций и интерпретация визуальных подсказок являются критически важными компонентами современных мультимодальных моделей. Эти механизмы позволяют моделям выходить за рамки буквального понимания входных данных, улавливая скрытые намерения и смысл, выраженные через невербальные сигналы. Анализ эмоций, проявляющихся в голосе или выражении лица, в сочетании с распознаванием визуальных знаков, таких как жесты или контекст окружающей обстановки, существенно повышает способность модели к пониманию сложных ситуаций и адекватному реагированию на них. Данный подход особенно важен для задач, требующих понимания человеческой коммуникации и взаимодействия, например, в сфере обслуживания клиентов или в разработке интеллектуальных помощников.
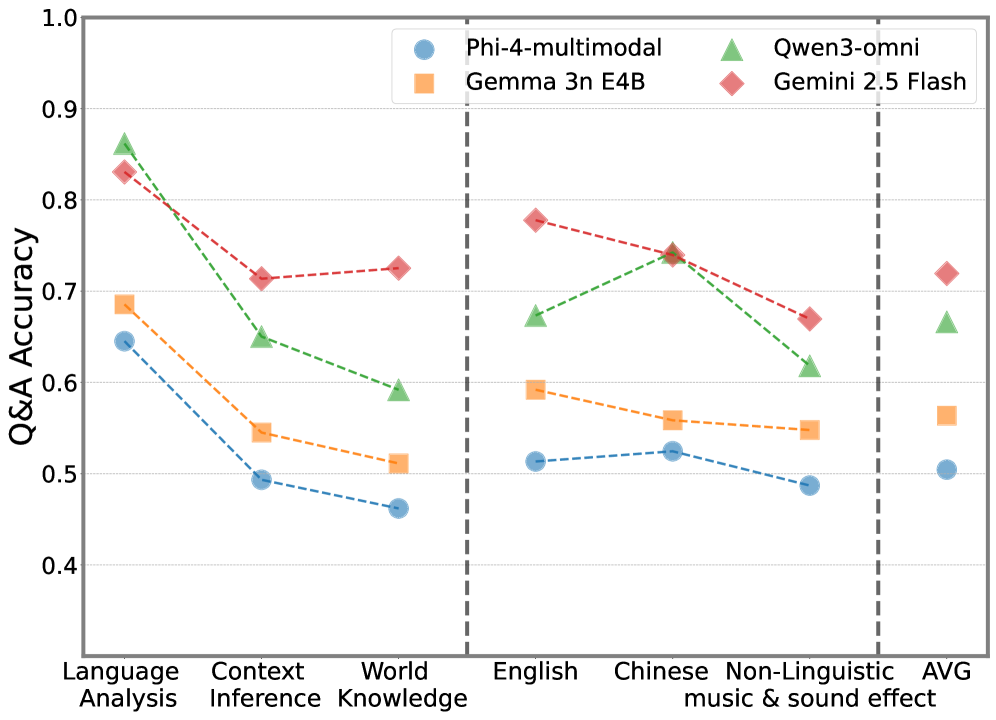
Текущие модели, такие как Gemini 3 Pro, демонстрируют значительное повышение точности при обработке мультимодальных данных. Согласно результатам тестирования, точность модели составляет 76.6% при решении задач, основанных исключительно на аудио, и возрастает до 80.0% при одновременной обработке аудио и визуальной информации. Данный прирост в 3.4% подтверждает эффективность интеграции различных модальностей данных для улучшения производительности моделей в задачах анализа и понимания контента.
Наблюдается значительный разрыв в производительности, составляющий примерно 30-40%, между задачами анализа языка и задачами, требующими применения общих знаний о мире. Это указывает на трудности, возникающие у моделей при понимании контекста и выполнении логических выводов, выходящих за рамки простого синтаксического и семантического анализа. Неспособность эффективно интегрировать общие знания ограничивает способность моделей к полноценному контекстному рассуждению и интерпретации информации, особенно в ситуациях, требующих понимания неявных смыслов и подразумеваемых связей.

AVMemeExam: Испытание Истинного Мультимодального Понимания
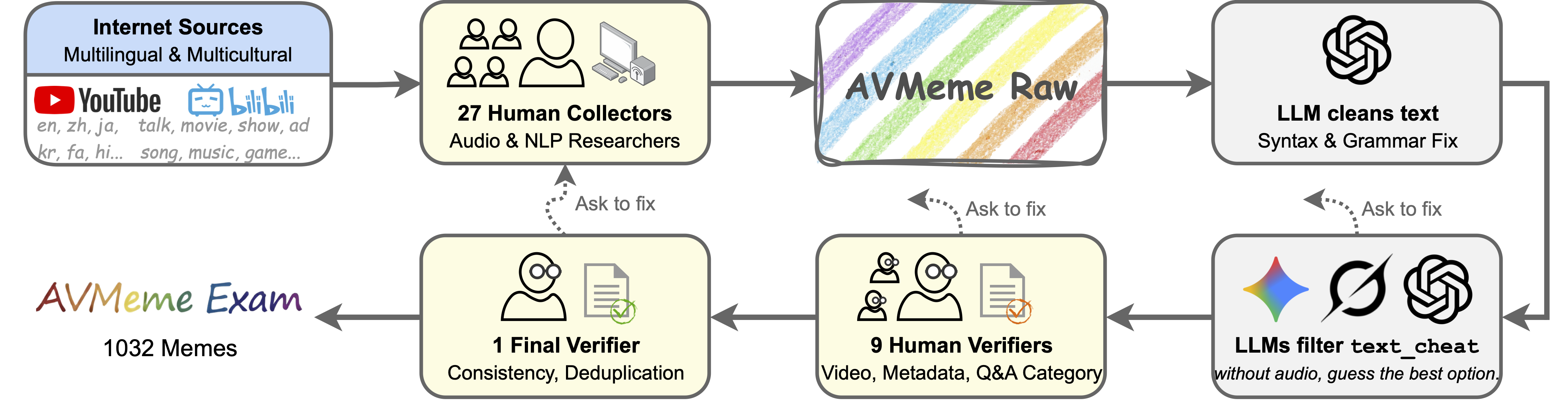
Бенчмарк AVMemeExam специально разработан для оценки способности больших языковых моделей (LLM) понимать аудиовизуальные мемы. Данный тест выходит за рамки простого распознавания объектов или действий, требуя от моделей комплексного анализа содержания, контекста и культурных отсылок, заложенных в мемах. Оценка строится на проверке, насколько точно модель способна интерпретировать юмор, иронию и другие нюансы, характерные для данного типа контента, что делает AVMemeExam уникальным инструментом для определения истинного мультимодального понимания, а не просто поверхностной обработки данных.
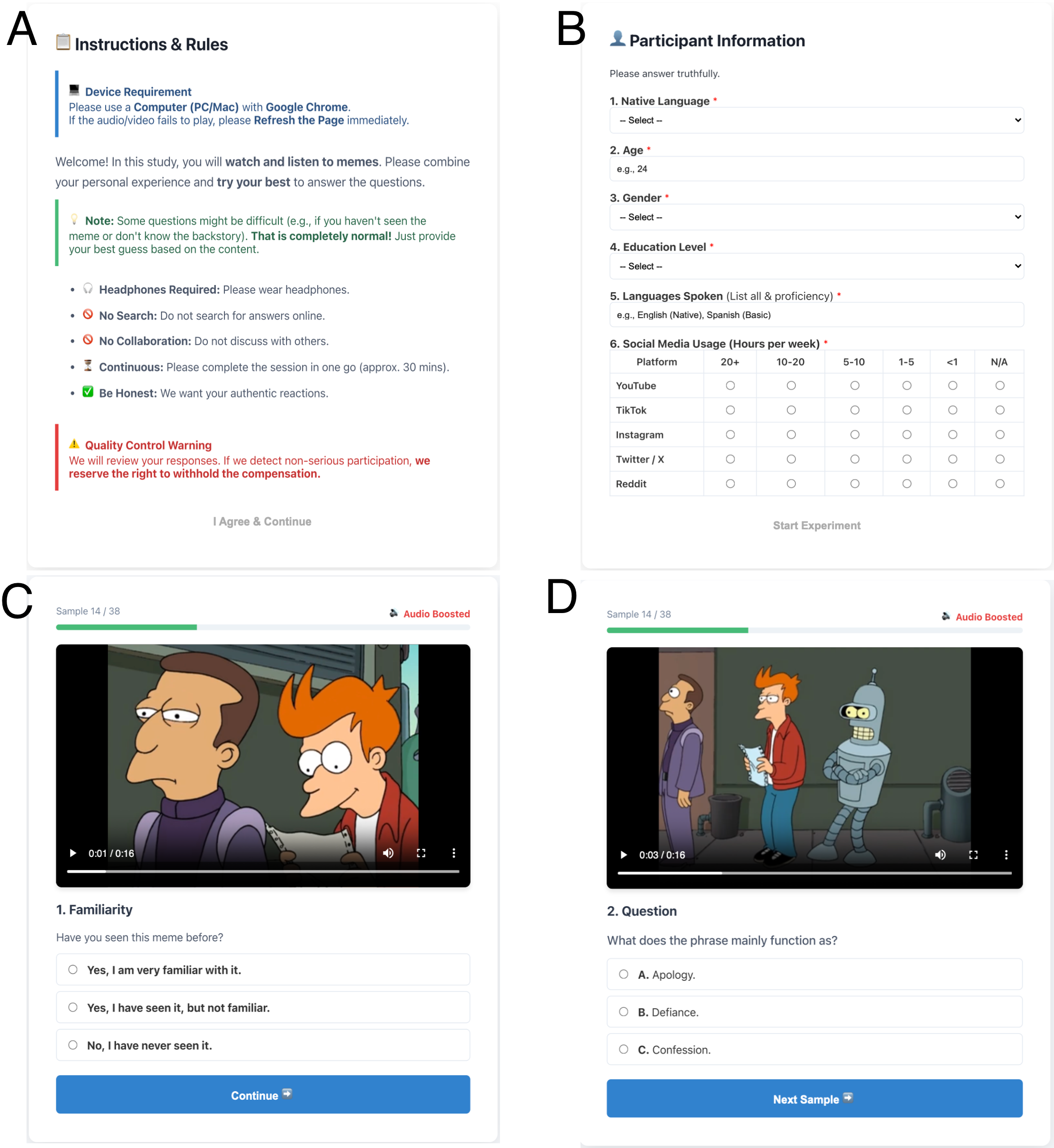
Оценка результатов, основанная на участии людей, является ключевым аспектом при тестировании моделей искусственного интеллекта, поскольку позволяет выявить их способность понимать тонкие нюансы и избегать неверных интерпретаций. В отличие от автоматизированных метрик, которые могут оценивать лишь поверхностное соответствие, человеческая оценка способна уловить контекстуальные особенности и культурные отсылки, необходимые для полноценного понимания, особенно в сложных задачах, таких как анализ аудиовизуальных мемов. Этот подход позволяет выявить не только точность модели, но и качество ее понимания, а также ее способность к рассуждению и адаптации к различным контекстам, что является важным шагом на пути к созданию действительно интеллектуальных систем.
Исследование, проведенное в рамках AVMemeExam, показало, что современные языковые модели, демонстрируя успехи в определенных аспектах понимания аудиовизуальных мемов, всё ещё испытывают трудности с выведением контекстуальных смыслов. Несмотря на способность распознавать отдельные элементы и даже некоторые закономерности, модели часто не могут уловить тонкие нюансы и культурные отсылки, необходимые для адекватной интерпретации мема. Примечательно, что подобные ошибки в понимании не являются уникальными для искусственного интеллекта — люди также могут допускать неверные суждения, если им не хватает необходимой информации или контекста. Этот факт подчеркивает сложность задачи и указывает на необходимость дальнейших исследований в области развития способности моделей к логическому выводу и пониманию неявных смыслов.
Анализ подмножества «визуальные подсказки» в тесте AVMemeExam продемонстрировал значительное — более чем на 40% — повышение точности распознавания мемов. Этот результат подчеркивает, что современные модели часто полагаются на прямые визуальные сигналы, а не на глубокое понимание контекста и культурных отсылок. Такая тенденция указывает на необходимость разработки более совершенных алгоритмов, способных к сложному рассуждению и интерпретации информации, выходящей за рамки поверхностного анализа визуального ряда. Успешное распознавание мемов требует не просто идентификации объектов на изображении, но и понимания иронии, сарказма и культурных особенностей, которые зачастую являются ключевыми для правильной интерпретации.
Путь Вперед: Открытые и Закрытые Модели
Развитие мультимодальных больших языковых моделей (LLM) происходит благодаря усилиям, направленным как на создание открытых, так и закрытых источников. Открытые модели, такие как LLaVA и IDEFICS, предоставляют исследователям и разработчикам полный доступ к архитектуре и весам, стимулируя инновации и позволяя адаптировать модели под специфические задачи. В то же время, закрытые модели, разрабатываемые такими компаниями как OpenAI и Google, часто демонстрируют передовые результаты благодаря значительным вычислительным ресурсам и тщательно подобранным данным для обучения. Каждая стратегия имеет свои преимущества и ограничения: открытость способствует прозрачности и кастомизации, а закрытость — более быстрому прогрессу и оптимизации производительности. В конечном итоге, синергия между этими подходами, а также постоянное преодоление технических сложностей, является ключевым фактором в создании действительно интеллектуальных систем, способных к полноценному восприятию и взаимодействию с окружающим миром.
Дальнейшие исследования и совместная работа имеют решающее значение для расширения границ мультимодального рассуждения, что необходимо для создания искусственного интеллекта, способного по-настоящему понимать и взаимодействовать с окружающим миром. Развитие систем, способных объединять и анализировать информацию, поступающую из различных источников — зрения, слуха, текста — требует глубокого изучения принципов когнитивной обработки и разработки новых алгоритмов. Совместные усилия исследователей из разных областей науки — лингвистики, информатики, нейробиологии — позволят создать более совершенные модели, способные не просто распознавать образы и звуки, но и интерпретировать их в контексте, извлекать смысл и делать обоснованные выводы. Преодоление существующих ограничений в области мультимодального понимания откроет новые возможности для создания интеллектуальных систем, способных решать сложные задачи в различных сферах — от робототехники и автономного транспорта до медицины и образования.
Точное понимание аудиовизуальных мемов является важным шагом на пути к созданию искусственного интеллекта, обладающего подлинным культурным интеллектом и контекстуальным пониманием. Способность системы распознавать юмор, иронию и отсылки, заложенные в таких форматах, требует не просто анализа визуального и звукового контента, но и понимания социальных норм, текущих трендов и культурных особенностей. Успешное декодирование мемов демонстрирует способность ИИ выходить за рамки буквального восприятия и улавливать скрытые смыслы, что необходимо для естественного и эффективного взаимодействия с человеком. Это указывает на прогресс в развитии систем, способных не только обрабатывать информацию, но и интерпретировать ее в контексте человеческой культуры и социального взаимодействия, открывая новые возможности для создания более интеллектуальных и адаптивных искусственных интеллектов.

Данное исследование, представляющее AVMeme Exam, закономерно выявляет пробелы в понимании контекста и культуры у современных мультимодальных LLM. Недостаточно просто оперировать языком; необходимо улавливать тонкие нюансы, отсылки и подтексты, которые формируют основу мемов. Как точно подметил Линус Торвальдс: «Плохой код похож на плохую шутку: если тебе нужно объяснить её, она не смешная». Аналогично, если LLM требуется детальное объяснение мема, значит, истинное понимание отсутствует. AVMeme Exam — это не просто тест на распознавание образов, а попытка оценить способность машин к культурной адаптации и контекстуальному мышлению, что, судя по результатам, пока даётся им с трудом.
Что дальше?
Представленный анализ, демонстрирующий пробелы в понимании аудиовизуальных мемов у современных многомодальных моделей, закономерно вызывает скепсис относительно заявленных прорывов. Каждая новая архитектура, обещающая «культурную осведомлённость», неизбежно столкнётся с реальностью, где контекст и ирония остаются недостижимыми для алгоритмов. В конечном итоге, AVMeme Exam — это не столько инструмент оценки, сколько напоминание о том, что «MVP» в области ИИ часто означает «подождите, мы потом разберемся с мемами».
Следующим этапом, вероятно, станет усложнение самих бенчмарков, добавление всё более тонких культурных нюансов и многослойной иронии. Однако, не стоит забывать, что любая метрика — это лишь приближение к реальности. Если код, претендующий на понимание юмора, выглядит идеально — значит, его ещё никто не тестировал на реальных пользователях.
Вместо гонки за всё более сложными моделями, возможно, стоит обратить внимание на более простые решения, фокусирующиеся на выявлении и смягчении культурных предубеждений. Ведь в конечном итоге, задача не в том, чтобы создать ИИ, который понимает мемы, а в том, чтобы создать ИИ, который не обижает людей, не понимая их культурного контекста. Это, пожалуй, более реалистичная цель, чем «революция в понимании юмора».
Оригинал статьи: https://arxiv.org/pdf/2601.17645.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Облачные вычисления для науки: гибкость и масштабируемость
2026-01-29 01:14