Автор: Денис Аветисян
Представлена Foundation-Sec-8B-Reasoning — языковая модель с 8 миллиардами параметров, разработанная специально для решения задач в области кибербезопасности и демонстрирующая улучшенные возможности рассуждения.
Модель использует двухэтапную схему обучения с применением контролируемого обучения и обучения с подкреплением для повышения эффективности анализа уязвимостей и обработки информации об угрозах.
Несмотря на значительный прогресс в области больших языковых моделей, специализированные задачи, такие как анализ киберугроз, требуют доработки и углубленного понимания предметной области. В настоящем техническом отчете, ‘Llama-3.1-FoundationAI-SecurityLLM-Reasoning-8B Technical Report’, представлена модель Foundation-Sec-8B-Reasoning, разработанная на базе Llama-3.1-8B и обученная с использованием двухэтапного процесса, включающего контролируемое обучение и обучение с подкреплением по верифицируемым наградам. Полученные результаты демонстрируют конкурентоспособную производительность в 10 задачах кибербезопасности и сохранение общих возможностей, превосходя более крупные модели. Сможет ли подобный подход к созданию специализированных моделей с развитыми навыками рассуждения значительно повысить эффективность защиты от современных киберугроз?
Ловушка логики: Почему LLM нуждаются в осмысленном рассуждении
Несмотря на впечатляющую мощь, современные большие языковые модели (LLM) зачастую демонстрируют недостаточную надежность в процессе рассуждений, что создает серьезные уязвимости в приложениях, связанных с безопасностью. Модели способны генерировать убедительные ответы, но не всегда способны подтвердить логическую последовательность своих умозаключений. Это означает, что даже при кажущейся корректности ответа, внутренняя логика может быть ошибочной или подвержена манипуляциям, что делает их ненадежными для критически важных задач, таких как анализ угроз, проверка кода на наличие уязвимостей или принятие решений в сфере кибербезопасности. Отсутствие прозрачности в процессе рассуждений препятствует выявлению ошибок и повышает риск непредсказуемого поведения модели в сложных ситуациях.
Традиционное увеличение масштаба языковых моделей, заключающееся в наращивании объёма данных и параметров, не решило фундаментальную проблему: способность демонстрировать логическую цепочку рассуждений, а не просто выдавать вероятные ответы. В то время как более крупные модели могут показывать впечатляющую статистическую корреляцию, они часто не способны объяснить, почему они пришли к определенному заключению. Это критически важно для приложений, требующих надёжности и проверяемости, например, в сфере кибербезопасности или критически важных системах, где недостаточно просто получить правильный ответ — необходимо понимать и подтверждать обоснованность этого ответа. Современные исследования направлены на разработку методов, позволяющих моделям не только предсказывать, но и предоставлять чёткое и понятное объяснение своих действий, раскрывая внутреннюю логику и обеспечивая возможность верификации принимаемых решений.

Foundation-Sec-8B-Reasoning: Возвращая логику в машины
Модель Foundation-Sec-8B-Reasoning является развитием базовой модели Foundation-Sec-8B и расширяет ее функциональные возможности за счет внедрения подхода “естественного рассуждения”. Этот подход заключается в использовании архитектуры, изначально спроектированной для генерации явных цепочек рассуждений, а не просто выдачи конечного ответа. В результате модель способна демонстрировать процесс принятия решений, что повышает ее надежность и позволяет более эффективно отлаживать и верифицировать результаты.
Подход, используемый в Foundation-Sec-8B-Reasoning, делает акцент на генерации явных цепочек рассуждений перед формулированием окончательного ответа. Это достигается путем последовательного вывода промежуточных шагов логики, что позволяет проследить ход мысли модели и оценить обоснованность принятого решения. Подобная практика существенно повышает прозрачность работы модели и обеспечивает возможность верификации полученных результатов, поскольку каждый шаг рассуждений доступен для анализа и подтверждения.
Обучение с учителем (Supervised Fine-Tuning) используется для формирования у модели способности к последовательному изложению хода рассуждений. В процессе обучения модели предоставляются наборы данных, включающие не только входные данные и правильный ответ, но и детальное описание шагов, необходимых для получения этого ответа. Модель обучается генерировать аналогичные «цепочки рассуждений» (reasoning traces) для новых входных данных, фактически артикулируя свой мыслительный процесс перед выдачей окончательного результата. Это позволяет не только повысить точность ответов, но и обеспечить возможность проверки и анализа логики, используемой моделью для принятия решений.

Оттачивая логику: Обучение с подкреплением и стабильность модели
Для тонкой настройки процесса рассуждений применяется обучение с подкреплением, использующее проверяемые награды. Система оценивает полученные выводы на основе их логической обоснованности и возможности верификации фактами. Награды назначаются за ответы, которые не только соответствуют заданным условиям, но и могут быть подтверждены внешними источниками или логическим анализом. Это позволяет модели улучшать качество своих рассуждений, избегая нелогичных или недостоверных заключений, и фокусироваться на генерации обоснованных и проверяемых результатов.
Алгоритм Group Relative Policy Optimization (GRPO) обеспечивает эффективное исследование пространства возможных путей рассуждений путем оптимизации политики агента относительно группы похожих траекторий. В отличие от стандартных алгоритмов обучения с подкреплением, GRPO вычисляет преимущества действий не по отношению к среднему вознаграждению, а по отношению к вознаграждениям, полученным группой агентов, следующих схожим стратегиям. Это позволяет снизить дисперсию оценок и ускорить процесс обучения, особенно в сложных задачах, где существует множество равноценных путей решения. GRPO максимизирует суммарное вознаграждение, получаемое агентом за выбранную последовательность действий, обеспечивая тем самым более стабильное и быстрое схождение к оптимальной стратегии рассуждений.
Для обеспечения стабильности процесса обучения и предотвращения катастрофического забывания, в алгоритм применяется штраф на основе расхождения Кульбака-Лейблера (KL-Divergence). Данный штраф ограничивает отклонение политики модели от её начального состояния. Величина штрафа пропорциональна разнице между текущим и начальным распределениями вероятностей действий, что позволяет сохранить базовые навыки рассуждения, приобретенные на предварительных этапах обучения, и избежать резких изменений в поведении модели, вызванных новыми данными или задачами. Использование KL-Divergence Penalty эффективно смягчает процесс обновления политики, обеспечивая более плавную адаптацию и устойчивость к переобучению.

Надежная логика: Преимущества и реальное влияние
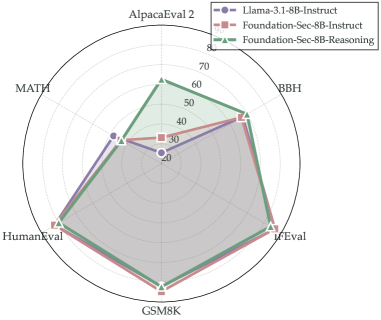
Модель Foundation-Sec-8B-Reasoning продемонстрировала выдающиеся результаты на ключевых отраслевых бенчмарках, предназначенных для оценки способностей в области кибербезопасности. Успешное прохождение тестов CTIBench, CWE и HarmBench подтверждает, что данная модель обладает развитыми навыками логического мышления и анализа, необходимыми для выявления и предотвращения угроз информационной безопасности. Это свидетельствует о ее потенциале в качестве надежного инструмента для автоматизации задач, связанных с обнаружением уязвимостей и разработкой стратегий защиты от кибератак, а также о возможности ее применения в системах анализа вредоносного кода и реагирования на инциденты.
Исследования показали, что модель демонстрирует значительное превосходство в решении сложных задач, требующих логического мышления. В ходе сравнительного анализа с такими моделями, как DeepSeek-R1 и Llama-3.3-70B-Instruct, была зафиксирована более высокая точность в решении задач из набора CTIBench-RCM — 75.3% против 68.4% у Llama-3.3-70B-Instruct и 71.2% у GPT-OSS-120B. Данный результат подтверждает способность модели эффективно анализировать информацию и находить оптимальные решения в сложных сценариях, что выделяет её на фоне других существующих систем искусственного интеллекта.
Исследования, проведенные с использованием AlpacaEval2, демонстрируют способность модели генерировать не только корректные, но и понятные для человека рассуждения. Результаты показали впечатляющий показатель в 62.6% случаев, когда модель превосходит альтернативные решения в плане предпочтений пользователей. Этот результат значительно превышает аналогичный показатель для Llama-3.1-8B-Instruct, составивший всего 25.4%, что указывает на существенный прогресс в создании систем искусственного интеллекта, способных эффективно коммуницировать и объяснять свои выводы, что критически важно для доверия и практического применения.
В ходе тестирования на наборе данных 2WikiMultihopQA, модель продемонстрировала значительное улучшение точности, превысив показатели базовой версии, обученной методом Supervised Fine-Tuning (SFT), на 36.1%. Данный результат свидетельствует о существенном прогрессе в способности модели к многоступенчатому логическому выводу и поиску информации в различных источниках. Улучшение точности на столь сложном наборе данных указывает на то, что модель не просто запоминает факты, но и способна устанавливать связи между ними, эффективно используя знания для ответа на вопросы, требующие анализа и синтеза информации из нескольких источников.
Исследования показали, что при использовании специальных системных подсказок, модель демонстрирует впечатляющую устойчивость к генерации потенциально вредоносного контента, достигая 93% успешных прохождений теста HarmBench. Этот показатель свидетельствует о значительном прогрессе в обеспечении безопасности больших языковых моделей и их способности избегать создания ответов, которые могут быть использованы для злонамеренных целей. Высокий процент успешного прохождения указывает на эффективную работу механизмов фильтрации и контроля, встроенных в модель, и подтверждает её способность генерировать безопасные и этичные ответы даже при сложных и провокационных запросах.

Данное исследование, представляющее Foundation-Sec-8B-Reasoning, закономерно вызывает скепсис. Разработчики уверяют, что новая модель демонстрирует улучшенные возможности рассуждения в сфере кибербезопасности благодаря двухэтапному процессу обучения. Однако, как показывает опыт, любое усложнение архитектуры, даже направленное на повышение производительности, рано или поздно обернется техническим долгом. Кен Томпсон однажды заметил: «Я думаю, что разработка программного обеспечения — это как строительство дома. Если вы строите дом, вы должны быть готовы к тому, что он будет нуждаться в ремонте». В контексте больших языковых моделей это означает, что Foundation-Sec-8B-Reasoning, вероятно, потребует постоянной доработки и адаптации к новым угрозам, а заявленное улучшение возможностей рассуждения может оказаться лишь временным выигрышем в гонке вооружений с киберпреступниками. В конечном итоге, производительность модели будет определяться не теоретическими преимуществами, а реальными сценариями эксплуатации и способностью выдерживать нагрузку в продакшене.
Что дальше?
Представленная работа, как и большинство подобных, демонстрирует улучшение метрик на синтетических датасетах. Это всегда приятно, конечно, но опыт подсказывает, что реальные злоумышленники не читают научные статьи, чтобы адаптировать свои атаки под новые алгоритмы. Скорее, они найдут способ обойти любую «защиту», основанную на статистических закономерностях. Очевидно, что задача анализа уязвимостей — это не только о «рассуждениях», но и о понимании контекста, и о неявных знаниях, которые пока сложно формализовать.
Очевидным направлением является увеличение размера модели, но история показывает, что каждый скачок в параметрах сопровождается пропорциональным ростом сложностей с обучением и эксплуатацией. Скорее всего, мы увидим борьбу между «больше и лучше» и «компактнее и эффективнее». Возможно, имеет смысл пересмотреть саму парадигму: вместо того, чтобы пытаться создать универсальный «мозг», решать узкие, конкретные задачи с помощью специализированных моделей. В конце концов, «DevOps» — это когда инженеры смирились с тем, что автоматизировать всё невозможно.
В конечном счете, каждое «революционное» решение — это просто новый техдолг. И эта модель, вероятно, станет лишь ещё одной обёрткой над старыми багами. Всё новое — это просто старое с худшей документацией. И это, пожалуй, самое предсказуемое будущее.
Оригинал статьи: https://arxiv.org/pdf/2601.21051.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Экзотические разложения: новые грани цилиндрической алгебры
- Командная работа агентов: обучение без обновления модели
2026-01-30 07:27