Автор: Денис Аветисян
Исследователи предлагают инновационный подход к динамическому объединению токенов в концепты, позволяющий оптимизировать вычислительные ресурсы и повысить эффективность работы моделей.

ConceptMoE — адаптивное сжатие токенов в концепты для неявного распределения вычислительных ресурсов.
Несмотря на впечатляющие возможности современных больших языковых моделей, распределение вычислительных ресурсов по всем токенам последовательности часто неэффективно, игнорируя различия в их сложности. В статье ‘ConceptMoE: Adaptive Token-to-Concept Compression for Implicit Compute Allocation’ представлен новый подход ConceptMoE, динамически объединяющий семантически близкие токены в концепты для неявного распределения вычислительных затрат. Этот метод позволяет добиться повышения производительности на 0.6-5.5 пункта в различных задачах, включая языковое моделирование и мультимодальный анализ, при одновременном снижении вычислительных затрат до R^2\times для внимания и R\times для кэша KV. Возможно ли дальнейшее масштабирование ConceptMoE для ещё более эффективной обработки длинных последовательностей и сложных задач?
Преодолевая Границы: Проблема Масштабируемости Трансформеров
Современные большие языковые модели, основанные на архитектуре Transformer, сталкиваются с существенными ограничениями при обработке чрезвычайно длинных последовательностей текста. Проблема заключается в том, что вычислительные затраты растут пропорционально квадрату длины последовательности — это явление, известное как квадратичная сложность. O(n^2), где n — длина последовательности, означает, что удвоение длины текста приводит к учетверенному увеличению требуемых вычислительных ресурсов и памяти. Такая зависимость быстро становится непосильной для существующих аппаратных средств, ограничивая возможность эффективной обработки больших документов, длинных диалогов или сложных задач, требующих анализа обширного контекста. В результате, несмотря на впечатляющие успехи, возможность масштабирования Transformer-моделей для работы с действительно длинными последовательностями остается серьезным препятствием для дальнейшего развития искусственного интеллекта.
Увеличение длины обрабатываемой последовательности в современных языковых моделях, основанных на архитектуре Transformer, требует экспоненциального роста числа параметров и объёма вычислительных ресурсов. Это связано с тем, что внимание (attention mechanism), ключевой компонент Transformer, имеет квадратичную сложность относительно длины последовательности O(n^2). Таким образом, удвоение длины последовательности приводит к учетверению требуемых параметров и вычислительных затрат. Этот процесс быстро становится неустойчивым, поскольку для обработки действительно длинных текстов требуются огромные вычислительные мощности и объёмы памяти, недоступные большинству исследователей и организаций. В результате, масштабирование моделей для работы с длинными контекстами сталкивается с серьёзными практическими ограничениями, препятствующими дальнейшему прогрессу в области обработки естественного языка.
Ограничения в вычислительных ресурсах, возникающие при обработке длинных последовательностей, существенно затрудняют решение сложных задач, требующих анализа развернутых контекстов. Модели, сталкиваясь с необходимостью обработки больших объемов информации, испытывают трудности в установлении долгосрочных зависимостей и логических связей между элементами текста. Это приводит к снижению точности и эффективности в задачах, таких как суммирование длинных документов, ответы на вопросы, требующие глубокого понимания контекста, и сложные рассуждения, основанные на большом объеме данных. По сути, способность модели к осмысленному анализу и эффективному использованию информации, содержащейся в расширенном контексте, напрямую зависит от ее вычислительной мощности и способности справляться с экспоненциально растущими требованиями к ресурсам.
ConceptMoE: Динамическое Объединение для Эффективной Обработки Длинного Контекста
ConceptMoE — это фреймворк, предназначенный для динамического объединения семантически близких токенов в “концепты”. Этот подход позволяет сократить эффективную длину последовательности Sequence Length без потери информации. Вместо обработки каждого токена по отдельности, ConceptMoE группирует связанные токены, представляя их как единую концептуальную единицу. Это уменьшает вычислительную сложность и требования к памяти, особенно при работе с длинными последовательностями текста или другими данными, сохраняя при этом ключевые семантические связи.
Адаптивная группировка токенов является ключевым элементом данной методики. Она основана на вычислении косинусной близости \cos(\theta) между векторами, представляющими отдельные токены. Токены, демонстрирующие высокую косинусную близость, объединяются в семантически связанные концепты. Этот процесс позволяет динамически формировать группы токенов, отражающие их смысловую связь, и, таким образом, эффективно сокращать фактическую длину последовательности без потери значимой информации. Пороговое значение косинусной близости определяет, какие токены будут объединены в один концепт, обеспечивая баланс между степенью сжатия и сохранением семантической точности.
Процесс динамического объединения токенов в семантические концепции осуществляется посредством двух специализированных модулей: модуля кодирования (Chunk Module) и модуля декодирования (Dechunk Module). Модуль кодирования отвечает за выявление семантической близости между токенами и формирование на ее основе концептуальных представлений, что позволяет сократить эффективную длину последовательности. Модуль декодирования выполняет обратную операцию, восстанавливая исходную последовательность токенов из концептуальных представлений. Такая архитектура обеспечивает эффективное кодирование и декодирование информации, необходимой для обработки длинных контекстов, сохраняя при этом семантическую целостность исходного текста.

Подтверждение Эффективности и Архитектурные Детали
Архитектура ConceptMoE является расширением MoE (Mixture of Experts) и основана на интеллектуальном объединении токенов. Этот подход позволяет значительно снизить вычислительную сложность, измеряемую в FLOPs (операциях с плавающей точкой за секунду), за счет уменьшения количества обрабатываемых токенов. В результате, ConceptMoE позволяет обрабатывать последовательности большей длины, не увеличивая при этом требуемые вычислительные ресурсы. Объединение токенов происходит динамически, основываясь на семантической близости, что позволяет сохранять информативность входных данных при уменьшении их объема.
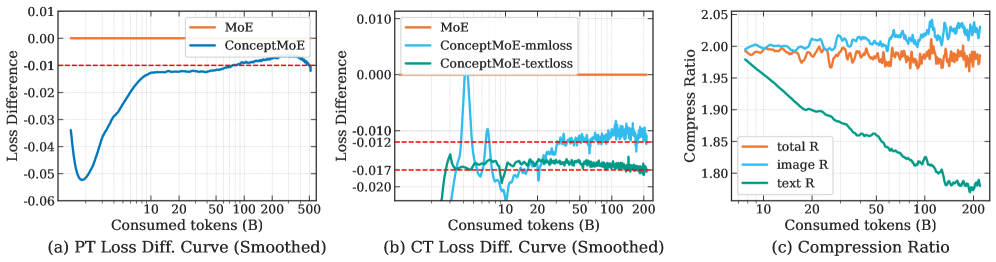
Использование векторных представлений токенов (Token Embedding) и последующего разбиения на чанки позволяет добиться более компактного представления входных данных. Этот подход предполагает преобразование каждого токена в многомерный вектор, а затем группировку этих векторов в чанки для последующей обработки. В результате применения данной методики на этапе предварительного обучения языковых моделей было достигнуто улучшение показателя на 6.4 пункта. Это свидетельствует о повышении эффективности использования вычислительных ресурсов и улучшении качества получаемых языковых представлений.
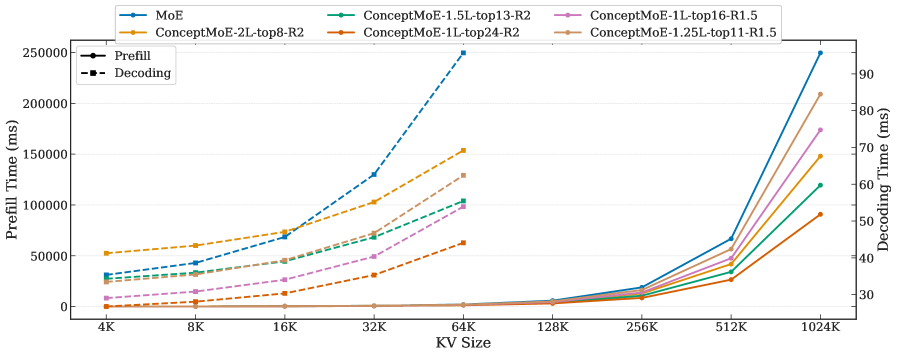
В ConceptMoE используется дополнительная функция потерь (Auxiliary Loss), предназначенная для уточнения процесса разбиения входной последовательности на чанки. Это позволяет повысить качество представления концепций и добиться снижения вычислительной сложности вычислений внимания до R^2 и уменьшения объема KV-кэша до R, где R представляет собой коэффициент сжатия. Уточнение процесса чанкинга посредством данной функции потерь способствует более эффективному использованию ресурсов и ускорению обработки данных, особенно при работе с длинными последовательностями.
За Пределами Эффективности: Обеспечение Более Надежного Рассуждения
Разработка ConceptMoE значительно расширяет возможности обработки длинных контекстов, позволяя моделям сохранять связность и точность при работе с протяженными последовательностями данных. Исследования показывают, что применение данной архитектуры приводит к улучшению результатов на задачах, связанных с обработкой визуальной и языковой информации в длинном контексте, на целых 2.3 пункта. Это достигается за счет более эффективного представления и использования информации, что позволяет модели лучше понимать взаимосвязи и зависимости в длинных последовательностях, избегая потери контекста и обеспечивая более осмысленные и точные результаты. Такая возможность открывает новые перспективы для решения сложных задач, требующих анализа больших объемов данных и поддержания долгосрочной памяти.
Использование концептуальных представлений значительно повышает эффективность совместного декодирования. Вместо обработки последовательности токенов как единого потока, модель разбивает информацию на более абстрактные, семантически значимые концепты. Это позволяет ей не просто сопоставлять слова, но и понимать взаимосвязи между ними на более глубоком уровне. В результате, генерируемые тексты становятся более нюансированными, содержат более точные детали и демонстрируют более глубокое понимание темы. Такой подход особенно важен при решении сложных задач, где требуется не просто пересказ информации, а её осмысление и интерпретация, что открывает новые возможности для создания интеллектуальных систем и инструментов.
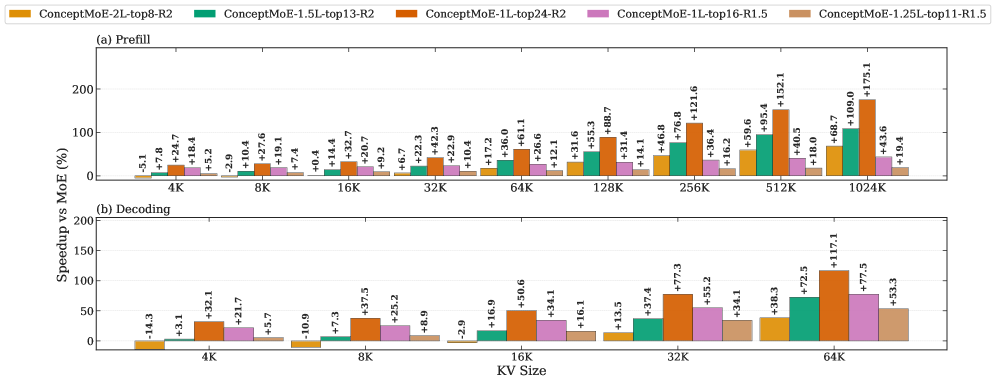
Предложенная архитектура демонстрирует значительное ускорение процесса логического вывода — до 175% на этапе предварительной обработки и 117% во время декодирования. Такое повышение производительности открывает новые горизонты в областях, требующих интенсивных вычислений, таких как научные исследования и решение сложных задач. Это позволяет обрабатывать значительно большие объемы данных и проводить более глубокий анализ, что особенно важно для моделирования сложных систем и выявления скрытых закономерностей. Ускорение логического вывода не только сокращает время, необходимое для получения результатов, но и делает возможным применение передовых моделей искусственного интеллекта в задачах, где скорость обработки имеет решающее значение.
Предложенная концепция ConceptMoE демонстрирует стремление к элегантности в проектировании систем обработки естественного языка. Подобно тому, как в хорошо спроектированной архитектуре каждая деталь служит общей цели, ConceptMoE объединяет токены в концепты, оптимизируя распределение вычислительных ресурсов. Этот подход, динамически адаптирующийся к структуре данных, позволяет избежать перегрузки отдельных компонентов системы и повышает её общую устойчивость. Как однажды заметил Г.Х. Харди: «Математика — это наука о том, что нельзя доказать». По аналогии, в сложных системах, подобных большим языковым моделям, невозможно предвидеть все возможные сценарии; однако, стремление к упрощению и ясности структуры позволяет минимизировать риски и повысить надежность системы, даже перед лицом неопределенности.
Что Дальше?
Представленная работа, как и любой сдвиг в парадигме, скорее открывает новые вопросы, чем дает окончательные ответы. Концептуальное сжатие токенов, предложенное ConceptMoE, безусловно, демонстрирует потенциал для более эффективного распределения вычислительных ресурсов. Однако, истинная сложность заключается не в самом алгоритме, а в его интеграции в существующую, весьма сложную инфраструктуру больших языковых моделей. Необходимо учитывать, что адаптация к «концептам» — процесс, требующий тщательной калибровки, и любое упрощение может привести к нежелательной потере информации, подобно перестройке квартала ради одной новой улицы.
Перспективы дальнейших исследований, очевидно, лежат в области динамической гранулярности этих самых «концептов». Как определить оптимальный размер концепта в зависимости от контекста, типа данных и даже стадии обучения модели? Очевидно, что статичные подходы будут неэффективны. Более того, необходимо исследовать возможности использования ConceptMoE не только для повышения эффективности, но и для улучшения способности моделей к обобщению, то есть, к построению более устойчивых и надежных представлений о мире.
В конечном итоге, успех подобных подходов будет зависеть не только от математической элегантности алгоритмов, но и от их способности адаптироваться к постоянно меняющейся природе языка и знаний. Хорошая система — живой организм, и ее развитие требует постоянного внимания к деталям и понимания взаимосвязей между различными компонентами. Простота и ясность структуры — залог ее долговечности.
Оригинал статьи: https://arxiv.org/pdf/2601.21420.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- БиоАгент: Проверка ИИ на прочность в мире геномики
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Командная работа агентов: обучение без обновления модели
- Квантовые Загадки и Финансовые Реалии
2026-01-30 22:43