Автор: Денис Аветисян
Исследователи предлагают инновационный подход к предварительному обучению, позволяющий использовать сильные модели для улучшения качества, безопасности и достоверности генерируемого текста.

Метод самосовершенствующегося предварительного обучения (Self-Improving Pretraining) использует переобученные модели для контроля над процессом обучения и повышения эффективности языковых моделей.
Несмотря на значительные успехи в обучении больших языковых моделей, обеспечение их безопасности, фактической точности и общего качества генерируемого текста остается сложной задачей. В данной работе, ‘Self-Improving Pretraining: using post-trained models to pretrain better models’, предложен новый метод предварительного обучения, использующий обученную модель для оценки и улучшения генерируемых последовательностей посредством переписывания и обучения с подкреплением. Этот подход позволяет создавать модели с улучшенными показателями фактической точности и безопасности уже на этапе предварительного обучения, демонстрируя относительное улучшение до 36.2% и 18.5% соответственно. Сможет ли подобный самообучающийся подход стать основой для создания более надежных и контролируемых языковых моделей будущего?
Проблема масштаба и надёжности языковых моделей
Современные большие языковые модели демонстрируют впечатляющую способность к генерации связных последовательностей текста, однако традиционный подход, основанный на предсказании следующего токена, часто испытывает трудности с обеспечением фактической точности и безопасности. В процессе обучения модели фокусируются на статистической вероятности продолжения текста, а не на его соответствии реальности или этическим нормам. Это приводит к тому, что модель может генерировать правдоподобно звучащие, но ложные утверждения или содержащий вредоносный контент, особенно если обучающий набор данных не подвергался тщательной фильтрации и проверке. Таким образом, высокая эффективность в генерации текста не гарантирует надежность и безопасность создаваемого контента, что представляет серьезную проблему для практического применения этих моделей.
Увеличение размера языковой модели само по себе не гарантирует повышения достоверности генерируемых текстов и не решает проблему создания потенциально опасного контента. Исследования показывают, что даже самые крупные модели, обученные на необработанных данных, таких как датасет RedPajama, могут выдавать фактические ошибки и генерировать предвзятые или вредоносные высказывания. Простое наращивание параметров модели не способно компенсировать недостатки исходных данных и требует дополнительных методов контроля качества и фильтрации, а также разработки специализированных алгоритмов, направленных на повышение надежности и безопасности генерируемых текстов. Таким образом, ключевым фактором является не только масштаб модели, но и качество данных, на которых она обучается, а также применяемые механизмы контроля.
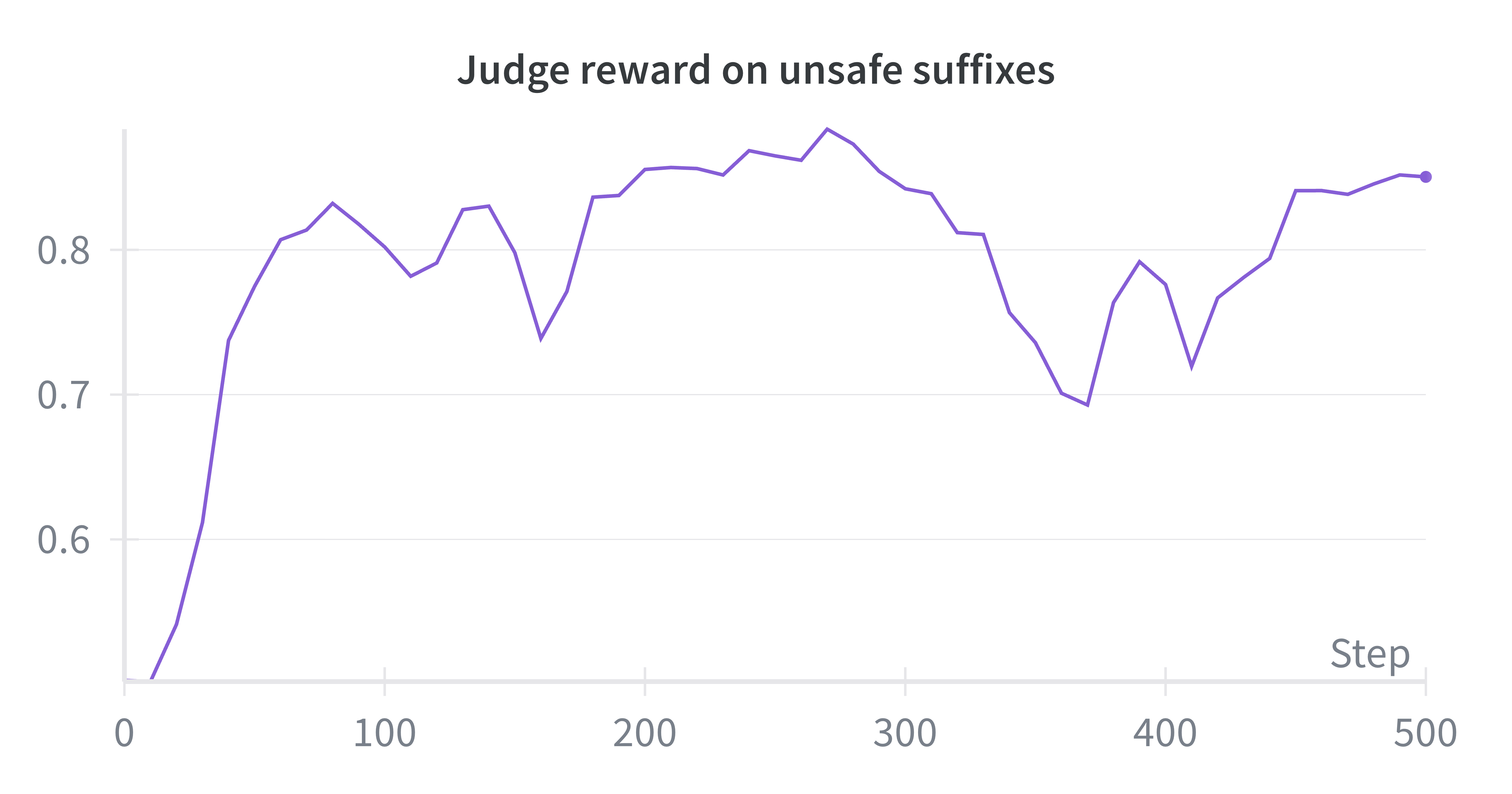
Самообучающееся предварительное обучение: новый подход к совершенствованию
Метод самообучающегося предварительного обучения (Self-Improving Pretraining) использует сильную, предварительно обученную модель (Post-Trained Model) для двух ключевых операций: переписывания сгенерированных последовательностей и оценки их качества. Модель выступает в роли и генератора, и критика, что позволяет итеративно улучшать выходные данные без необходимости внешних данных или ручной разметки. В процессе генерации, модель не только создает текст, но и оценивает его соответствие заданным критериям, используя эту оценку для корректировки и улучшения последующих сгенерированных токенов. Такой подход позволяет модели самостоятельно выявлять и исправлять собственные ошибки, что приводит к повышению качества, фактической точности и безопасности генерируемого контента.
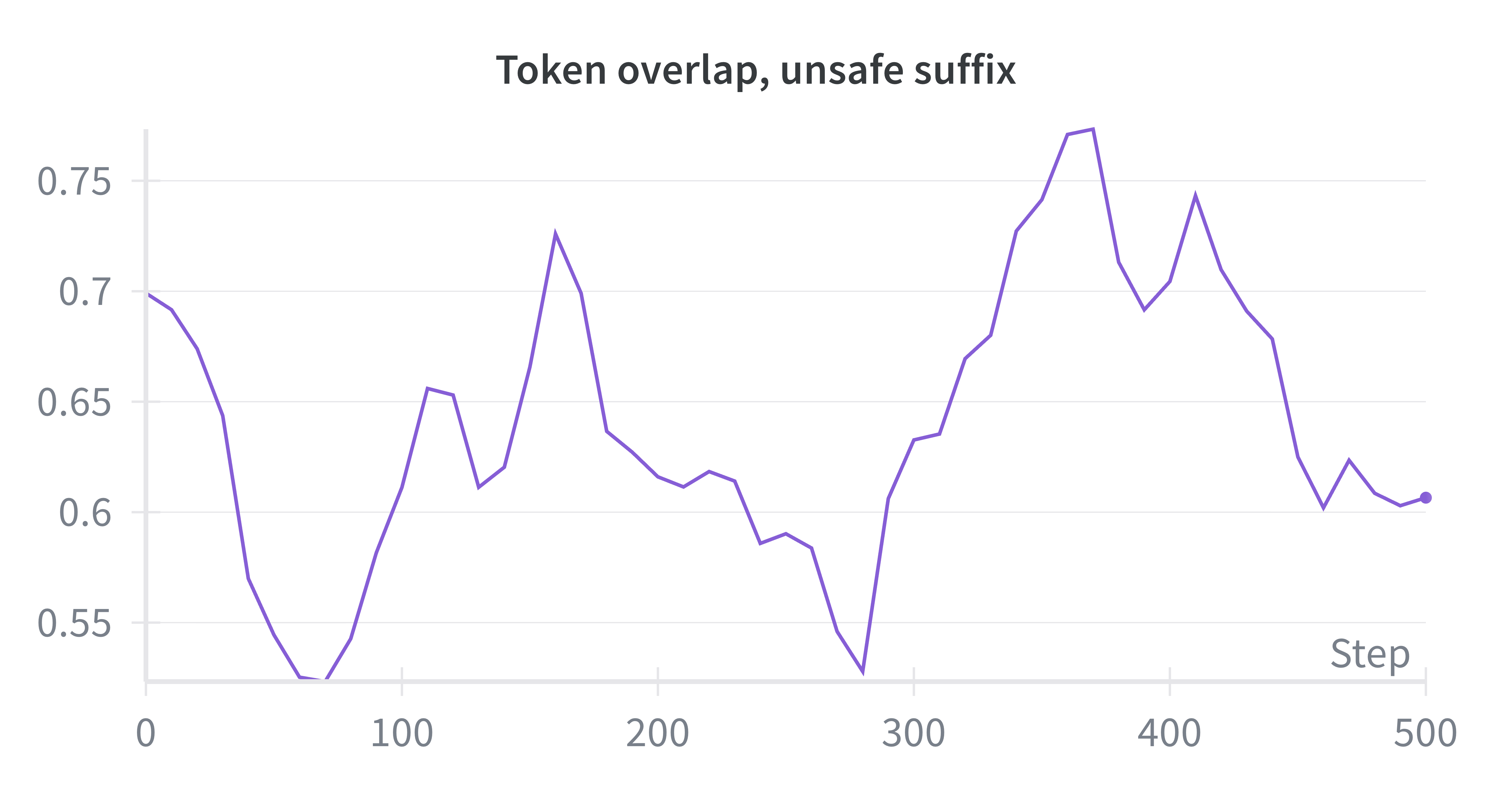
Процесс улучшения качества и безопасности генерируемого текста осуществляется посредством переписывания суффикса — последних сгенерированных токенов. В рамках данной методики, модель самостоятельно оценивает качество сгенерированного суффикса и, основываясь на этой внутренней оценке, производит его переписывание. Это позволяет итеративно улучшать выходные данные, фокусируясь на наиболее недавней части сгенерированного текста и повышая его соответствие заданным критериям качества и безопасности.
В основе метода Self-Improving Pretraining лежит итеративное улучшение генерируемого текста. Эксперименты показали, что данный подход позволяет достичь до 86.3% случаев победы в оценке качества генерации по сравнению со стандартным предварительным обучением. При этом наблюдается относительное улучшение фактической точности на 36.2% и повышение безопасности генерируемого контента на 18.5%. Данные показатели демонстрируют существенное превосходство итеративной стратегии доработки над традиционными методами предварительного обучения языковых моделей.
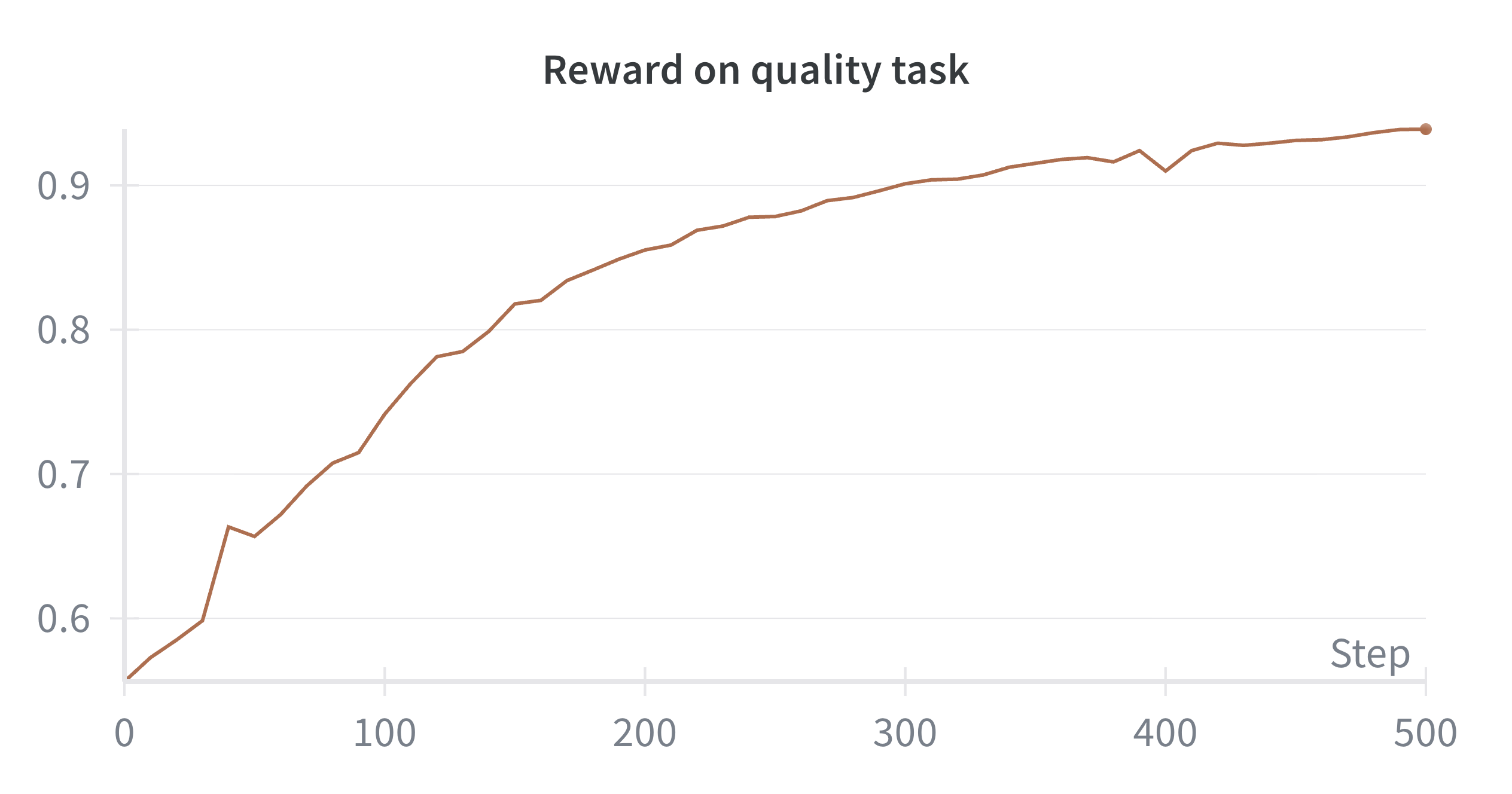
Оценка и валидация процесса совершенствования
В процессе оценки качества перефразировок используется постобученная модель, функционирующая в качестве автоматического судьи. Эта модель оценивает сгенерированные последовательности, применяя метрики, направленные на проверку фактической точности (Factuality) и безопасности (Safety). Оценка фактической точности определяет, соответствуют ли утверждения, содержащиеся в сгенерированном тексте, известным фактам и источникам. Оценка безопасности направлена на выявление и предотвращение генерации потенциально вредоносного, оскорбительного или предвзятого контента. Результаты этих оценок используются для количественной оценки качества перефразировки и дальнейшей оптимизации процесса.
Для оценки переписанных суффиксов и обеспечения соответствия желаемым характеристикам используются модели, такие как GPT-OSS-120B и Llama3-8B-Instruct. Эти модели применяются в качестве судей для анализа генерируемых последовательностей, оценивая их по таким параметрам, как фактическая точность и безопасность. Выбор данных моделей обусловлен их способностью к эффективной оценке качества и соответствия генерируемого текста заданным критериям, что позволяет автоматизировать процесс контроля и улучшения результатов перефразирования.
В процессе оптимизации этапа доработки моделей мы исследовали стратегии обучения, такие как Online DPO (Direct Preference Optimization) и Reward-Filtered NLL (Negative Log-Likelihood). Применение данных методов позволило добиться значительного улучшения показателей качества генерации, увеличив долю «выигрышей» в оценках с 1.3% до 32.4%. Параллельно, уровень безопасности генерируемых текстов был повышен с базового показателя в 85.2% до 97.5% при обучении моделей «с нуля». Эти результаты демонстрируют эффективность предложенных подходов к повышению как качества, так и безопасности генерируемого контента.
К более надёжным и безопасным языковым моделям
Исследование продемонстрировало значительное повышение безопасности языковых моделей благодаря применению тщательно отфильтрованного набора данных SlimPajama. В отличие от своего предшественника, RedPajama, содержавшего потенциально опасный контент, SlimPajama подвергся строгой обработке для удаления нежелательных материалов. Результаты показывают, что обучение моделей на этом очищенном наборе данных позволяет существенно снизить вероятность генерации токсичных, предвзятых или вводящих в заблуждение текстов. Данный подход открывает перспективные возможности для создания более надежных и безопасных систем искусственного интеллекта, способных эффективно взаимодействовать с людьми, не представляя при этом угрозы для общества.
В основе данного подхода лежит концепция использования префиксов и суффиксов — специальных фрагментов текста, добавляемых к входным данным модели. Префиксы задают контекст и направляют модель к желаемому типу ответа, а суффиксы, в свою очередь, позволяют уточнить и отшлифовать результат, минимизируя вероятность генерации нежелательного или небезопасного контента. Эффективность этого метода заключается в способности модели не просто «угадывать» наиболее вероятный ответ, а активно учитывать предоставленный контекст и целенаправленно формировать выходные данные, соответствующие заданным параметрам. Благодаря этому, модель приобретает способность к более тонкому и осознанному взаимодействию, что существенно повышает её надёжность и предсказуемость.
Разработка современных языковых моделей всё чаще фокусируется не только на увеличении их размера и вычислительной мощности, но и на обеспечении их надёжности и соответствия этическим нормам общества. Предложенный подход демонстрирует возможность создания моделей, которые не просто генерируют текст, но и делают это безопасно и предсказуемо. Вместо слепого увеличения параметров, данная методика направлена на фундаментальное улучшение качества обучения, позволяя моделям лучше понимать контекст и избегать генерации потенциально вредоносного или предвзятого контента. Это открывает путь к созданию искусственного интеллекта, который не только обладает впечатляющими способностями к обработке языка, но и способствует формированию более безопасного и ответственного цифрового пространства.
В исследовании, посвященном самообучающемуся предварительному обучению, проявляется глубокая истина: системы не создаются, а скорее взращиваются. Авторы предлагают метод, в котором уже обученная модель используется для контроля процесса предварительного обучения, что напоминает заботливого садовника, направляющего рост молодого растения. Это подчеркивает важность итеративного подхода, где каждая новая версия модели формируется под влиянием предыдущей. Как заметил Карл Фридрих Гаусс: «Я не знаю, как я выгляжу в глазах других, но я могу сказать, что я никогда не пытался упростить свои принципы или приспособить их к мнению других». Подобно тому, как Гаусс оставался верен своим принципам, эта работа подчеркивает, что улучшение безопасности и фактической точности языковых моделей требует последовательного и вдумчивого подхода, а не слепого следования трендам.
Что дальше?
Предложенный подход, использующий уже обученную модель для курирования процесса предварительного обучения, обнажает неизбежную истину: системы не строятся, они взращиваются. Каждый этап “улучшения” — это лишь небольшое изменение в экосистеме, и предсказать все последствия, особенно в долгосрочной перспективе, невозможно. Попытки “самосовершенствования” — это, по сути, самопророчества, и каждое развертывание — маленький апокалипсис, проявляющийся в новых, неожиданных формах.
Особую тревогу вызывает вопрос о критериях “истинности” и “безопасности”, используемых в процессе обучения. Кто решает, что есть “факт” или “безопасность”? Перекладывание ответственности на другую модель лишь усугубляет проблему, создавая замкнутый круг предвзятостей и неявно заложенных ограничений. Разработка более надежных и прозрачных механизмов оценки — задача, которая выходит далеко за рамки простого улучшения метрик.
И, конечно, документация. Кто пишет пророчества после их исполнения? Ведь каждый “улучшенный” шаг — это лишь небольшое отклонение от предсказанного сценария, и попытка зафиксировать все возможные варианты заранее — бессмысленна. Будущие исследования, вероятно, будут сосредоточены не на создании идеальных моделей, а на разработке систем, способных адаптироваться к неизбежным ошибкам и непредсказуемым последствиям.
Оригинал статьи: https://arxiv.org/pdf/2601.21343.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
2026-01-30 19:16