Автор: Денис Аветисян
Исследование показывает, что увеличение размера словарного представления, а не количества экспертов, может стать более эффективным способом улучшения производительности и скорости работы больших языковых моделей.
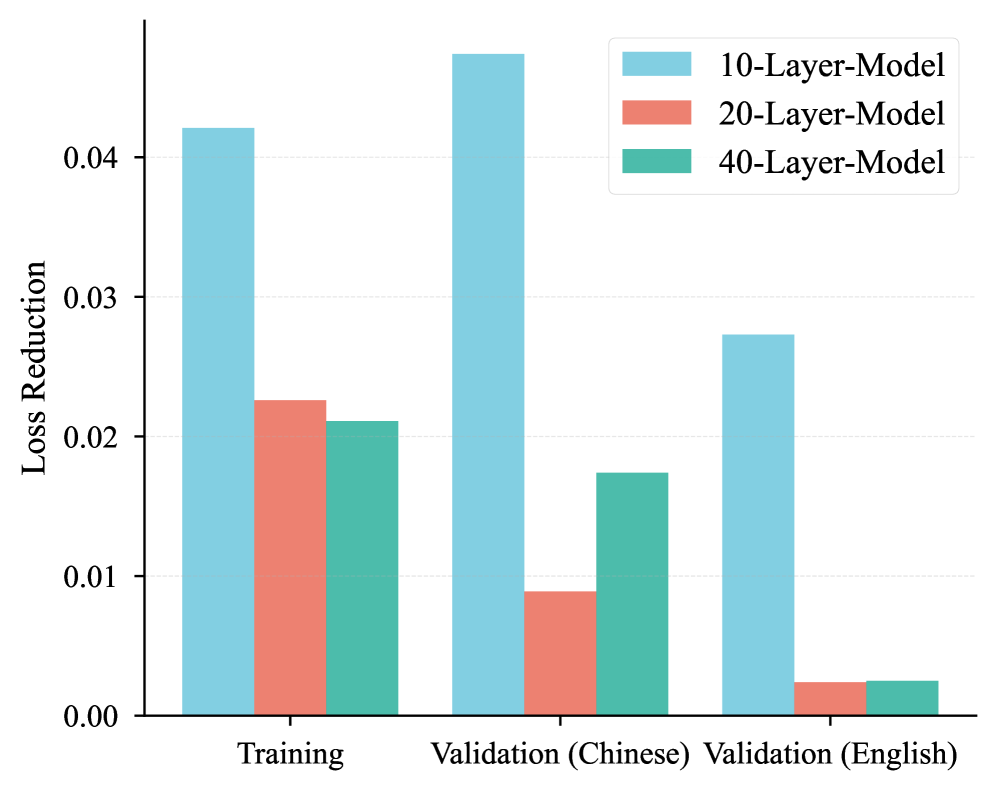
Масштабирование N-gram Embedding демонстрирует превосходство над увеличением числа экспертов в Mixture-of-Experts моделях, оптимизируя работу с длинными контекстами и повышая эффективность вывода.
Несмотря на широкое распространение архитектур, основанных на смеси экспертов (MoE), для масштабирования больших языковых моделей, они все чаще сталкиваются с проблемой уменьшения отдачи и системными ограничениями. В своей работе ‘Scaling Embeddings Outperforms Scaling Experts in Language Models’ авторы исследуют масштабирование параметров встраивания как перспективную альтернативу, способную преодолеть эти недостатки. Показано, что в определенных режимах масштабирование встраивания, особенно с использованием N-gram встраиваний, обеспечивает более выгодное соотношение между производительностью и вычислительными затратами по сравнению с масштабированием экспертов. Каковы перспективы дальнейшей оптимизации архитектур LLM за счет более эффективного использования параметров встраивания и интеграции специализированных системных оптимизаций?
Масштабирование неизбежно: Ограничения больших языковых моделей
Несмотря на впечатляющие достижения в обработке естественного языка, большие языковые модели (БЯМ) сталкиваются с фундаментальными ограничениями масштабируемости, обусловленными колоссальными вычислительными затратами. По мере увеличения числа параметров модели экспоненциально возрастают требования к памяти и вычислительной мощности, что приводит к замедлению обучения и инференса. Этот процесс становится все более дорогостоящим и энергоемким, создавая серьезные препятствия для дальнейшего развития и широкого применения БЯМ. Увеличение размеров моделей перестает приводить к пропорциональному улучшению производительности, что указывает на необходимость поиска альтернативных подходов к масштабированию, позволяющих преодолеть существующие вычислительные барьеры и реализовать весь потенциал этих мощных инструментов.
Традиционные плотные модели, несмотря на увеличение числа параметров, демонстрируют снижение эффективности масштабирования. Увеличение размеров модели не всегда приводит к пропорциональному улучшению производительности, поскольку вычислительные затраты растут экспоненциально. Это связано с тем, что не все параметры вносят равноценный вклад в решение задачи, и значительная часть вычислительных ресурсов тратится на обработку избыточной информации. По мере увеличения масштаба модели, эффект от добавления новых параметров постепенно снижается, приводя к уменьшению прироста в точности и скорости работы. Таким образом, простое увеличение количества параметров не является устойчивым путем к созданию более мощных языковых моделей, и необходимы новые подходы к организации и использованию этих параметров.
Основная проблема дальнейшего развития больших языковых моделей заключается в разделении их способности к обучению и запоминанию информации от растущих вычислительных затрат. Традиционный подход к увеличению размера модели, добавляя все больше параметров, демонстрирует снижение эффективности: каждое последующее увеличение требует экспоненциально больше вычислительных ресурсов для обучения и использования. Это создает серьезный барьер для создания действительно масштабируемых систем, способных обрабатывать и понимать огромные объемы данных. Для преодоления этого ограничения необходимы инновационные архитектуры и методы повышения эффективности параметров, позволяющие модели сохранять или даже улучшать свои возможности, не увеличивая при этом вычислительную сложность. Именно это разделение потенциала модели и её стоимости является ключевой задачей, определяющей будущее больших языковых моделей.
Для преодоления ограничений масштабируемости больших языковых моделей необходимы инновационные архитектурные решения и методы повышения эффективности использования параметров. Исследования направлены на разработку моделей, способных к экспоненциальному росту производительности без пропорционального увеличения вычислительных затрат. Особое внимание уделяется техникам разреженности, квантизации и дистилляции знаний, позволяющим уменьшить размер модели и ускорить вычисления без значительной потери точности. Помимо этого, перспективным направлением является изучение альтернативных архитектур, таких как Mixture of Experts и State Space Models, которые предлагают новые способы организации и использования параметров, открывая путь к созданию более мощных и эффективных языковых моделей будущего.
Разреженность как ключ: Архитектура Mixture-of-Experts
Архитектура Mixture-of-Experts (MoE) характеризуется динамической активацией лишь части параметров — так называемых «экспертов» — для обработки каждого входного токена. Вместо использования всех параметров модели для каждого токена, MoE маршрутизирует каждый токен к подмножеству экспертов, что значительно снижает вычислительные затраты. Этот процесс создает разреженность (sparsity), поскольку большинство параметров остаются неактивными при обработке конкретного токена. Степень разреженности определяется механизмами маршрутизации и параметрами активации, позволяя эффективно использовать модель с большим количеством параметров при сохранении приемлемой скорости обработки.
Архитектура Mixture-of-Experts (MoE) достигает разделения между вычислительной емкостью и стоимостью за счет механизмов маршрутизации, которые динамически определяют, какие эксперты обрабатывают каждый входной токен. Эти механизмы, как правило, основаны на использовании gating-сетей, которые предсказывают веса для каждого эксперта в зависимости от входного токена. Токены направляются к небольшому подмножеству экспертов с наивысшими весами, что позволяет модели поддерживать большую общую емкость (общее количество параметров всех экспертов) при одновременном использовании лишь небольшой части параметров для каждого конкретного ввода. Это позволяет эффективно масштабировать модели, поскольку увеличение емкости не обязательно приводит к пропорциональному увеличению вычислительных затрат.
Эффективные модели MoE требуют тщательного подбора параметров активации и стратегий для минимизации накладных расходов на коммуникацию. Выбор количества активируемых экспертов (sparsity) и способ их маршрутизации оказывают существенное влияние на производительность. Высокая степень разреженности снижает вычислительные затраты, но может увеличить объем передаваемых данных между устройствами, особенно в распределенных системах. Стратегии, такие как gated routing и expert balancing, направлены на оптимизацию баланса между разреженностью и коммуникационными издержками, учитывая такие факторы, как пропускная способность сети и задержки. Неоптимальные параметры активации могут привести к перегрузке отдельных экспертов или неэффективному использованию ресурсов, снижая общую эффективность модели.
Разреженность является ключевым принципом работы архитектуры Mixture-of-Experts (MoE), обеспечивающим возможность масштабирования больших языковых моделей (LLM) за пределы ограничений, присущих плотным архитектурам. В отличие от плотных моделей, где все параметры задействованы при обработке каждого токена, MoE динамически активирует лишь подмножество параметров («экспертов») для каждого входного токена. Это позволяет значительно увеличить общую емкость модели без пропорционального увеличения вычислительных затрат и требований к памяти, поскольку большая часть параметров остается неактивной при обработке конкретного запроса. Такой подход позволяет создавать модели с триллионами параметров, которые могут быть эффективно развернуты и обучены на доступном оборудовании, преодолевая ограничения, связанные с необходимостью хранения и обработки огромных матриц весов в плотных моделях.
Расширение емкости без издержек: N-gram Embedding
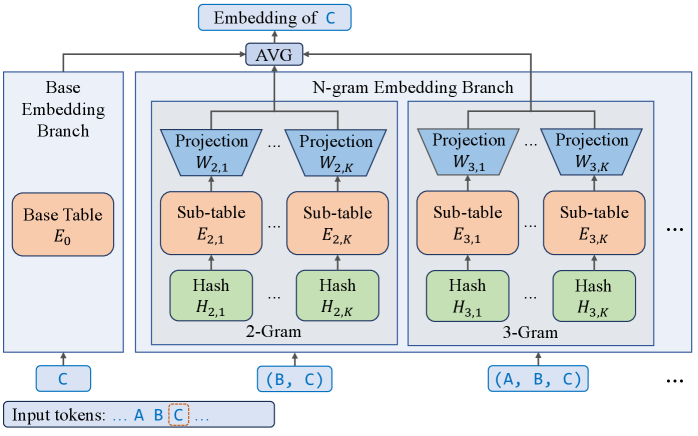
Встраивание N-грамм дополняет векторные представления токенов информацией о последовательностях N токенов (N-граммах), что позволяет значительно расширить словарный запас модели. В отличие от традиционных методов маршрутизации, требующих дополнительных вычислений для обработки новых токенов, N-граммное встраивание позволяет эффективно добавлять новые последовательности без существенного увеличения вычислительной нагрузки. Это достигается за счет того, что N-граммы рассматриваются как расширенные признаки токенов, а не как отдельные сущности, требующие отдельной обработки при маршрутизации. Таким образом, N-граммное встраивание позволяет модели запоминать и использовать информацию о более длинных последовательностях токенов, не увеличивая при этом сложность вычислений, связанных с маршрутизацией и обработкой входных данных.
Внедрение N-gram Embedding позволяет значительно расширить количество параметров модели, эффективно увеличивая её ёмкость без необходимости увеличения вычислительных затрат на маршрутизацию. Традиционное увеличение ёмкости модели требует дополнительных вычислений для обработки расширенного пространства токенов. N-gram Embedding обходит это ограничение, добавляя параметры, связанные с n-граммами, что позволяет модели запоминать и использовать больше информации без пропорционального увеличения сложности вычислений. Это особенно важно для масштабных языковых моделей, где увеличение ёмкости напрямую связано с улучшением производительности и способностью к обобщению.
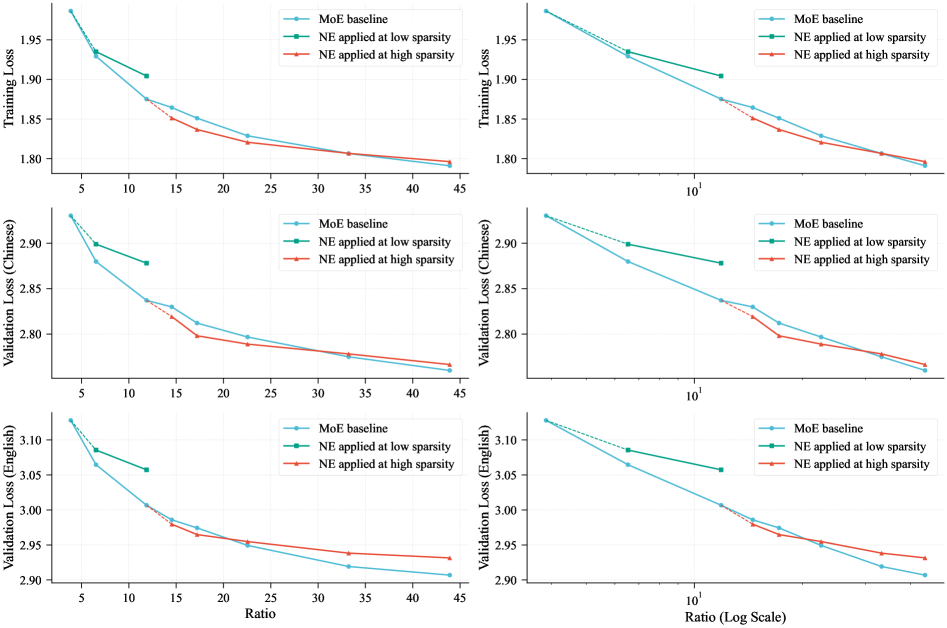
Законы масштабирования показывают, что более крупные языковые модели, при условии корректной тренировки, демонстрируют превосходящую производительность в различных задачах обработки естественного языка. Это означает, что увеличение числа параметров модели, как правило, приводит к улучшению качества генерируемого текста, точности ответов и способности к обобщению. Техника N-gram Embedding позволяет значительно расширить ёмкость модели, увеличивая количество параметров без значительного увеличения вычислительных затрат, что делает её эффективным способом повышения производительности в соответствии с принципами, установленными законами масштабирования.
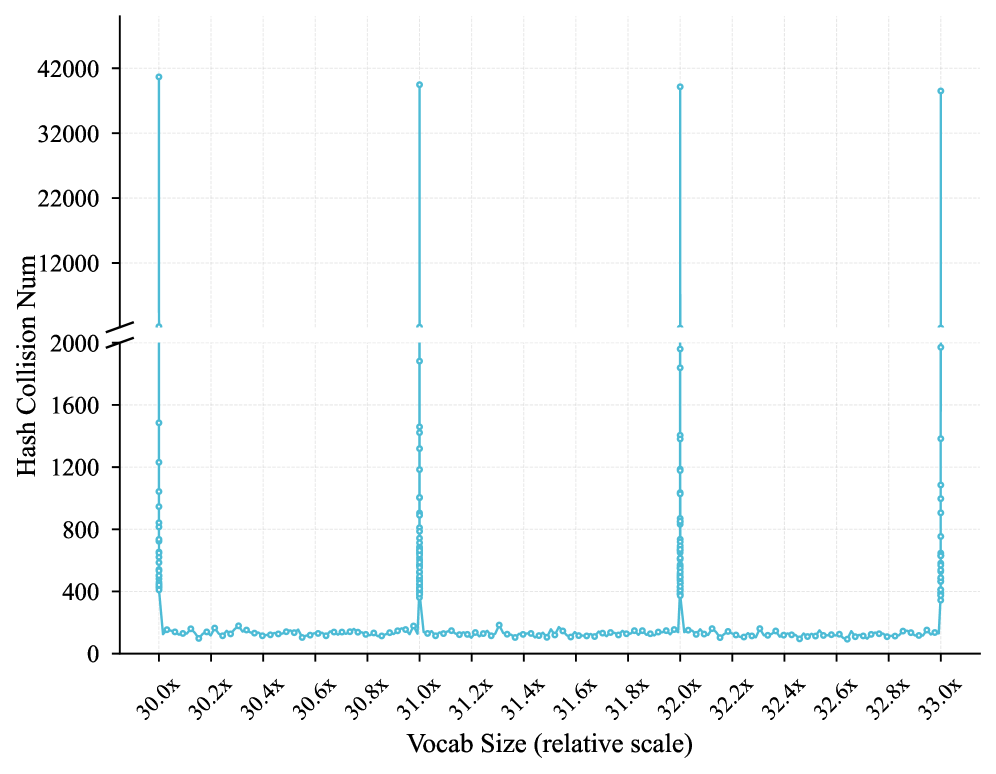
Модель LongCat-Flash-Lite, насчитывающая 68.5 миллиардов параметров, выделяет более 30 миллиардов параметров исключительно для N-gram Embedding, что составляет более 46% от общего числа параметров модели. Данный подход позволяет значительно расширить возможности модели без существенного увеличения вычислительных затрат, поскольку большая часть дополнительных параметров используется для хранения и обработки N-gram представлений токенов, а не для усложнения операций маршрутизации или вычислений в процессе инференса. Фактически, значительная доля от общего числа параметров модели посвящена представлению N-gram, что демонстрирует важность данного метода для повышения емкости модели и, как следствие, ее производительности.
Влияние на производительность: Оптимизация инференса масштабируемых моделей
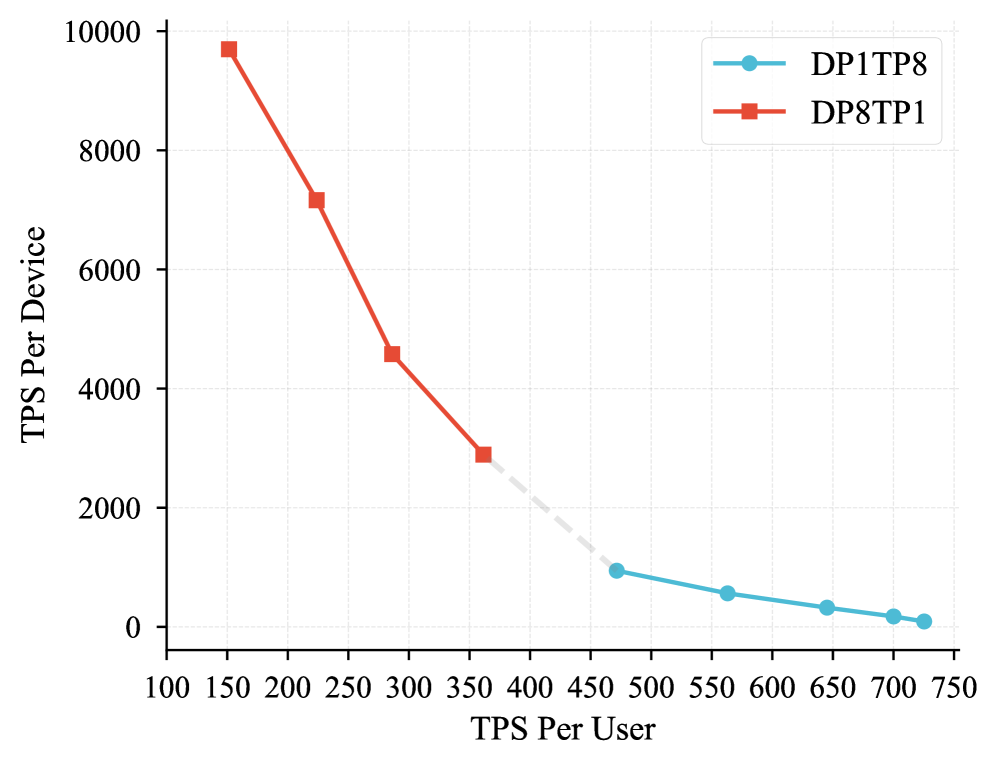
Эффективный вывод данных является ключевым фактором для успешного развертывания масштабных моделей, таких как LongCat-Flash-Lite, использующей технологию N-gram Embedding и Mixture of Experts (MoE). Необходимость быстрой обработки запросов обусловлена тем, что задержка при выводе напрямую влияет на пользовательский опыт и стоимость обслуживания. LongCat-Flash-Lite, благодаря оптимизированной архитектуре и использованию N-gram Embedding для компактного представления данных, а также MoE для повышения эффективности, стремится обеспечить высокую скорость вывода при сохранении точности.
Для существенного снижения задержки и повышения пропускной способности при работе с крупномасштабными моделями, такими как LongCat-Flash-Lite, применяются передовые методы оптимизации. Kernel Fusion объединяет несколько операций ядра в один, уменьшая накладные расходы на запуск и межпроцессное взаимодействие. Programmatic Dependent Launch (PDL) позволяет более гибко управлять запуском ядер, адаптируя их к специфическим характеристикам данных и аппаратного обеспечения. Наконец, Expert Parallel (EP) эффективно распараллеливает вычисления, распределяя нагрузку между несколькими экспертами, что особенно важно при использовании архитектур Mixture-of-Experts.
Исследования показывают, что техника Single Batch Overlap (SBO) еще больше повышает эффективность, перекрывая выполнение различных вычислительных ядер. Вместо последовательного запуска каждого ядра, SBO инициирует выполнение следующего ядра до завершения предыдущего, эффективно скрывая задержки, связанные с передачей данных и переключением контекста. Такой подход существенно повышает пропускную способность и снижает общие вычислительные затраты, что позволяет создавать еще более мощные и эффективные языковые модели.
Модель LongCat-Flash-Lite демонстрирует конкурентоспособную производительность, работая с диапазоном активированных параметров от 2.9 до 4.5 миллиардов. Несмотря на значительно меньший размер по сравнению с более крупными моделями, такими как Qwen3-Next-80B, LongCat-Flash-Lite достигает впечатляющих результатов на различных бенчмарках. Такая эффективность достигается благодаря оптимизациям в архитектуре, включая использование N-gram Embedding и Mixture of Experts (MoE), что позволяет модели сохранять высокую точность при относительно небольшом количестве параметров.
Взгляд в будущее: Преодоление границ масштабирования
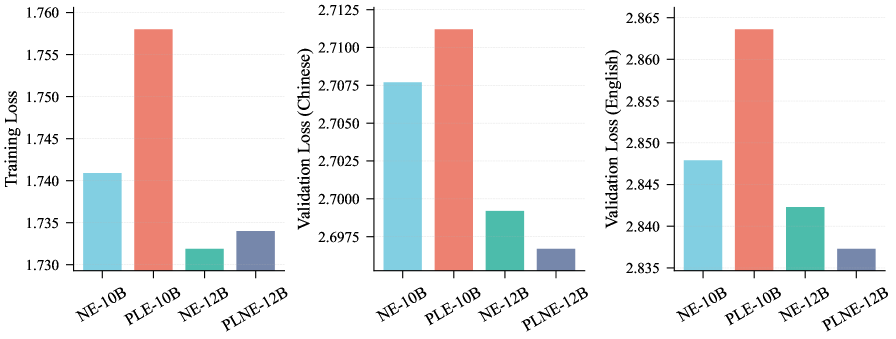
Архитектурные модификации, такие как внедрение Per-Layer Embedding (PLE) и структурное расширение, представляют собой перспективные пути увеличения емкости языковых моделей. PLE позволяет каждому слою сети формировать собственное представление о входных данных, что способствует более тонкой настройке и улучшению способности модели к обобщению. В свою очередь, структурное расширение подразумевает добавление новых слоев или блоков, не увеличивая при этом вычислительную сложность за счет использования разреженных связей. Сочетание этих подходов позволяет создавать модели с значительно большей емкостью, способные обрабатывать более сложные задачи и демонстрировать улучшенные результаты в обработке естественного языка, при этом эффективно используя доступные вычислительные ресурсы и память.
Для дальнейшего повышения эффективности моделей с разреженной активацией (MoE) ключевым направлением является оптимизация алгоритмов маршрутизации и коммуникационных протоколов. Современные MoE-архитектуры, хоть и демонстрируют значительный прирост производительности, часто сталкиваются с узкими местами при передаче данных между экспертами и маршрутизаторами. Исследования направлены на разработку более интеллектуальных алгоритмов, способных динамически адаптироваться к изменениям в структуре данных и распределять нагрузку между экспертами более равномерно. Особое внимание уделяется снижению задержек при обмене информацией и минимизации энергопотребления, что особенно важно для развертывания масштабных моделей на ограниченных ресурсах.
Исследования в области разреженных представлений и техник компрессии демонстрируют значительный потенциал для снижения требований к памяти и повышения скорости работы больших языковых моделей. Вместо хранения всех параметров сети, эти методы фокусируются на идентификации и сохранении лишь наиболее важных весов, а остальные либо обнуляются, либо представляются в сжатом виде. Инновационные подходы к разреженности, такие как структурированная разреженность и динамическое распределение ресурсов, позволяют добиться существенного сокращения вычислительных затрат без значительной потери точности. Комбинация различных техник компрессии, включая квантизацию, прунинг и дистилляцию знаний, открывает перспективы для развертывания мощных языковых моделей на устройствах с ограниченными ресурсами, расширяя их доступность и практическое применение.
Сочетание описанных подходов — архитектурных модификаций, оптимизации маршрутизации и применения инновационных методов разреженности — открывает перспективы для существенного увеличения возможностей больших языковых моделей. Исследования показывают, что параллельное внедрение технологий, таких как Per-Layer Embedding и Structural Expansion, в сочетании с усовершенствованными протоколами связи, способно не только повысить эффективность обработки информации, но и значительно снизить требования к вычислительным ресурсам. Ожидается, что подобный синергетический эффект позволит преодолеть текущие ограничения в области обработки естественного языка, приближая создание систем, способных к более глубокому пониманию и генерации текстов, а также к решению сложных задач, требующих интеллектуального анализа и синтеза информации.
Исследование показывает, что гонка за увеличением числа экспертов в моделях машинного обучения не всегда является наиболее эффективным путем. Авторы предлагают иной подход — масштабирование параметров встраивания, в частности, использование N-грамм. Это напоминает о том, что архитектура — это не структура, а компромисс, застывший во времени. Словно древний садовник, взращивающий дерево, необходимо уделить внимание корням — представлению данных — а не только верхушке — количеству параметров. Как заметил Эдсгер Дейкстра: “Простота — это высшая степень совершенства.” Иногда, чтобы достичь большего, необходимо отказаться от излишней сложности и сосредоточиться на фундаментальных основах представления информации, особенно в контексте длинного моделирования и оптимизации вывода.
Что же дальше?
Рассмотренные здесь методы масштабирования представлений, безусловно, обнажают новую грань в вечном поиске более эффективных языковых моделей. Однако, подобно любому садовнику, знающему, что прививка не гарантирует урожай, следует помнить: увеличение параметров встраивания — это не панацея. Это лишь один из путей, и, как показывает опыт, каждый рефакторинг начинается как молитва и заканчивается покаянием.
Проблема долгосрочного контекста и эффективного использования разреженных активаций остается открытой. Увеличение размера словаря N-грамм может привести к неожиданным последствиям, к новым формам «забывания» и искажениям, которые еще предстоит изучить. Система взрослеет, и ее капризы будут проявляться все чаще. Не стоит забывать, что архитектурный выбор — это пророчество о будущем сбое.
Будущие исследования, вероятно, сосредоточатся на симбиозе этих подходов — на поиске баланса между масштабированием экспертов и представлений, а также на разработке методов динамической адаптации размера словаря N-грамм в зависимости от контекста. И, конечно, на принятии того факта, что идеальной системы не существует — лишь системы, которые учатся жить со своими недостатками.
Оригинал статьи: https://arxiv.org/pdf/2601.21204.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Моделирование биомолекул: новый импульс от нейросетей
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Облачные вычисления для науки: гибкость и масштабируемость
2026-01-30 14:12