Автор: Денис Аветисян
Представлен фреймворк BloomQA, позволяющий автоматически создавать качественные и валидные тесты для оценки возможностей языковых моделей в практических областях.
Автоматизированная генерация бенчмарков на основе отраслевых стандартов и принципов таксономии Блума для повышения надежности оценки ИИ.
Оценка способности больших языковых моделей (LLM) к рассуждениям в прикладных областях затруднена из-за отсутствия доступных стандартизированных наборов данных. В статье, посвященной ‘Automated Benchmark Generation from Domain Guidelines Informed by Bloom’s Taxonomy’, предложен фреймворк BloomQA для автоматической генерации психометрически валидных тестов на основе экспертных рекомендаций и таксономии Блума. Разработанный подход позволяет создавать масштабируемые бенчмарки, выявляющие неинтуитивные особенности рассуждений LLM, особенно в областях, требующих процедурных знаний, таких как педагогика, диетология и уход за больными. Сможет ли автоматизированная генерация бенчмарков стать ключом к более надежной и всесторонней оценке возможностей LLM в реальных сценариях?
За гранью баз вопросов: Необходимость осмысленной оценки
Традиционные методы оценки знаний, основанные на использовании готовых баз вопросов, зачастую ограничивают возможность адаптации к меняющимся условиям и детальному анализу сложных ситуаций. Эти банки вопросов, как правило, разрабатываются заранее и не всегда отражают весь спектр реальных профессиональных задач, особенно в динамичных областях, таких как здравоохранение и образование. Ограниченность в охвате нюансов и нестандартных сценариев приводит к тому, что оценка компетенций может быть поверхностной и не способна точно определить уровень экспертности специалиста в условиях реальной практики. В результате, полагаясь исключительно на существующие банки вопросов, оценивающие системы испытывают трудности в выявлении истинного понимания материала и способности применять знания в контексте сложных, нетипичных ситуаций.
Существующие базы вопросов для оценки знаний, особенно в таких сложных областях, как здравоохранение и образование, часто оказываются недостаточно глубокими для точной оценки уровня компетенций. Они, как правило, фокусируются на воспроизведении заученных фактов и стандартных процедур, не затрагивая способности к критическому мышлению, принятию решений в нестандартных ситуациях и адаптации к меняющимся обстоятельствам. Это приводит к тому, что оценка может показывать поверхностное понимание материала, не отражая реальную готовность специалиста к практической деятельности и решению сложных задач, с которыми он столкнется в своей профессиональной сфере. В результате, полагаясь исключительно на подобные банки вопросов, сложно достоверно оценить не только фактические знания, но и навыки применения этих знаний в реальных условиях, что особенно критично в областях, где ошибка может иметь серьезные последствия.
Существует ощутимый пробел в создании оценочных материалов, которые бы соответствовали постоянно меняющимся практическим рекомендациям и реальной сложности профессиональной деятельности. Традиционные методы оценки часто опираются на устаревшие стандарты, не учитывая новые открытия и передовые практики, что приводит к несоответствию между теоретическими знаниями и практическими навыками. Исследования показывают, что актуальные оценочные инструменты не всегда способны выявить нюансы, необходимые для эффективной работы в динамично меняющихся условиях, особенно в таких критически важных областях, как здравоохранение и образование. Необходимость в адаптивных, контекстуализированных оценках, отражающих текущие требования к профессиональной компетентности, становится все более очевидной для обеспечения высокого качества подготовки специалистов и повышения эффективности их работы.
Современные методы оценки знаний зачастую не способны предоставить индивидуальную обратную связь, учитывающую уникальные потребности обучающегося и выявляющую конкретные пробелы в понимании материала. Ограниченность стандартных тестов и экзаменов в анализе ответов и выявлении причин ошибок приводит к тому, что учащиеся получают лишь общую оценку, не позволяющую им понять, над какими именно аспектами необходимо работать. В результате, возможность эффективной самокоррекции и целенаправленного улучшения навыков существенно снижается, что препятствует достижению оптимального уровня компетентности. Разработка систем, способных адаптироваться к индивидуальному темпу обучения и предоставлять детализированные рекомендации, представляется ключевой задачей для повышения эффективности образовательного процесса и обеспечения качественной подготовки специалистов в различных областях.
BloomQA: Автоматизированное создание оценочных материалов
BloomQA использует большие языковые модели (LLM) для автоматизированного извлечения и структурирования передовых практик непосредственно из утвержденных клинических рекомендаций и руководств. Этот процесс, известный как LLM-ассистированное извлечение, позволяет идентифицировать ключевые рекомендации, протоколы и стандарты ухода, представленные в текстовом формате. Извлеченные данные затем преобразуются в структурированный формат, пригодный для создания оценочных материалов, обеспечивая соответствие оценок самым современным и научно обоснованным практикам. Алгоритмы LLM позволяют обрабатывать большие объемы текстовой информации и выделять наиболее важные аспекты, что значительно сокращает время и ресурсы, необходимые для разработки качественных оценочных инструментов.
В основе BloomQA лежит генерация сценариев, основанных на нарушениях установленных практик. Данный подход предполагает создание реалистичных ситуаций, в которых либо соблюдаются рекомендуемые процедуры, либо преднамеренно допускаются отклонения от них. Такой метод позволяет не просто проверить знание правил, но и оценить способность к выявлению ошибок и пониманию последствий их допущения в практической деятельности. Сценарии создаются таким образом, чтобы отражать типичные рабочие ситуации и учитывать возможные факторы, влияющие на принятие решений, что обеспечивает высокую степень валидности и применимости оценочных материалов.
Процесс генерации вопросов с множественным выбором в BloomQA включает создание реалистичных сценариев, а затем их преобразование в вопросы, требующие демонстрации глубокого понимания, а не простого воспроизведения информации. Ключевым элементом является разработка правдоподобных отвлекающих вариантов ответов (дистракторов), которые основаны на распространенных ошибках или неполном понимании темы. Эти дистракторы конструируются таким образом, чтобы проверить, действительно ли испытуемый понимает принципы, лежащие в основе правильного ответа, а не просто угадывает или использует поверхностные знания. Эффективные дистракторы требуют тщательного анализа типичных заблуждений и потенциальных неверных интерпретаций, что обеспечивает более точную оценку уровня компетентности.
В основе BloomQA лежит таксономия Блума, что обеспечивает создание оценочных материалов, охватывающих различные когнитивные навыки. Таксономия Блума определяет шесть уровней познавательной деятельности: знание (recall), понимание (comprehension), применение (application), анализ (analysis), синтез (synthesis) и оценка (evaluation). BloomQA использует эти уровни для структурирования вопросов, гарантируя, что оценки проверяют не только способность к воспроизведению информации, но и умение понимать, применять, анализировать, создавать и оценивать знания в контексте заданных сценариев. Это позволяет получить более полное и достоверное представление об уровне подготовки оцениваемого.
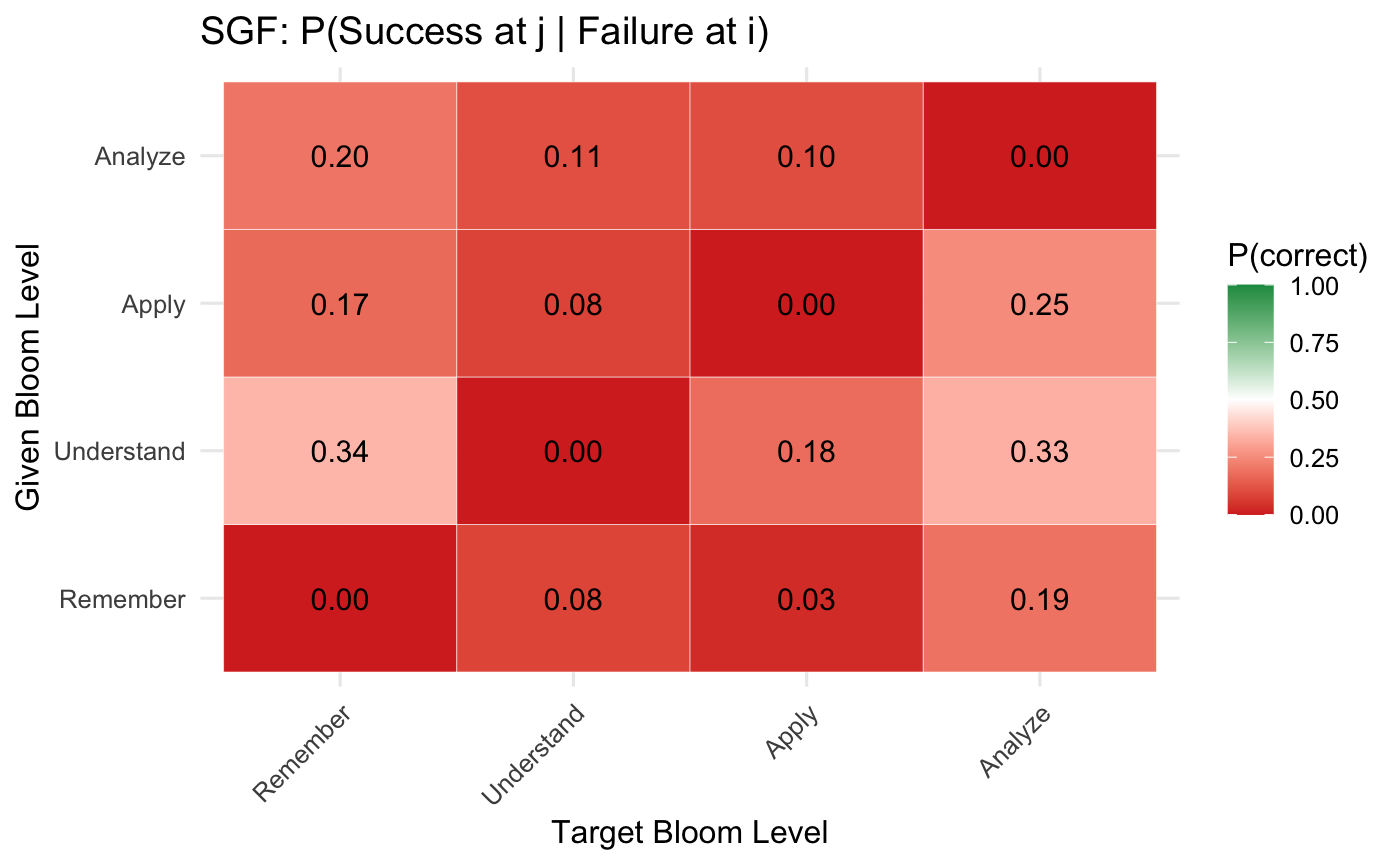
Строгая валидация: Обеспечение качества оценки
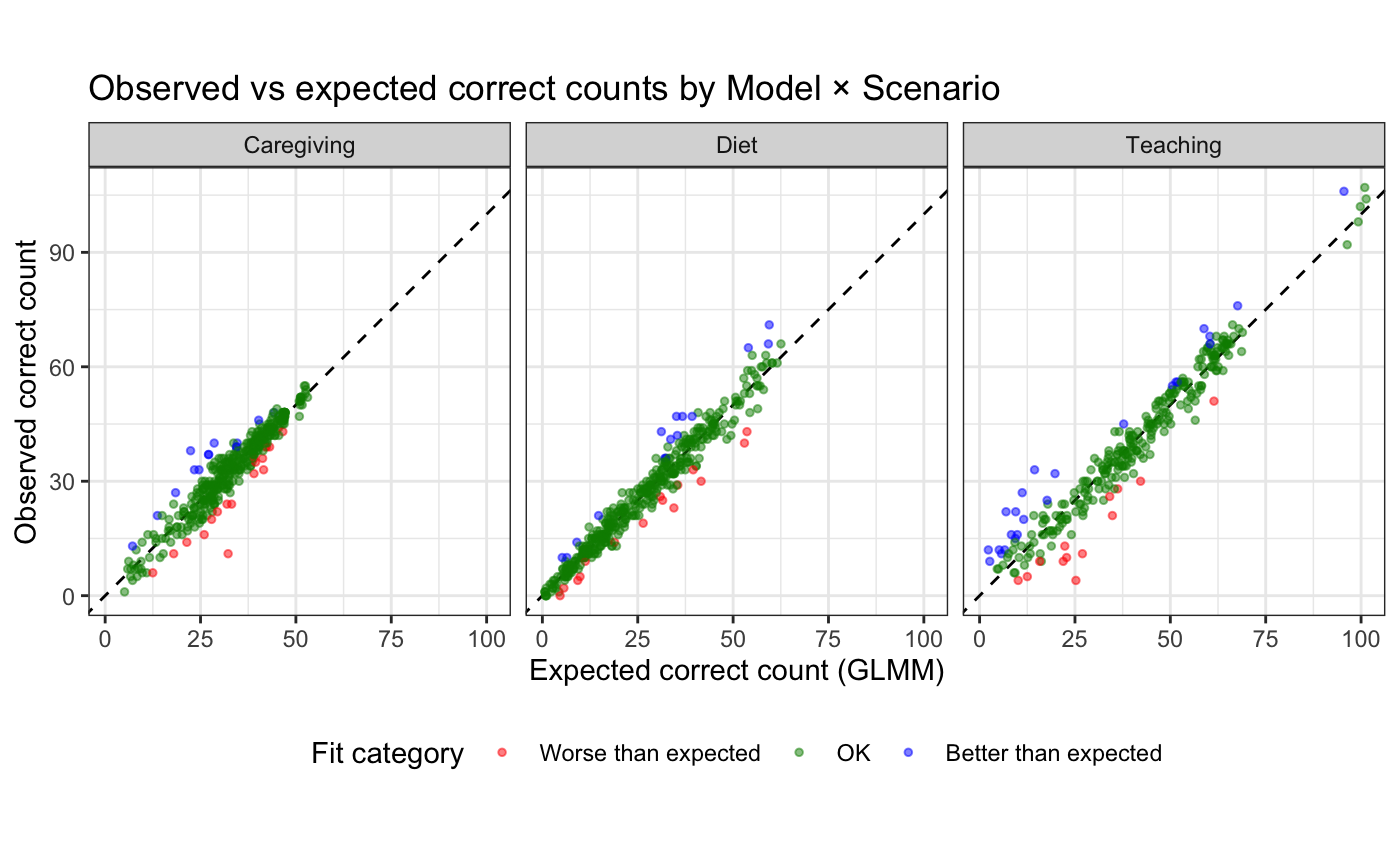
Психометрическая валидация является основополагающим этапом для подтверждения надежности и валидности генерируемых оценочных материалов. Надежность, определяемая как согласованность результатов при повторном тестировании, и валидность, отражающая соответствие оценки измеряемому конструкту, критически важны для обеспечения корректной интерпретации результатов. Процесс валидации включает в себя анализ различных показателей, таких как коэффициент дискриминации, для выявления вопросов, эффективно различающих группы испытуемых с разными уровнями знаний, а также использование статистических моделей, например, обобщенных линейных смешанных моделей (GLMM), для учета вариативности ответов и повышения статистической обоснованности оценки. Отсутствие надлежащей психометрической валидации может привести к неточным результатам и ошибочным выводам, что снижает ценность и достоверность оценочных материалов.
Для оценки качества генерируемых вопросов используется индекс дискриминации (Discrimination Index), позволяющий выявить вопросы, эффективно различающие между сильными и слабыми участниками. Этот показатель рассчитывается как разница между долей высокоэффективных участников, правильно ответивших на вопрос, и долей низкоэффективных участников, правильно ответивших на тот же вопрос. Высокий индекс дискриминации указывает на то, что вопрос успешно идентифицирует тех, кто обладает глубоким пониманием материала, в то время как низкий индекс свидетельствует о неэффективности вопроса в разграничении уровней знаний. В домене обучения (Teaching) сгенерированные вопросы продемонстрировали индекс дискриминации 0.912, что подтверждает их способность эффективно разделять модели по уровню компетентности.
Для обеспечения статистической надежности и учета вариативности ответов при оценке качества генерируемых тестов используются обобщенные линейные смешанные модели (GLMM). GLMM позволяют моделировать и контролировать различные источники изменчивости, включая индивидуальные различия между тестируемыми, а также специфические характеристики вопросов и вариантов ответов. Применение GLMM особенно важно при анализе данных, полученных в условиях, когда ответы могут зависеть от множества факторов, таких как уровень подготовки испытуемого, сложность вопроса или наличие отвлекающих факторов. Данный подход позволяет получить более точные и надежные оценки валидности и надежности генерируемых оценочных материалов, а также выявить потенциальные смещения и недостатки в их структуре.
Для подтверждения полноты охвата ключевых концепций в предметной области к сгенерированным вопросам применяется тематическое моделирование (Topic Modeling). Данный метод позволяет автоматически выявлять основные темы, представленные в вопросах, и оценивать, насколько равномерно и всесторонне они охватывают теоретический материал. Анализ тематической структуры позволяет удостовериться, что вопросы не концентрируются на узком круге тем, а отражают весь спектр знаний, необходимых для оценки компетенций в данной области. Результаты тематического моделирования служат дополнительным подтверждением валидности и репрезентативности сгенерированных оценочных материалов.
BloomQA позволила сгенерировать масштабные наборы данных, включающие 19 824 вопроса по педагогике (Teach-QA), 18 756 вопросов по диетологии (Diet-QA) и 20 000 вопросов по уходу (CareGiving-QA). Данный объем сгенерированных элементов подтверждает способность системы создавать оценочные материалы в больших масштабах, что важно для автоматизированного тестирования и обучения. Размер сгенерированных наборов данных обеспечивает статистическую значимость при проведении валидационных исследований и позволяет создавать надежные и валидные оценочные инструменты в различных предметных областях.
При валидации сгенерированных вопросов в предметной области «Педагогика» был получен показатель дискриминации (Discrimination Index) равный 0.912. Этот показатель характеризует способность вопросов различать между собой сильных и слабых решающих, где значения, близкие к 1, указывают на высокую эффективность вопроса в разделении групп. В данном случае, значение 0.912 свидетельствует о том, что вопросы эффективно выявляют различия в уровне знаний и компетенций между участниками тестирования, обеспечивая надежную дифференциацию результатов.
В процессе валидации сгенерированных оценочных материалов был выявлен разрыв в точности ответов на вопросы, соответствующих различным уровням таксономии Блума, составивший 0.163. Данный показатель свидетельствует о неравномерном распределении сложности вопросов: вопросы, требующие более высоких когнитивных навыков (анализ, оценка, создание), демонстрируют более низкую точность ответов по сравнению с вопросами, проверяющими базовые знания и понимание. Это указывает на то, что сгенерированные вопросы охватывают различные уровни сложности, что является важным аспектом для всесторонней оценки компетенций.
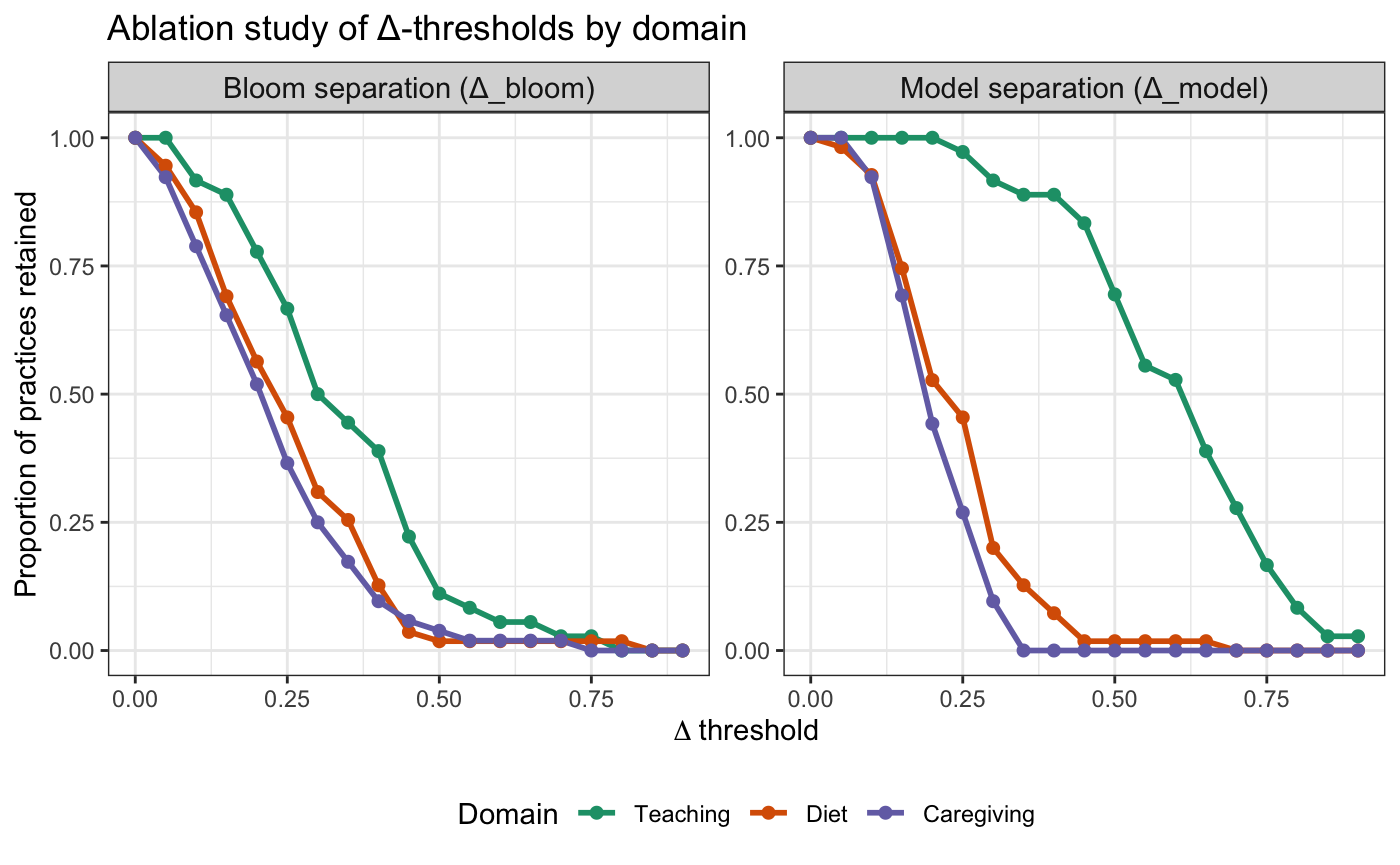
Влияние и перспективы развития
Система BloomQA предоставляет возможность создавать оценочные материалы, точно соответствующие поставленным учебным целям и актуальным рекомендациям в конкретной области знаний, что значительно повышает их эффективность и практическую ценность. В отличие от традиционных методов, требующих значительных временных затрат на разработку и адаптацию тестов, BloomQA автоматизирует этот процесс, позволяя оперативно формировать вопросы, отражающие последние изменения в практике и стандартах. Такая гибкость особенно важна в динамично развивающихся сферах, где своевременное обновление оценочных инструментов необходимо для поддержания высокого уровня компетенции и обеспечения соответствия требованиям времени. В результате, BloomQA способствует более точной и релевантной оценке знаний и навыков, что положительно сказывается на качестве обучения и профессиональной подготовке специалистов.
Автоматизированная генерация вопросов значительно снижает нагрузку на преподавателей и экспертов в предметной области, высвобождая ценное время и ресурсы. Традиционно, создание качественных оценочных материалов требует значительных усилий и времени, от разработки вопросов до проверки и адаптации к изменяющимся учебным планам. BloomQA позволяет автоматизировать этот процесс, предлагая возможность быстрого создания разнообразных вопросов, соответствующих конкретным учебным целям. Это не только экономит время, но и позволяет экспертам сосредоточиться на более сложных задачах, таких как разработка учебных программ и индивидуальная работа со студентами. В результате, образовательные учреждения могут повысить эффективность обучения и обеспечить более качественную оценку знаний, при этом оптимизируя использование имеющихся ресурсов.
Гибкость разработанной системы позволяет осуществлять непрерывную оценку знаний и предоставлять персонализированную обратную связь, что является ключевым фактором для поддержки обучения на протяжении всей жизни и развития профессиональных навыков. В отличие от традиционных методов, которые часто ограничиваются разовыми экзаменами или тестами, данная платформа обеспечивает постоянный мониторинг прогресса и адаптацию к индивидуальным потребностям обучающегося. Это достигается за счет динамической генерации вопросов и анализа ответов, что позволяет выявлять пробелы в знаниях и предлагать целевые рекомендации для улучшения. В результате, пользователи получают возможность не только подтвердить свои компетенции, но и постоянно совершенствовать их, оставаясь в курсе последних тенденций и изменений в своей области.
Предстоящие исследования направлены на интеграцию BloomQA с платформами адаптивного обучения, что позволит создать по-настоящему индивидуализированный опыт освоения знаний. Эта синергия предполагает динамическую настройку учебного процесса, где сложность и содержание вопросов автоматически подстраиваются под текущий уровень подготовки и прогресс обучающегося. В результате, BloomQA будет генерировать не просто вопросы, а последовательность заданий, оптимально соответствующих потребностям каждого пользователя, обеспечивая эффективное усвоение материала и максимальное развитие навыков. Такой подход позволит перейти от универсальных образовательных программ к персонализированным траекториям обучения, способствуя повышению мотивации и достижению лучших результатов.
Представленная работа, стремясь автоматизировать генерацию бенчмарков, неизбежно сталкивается с вечной проблемой: качеством исходных данных. Авторы, опираясь на таксономию Блума, пытаются структурировать процесс, но, как известно, даже самая продуманная классификация не гарантирует отсутствие ошибок в базовых утверждениях. Барбара Лисков однажды заметила: «Программы должны быть спроектированы таким образом, чтобы изменения в одной части не приводили к неожиданным последствиям в других». И в данном случае, стремление к автоматизации без тщательной валидации исходных «доменных руководств» рискует создать бенчмарки, которые будут измерять не способность модели к рассуждениям, а лишь её умение воспроизводить предвзятые или неточные данные. В конечном итоге, даже самые элегантные алгоритмы генерации вопросов не спасут от банальной «технологической задолженности», если не уделить должного внимания качеству исходного материала.
Куда Ведет Автоматизация?
Представленная работа, автоматизируя генерацию бенчмарков на основе таксономии Блума, лишь отодвигает неизбежное. Разумеется, система, создающая тесты, может генерировать больше вопросов, чем человек. Но качество этих вопросов — это всегда компромисс между статистической валидностью и способностью действительно оценить сложность рассуждений. В конечном итоге, каждый «объективный» тест — это просто набор косвенных показателей, которые прод всегда найдет способ обойти, подстроив ввод или выбрав «правильный» сценарий.
Более того, автоматизация генерации бенчмарков подчеркивает фундаментальную проблему: мы строим все более сложные системы оценки, чтобы измерить то, что по сути не поддается количественному определению — способность к «практическому мышлению». Вместо того, чтобы тратить усилия на создание идеальных тестов, возможно, стоит признать, что любая оценка — это всегда приближение, и сосредоточиться на создании систем, способных адаптироваться к неточностям и неопределенности. Нам не нужно больше микросервисов для оценки — нам нужно меньше иллюзий.
Вероятно, будущее бенчмаркинга LLM лежит не в создании более сложных тестов, а в разработке методов, позволяющих оценивать эти модели в реальных условиях, в контексте конкретных задач и пользовательских сценариев. Каждая «революционная» метрика сегодня станет техдолгом завтра, когда прод найдет способ сломать её элегантную теорию. Поэтому, возможно, стоит сосредоточиться на создании систем, способных самообучаться и адаптироваться к меняющимся требованиям.
Оригинал статьи: https://arxiv.org/pdf/2601.20253.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Квантовая механика: скрытый детерминизм?
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Отчетность об устойчивом развитии: Автоматизация анализа с помощью искусственного интеллекта
2026-01-29 16:25