Автор: Денис Аветисян
Новое исследование показывает, что опыт разработчиков по-прежнему определяет способы взаимодействия с инструментами автоматизации кода, даже с появлением «умных» помощников.
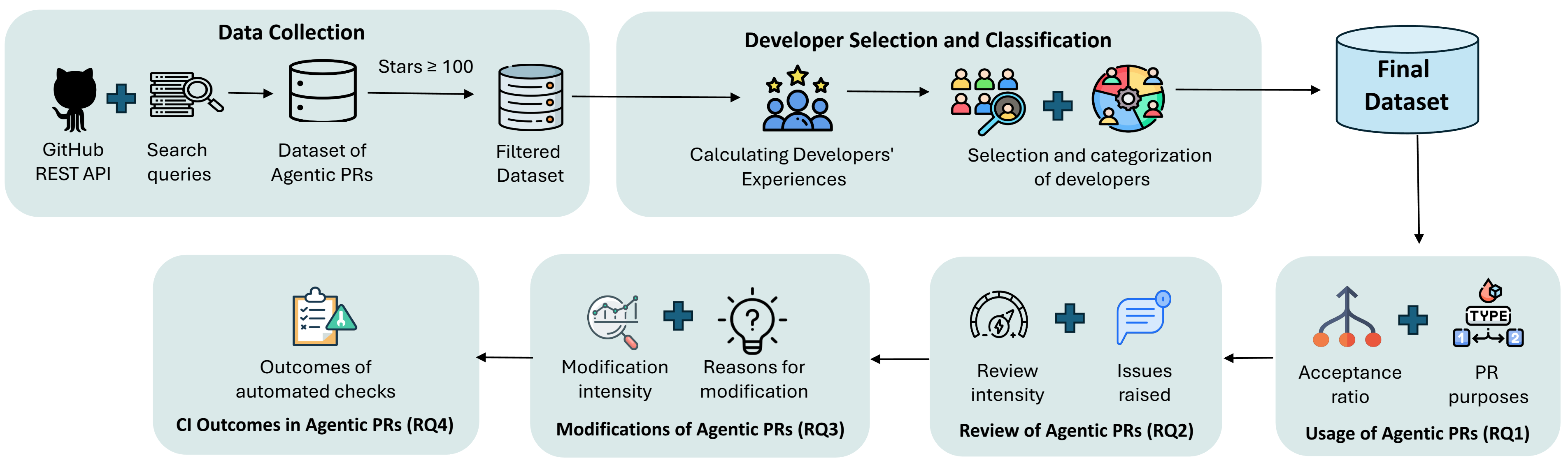
Эмпирическое исследование показывает различия в использовании инструментов автоматизации кода основными и периферийными разработчиками в контексте pull requests и CI/CD pipelines.
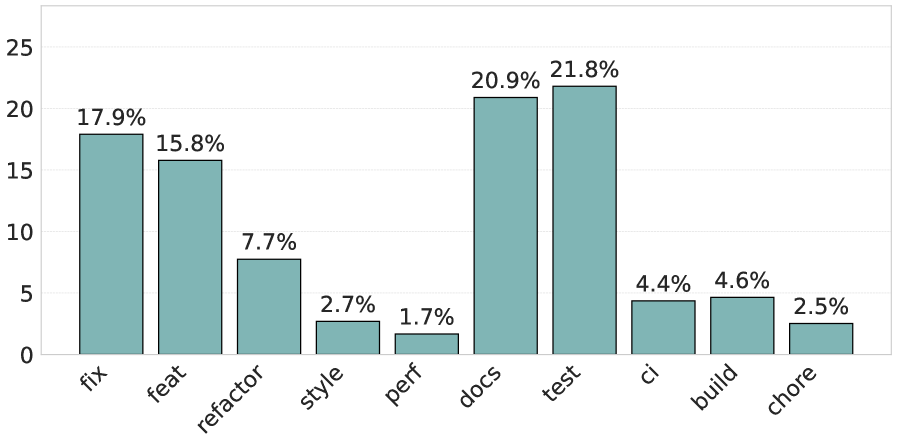
Несмотря на стремительное развитие автономных инструментов разработки, вопрос о том, как опыт программиста влияет на взаимодействие с ними, остается открытым. В настоящем исследовании, озаглавленном ‘Are We All Using Agents the Same Way? An Empirical Study of Core and Peripheral Developers Use of Coding Agents’, проанализировано 9427 pull request’ов, созданных с помощью AI-агентов, чтобы выявить различия в использовании этих инструментов опытными и менее опытными разработчиками. Полученные данные свидетельствуют о том, что ключевые разработчики склонны использовать агентов для задач, связанных с документацией и тестированием, в то время как разработчики с меньшим опытом более равномерно распределяют задачи между отладкой, добавлением функциональности, документацией и тестированием. Какие стратегии взаимодействия с AI-агентами позволят максимально эффективно использовать их потенциал для разработчиков с различным уровнем подготовки?
Бремя Сложности: Вызовы Современных Кодовых Баз
Современные программные системы становятся всё более масштабными и сложными, что предъявляет повышенные требования к ресурсам, необходимым для их поддержки и развития. Поддержание работоспособности и внесение изменений в такие кодовые базы требует значительных затрат времени и усилий разработчиков. Каждая новая функция или исправление ошибки требует тщательного анализа влияния на существующую структуру, что увеличивает вероятность появления ошибок и усложняет процесс тестирования. В результате, команды разработчиков тратят всё больше времени на исправление ошибок и поддержку существующего кода, вместо создания новых функций и инноваций, что негативно сказывается на скорости разработки и конкурентоспособности продукта.
Современные подходы к модификации кода, такие как ручная проверка и тестирование, все чаще не успевают за стремительными темпами изменений в программных проектах. Это приводит к накоплению технического долга — ситуации, когда быстрые, но неоптимальные решения внедряются для удовлетворения текущих потребностей, жертвуя долгосрочной поддерживаемостью и качеством кода. В результате, последующие изменения становятся все более трудоемкими и подверженными ошибкам, замедляя разработку и увеличивая риски возникновения критических уязвимостей. Накопленный технический долг требует значительных ресурсов для исправления, что отвлекает разработчиков от внедрения новых функций и поддержания конкурентоспособности продукта.
Затруднения в поставке программного обеспечения и замедление инноваций становятся ощутимой проблемой для современных разработчиков. Накопление технического долга, вызванное сложностью поддержки и развития крупных кодовых баз, создает узкое место в процессе разработки. Традиционные методы проверки и тестирования попросту не успевают за темпами изменений, что приводит к увеличению времени выпуска новых версий и снижению конкурентоспособности. В связи с этим, возрастает потребность во внедрении автоматизированных решений, способных ускорить процесс поставки, снизить риски и высвободить ресурсы для более творческих задач, таких как разработка новых функций и улучшение пользовательского опыта.
Автономные Агенты Кодирования: Новый Взгляд на Разработку
Агенты кодирования представляют собой новую парадигму в разработке программного обеспечения, используя возможности искусственного интеллекта для автономного решения проблем и внесения изменений в кодовую базу. В отличие от традиционных подходов, требующих непосредственного участия разработчика на каждом этапе, агенты способны самостоятельно анализировать задачи, генерировать необходимые исправления или новые функции, и предлагать их в виде Pull Request для интеграции. Этот процесс автоматизации позволяет существенно повысить производительность разработки, снизить количество ошибок, вызванных человеческим фактором, и освободить ресурсы разработчиков для более сложных и творческих задач.
Автономные агенты для кодирования используют такие модели, как OpenAI Codex, Claude Code и Cursor, для генерации и модификации кода с минимальным участием человека. Codex, основанный на архитектуре GPT, специализируется на переводе естественного языка в код и наоборот. Claude Code, разработанный Anthropic, обеспечивает надежную генерацию кода и анализ уязвимостей. Cursor представляет собой интегрированную среду разработки (IDE), использующую большие языковые модели для помощи в программировании. Эти модели позволяют агентам выполнять задачи, включающие автоматическое исправление ошибок, рефакторинг кода и даже реализацию новых функций, существенно сокращая время разработки и повышая производительность.
Согласно данным исследований, 74.1% запросов на включение изменений (Pull Requests), сгенерированных автономными агентами кодирования, были приняты без каких-либо модификаций. Это демонстрирует высокую эффективность данных агентов в решении задач по внесению изменений в кодовую базу. Интеграция с платформами, такими как GitHub, обеспечивает оптимизированный рабочий процесс, начиная от автоматического выявления проблем и заканчивая полным включением сгенерированного кода в основной репозиторий.
Автоматизация Рабочих Процессов и Качество Кода
Агенты кодирования бесшовно интегрируются с конвейерами CI (непрерывной интеграции), автоматизируя процессы сборки, тестирования и развертывания. Эта интеграция позволяет автоматически запускать этапы конвейера после внесения изменений в код, обеспечивая быструю обратную связь и сокращая время, необходимое для проверки и выпуска новых версий программного обеспечения. Автоматизация включает в себя компиляцию кода, запуск автоматизированных тестов (юнит-тесты, интеграционные тесты и т.д.), анализ кода на предмет ошибок и уязвимостей, а также развертывание приложения в тестовой или производственной среде. В результате, процесс разработки становится более эффективным, снижается вероятность ошибок и ускоряется выпуск новых функций и исправлений.
Автоматическая отправка Pull Requests агентами способствует оптимизации процессов код-ревью и совместной разработки. Вместо ручного создания и отправки запросов на слияние, агенты самостоятельно предлагают изменения в коде, что позволяет разработчикам оперативно их просматривать и обсуждать. Такой подход сокращает время, необходимое для интеграции новых функций и исправления ошибок, а также повышает прозрачность процесса разработки и вовлеченность команды. Автоматизация также снижает вероятность пропустить важные изменения или допустить ошибки при ручном слиянии кода.
Анализ объединенных запросов на слияние (Pull Requests), созданных агентами автоматизации, показал разницу в уровне вовлеченности между основными и периферийными разработчиками. Основные разработчики внесли изменения в 28.3% принятых агентских PR, в то время как периферийные разработчики — только в 23.5%. При этом, 19.1% периферийных разработчиков объединили агентские PR без проведения проверок, в сравнении с 11.2% среди основных разработчиков. Данные свидетельствуют о том, что автоматизация ускоряет циклы разработки и, несмотря на разницу в подходах к проверке, способствует повышению качества кода и снижению риска ошибок.
![Среднее количество добавленных и удаленных строк кода в pull request, сделанных разными разработчиками, показывает тенденции к изменениям в кодовой базе ([\bullet] обозначает среднее значение).](https://arxiv.org/html/2601.20106v1/x7.png)
Встраивание Эволюционируемости в Кодовые Базы
Способность кодовой базы адаптироваться к изменяющимся требованиям, известная как ‘Эволюционируемость’, напрямую зависит от последовательного применения автоматизированных инструментов для исправления ошибок, рефакторинга и тестирования. Регулярное автоматическое устранение дефектов не только повышает надежность программного обеспечения, но и упрощает внесение дальнейших изменений. Рефакторинг, выполняемый автоматически, поддерживает чистоту и понятность кода, снижая сложность и облегчая его модификацию. Наконец, автоматизированное тестирование гарантирует, что внесенные изменения не приведут к непредвиденным последствиям и не нарушат существующую функциональность. Таким образом, постоянное применение этих практик создает самоподдерживающуюся систему, в которой кодовая база становится более гибкой, устойчивой и приспособленной к будущим инновациям.
Надежная документация, поддерживаемая автоматизированными процессами, играет ключевую роль в повышении поддерживаемости программного обеспечения и значительно снижает затраты на адаптацию новых разработчиков. Автоматизация генерации и обновления документации, включая API-документацию и руководства пользователя, гарантирует её актуальность и точность, избавляя от необходимости ручного сопровождения. Это не только уменьшает вероятность ошибок и недопониманий, но и позволяет новым членам команды быстрее освоиться с кодовой базой и начать эффективно работать, тем самым ускоряя процесс разработки и снижая риски, связанные с нехваткой квалифицированных специалистов.
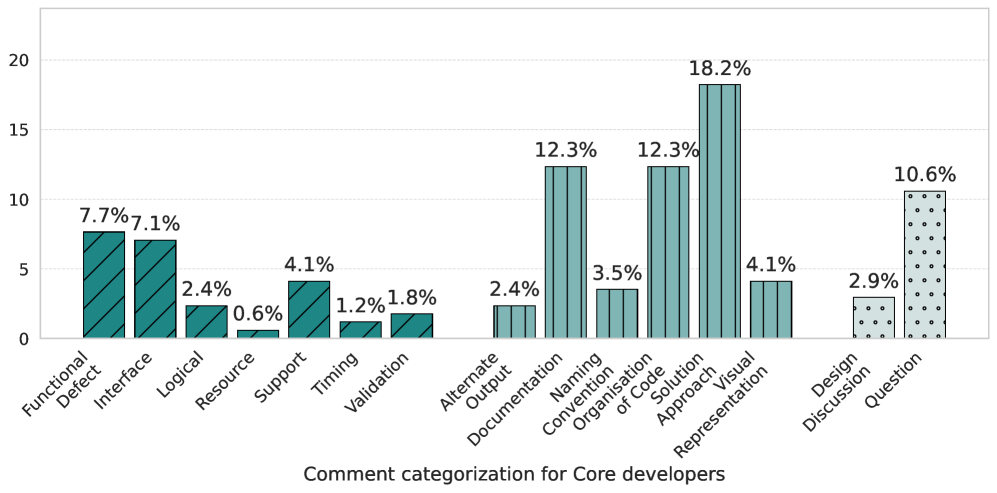
Проведенный Mann-Whitney-Wilcoxon тест выявил разницу в количестве комментариев при проверке кода между группами разработчиков, выраженную значением Cliff’s Delta, равным 0.28. Несмотря на то, что эта разница невелика, она статистически значима и указывает на повышение эффективности процесса разработки. Высокая степень согласованности между кодировщиками, подтвержденная коэффициентом Cohen’s Kappa в диапазоне от 80.3% до 82.5%, свидетельствует о надежности оценки изменений в коде. Подобное повышение “эволюционируемости” кодовой базы способствует ускорению инноваций, снижению технического долга и, как следствие, обеспечивает конкурентное преимущество в динамично меняющейся технологической среде.
Исследование показывает, что даже с появлением автономных инструментов, опыт разработчика остаётся ключевым фактором в формировании паттернов сотрудничества. Ядро разработчиков сосредоточено на качестве и поддерживаемости кода, в то время как разработчики, работающие на периферии, используют возможности агентов в более широком спектре задач. В этом нет ничего удивительного, ведь, как говорил Пауль Эрдеш: «Математика — это искусство делать очевидное». Подобно тому, как математик стремится к ясности в доказательствах, опытные разработчики стремятся к чистоте и понятности кода, даже когда есть инструменты, способные автоматизировать рутинные задачи. Сложность — это лишь иллюзия, а истинное мастерство заключается в умении упрощать.
Что дальше?
Исследование, как и любое другое, лишь аккуратно отодвигает завесу, а не рассеивает туман. Очевидно, что опыт разработчика остаётся определяющим фактором, даже когда в процесс включаются автономные агенты. Однако, где та граница, за которой агент становится не инструментом, а продолжением мышления разработчика? Этот вопрос требует дальнейшего изучения, особенно в контексте долгосрочных проектов и командной динамики.
Настоящая сложность кроется не в самих агентах, а в неявных предположениях о «качестве» и «поддерживаемости» кода. Эти понятия субъективны и контекстуальны. Следующим шагом представляется разработка метрик, способных количественно оценить эти качества, а не просто полагаться на интуицию. Иначе, агенты будут оптимизировать то, что легко измерить, игнорируя более тонкие аспекты.
Ясность — это минимальная форма любви. Поэтому, вместо того, чтобы стремиться к созданию универсальных агентов, необходимо сосредоточиться на разработке специализированных инструментов, адаптированных к конкретным задачам и рабочим процессам. И только тогда станет понятно, где заканчивается помощь агента и начинается истинное мастерство разработчика.
Оригинал статьи: https://arxiv.org/pdf/2601.20106.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Самообучающиеся признаки: новый подход к машинному обучению
- Облачные вычисления для науки: гибкость и масштабируемость
- Сопоставление объектов в разных ракурсах: новый подход с использованием ИИ
- Квантовая механика: скрытый детерминизм?
2026-01-30 04:08