Автор: Денис Аветисян
Новая модель Qwen3-ASR открывает возможности для точного и многоязычного распознавания речи, обеспечивая высокую точность и временную синхронизацию.

Представлена семейство больших аудио-языковых моделей для автоматического распознавания речи и новый многоязычный инструмент принудительной выверки.
Несмотря на значительный прогресс в области автоматического распознавания речи, обеспечение высокой точности и эффективности для широкого спектра языков остается сложной задачей. В настоящем отчете, ‘Qwen3-ASR Technical Report’, представлена семейство моделей Qwen3-ASR, включающее в себя всесторонние модели автоматического распознавания речи и инновационную модель неавторегрессивного выравнивания речи, демонстрирующие передовые результаты в многоязычном распознавании и точном предсказании временных меток. Эксперименты показывают, что разработанные модели превосходят существующие аналоги по ключевым показателям, предлагая оптимальный баланс между точностью и скоростью обработки. Какие перспективы открываются для дальнейшего развития технологий обработки речи и аудио, основанных на больших языковых моделях?
Призраки чистого сигнала: О проблемах распознавания речи
Традиционные методы автоматического распознавания речи (ASR), включая сквозные (End-to-End) подходы, зачастую демонстрируют снижение эффективности в условиях зашумленной среды и при обработке речи с различными акцентами. Это связано с тем, что существующие модели, как правило, обучаются на относительно чистых и стандартизированных данных, что ограничивает их способность адаптироваться к реальным акустическим условиям и вариативности произношения. Шум, эхо, фоновые разговоры и особенности артикуляции, связанные с акцентом, могут искажать речевой сигнал, приводя к ошибкам в распознавании. В результате, даже современные ASR-системы испытывают трудности с точным преобразованием речи в текст в неидеальных условиях, подчеркивая необходимость разработки более устойчивых и адаптивных алгоритмов.
Ограничения существующих систем автоматического распознавания речи (ASR) в условиях реального мира подчеркивают необходимость разработки более устойчивых и адаптируемых технологий. Традиционные методы, включая сквозные (End-to-End) подходы, часто демонстрируют снижение точности при наличии шумов или при обработке речи с различными акцентами. Это требует инновационных решений, способных эффективно фильтровать помехи и учитывать лингвистические особенности различных диалектов. Исследования направлены на создание систем, которые не только точно транскрибируют речь в идеальных условиях, но и сохраняют высокую производительность в сложных акустических средах и при взаимодействии с разнообразными пользователями, что критически важно для широкого внедрения ASR в повседневную жизнь и профессиональную деятельность.
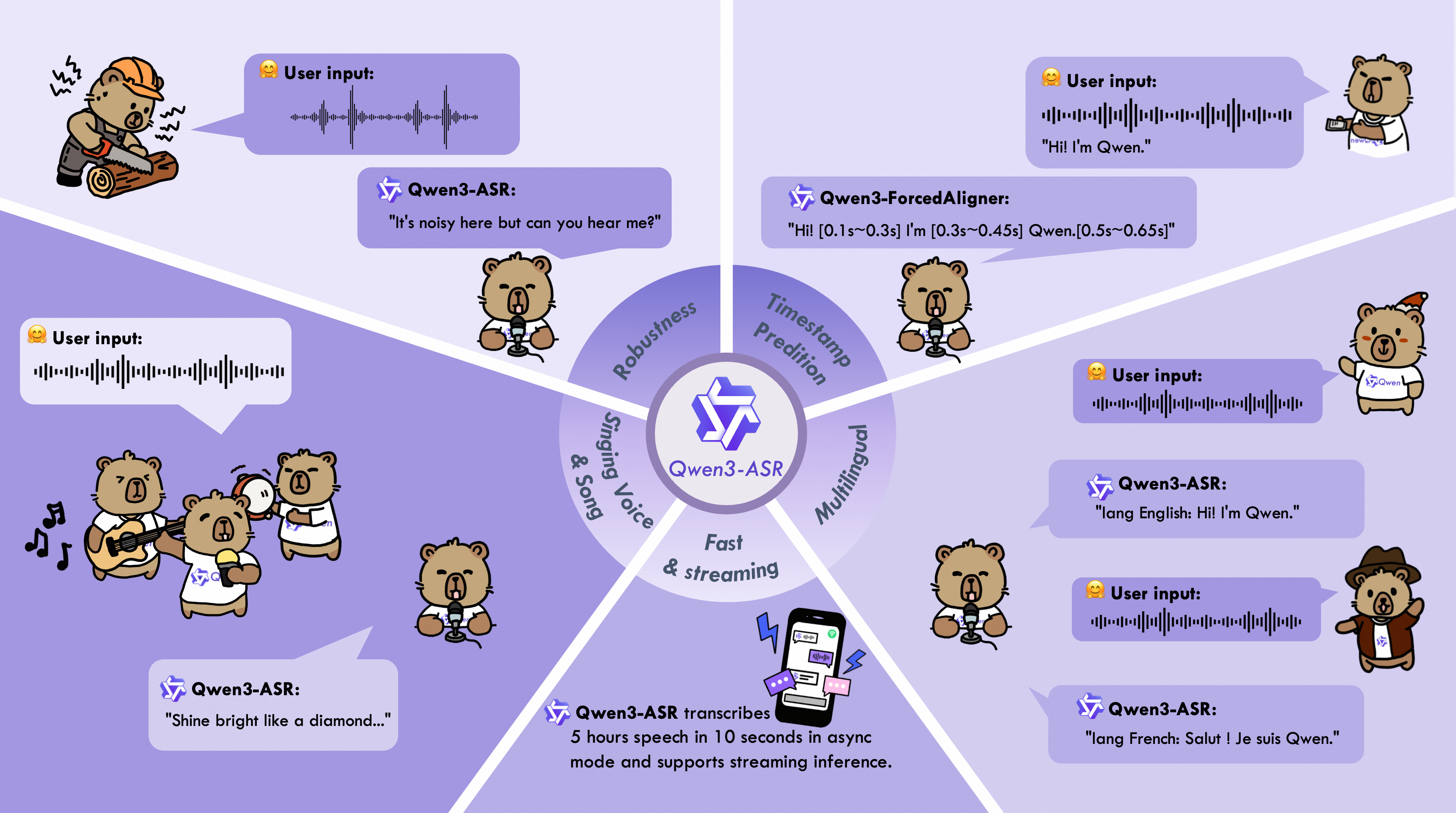
Qwen3-ASR: Новый взгляд на аудио-языковые модели
Семейство Qwen3-ASR представляет собой новое поколение систем автоматического распознавания речи (ASR), построенных на основе больших аудио-языковых моделей (LALM). В отличие от традиционных ASR-систем, использующих отдельные акустические и языковые модели, Qwen3-ASR интегрирует эти компоненты в единую нейронную сеть, что позволяет более эффективно моделировать взаимосвязь между звуком и текстом. Этот подход позволяет системе лучше понимать контекст речи, снижать количество ошибок распознавания и повышать общую производительность, особенно в сложных акустических условиях и при наличии акцентов.
Архитектура Qwen3-ASR использует возможности предварительно обученных моделей, таких как Qwen3-Omni, для обеспечения глубокого понимания аудио и повышения производительности в различных условиях. Предварительное обучение на обширных данных позволяет модели эффективно извлекать признаки из аудиосигналов и устанавливать связи между звуком и текстом. Это позволяет Qwen3-ASR демонстрировать улучшенную устойчивость к шумам, акцентам и другим вариациям в аудио, а также более точное распознавание речи в сложных акустических средах. Использование предварительно обученных моделей значительно снижает потребность в большом количестве размеченных данных для обучения конкретной задачи распознавания речи.
Семейство Qwen3-ASR использует архитектуру «внимание-энкодер-декодер» с применением энкодера AuT, обученного на обширном наборе данных объемом 40 миллионов часов псевдо-размеченных данных для автоматического распознавания речи. Основной объем данных представлен китайским и английским языками. В процессе обучения также использовались 3 триллиона токенов, полученных в результате предварительного обучения модели Omni, что позволило значительно повысить точность и надежность распознавания речи в различных условиях.
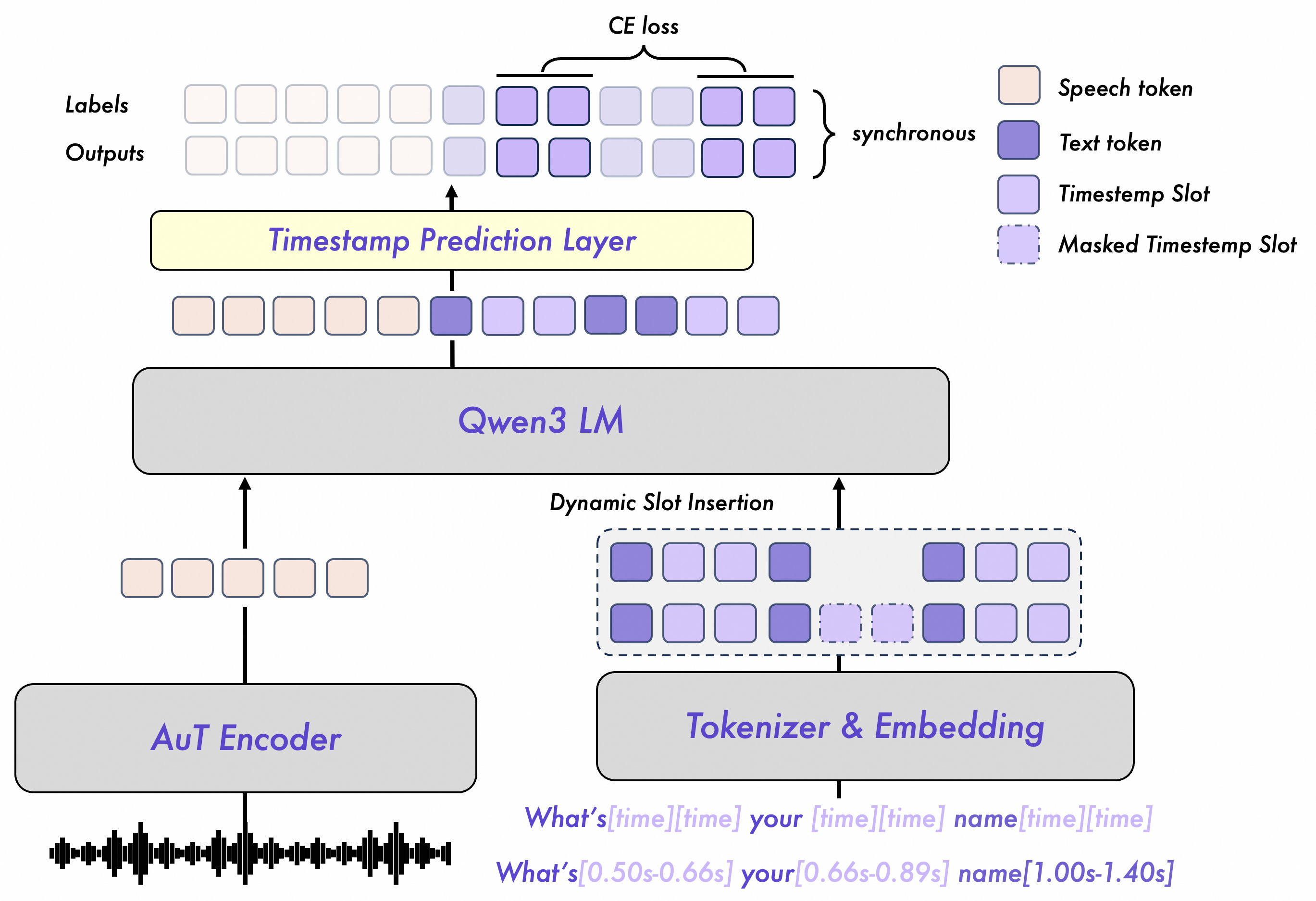
Принудительное выравнивание речи с Qwen3: Точность во времени
Модель Qwen3-ForcedAligner-0.6B обеспечивает точное выравнивание (Forced Alignment), являющееся ключевым этапом в задачах обработки речи. Процесс Forced Alignment заключается в установлении соответствия между аудиосигналом и его текстовой расшифровкой, определяя временные метки для каждого фонетического сегмента в аудиозаписи. Это необходимо для задач, требующих синхронизации аудио и текста, таких как синтез речи, распознавание речи и анализ речи, а также для создания размеченных данных для обучения моделей автоматического распознавания речи.
Модель Qwen3-ForcedAligner-0.6B, являясь облегченным выравнивателем на основе LALM, поддерживает принудительное выравнивание (Forced Alignment) для 11 языков, включая русский. Особенностью данной модели является возможность гибкого предсказания временных меток (timestamps), что позволяет точно сопоставлять аудиофрагменты с соответствующими текстовыми транскрипциями. Гибкость предсказания меток обеспечивает адаптацию к различным скоростям речи и особенностям произношения, повышая точность выравнивания для широкого спектра аудиоматериалов.
Семейство моделей Qwen3-ASR обучалось на 50 тысячах образцов данных, полученных с использованием обучения с подкреплением (Reinforcement Learning, RL). Структура обучающего набора данных включает 35% образцов на китайском и английском языках, 35% многоязычных образцов и 30% функциональных данных, что обеспечивает широкое покрытие языков и сценариев использования для повышения точности и надежности системы распознавания речи.
Власть многоязычия и масштабируемая производительность Qwen3
Семейство Qwen3-ASR демонстрирует выдающиеся многоязыковые возможности, поддерживая распознавание речи на 52 языках и диалектах, а также на 22 диалектах китайского языка. Достигнутые показатели производительности превосходят аналогичные открытые модели автоматического распознавания речи (ASR), устанавливая новый стандарт в этой области. Данная поддержка широкого спектра языков и диалектов, в сочетании с передовыми алгоритмами, позволяет Qwen3-ASR эффективно обрабатывать речь в различных лингвистических контекстах, обеспечивая высокую точность и надежность распознавания даже в сложных акустических условиях. Это делает семейство Qwen3-ASR ценным инструментом для широкого круга приложений, от глобальных голосовых помощников до специализированных систем транскрипции.
Семейство моделей Qwen3-ASR демонстрирует впечатляющий компромисс между вычислительной эффективностью и передовой точностью распознавания речи. В частности, модели Qwen3-ASR-0.6B и Qwen3-ASR-1.7B позволяют достичь результатов, сопоставимых с более крупными и ресурсоемкими системами, при значительно меньших требованиях к вычислительным мощностям. Такое сочетание характеристик делает их особенно привлекательными для широкого спектра приложений, где важна как высокая производительность, так и возможность развертывания на устройствах с ограниченными ресурсами, например, на мобильных платформах или встраиваемых системах. Достигнутая оптимизация позволяет снизить задержки и энергопотребление, открывая новые возможности для использования автоматического распознавания речи в реальном времени.
Сочетание высокой производительности и масштабируемости делает Qwen3-ASR передовым решением для широкого спектра приложений автоматического распознавания речи. Данная модель демонстрирует конкурентоспособность с проприетарными коммерческими API, предлагая альтернативу, не уступающую им в точности, но при этом обладающую открытым исходным кодом. Это позволяет разработчикам и организациям интегрировать передовые технологии распознавания речи в свои проекты без ограничений, связанных с лицензированием и зависимостью от внешних поставщиков. Qwen3-ASR открывает новые возможности для создания инновационных приложений в области голосовых помощников, транскрибации аудио- и видеоматериалов, а также автоматизации различных процессов, требующих обработки речи.
В отчёте о Qwen3-ASR, как и во многих других работах, описывающих прорывные модели, заявлена высокая точность распознавания речи и предсказания временных меток. Однако, стоит помнить, что любая, даже самая элегантная архитектура, рано или поздно столкнётся с суровой реальностью продакшена. Как однажды заметил Дональд Дэвис: «Простота — это главное. Но это трудно». Иными словами, стремление к бесконечной масштабируемости и поддержке множества языков, описанное в отчёте, — это лишь первый шаг. Настоящая проверка придёт с первыми тысячами пользователей и терабайтами реальных аудиоданных, когда станет ясно, насколько хорошо модель выдержит нагрузку и сохранит заявленное качество. Ведь зелёные тесты — это, конечно, приятно, но они мало что говорят о реальной надёжности системы.
Что дальше?
Представленная работа, как и все подобные, демонстрирует впечатляющие результаты на стандартных бенчмарках. Но за этими цифрами неизменно скрывается вопрос: сколько ресурсов было потрачено, чтобы получить этот прирост в процентах? И сколько ещё потребуется, чтобы система стабильно работала в реальных условиях, с шумами, акцентами и, не дай бог, спонтанными репликами пользователей? По сути, каждое новое поколение систем автоматического распознавания речи — это просто более сложная обёртка над вечными проблемами обработки акустических сигналов.
Особый интерес вызывает заявленная точность временных меток. Кажется, все забыли, что в конечном итоге, даже идеально выровненный текст не спасёт от необходимости ручной вычитки. В конце концов, «точное» время — это лишь иллюзия, пока кто-то не попробует использовать эту информацию для действительно полезных задач. И тогда всегда найдётся способ сломать элегантную теорию.
Вероятно, следующим шагом станет ещё больше данных и ещё более сложные архитектуры. Но не стоит забывать, что «всё новое — это просто старое с худшей документацией». Реальный прогресс заключается не в погоне за SOTA, а в создании систем, которые просто работают, и которые можно поддерживать без необходимости вызывать команду аспирантов каждый раз, когда что-то идёт не так.
Оригинал статьи: https://arxiv.org/pdf/2601.21337.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Робот-исследователь: новый подход к автономной навигации
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Самообучающиеся признаки: новый подход к машинному обучению
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Искусственный интеллект: хрупкость визуального мышления
2026-01-30 17:31