Автор: Денис Аветисян

Многомодальные большие языковые модели, несмотря на впечатляющие возможности, подвержены проблеме межмодальных галлюцинаций, приводящих к неверной генерации информации. В работе ‘MAD: Modality-Adaptive Decoding for Mitigating Cross-Modal Hallucinations in Multimodal Large Language Models’ предложен метод Modality-Adaptive Decoding (MAD) — обучение без учителя, динамически взвешивающее вклад различных модальностей при декодировании. Данный подход позволяет модели фокусироваться на релевантной информации и подавлять межмодальные помехи, значительно снижая количество галлюцинаций в аудиовизуальных задачах. Не является ли адаптивное взвешивание модальностей ключевым шагом к созданию более надежных и эффективных многомодальных систем искусственного интеллекта?
Иллюзия и Реальность: Понимание Галлюцинаций в Мультимодальных Моделях
Многомодальные большие языковые модели (MLLM) демонстрируют впечатляющие возможности в обработке и генерации информации, объединяя данные из различных источников, таких как текст и изображения. Однако, несмотря на свой потенциал, эти модели подвержены феномену, известному как «галлюцинации» — склонности к генерации неточной или полностью вымышленной информации. Это проявляется в создании утверждений, не подкрепленных входными данными, или в искажении реальных фактов, что ставит под сомнение надежность и достоверность генерируемого контента. Несмотря на достижения в области искусственного интеллекта, проблема галлюцинаций остается серьезным препятствием на пути к созданию действительно надежных и полезных многомодальных систем, требующих дальнейших исследований и разработки эффективных методов коррекции.
Многомодальные большие языковые модели, несмотря на впечатляющие возможности, подвержены галлюцинациям — генерации неточной или вымышленной информации. Эти галлюцинации проявляются в различных формах, в том числе и внутри одной модальности, когда модель искажает факты, представленные в тексте или изображении, например, описывая несуществующие детали. Более сложным является межмодальное проявление, когда модель противоречиво интерпретирует информацию из разных источников — например, описывает изображение, не соответствующее содержанию текста. Такие несоответствия существенно снижают надежность работы моделей, препятствуя их применению в критически важных задачах, где точность и правдивость информации являются первостепенными.
Основная причина возникновения галлюцинаций в мультимодальных больших языковых моделях заключается в сложностях, возникающих при интеграции информации из различных источников и поддержании фактической согласованности. Модели испытывают трудности в установлении надежных связей между данными, поступающими из разных модальностей — например, изображений и текста — что приводит к неверным выводам или выдуманным деталям. Неспособность эффективно сопоставлять и проверять информацию внутри и между модальностями приводит к генерации контента, который может казаться правдоподобным, но не соответствует действительности. Это особенно заметно при обработке сложных или неоднозначных данных, где модель может опираться на неполную или неточную информацию, что приводит к искажению фактов и появлению галлюцинаций.
Понимание механизмов, приводящих к возникновению галлюцинаций в мультимодальных больших языковых моделях, является ключевым фактором для создания действительно надежных и заслуживающих доверия систем. Исследование этих сбоев позволяет выявить слабые места в процессе интеграции информации из различных источников — будь то текст, изображения или звук. Тщательный анализ этих ошибок открывает возможности для разработки новых методов обучения и архитектур моделей, направленных на повышение фактической точности и последовательности генерируемых ответов. Без глубокого понимания этих “галлюцинаций” невозможно гарантировать, что мультимодальные модели будут предоставлять достоверную информацию и принимать обоснованные решения, что критически важно для их применения в таких областях, как медицина, образование и автономные системы.
Контрастное Декодирование: Борьба с Искажениями
Контрастирующая декодировка представляет собой перспективный подход к снижению галлюцинаций в моделях генерации текста и мультимодальных системах. Суть метода заключается в сопоставлении наиболее вероятных выходных данных с результатами, полученными на основе намеренно искаженных или зашумленных входных данных. Посредством сравнения и вычитания нежелательных выходных данных, вызванных возмущениями, достигается более согласованный и правдоподобный вывод. Эффективность подхода обусловлена тем, что он позволяет модели оценивать устойчивость своих предсказаний к небольшим изменениям во входных данных, тем самым уменьшая вероятность генерации нерелевантного или ложного контента.
Методы контрастного декодирования были расширены для применения к моделям компьютерного зрения и аудиовизуальным моделям. Визуальное контрастное декодирование адаптирует принцип сопоставления вероятных и возмущенных выходов для обработки визуальных данных, фокусируясь на снижении галлюцинаций в задачах, связанных с изображениями. Аналогично, аудиовизуальное контрастное декодирование использует этот подход для моделей, обрабатывающих как аудио-, так и визуальную информацию, стремясь к более надежным и точным результатам в мультимодальных сценариях. В обоих случаях, ключевая идея заключается в усилении сигнала от наиболее вероятных выходных данных за счет подавления тех, что генерируются на основе искаженных или зашумленных входных данных.
Стандартные методы контрастного декодирования для аудио-визуальных моделей часто не предусматривают динамическую настройку веса каждой модальности. Это означает, что вклад аудио- и видеоинформации в процесс генерации ответа задается статически и не адаптируется к конкретной задаче или входным данным. В результате, при решении задач, где одна из модальностей является более релевантной или информативной, статическое взвешивание может приводить к снижению качества генерации, поскольку значимость более важной модальности не выделяется должным образом, а менее значимая оказывает непропорциональное влияние на конечный результат.
Неспособность стандартного аудио-визуального контрастного декодирования динамически адаптировать значимость каждой модальности приводит к субоптимальной производительности. В задачах, где аудиоинформация является критически важной (например, распознавание речи), фиксированное взвешивание аудио и видео каналов может приводить к игнорированию релевантных звуковых сигналов. Аналогично, в задачах, где визуальная информация преобладает (например, анализ сцены), недостаточное внимание к аудиоканалу может снизить точность. Эффективность алгоритма напрямую зависит от способности учитывать специфику задачи и приоритизировать наиболее информативную модальность, что требует механизмов динамической адаптации весов для каждого входного сигнала.
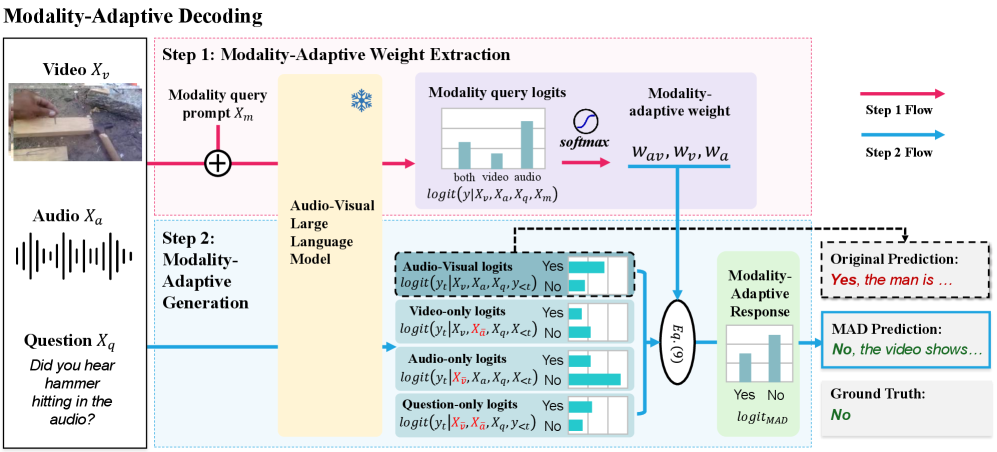
Адаптивное Декодирование Модальностей: Динамический Подход
Метод адаптивного декодирования модальностей (Modality-Adaptive Decoding) является расширением подхода Contrastive Decoding и отличается динамической настройкой вклада каждой модальности в процесс генерации, исходя из специфики решаемой задачи. В отличие от фиксированного веса, применяемого в стандартном Contrastive Decoding, данный метод позволяет модели изменять степень влияния аудио- и визуальных данных, оптимизируя результат для конкретного типа запроса или условия. Это достигается путем анализа требований задачи и соответствующей корректировки весовых коэффициентов для каждой модальности, что позволяет повысить точность и релевантность генерируемого контента.
Метод адаптивного декодирования использует запрос самооценки (Self-Assessment Prompt) для определения релевантности каждой модальности (например, аудио или видео) для конкретной задачи. Этот запрос позволяет модели оценить, насколько важна каждая модальность для достижения желаемого результата. На основе этой оценки назначаются веса, определяющие вклад каждой модальности в процесс декодирования. Таким образом, система динамически регулирует влияние каждой модальности, отдавая приоритет наиболее информативным источникам данных и снижая влияние менее релевантных или вводящих в заблуждение сигналов, что повышает точность и эффективность работы модели.
Применение адаптивного декодирования позволяет модели динамически выделять наиболее информативный источник данных, минимизируя влияние нерелевантных или вводящих в заблуждение данных. Это достигается путем оценки релевантности каждого источника (например, аудио и видео) для конкретной задачи и соответствующей корректировки весов при декодировании. В результате модель сосредотачивается на данных, которые в наибольшей степени способствуют решению задачи, игнорируя или уменьшая вклад менее значимых источников, что повышает точность и надежность результатов.
В рамках данной методики используются как декодирование с контрастом для отдельных модальностей (Single-Modality Contrastive Decoding), так и совместное аудио-визуальное декодирование с контрастом (Joint Audio-Visual Contrastive Decoding). Первый подход позволяет модели анализировать и использовать информацию из каждой модальности независимо, в то время как второй обеспечивает интеграцию аудио- и визуальных данных для формирования более полного представления. Комбинирование этих двух стратегий позволяет системе адаптироваться к различным типам входных данных и задачам, оптимизируя процесс декодирования в зависимости от релевантности каждой модальности.
Эмпирическая Валидация и Прирост Производительности
Метод адаптивного декодирования модальностей был успешно интегрирован в современные мультимодальные большие языковые модели, такие как VideoLLaMA2-AV и Qwen2.5-Omni, что подтверждает его практическую применимость. Данная реализация демонстрирует возможность эффективной работы алгоритма в различных архитектурах и с разными типами данных, включая видео и аудио. Успешное внедрение в передовые модели свидетельствует о зрелости подхода и его потенциале для улучшения качества и надежности мультимодальных систем, способных обрабатывать и понимать информацию, поступающую из нескольких источников.
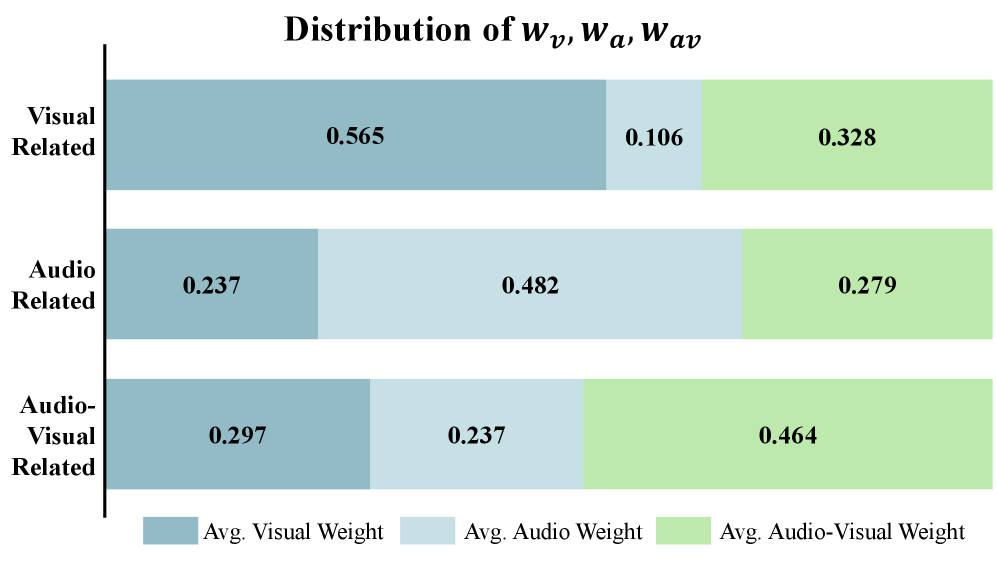
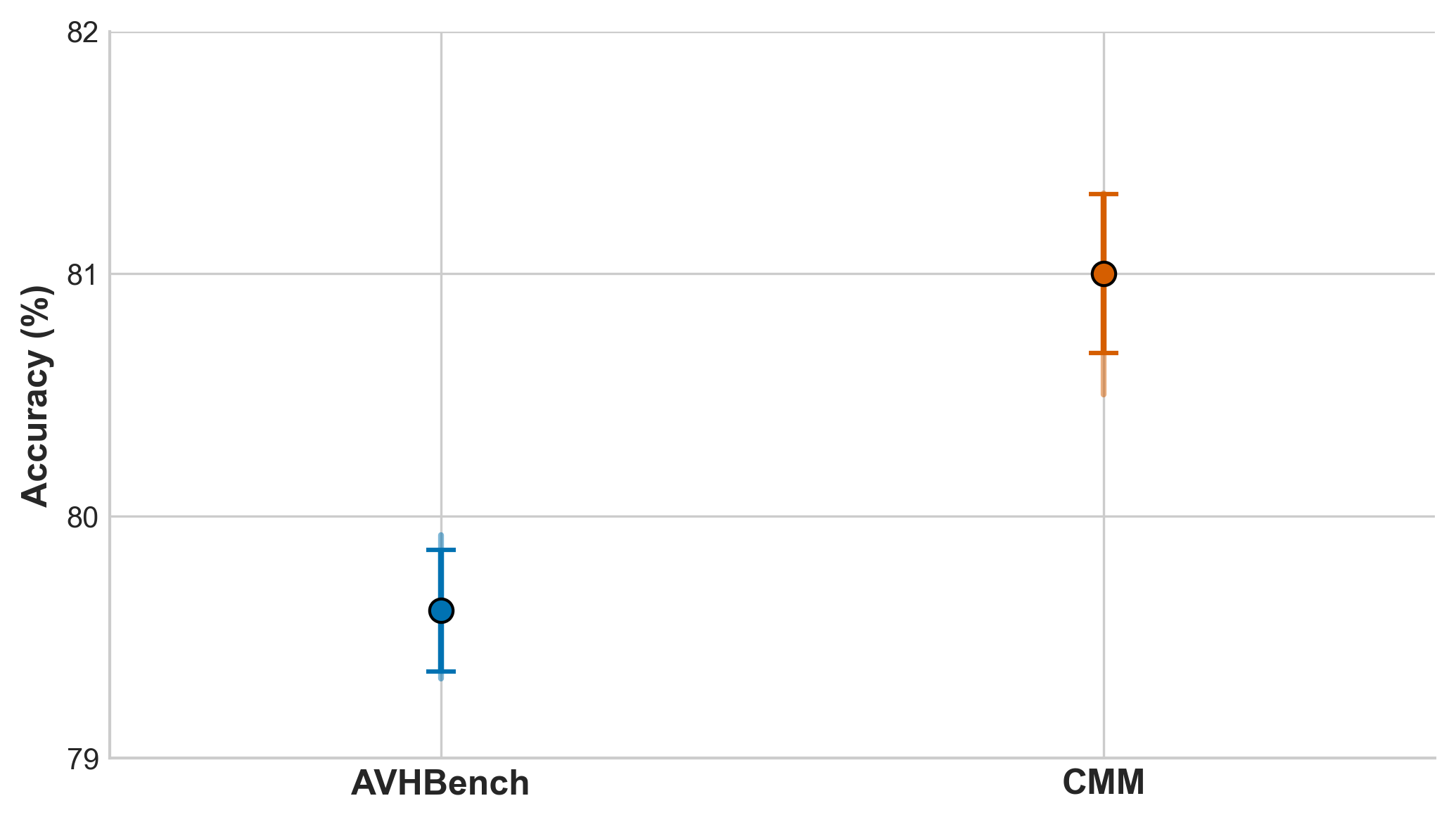
Исследования, проведенные на стандартных бенчмарках, таких как AVHBench и CMM, последовательно демонстрируют превосходство метода Modality-Adaptive Decoding над традиционными методами контрастного декодирования. В частности, зафиксировано общее улучшение показателей в задачах, связанных с визуальным доминированием, достигающее 12.3%. Этот прирост эффективности указывает на способность Modality-Adaptive Decoding более точно интерпретировать и использовать визуальную информацию, что приводит к более надежным и точным результатам в мультимодальных моделях. Полученные данные подтверждают, что предлагаемый подход позволяет существенно повысить производительность MLLM в задачах, где визуальный компонент играет ключевую роль.
В ходе оценки на бенчмарке CMM, разработанная методика продемонстрировала значительное повышение точности распознавания доминирующей модальности. С использованием модели VideoLLaMA2-AV, точность определения визуального доминирования достигла 81.3%, что на 9.3% превышает показатели базовой модели. Аналогичные результаты были получены с моделью Qwen2.5-Omni, где точность определения аудио доминирования составила 81.4%, что на 12.0% выше, чем у исходной версии. Эти данные свидетельствуют о способности данной методики существенно улучшать способность мультимодальных моделей к корректному определению наиболее значимой модальности в различных ситуациях.
Исследования показали, что применение адаптивной декодировки модальностей значительно повысило точность распознавания аудио, вызванного видео, на 4.0% при использовании модели VideoLLaMA2-AV, и точность распознавания видео, вызванного аудио, на 5.7% с моделью Qwen2.5-Omni. Этот результат указывает на способность данной методики снижать количество галлюцинаций — то есть, генерацию не соответствующих входным данным данных — в мультимодальных больших языковых моделях, тем самым повышая надежность и достоверность генерируемого контента и улучшая восприятие информации пользователем.
Полученные результаты демонстрируют значительный потенциал метода Modality-Adaptive Decoding в повышении надёжности и достоверности мультимодальных больших языковых моделей (MLLM). Данная техника позволяет существенно снизить вероятность галлюцинаций — генерации неверной или несоответствующей действительности информации — в ситуациях, когда модель полагается на разные модальности данных, такие как видео и аудио. Наблюдаемое улучшение точности на ключевых бенчмарках, включая AVHBench и CMM, свидетельствует о способности Modality-Adaptive Decoding более эффективно интегрировать информацию из различных источников, что, в свою очередь, приводит к более правдоподобным и заслуживающим доверия ответам. Повышение точности в задачах, связанных с определением доминирующей модальности и разрешением конфликтов между видео- и аудиоданными, указывает на перспективность данного подхода для создания более надёжных и полезных мультимодальных систем искусственного интеллекта.

Исследование, представленное в данной работе, демонстрирует стремление к элегантности в решении сложной проблемы — галлюцинаций в мультимодальных больших языковых моделях. Авторы предлагают метод MAD, который динамически адаптирует взвешивание модальностей, опираясь на их релевантность. Такой подход, избегающий усложнения модели, соответствует принципу, высказанному Линусом Торвальдсом: «Плохой дизайн — это просто отсутствие ясности». Работа подчеркивает, что истинное мастерство заключается не в добавлении новых возможностей, а в умении эффективно использовать существующие, убирая лишнее и фокусируясь на наиболее значимом — в данном случае, на релевантности каждой модальности для предотвращения ложных утверждений.
Что Дальше?
Предложенный подход, безусловно, демонстрирует снижение галлюцинаций, но суть проблемы кроется глубже. Устранение симптома — не лечение болезни. Упор на динамическое взвешивание модальностей — это, по сути, признание слабости самой архитектуры. Почему модели изначально нуждаются в корректировке, а не в более строгой внутренней логике? Необходимо переосмыслить принципы интеграции информации из разных источников, отказавшись от наивного предположения, что простое объединение данных приведет к пониманию.
Дальнейшие исследования неизбежно столкнутся с вопросом о границах применимости. Работает ли данный метод для произвольных комбинаций модальностей? Не принесет ли упрощение, необходимое для динамического взвешивания, новых искажений? Очевидно, что универсального решения не существует. Истина, как всегда, лежит в деталях, в специфике каждого конкретного случая.
В конечном итоге, истинный прогресс потребует не просто новых алгоритмов, а принципиально иного взгляда на природу интеллекта. Не стоит гнаться за иллюзией всезнания. Понимание границ своих возможностей — вот что действительно важно. А всё остальное — лишь игра с символами.
Оригинал статьи: https://arxiv.org/pdf/2601.21181.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Облачные вычисления для науки: гибкость и масштабируемость
2026-01-30 12:01