Автор: Денис Аветисян
Новый подход позволяет значительно снизить вычислительную нагрузку моделей, понимающих язык, зрение и действия, открывая путь к их использованию на мобильных и встраиваемых устройствах.
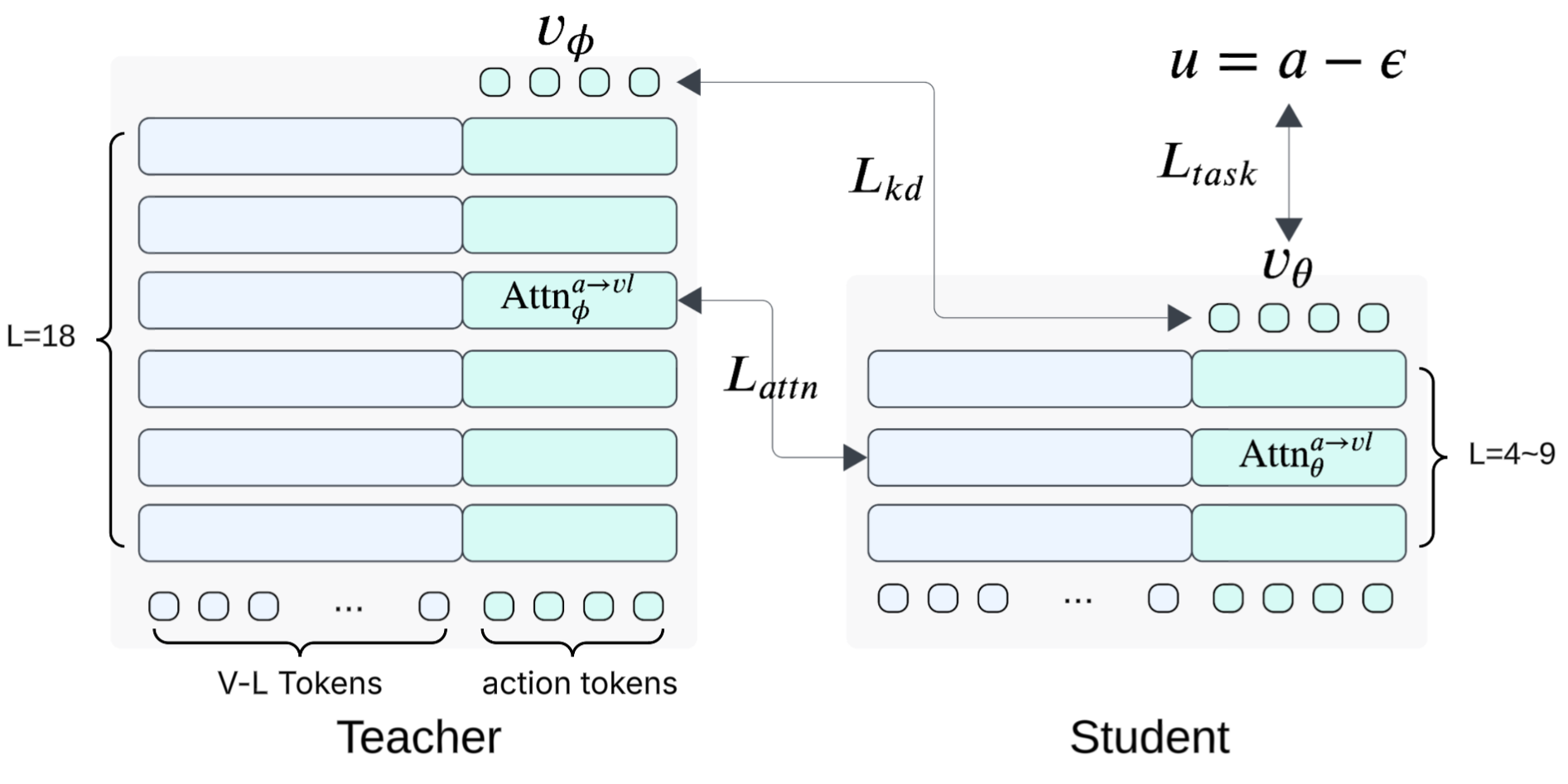
В статье представлена Shallow-π, схема дистилляции знаний, эффективно уменьшающая вычислительные затраты flow-based VLA моделей за счёт одновременной компрессии VLM-бэкенда и блока действий.
Растущий спрос на робототехнику реального времени требует быстрых и эффективных моделей для обработки визуальной информации, языка и действий. В данной работе, ‘Shallow-π: Knowledge Distillation for Flow-based VLAs’, предложен новый подход к уменьшению вычислительной сложности моделей Vision-Language-Action (VLA) посредством дистилляции знаний и агрессивного уменьшения глубины трансформерных слоев как в языковой, так и в исполнительной частях модели. Разработанный фреймворк Shallow-π позволяет ускорить процесс вывода более чем в два раза, практически не снижая точность манипуляций, и демонстрирует передовые результаты среди моделей VLA с уменьшенным количеством параметров. Возможно ли дальнейшее повышение эффективности и адаптация подобных методов для еще более сложных робототехнических систем и динамичных сред?
От простоты к пониманию: Основы воплощенного ИИ
Традиционные робототехнические системы часто сталкиваются с трудностями в сложных, реальных условиях из-за ограниченных возможностей восприятия, понимания и реагирования на визуальную информацию. Ограниченность заключается не только в обработке изображений, но и в интерпретации контекста, распознавании объектов в изменяющейся обстановке и предвидении последствий действий. Например, робот может успешно идентифицировать стул, но не сможет понять, что этот стул заблокировал проход, или что его необходимо отодвинуть для выполнения поставленной задачи. Такие недостатки приводят к ошибкам в навигации, неэффективному выполнению задач и общей неспособности адаптироваться к динамичной окружающей среде, что существенно ограничивает применение роботов в повседневной жизни и промышленности.
Модели «Зрение-Язык-Действие» (VLA) знаменуют собой принципиально новый подход в робототехнике, позволяя машинам не просто воспринимать визуальную информацию, но и понимать инструкции, сформулированные на естественном языке, и преобразовывать их в конкретные физические действия. В отличие от традиционных систем, требующих сложного программирования для каждой задачи, VLA-модели способны адаптироваться к новым командам и выполнять их в реальном времени, открывая перспективы для создания действительно автономных и гибких роботов. Такой подход позволяет машинам оперировать в сложных, динамичных средах, реагируя на устные указания и визуальные подсказки, что значительно расширяет область их применения — от помощи по дому до работы в промышленных условиях и выполнения задач в чрезвычайных ситуациях.
Ключевым моментом для реализации потенциала систем, способных воспринимать мир и действовать в нем, является эффективное соединение зрительного восприятия и управления робототехникой, что требует разработки принципиально новых архитектур моделей. Традиционные подходы часто оказываются неспособными адекватно обрабатывать сложные визуальные сцены и преобразовывать их в точные команды для манипуляторов. Современные исследования сосредоточены на создании моделей, способных не только распознавать объекты на изображениях, но и понимать их взаимосвязи, предсказывать последствия действий и генерировать оптимальные траектории движения. Это предполагает интеграцию передовых методов компьютерного зрения, обработки естественного языка и обучения с подкреплением, что позволяет роботам адаптироваться к изменяющимся условиям и выполнять сложные задачи с высокой степенью точности и надежности. Разработка подобных архитектур — это сложная, но перспективная задача, открывающая новые возможности для автоматизации и расширения функциональных возможностей роботов.
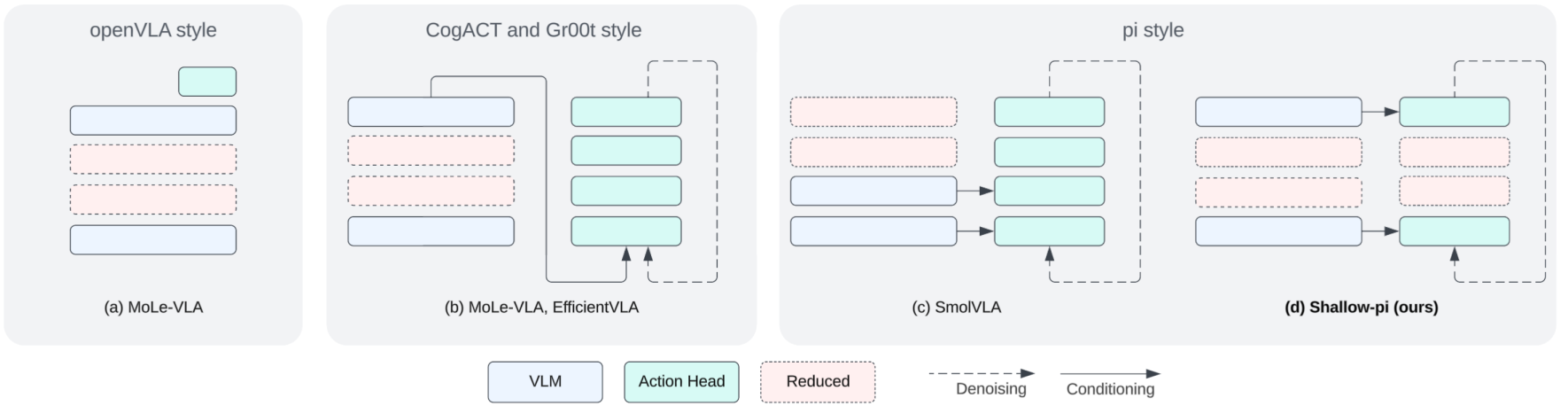
Непрерывность движения: Основы Flow-Based VLA
В отличие от традиционных подходов, использующих дискретные пространства действий, Flow-Based VLAs (Variable Latent Action spaces) генерируют непрерывные команды управления роботом посредством обучения условного векторного поля. Этот подход заключается в отображении текущего состояния робота и целевой точки в вектор, определяющий направление и величину движения. Обучение осуществляется с использованием методов, таких как Flow Matching, позволяющих моделировать сложные зависимости между состоянием, целью и действием. В результате, робот способен генерировать плавные и точные траектории, избегая резких переходов и обеспечивая более эффективное управление в динамических средах. Векторное поле, обученное в процессе, представляет собой функцию, принимающую на вход состояние и цель, и возвращающую вектор действия, определяющий непрерывное изменение состояния робота.
Повышенная плавность и точность движений робота, обеспечиваемая подходом Flow-Based VLAs, критически важна для задач, требующих тонкого моторического контроля и адаптации к изменяющимся условиям. В задачах, где необходимы точные траектории, таких как сборка, хирургия или манипулирование хрупкими объектами, дискретные действия могут приводить к рывкам и ошибкам. Непрерывное пространство действий, генерируемое Flow-Based VLAs, позволяет роботу выполнять более естественные и контролируемые движения, минимизируя ошибки и повышая надежность работы в динамичных средах, где требуется быстрое реагирование на внешние воздействия и корректировка траектории в реальном времени.
Использование методов сопоставления потоков (Flow Matching) обеспечивает устойчивое обучение и повышение производительности в сложных сценариях. Данный подход позволяет моделировать динамику непрерывных действий, эффективно решая задачу обучения с подкреплением в условиях высокой размерности пространства состояний и действий. Методы сопоставления потоков отличаются повышенной стабильностью процесса обучения по сравнению с традиционными методами обучения с подкреплением, поскольку они оптимизируют непрерывное отображение состояний в действия, снижая вероятность расхождения и обеспечивая более плавные и предсказуемые траектории движения робота. Это особенно важно в задачах, требующих точного управления и адаптации к непредсказуемым изменениям в окружающей среде.
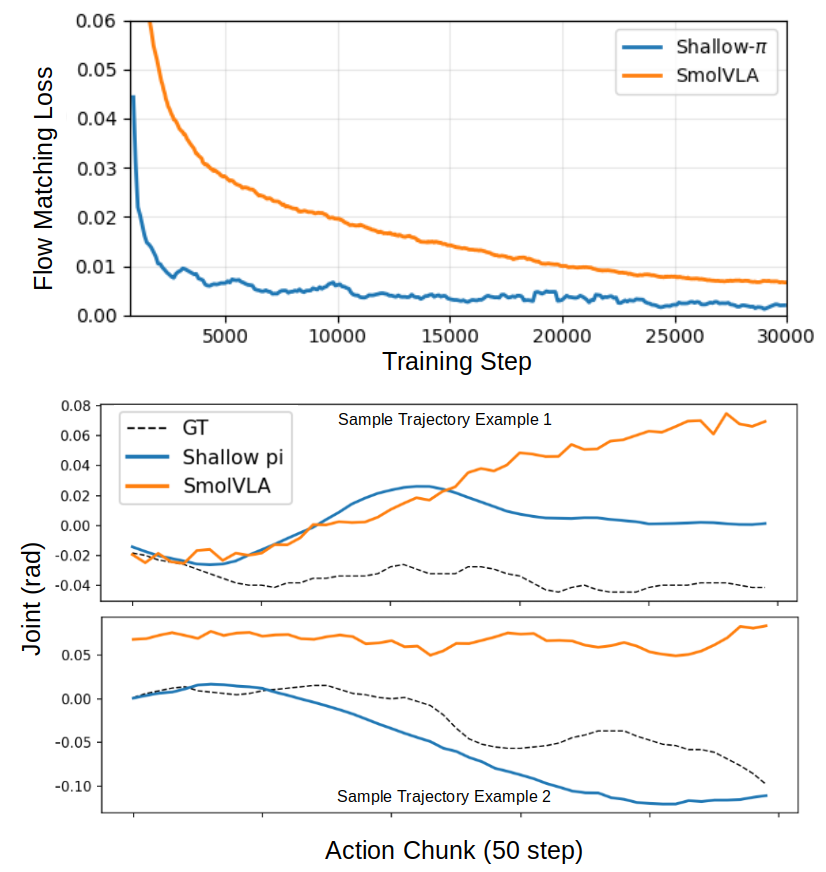
Shallow-π: Дистилляция знаний для эффективной робототехники
Shallow-π представляет собой фреймворк дистилляции знаний, разработанный специально для сжатия как VLM-бэкенда (Visual Language Model), так и блока управления действиями (action head) в потоковых визуально-языковых агентах (flow-based VLAs). В отличие от традиционных методов дистилляции, которые часто фокусируются только на одном компоненте, Shallow-π оптимизирует оба ключевых модуля агента, что позволяет значительно уменьшить размер модели и вычислительные затраты без существенной потери в производительности. Это достигается путем переноса знаний от более крупной «учительской» модели к меньшей «ученической», что делает систему более эффективной для применения в реальном времени и на устройствах с ограниченными ресурсами.
Механизм Shallow-π позволяет существенно снизить размер и вычислительную сложность моделей управления роботами, основанных на визуальных языковых моделях (VLM), за счет дистилляции знаний из более крупной “учительской” модели. В ходе процесса дистилляции достигается сокращение количества слоев модели до 70% без значительного ухудшения производительности. Это достигается путем переноса знаний от сложной, но точной “учительской” модели к более компактной “студенческой” модели, что позволяет сохранить эффективность при значительном снижении требований к вычислительным ресурсам и времени отклика.
Для обеспечения эффективной передачи знаний в процессе дистилляции, фреймворк Shallow-π использует ряд специализированных техник. В частности, применяется передача промежуточного внимания (Intermediate Attention Transfer), которая позволяет студенческой модели учиться фокусироваться на наиболее значимых областях входных данных, как это делает учительская модель. Кроме того, процесс обучения опирается на два типа надзора: надзор на основе реальных меток (Ground-Truth Supervision), обеспечивающий точность предсказаний, и имитацию траектории учителя (Teacher Trajectory Imitation), направленную на воспроизведение поведения более сложной модели. Комбинация этих подходов позволяет существенно уменьшить размер и вычислительную сложность модели, сохраняя при этом высокую производительность.

Реальное применение и оценка эффективности
Технология Shallow-π позволяет развертывать сжатые визуально-лингвистические представления (VLA) непосредственно на периферийных вычислительных устройствах, таких как Jetson Orin. Это открывает возможности для управления роботами в режиме реального времени, исключая зависимость от облачных вычислений и сетевого соединения. Благодаря этому роботы способны функционировать автономно в динамичных средах, оперативно адаптируясь к неожиданным ситуациям и быстро реагируя на изменения. Такой подход обеспечивает повышенную надежность и скорость работы, критически важные для приложений, требующих немедленного отклика, например, в промышленной автоматизации или поисково-спасательных операциях.
Возможность функционирования роботов в динамичных условиях, без необходимости постоянного подключения к облачным сервисам, открывает новые перспективы для автономной работы. Роботизированные системы, оснащенные технологией Shallow-π, способны адаптироваться к непредсказуемым изменениям в окружающей среде и оперативно реагировать на возникающие ситуации. Это достигается за счет обработки данных непосредственно на борту устройства, что позволяет избежать задержек, связанных с передачей информации в облако и обратно. Благодаря этому, роботы могут самостоятельно принимать решения и выполнять задачи даже в условиях ограниченной связи или полной ее потери, что критически важно для применения в таких сферах, как поисково-спасательные операции, исследование труднодоступных территорий и промышленная автоматизация.
Практическая реализуемость и эффективность предложенного подхода были подтверждены в ходе экспериментов на робототехнических платформах ALOHA и RB-Y1. На платформе ALOHA, при выполнении задачи «вставить штырь в отверстие», Shallow-π продемонстрировал успешность в 82% случаев, а на RB-Y1, при решении задачи переработки отходов, — в 81%. Более того, на вычислительном устройстве Jetson Orin удалось достичь частоты обработки в почти 10 Гц, что соответствует времени отклика менее 100 миллисекунд и обеспечивает снижение времени обработки на 200 миллисекунд по сравнению с существующими решениями. Данные результаты свидетельствуют о возможности использования Shallow-π для создания быстрых и надежных систем управления роботами, способных функционировать в реальном времени без зависимости от облачных вычислений.
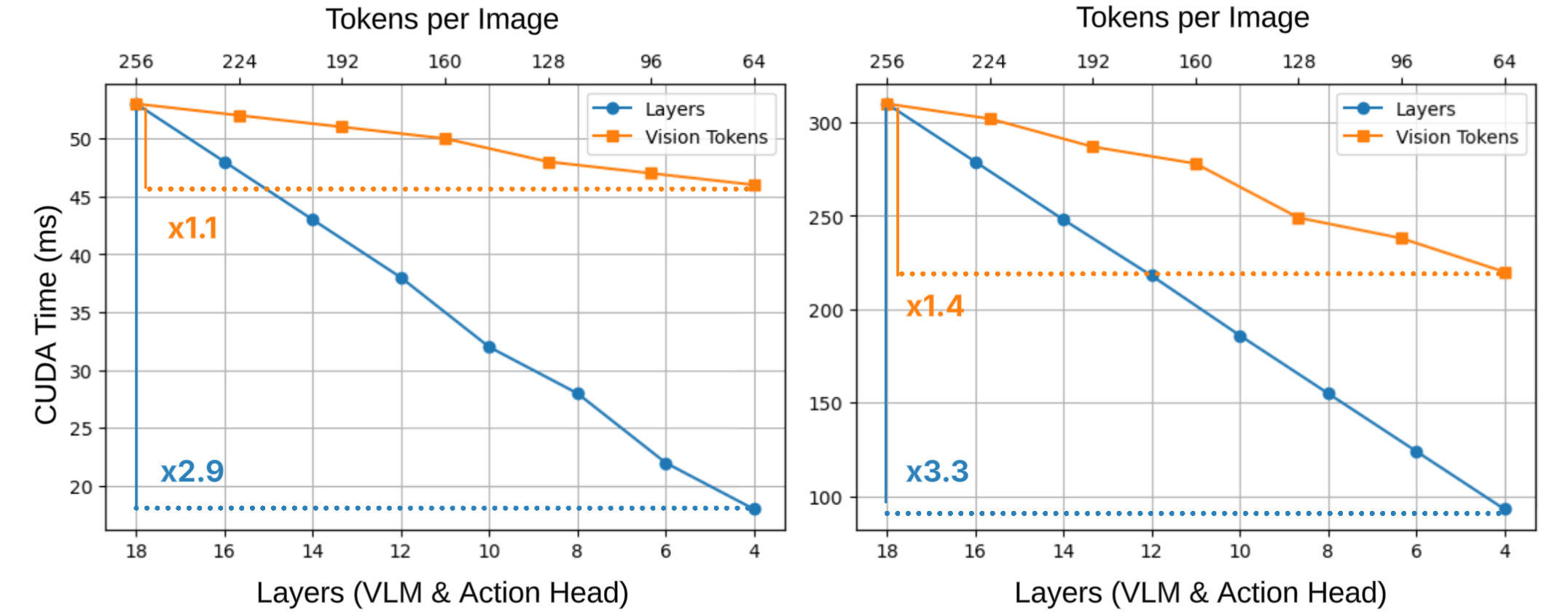
Перспективы развития и оптимизации
Для повышения скорости обработки и снижения вычислительной нагрузки активно исследуются различные методы оптимизации. К ним относятся уменьшение числа шагов диффузии, сокращение количества визуальных токенов, использование механизма раннего выхода из сети и условного пропуска слоев. Эти подходы позволяют эффективно уменьшить объем вычислений, сохраняя при этом приемлемый уровень точности. Уменьшение числа шагов диффузии, например, позволяет ускорить генерацию изображений, а визуальная токенизация — снизить сложность обработки визуальной информации. Ранний выход позволяет прекратить обработку, как только достигнут достаточный уровень уверенности, а условный пропуск слоев — динамически отключать некритичные компоненты сети. Сочетание этих методов открывает перспективные пути для создания более эффективных и ресурсоэкономичных систем искусственного интеллекта.
Надёжность работы робототехнических систем напрямую зависит от способности корректно функционировать в условиях неполной информации и возмущений, что делает проблему «открытого цикла» критически важной. Исследования направлены на разработку устойчивых алгоритмов оценки состояния и прогнозирования, позволяющих роботу предвидеть изменения в окружающей среде и адаптировать свои действия. Успешное решение этой задачи требует не просто точного определения текущего положения, но и предсказания его будущих изменений, учитывая динамику системы и возможные внешние факторы. Разработка robust-методов оценки состояния, способных справляться с шумами и неопределенностями сенсорных данных, является ключевым фактором для обеспечения безотказной работы робота в реальных условиях эксплуатации и повышения его адаптивности к непредсказуемым ситуациям.
Для дальнейшего развития воплощенного искусственного интеллекта необходимо изучение альтернативных стратегий сжатия моделей. Исследователи активно работают над поиском оптимального баланса между размером модели, сохранением точности и обеспечением производительности в реальном времени. Сокращение вычислительных затрат, необходимое для работы моделей на встроенных системах и роботах, требует тщательного анализа различных методов, включая квантизацию, прунинг и дистилляцию знаний. Оптимизация этого компромисса позволит создавать более эффективные и доступные системы, способные решать сложные задачи в динамичных реальных условиях, расширяя сферу применения воплощенного ИИ в робототехнике, автономных транспортных средствах и других областях.

Исследование представляет собой стремление к редукции сложности, что находит отклик в словах Роберта Тарьяна: «Простота — это форма интеллекта, а не ограничения». Авторы статьи демонстрируют, как посредством дистилляции знаний удается существенно снизить вычислительные затраты моделей Vision-Language-Action, сохраняя при этом их эффективность. Этот подход, направленный на оптимизацию как VLM-бэкенда, так и блока действий, особенно важен для развертывания моделей на периферийных устройствах, где ресурсы ограничены. Стремление к минимализму в архитектуре модели позволяет добиться реального времени обработки, что подчеркивает важность ясности и элегантности в проектировании систем.
Что дальше?
Представленная работа, стремясь к эффективности в моделях Vision-Language-Action, не решает фундаментальную проблему: избыточность. Уменьшение глубины Transformer и дистилляция знаний — это, по сути, хирургическое удаление лишнего, а не создание принципиально новой архитектуры. Истина в том, что «лёгкость» — это не только вычислительная эффективность, но и концептуальная ясность. Необходимо искать не просто способы сжать существующее, а пути к более элегантным, минималистичным решениям.
Ограничения текущего подхода очевидны: зависимость от предварительно обученных моделей и сложность адаптации к новым задачам. Будущие исследования должны сосредоточиться на разработке самообучающихся систем, способных к непрерывной оптимизации и адаптации без необходимости в огромных объемах размеченных данных. Поиск инвариантных представлений, не связанных с конкретным доменом, — вот где кроется настоящий прогресс. Ясность — это минимальная форма любви, и это относится к архитектуре моделей.
Реализация на периферийных устройствах — лишь следствие, а не цель. Истинный вызов — создание моделей, способных к рассуждению, планированию и адаптации в реальном времени, не требующих колоссальных вычислительных ресурсов. И тогда, возможно, «умные» устройства перестанут быть просто инструментами и начнут по-настоящему понимать окружающий мир. Сложность — это тщеславие; простота — суть.
Оригинал статьи: https://arxiv.org/pdf/2601.20262.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Квантовая механика: скрытый детерминизм?
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Метаданные под контролем: упрощаем научные данные
2026-01-29 16:19