Автор: Денис Аветисян
Разработчики представили DeepSeek-OCR 2 — систему, способную глубже анализировать визуальную информацию в документах, используя принципы причинно-следственного анализа.
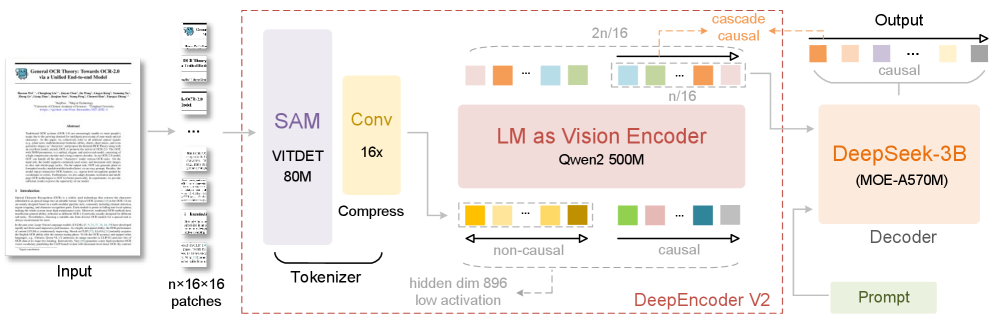
DeepSeek-OCR 2 использует инновационный LLM-совместимый энкодер DeepEncoder V2 и визуальную перестановку токенов для достижения передовых результатов на OmniDocBench v1.5.
В существующих моделях «зрение-язык» последовательность обработки визуальных токенов жестко задана, не отражая гибкость человеческого восприятия. В работе ‘DeepSeek-OCR 2: Visual Causal Flow’ представлен новый подход, использующий энкодер DeepEncoder V2, способный динамически переупорядочивать визуальные токены, опираясь на семантику изображения и принципы причинно-следственной логики. Это позволяет модели более эффективно понимать сложные макеты документов и достигать передовых результатов на OmniDocBench v1.5. Возможно ли, используя подобные механизмы, создать архитектуру, способную к подлинному двумерному рассуждению и более глубокому пониманию визуальной информации?
За пределами традиционного OCR: Стремление к причинно-следственному пониманию
Традиционные системы оптического распознавания символов (OCR) зачастую испытывают трудности при обработке документов со сложной структурой и тонкими визуальными особенностями. В отличие от простых изображений, реальные документы редко представляют собой идеально отформатированный текст. Наличие таблиц, многоколовочного текста, рукописных пометок, водяных знаков, а также различного рода графических элементов значительно усложняют задачу. Алгоритмы, основанные на простом сопоставлении шаблонов, оказываются неспособными адекватно интерпретировать такие документы, что приводит к ошибкам при распознавании и нарушению целостности информации. Особенно проблематичны случаи, когда визуальное представление текста отличается от стандартного — например, при наличии искажений, шумов или нестандартных шрифтов. В результате, точность распознавания существенно снижается, и требуется ручная корректировка, что делает процесс трудоемким и дорогостоящим.
Существующие методы оптического распознавания символов (OCR) зачастую сталкиваются с трудностями при анализе сложных документов из-за неспособности моделировать причинно-следственные связи между визуальными элементами. Вместо понимания того, как различные символы и блоки текста влияют друг на друга и формируют смысл документа, большинство систем полагаются на простое сопоставление шаблонов. Это приводит к ошибкам при разборе структуры документа, особенно в случаях, когда визуальное оформление не соответствует стандартным шаблонам или содержит неоднозначности. Например, система может неправильно интерпретировать расположение таблиц, заголовков или списков, если не учитывает взаимосвязь между этими элементами и основным текстом. В результате, даже незначительные визуальные искажения или необычный макет могут привести к существенным ошибкам в распознавании и извлечении информации.
Для достижения надёжного оптического распознавания символов (OCR) недостаточно простого сопоставления образов. Современные системы должны выходить за рамки идентификации отдельных знаков и стремиться к пониманию внутренней структуры и логики документа. Это означает моделирование взаимосвязей между визуальными элементами — заголовками, абзацами, таблицами, изображениями — и их ролью в передаче информации. Такой подход позволяет учитывать контекст, игнорировать шумы и артефакты, а также корректно интерпретировать сложные макеты документов, где традиционные методы часто дают сбой. Вместо простого «что здесь видно», требуется понимание «почему это расположено именно так» и «как это влияет на смысл документа», что открывает путь к созданию OCR-систем, способных к более глубокому и точному анализу информации.
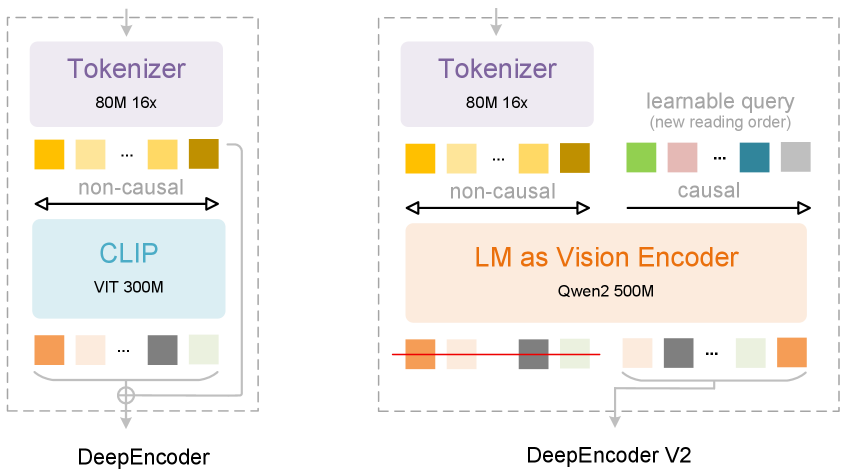
DeepEncoder V2: Дистилляция причинно-следственного потока в визуальных токенах
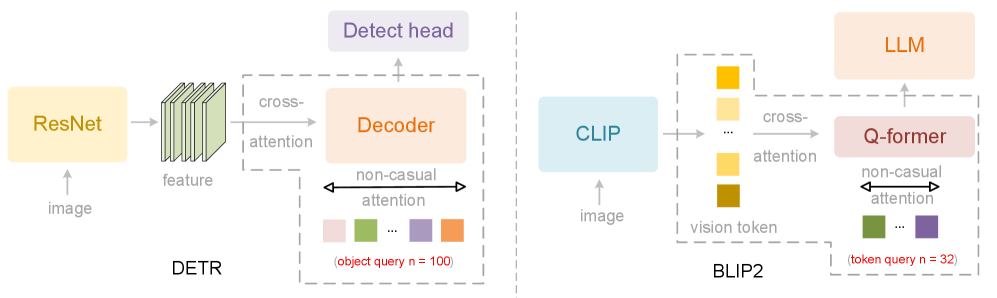
DeepEncoder V2 представляет собой новую архитектуру энкодера, которая расширяет возможности глобального моделирования, реализованные в CLIP, за счет интеграции принципов, используемых в больших языковых моделях (LLM). В отличие от традиционных подходов, полагающихся исключительно на глобальное агрегирование признаков, DeepEncoder V2 использует структуру, заимствованную из LLM, что позволяет более эффективно обрабатывать и представлять визуальную информацию. Это достигается путем применения механизмов внимания и слоев трансформации, которые изначально разрабатывались для обработки последовательностей текста, но адаптированы для обработки последовательности визуальных токенов, полученных из изображения. Такой подход позволяет моделировать сложные взаимосвязи между визуальными элементами и извлекать более содержательные представления изображения.
В архитектуре DeepEncoder V2 используется комбинация механизмов внимания для эффективной обработки визуальных токенов. Двунаправленное внимание (Bidirectional Attention) позволяет модели учитывать взаимосвязи между всеми токенами в потоке, сохраняя глобальный контекст изображения. Параллельно, каузальное внимание (Causal Attention) обрабатывает токены последовательно, моделируя зависимости между ними во времени или пространстве, что особенно важно для понимания порядка и взаимосвязей между визуальными элементами. Такое сочетание обеспечивает как общее понимание сцены, так и учет последовательности и причинно-следственных связей между отдельными объектами и их частями.
Архитектура DeepEncoder V2 использует токены потока причинности (Causal Flow Tokens) для явного представления и моделирования причинно-следственных связей между визуальными элементами. Эти токены кодируют информацию о том, как различные части изображения влияют друг на друга, позволяя модели не просто распознавать объекты, но и понимать их взаимосвязи. Каждый токен отражает влияние одного визуального элемента на другой, формируя направленный граф зависимостей внутри изображения. Это позволяет модели выполнять более сложные рассуждения, например, предсказывать последствия изменений в изображении или объяснять причины определенных визуальных явлений. В отличие от традиционных подходов, которые рассматривают изображение как набор независимых признаков, токены потока причинности обеспечивают структурированное представление, учитывающее взаимосвязи между элементами.
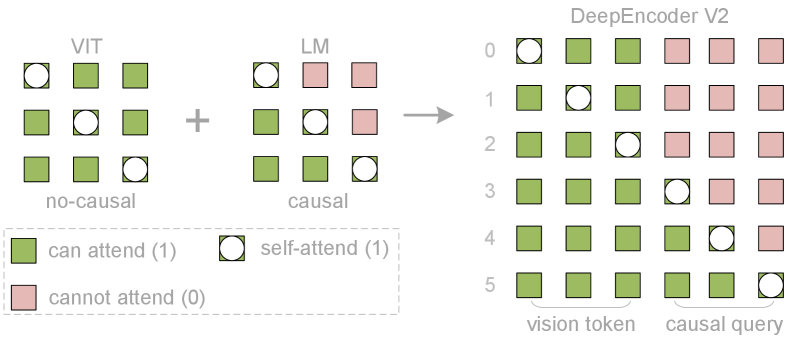
Оптимизация производительности и эффективности
DeepEncoder V2 использует многокадровый подход (Multi-crop Strategy) для обработки изображений, заключающийся в последовательной обработке одного и того же изображения в нескольких масштабах и разрешениях. Этот метод позволяет модели извлекать признаки на разных уровнях детализации, что повышает её устойчивость к изменениям масштаба и перспективы на изображении. В процессе обучения модель получает данные, представленные в различных разрешениях, что способствует более надежному и точному распознаванию объектов и сцен, особенно в сложных или зашумленных условиях. Использование нескольких кадровых разрешений также позволяет уменьшить влияние артефактов, возникающих при изменении размеров изображения.
Маска внимания в DeepEncoder V2 тщательно регулирует взаимодействие между токенами, ограничивая области, к которым каждый токен может обращаться при вычислении контекста. Это позволяет оптимизировать использование вычислительных ресурсов за счет исключения ненужных операций внимания, а также предотвращает утечку информации между несвязанными частями входных данных. Контроль над вниманием осуществляется путем применения бинарной маски, которая определяет, какие пары токенов могут взаимодействовать друг с другом во время процесса вычисления внимания.
Вся система обучения построена на задаче языкового моделирования, что предполагает совместную оптимизацию энкодера и легковесного декодера DeepSeek-3B-A500M. Данный подход позволяет не только улучшить общую производительность системы, но и способствует более эффективному представлению информации, извлеченной из входных данных. Использование языкового моделирования в качестве целевой функции обучения позволяет декодеру генерировать последовательности, соответствующие вероятностному распределению, обусловленному выходными данными энкодера, что повышает точность и связность генерируемого контента.
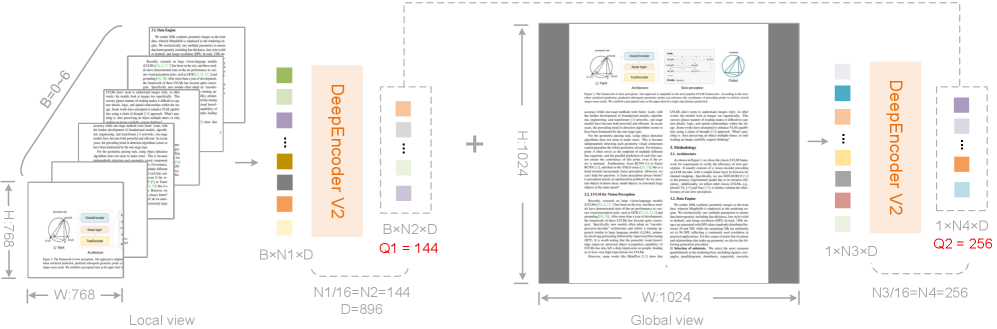
Подтверждение производительности и практическая готовность
Система DeepSeek-OCR 2 демонстрирует передовые результаты в области оптического распознавания символов, достигнув точности в 91.09% на бенчмарке OmniDocBench v1.5. Это представляет собой значительный прогресс, обеспечивая улучшение производительности на 3.73% по сравнению с предыдущей версией DeepSeek-OCR. Достигнутая точность свидетельствует о значительном повышении эффективности алгоритмов распознавания и обработки документов, позволяя системе более надежно извлекать текстовую информацию из разнообразных источников и форматов. Подобный уровень производительности открывает новые возможности для автоматизации процессов, связанных с оцифровкой и анализом документов, а также для повышения качества и скорости обработки больших объемов текстовых данных.
Система DeepSeek-OCR 2 значительно повысила точность определения порядка чтения текста на изображениях и в документах. В ходе тестирования удалось снизить метрику Edit Distance (ED) для определения порядка чтения (R-order) с 0.085 до 0.057. Это означает, что система стала более эффективно восстанавливать логическую последовательность слов и предложений, что критически важно для корректного извлечения информации и последующей обработки текста. Улучшение порядка чтения позволяет избежать ошибок при распознавании длинных текстов и сложных документов, обеспечивая более качественный результат и повышая удобство использования системы для различных задач, связанных с анализом и обработкой текстовой информации.
В ходе тестирования DeepSeek-OCR 2 продемонстрировал превосходные возможности по структурированию документов. Показатель Edit Distance, характеризующий отклонение от идеальной структуры, составил 0.100, что значительно ниже, чем у Gemini-3 Pro (0.115) при сопоставимом объеме визуальных токенов. Данный результат свидетельствует о более точном определении логической структуры документа, включая заголовки, абзацы и таблицы, что крайне важно для последующей обработки и анализа информации. Превосходство в парсинге документов позволяет DeepSeek-OCR 2 не только извлекать текст, но и сохранять его организацию, обеспечивая более эффективное использование полученных данных.
Помимо повышения точности распознавания, DeepSeek-OCR 2 уделяет особое внимание практической пригодности системы. В ходе тестирования зафиксировано значительное снижение частоты повторений — до 4,17% при анализе изображений, полученных от пользователей в режиме онлайн, и 2,88% при обработке данных из PDF-документов. Эти показатели существенно ниже, чем у предыдущей версии модели, где соответствующие значения составляли 6,25% и 3,69%. Такое снижение частоты повторений свидетельствует о повышенной надежности и стабильности работы DeepSeek-OCR 2 в реальных условиях эксплуатации, что критически важно для практического применения в различных областях, от автоматизации документооборота до обработки пользовательского контента.
К нативной мультимодальности и за её пределы
DeepSeek-OCR 2 знаменует собой существенный прорыв в области так называемой “нативной мультимодальности”, открывая путь к беспрепятственной интеграции визуальной информации с другими форматами данных, такими как текст и аудио. Эта разработка позволяет системам не просто распознавать символы на изображениях, но и понимать их контекст в сочетании со звуком или текстом, что существенно расширяет возможности анализа и обработки информации. В отличие от традиционных подходов, требующих отдельных этапов для обработки каждого типа данных, DeepSeek-OCR 2 обеспечивает единую, взаимосвязанную систему, способную комплексно интерпретировать различные модальности, что, в свою очередь, позволяет создавать более интеллектуальные и адаптивные приложения, например, в области автоматизированного анализа документов или создания мультимедийного контента.
Основой эффективности DeepSeek-OCR 2 является не просто распознавание визуальных паттернов, а моделирование причинно-следственных связей внутри изображений. Такой подход позволяет системе не просто “видеть” отдельные элементы, но и понимать, как они взаимодействуют друг с другом, что значительно повышает устойчивость к шумам и искажениям. Принципы, успешно примененные к анализу визуальных данных, могут быть адаптированы для работы с другими сложными типами информации, такими как временные ряды, графы знаний или даже последовательности ДНК. Это открывает перспективы для создания универсальных моделей искусственного интеллекта, способных к глубокому пониманию и анализу данных различной природы, и, в конечном итоге, к решению более широкого спектра задач.
Предстоящие исследования сосредоточены на масштабировании разработанных методов обработки изображений, используя значительно большие объемы данных для повышения точности и эффективности. Особое внимание уделяется применению этих технологий в задачах, связанных с пониманием документов и извлечением информации, где способность к анализу сложных визуальных структур играет ключевую роль. Ученые стремятся к созданию систем, способных не просто распознавать текст на изображениях, но и интерпретировать его смысл в контексте общего документа, что открывает перспективы для автоматизации обработки больших объемов информации в различных областях, включая архивное дело, юридическую практику и научные исследования. Дальнейшее развитие этих технологий позволит значительно упростить и ускорить процессы, связанные с анализом и пониманием визуальной информации.
Представленная работа демонстрирует стремление к элегантности в решении задачи оптического распознавания документов. Модель DeepSeek-OCR 2, используя инновационный LLM-подобный энкодер DeepEncoder V2, достигает значительных результатов за счёт улучшения причинно-следственного анализа и реорганизации визуальных токенов. Как однажды заметил Дэвид Марр: «Вычислительная теория разума должна объяснить, как из физических систем возникают ментальные процессы». Этот принцип находит отражение в архитектуре DeepSeek-OCR 2, где сложные визуальные данные преобразуются в структурированное представление, позволяющее модели эффективно понимать и интерпретировать содержимое документов. Последовательность в обработке визуальной информации, как и в любом сложном вычислении, является проявлением эмпатии к структуре данных и ключом к эффективному решению задачи.
Куда же дальше?
Представленная работа, подобно искусно настроенному инструменту, демонстрирует возможности извлечения смысла из визуального потока информации. Однако, как и в любой симфонии, остаются пробелы. Успех DeepSeek-OCR 2 на OmniDocBench v1.5 — это не финальный аккорд, а скорее удачное соло. Вопрос в том, как добиться истинной гармонии между обработкой визуальных данных и языковым пониманием, не ограничиваясь лишь эталонными наборами данных. Существующие модели, даже столь продвинутые, всё ещё склонны к поверхностному анализу, упуская нюансы, скрытые в тонкостях визуального оформления документов.
Будущее исследований, вероятно, лежит в области более глубокого моделирования причинно-следственных связей, не просто “видеть” элементы документа, а понимать их роль и взаимосвязь. Необходимо стремиться к созданию систем, способных к адаптации к различным стилям и форматам документов, к пониманию контекста, который часто неявно заложен в визуальном представлении. Интерфейс «поёт», когда элементы согласованы, но истинное пение требует способности импровизировать, находить новые решения, выходящие за рамки заученных шаблонов.
И, наконец, важно помнить, что даже самая незначительная деталь имеет значение, даже если её не замечают. Совершенствование алгоритмов сжатия визуальных токенов, оптимизация архитектуры энкодера — всё это лишь отдельные шаги на пути к созданию системы, способной не просто распознавать текст, а действительно понимать документы, словно опытный читатель, вдумчиво перелистывающий страницы.
Оригинал статьи: https://arxiv.org/pdf/2601.20552.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Квантовая механика: скрытый детерминизм?
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Мгновенная расшифровка: Voxtral Realtime на службе у скорости
2026-01-29 13:09