Автор: Денис Аветисян
Новое исследование показывает, что кэш KV, традиционно применяемый для ускорения генерации текста, может быть перепрофилирован для задач самооценки и адаптивного рассуждения, открывая новые возможности для эффективного использования ресурсов.
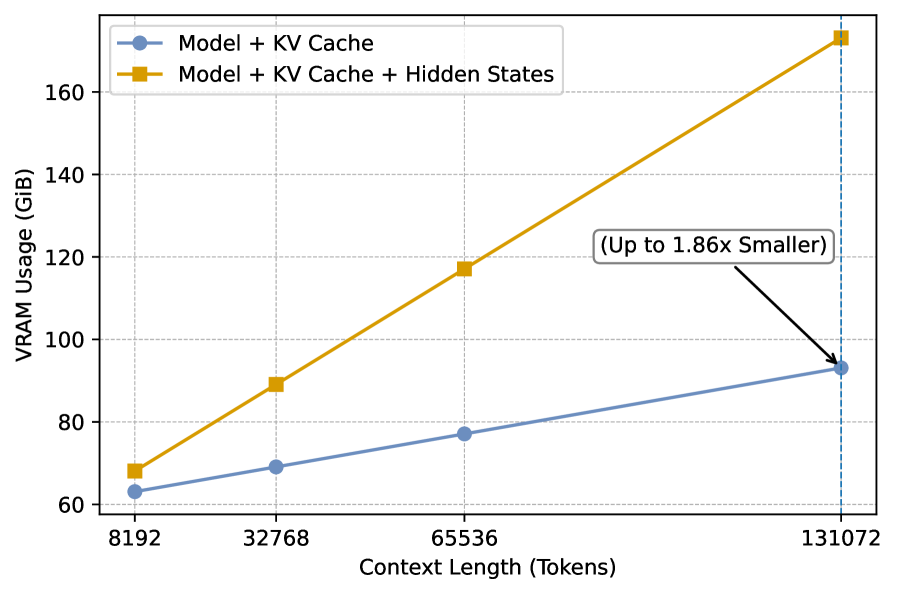
Кэш KV используется в качестве переиспользуемого представления скрытых состояний для повышения эффективности и расширения возможностей больших языковых моделей.
Оптимизация больших языковых моделей (LLM) часто сосредотачивается на увеличении скорости генерации, упуская из виду потенциал скрытых представлений. В работе ‘Beyond Speedup — Utilizing KV Cache for Sampling and Reasoning’ предложено использовать кэш KV — структуру, традиционно применяемую для ускорения авторегрессивной декодировки — в качестве легковесного представления контекста для задач, требующих рассуждений и самооценки. Показано, что извлеченные из кэша KV представления, несмотря на их меньшую выразительность по сравнению с полными скрытыми состояниями, достаточны для эффективной реализации методов ‘Chain-of-Embedding’ и адаптивного переключения между режимами ‘быстрого’ и ‘медленного’ мышления, сокращая время генерации токенов до 5.7\times с минимальными потерями точности. Может ли переосмысление существующих структур данных LLM открыть новые пути для повышения эффективности и снижения вычислительных затрат при выводе?
Логический тупик больших языковых моделей
Несмотря на впечатляющие размеры и объём данных, используемых для обучения, большие языковые модели (БЯМ) зачастую демонстрируют трудности при решении задач, требующих сложного логического мышления. Эта проблема особенно ярко проявляется при обработке длинных текстов и контекстов, где модели испытывают трудности с удержанием важной информации и установлением связей между отдельными элементами. Неэффективность обработки длинных последовательностей ограничивает способность БЯМ к глубокому анализу, синтезу и выводу, что препятствует их применению в задачах, требующих многоступенчатого рассуждения, таких как научные исследования, юридический анализ или разработка сложных стратегий. Это указывает на то, что простое увеличение масштаба моделей не является достаточным для достижения подлинного интеллекта и что необходимы инновационные архитектурные решения для улучшения их способности к логическому мышлению.
Традиционный метод авторегрессивного декодирования, лежащий в основе работы многих больших языковых моделей, сталкивается с серьезными ограничениями при обработке длинных последовательностей текста. В основе этого метода лежит кэш ключей и значений (KV Cache), который хранит промежуточные результаты вычислений для ускорения генерации. Однако, с увеличением длины входного текста, размер KV Cache экспоненциально растет, требуя всё больше вычислительных ресурсов и памяти. Это приводит к замедлению процесса декодирования и, в конечном итоге, ограничивает способность модели к глубокому логическому выводу и решению сложных задач, требующих анализа большого объема информации. Таким образом, масштабируемость KV Cache становится узким местом, препятствующим дальнейшему развитию возможностей больших языковых моделей в области рассуждений.
Для осуществления эффективного рассуждения необходимы оптимизированные методы управления и доступа к релевантной информации, что диктует потребность в инновационных архитектурных решениях. Традиционные подходы часто сталкиваются с трудностями при обработке обширных контекстов, поскольку поддержание и извлечение ключевых данных из больших объемов информации становится вычислительно затратным. Поэтому, современные исследования направлены на разработку новых архитектур, способных динамически оценивать важность различных фрагментов информации и фокусироваться на наиболее релевантных для конкретной задачи. Такие подходы включают в себя механизмы внимания, позволяющие модели выборочно концентрироваться на определенных частях входных данных, и иерархические структуры памяти, обеспечивающие эффективное хранение и извлечение информации. Успешное внедрение подобных инноваций позволит значительно повысить способность больших языковых моделей к решению сложных задач, требующих глубокого анализа и логических выводов.
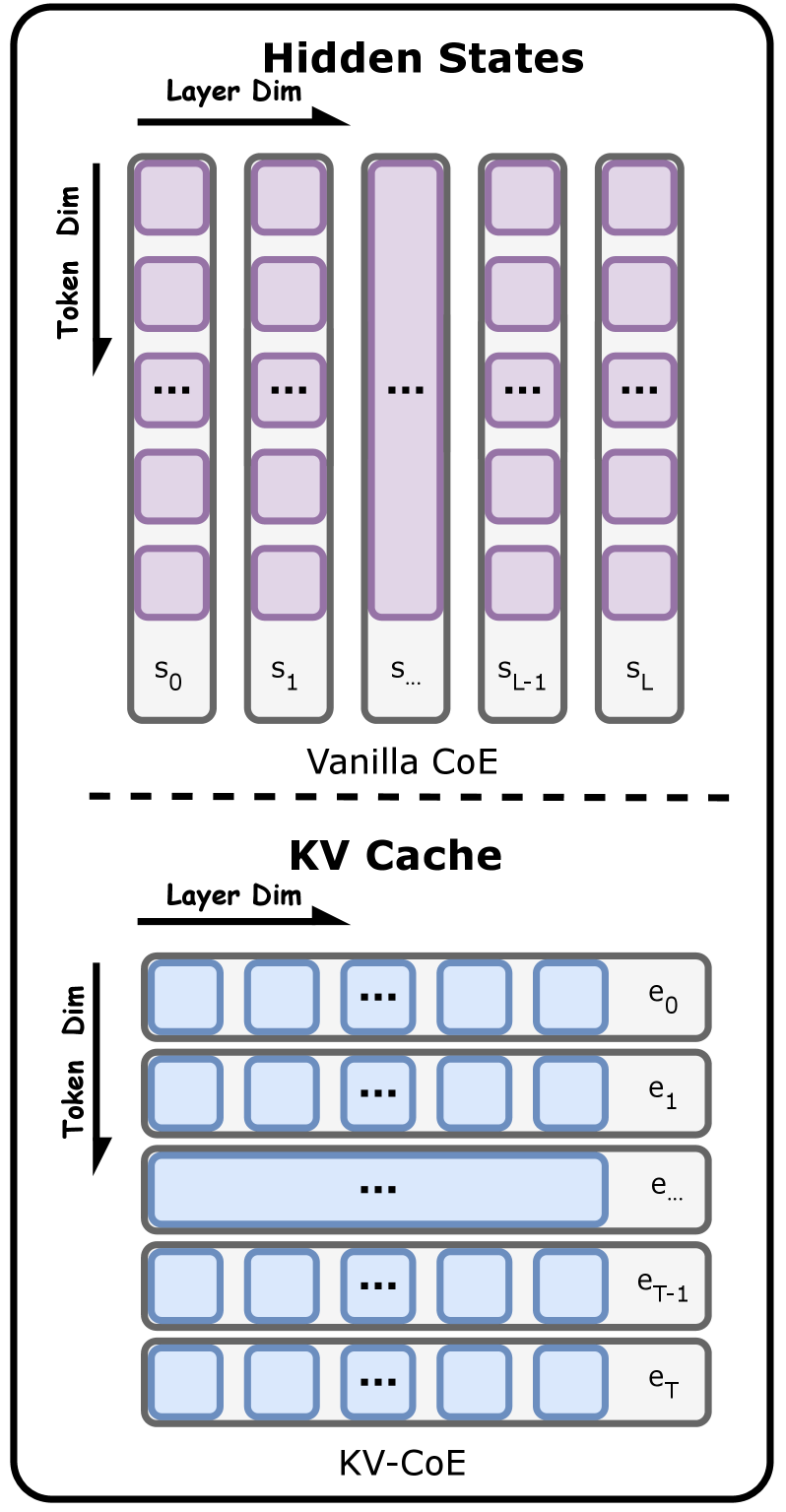
Динамическое рассуждение с адаптивной глубиной
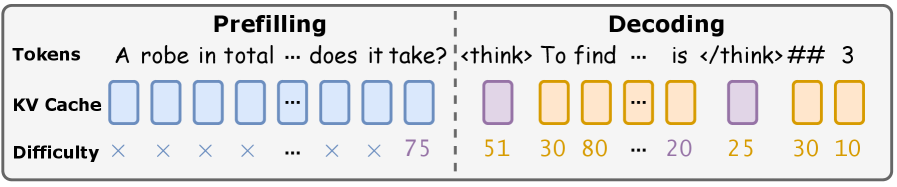
Адаптивное рассуждение представляет собой структуру, позволяющую языковым моделям (LLM) избирательно использовать режимы ‘быстрого’ или ‘медленного’ мышления, основываясь на оценке сложности входных данных. Оценка сложности, определяемая как Difficulty Score, служит критерием для переключения между режимами. В режиме ‘быстрого’ мышления модель опирается на эффективный прямой поиск информации из памяти, в то время как режим ‘медленного’ мышления активируется для выполнения детального, пошагового анализа, когда это необходимо. Этот механизм позволяет динамически распределять вычислительные ресурсы в зависимости от характеристик конкретного запроса, оптимизируя глубину рассуждений.
Быстрое мышление использует эффективность прямого извлечения информации из памяти, позволяя модели оперативно отвечать на простые запросы или задачи, требующие известных фактов. Медленное мышление, напротив, активирует детальный, пошаговый процесс рассуждений, необходимый для решения сложных задач, требующих анализа, логических выводов и применения знаний в новых контекстах. Переключение между этими режимами позволяет модели динамически адаптировать глубину рассуждений к сложности конкретного запроса, оптимизируя использование вычислительных ресурсов.
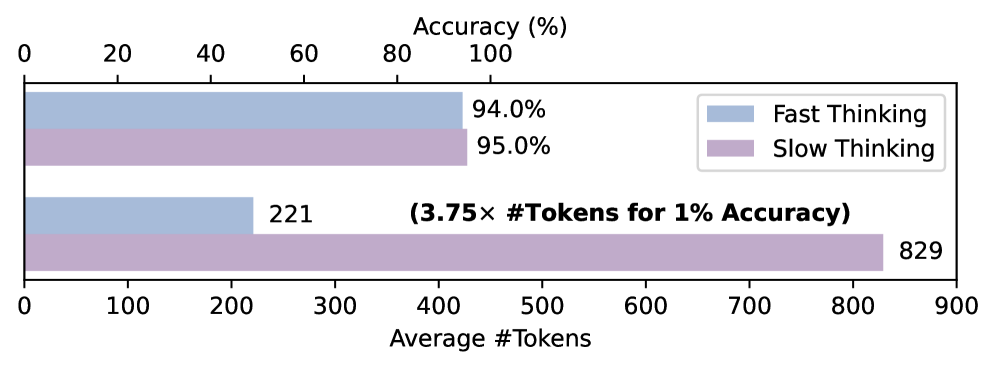
В ходе тестирования на наборе задач MATH500, применение адаптивного подхода к рассуждениям позволило добиться снижения количества используемых токенов до 5.7 раз. Данное снижение свидетельствует о существенной экономии вычислительных ресурсов, поскольку количество токенов напрямую связано с затратами на обработку и, следовательно, с общей стоимостью вычислений. Эффективность подхода подтверждается результатами, демонстрирующими возможность решения задач с меньшими вычислительными издержками без потери точности.
Переключение между режимами “быстрого” и “медленного” мышления позволяет динамически распределять вычислительные ресурсы в зависимости от сложности входных данных. Система оценивает сложность каждого запроса и, исходя из этой оценки, выбирает оптимальную глубину рассуждений. При низких оценках сложности активируется “быстрое” мышление, использующее прямые вызовы из памяти для эффективной обработки. При высоких оценках сложности переключается “медленное” мышление, которое обеспечивает детальный, пошаговый анализ для решения сложных задач. Такой подход позволяет адаптировать вычислительные затраты к конкретным требованиям каждого запроса, оптимизируя использование ресурсов.
KV-CoE: Использование KV-кэша для эффективного рассуждения
Механизм Chain of Embedding (CoE) предоставляет возможность самооценки, однако изначальная реализация опирается на скрытые состояния (Hidden States), что приводит к значительным вычислительным затратам. Скрытые состояния требуют обработки больших объемов данных и сложных матричных операций, что увеличивает время вычислений и потребление памяти. Использование скрытых состояний становится особенно проблематичным при работе с длинными последовательностями или при масштабировании модели для обработки больших объемов информации. В связи с этим, возникла необходимость в разработке более эффективных методов самооценки, которые бы снизили вычислительную сложность без существенной потери в качестве результатов.
KV-CoE представляет собой более эффективный подход к построению представлений, использующий эмбеддинги из KV-кэша (Key-Value Cache) вместо скрытых состояний. В отличие от традиционных методов, требующих вычислений на основе скрытых состояний, KV-CoE напрямую использует информацию, уже сохраненную в KV-кэше, что значительно снижает вычислительные затраты. Это позволяет получить сопоставимые результаты с использованием скрытых состояний, при этом требуя меньше ресурсов и обеспечивая более высокую скорость обработки. Данный подход особенно полезен в сценариях, где критична эффективность и масштабируемость, таких как обработка длинных последовательностей или работа с ограниченными вычислительными ресурсами.
Метод KV-CoE формирует комплексное представление входных данных посредством включения Token Embedding и применения двух стратегий агрегации. Token Embedding преобразует каждый токен во входном тексте в векторное представление. Layer-wise Aggregation аккумулирует информацию из различных слоев модели, позволяя учесть многоуровневые признаки. Token-centric Aggregation, в свою очередь, агрегирует информацию, ориентируясь на каждый отдельный токен, что позволяет учитывать контекст и взаимосвязи между токенами для создания более точного представления. Комбинация этих подходов обеспечивает эффективное извлечение и агрегирование информации из входных данных.
В задачах классификации, использование KV-CoE обеспечивает производительность, сопоставимую с использованием скрытых состояний (hidden states). Данный результат подтверждает эффективность KV-CoE как универсального и повторно используемого представления данных. Это означает, что KV-CoE может быть успешно применен в различных задачах классификации без значительной потери точности по сравнению с более ресурсоемкими методами, основанными на скрытых состояниях. Повторное использование представления позволяет снизить вычислительные затраты и повысить общую эффективность модели.
При использовании KV-CoE совместно с моделью Qwen3-8B, достигнута точность в 0.604 на датасете MATH500. Данный результат демонстрирует незначительное снижение производительности — всего 3.2% — по сравнению с полным процессом логического вывода (full reasoning). Это указывает на эффективность KV-CoE как метода создания компактных представлений, позволяющих сохранить высокую точность при решении математических задач.
Оценка результатов и перспективы на будущее
Оценка на базе Massive Text Embedding Benchmark (MTEB) подтвердила высокую эффективность механизма KV-CoE в генерации качественных векторных представлений текста. Данный подход позволяет модели создавать компактные и информативные эмбеддинги, что критически важно для широкого спектра задач, включая семантический поиск, кластеризацию и анализ текстовых данных. Результаты демонстрируют, что KV-CoE превосходит многие существующие методы в плане точности и эффективности представления семантического значения текста, открывая возможности для создания более продвинутых и ресурсоэффективных систем обработки естественного языка. Высокое качество генерируемых эмбеддингов способствует улучшению производительности моделей в задачах, требующих глубокого понимания смысла текста.
Механизм PagedAttention существенно оптимизирует кэш KV, представляющий собой критически важный компонент больших языковых моделей. В отличие от традиционных подходов с фиксированным выделением памяти, PagedAttention обеспечивает динамическое распределение ресурсов, что позволяет эффективно использовать доступную память и снижать вычислительные издержки. Данный подход разбивает кэш KV на отдельные страницы, аналогично виртуальной памяти в операционных системах, что позволяет загружать и выгружать страницы по мере необходимости. Такая организация не только повышает эффективность использования памяти, но и значительно улучшает масштабируемость модели, позволяя обрабатывать более длинные последовательности и обслуживать большее количество запросов одновременно. В результате, PagedAttention открывает возможности для создания более мощных и экономичных языковых моделей, способных решать сложные задачи при минимальном потреблении ресурсов.
Исследования показали, что модель, использующая архитектуру DeepSeek-R1-14B и KV-Generative, демонстрирует впечатляющую точность в 0.914 на бенчмарке GSM8K, решающем задачи математического рассуждения. Примечательно, что эта высокая результативность достигается при сниженном потреблении токенов, что свидетельствует об эффективности предложенного подхода к адаптивному рассуждению. Данное сочетание точности и экономичности токенов открывает перспективы для создания более компактных и производительных языковых моделей, способных решать сложные задачи с минимальными вычислительными затратами и ресурсами памяти.
Данная работа открывает новые перспективы в разработке более эффективных и надежных больших языковых моделей (LLM), способных решать сложные задачи рассуждения с минимальными вычислительными затратами. Исследование демонстрирует, что оптимизация архитектуры и методов управления памятью позволяет значительно снизить потребление ресурсов без потери точности. Это особенно важно для задач, требующих глубокого анализа и логических выводов, где традиционные модели часто сталкиваются с ограничениями по вычислительной мощности и энергопотреблению. Разработанные подходы позволяют создавать LLM, доступные для более широкого круга пользователей и применимые в условиях ограниченных ресурсов, что способствует развитию искусственного интеллекта в различных областях, от научных исследований до повседневных приложений.
Принципы адаптивного рассуждения и эффективного управления памятью, продемонстрированные в данной работе, имеют далеко идущие последствия для будущего искусственного интеллекта. Способность модели динамически выделять ресурсы и фокусироваться на наиболее релевантной информации не только повышает точность решения сложных задач, но и открывает путь к созданию более устойчивых и энергоэффективных систем. Такой подход позволяет преодолеть ограничения традиционных архитектур, требующих огромных вычислительных мощностей, и приближает нас к разработке интеллектуальных систем, способных к самообучению и адаптации в реальном времени. В перспективе, эти принципы могут быть применены в широком спектре областей, от автономных роботов и интеллектуальных ассистентов до сложных систем анализа данных и научных исследований, способствуя созданию более разумного и устойчивого будущего.
Исследование демонстрирует, что кэш KV, изначально предназначенный для ускорения декодирования больших языковых моделей, может быть эффективно использован в качестве переиспользуемого представления для задач самооценки и адаптивного рассуждения. Этот подход позволяет снизить вычислительные затраты, избегая необходимости полного доступа к скрытым состояниям. Как отмечал Блез Паскаль: «Все великие вещи требуют времени». Подобно тому, как для достижения глубины понимания требуется время и итерации, так и повторное использование информации, хранящейся в кэше KV, требует тонкой настройки и адаптации, чтобы раскрыть весь потенциал этой, казалось бы, простой концепции. Использование кэша KV для задач, выходящих за рамки ускорения вывода, подчеркивает важность переосмысления существующих инструментов и нахождения в них новых применений.
Что дальше?
Представленная работа, по сути, демонстрирует, что кэш KV, долгое время служивший лишь инструментом ускорения декодирования языковых моделей, обладает потенциалом, выходящим далеко за рамки простой оптимизации скорости. Вместо слепого наращивания вычислительных мощностей, можно ли взглянуть на этот кэш как на форму сжатой, переиспользуемой репрезентации знания? Очевидно, что это лишь первый шаг, и возникают вопросы: насколько эффективно можно «перегрузить» этот кэш для задач, требующих более сложного рассуждения, и где лежит предел его емкости? В конце концов, система, которую нельзя взломать, не обязательно понята.
Особый интерес представляет возможность адаптивного рассуждения и самооценки, основанных на кэше KV. Однако, стоит признать, что текущий подход, вероятно, чувствителен к специфике задачи и требует тонкой настройки. Неизбежен вопрос о генерализации: сможет ли эта методика эффективно применяться к разнообразным доменам и типам рассуждений, или же она останется узкоспециализированным решением? Ведь истинное понимание системы проявляется в способности адаптировать её к новым условиям.
В конечном счете, представленная работа заставляет задуматься о фундаментальных принципах организации знаний в больших языковых моделях. Если кэш KV способен служить своего рода «памятью» для рассуждений, то какие еще скрытые возможности таятся в архитектуре этих систем? Поиск этих возможностей, несомненно, станет ключевой задачей для будущих исследований, и, возможно, потребует пересмотра традиционных подходов к проектированию искусственного интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2601.20326.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Квантовая механика: скрытый детерминизм?
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Облачные вычисления для науки: гибкость и масштабируемость
2026-01-29 14:45