Автор: Денис Аветисян
Новый подход к предварительному обучению позволяет создавать более точные и универсальные 3D-модели, используя огромные объемы разнородных данных.

В статье представлена методика MetricAnything, масштабируемая платформа для предварительного обучения оценке глубины на основе данных из различных 3D-источников.
Несмотря на успехи в области современных фундаментальных моделей, масштабирование парадигмы обучения для оценки метрической глубины остается сложной задачей из-за разнородного шума сенсоров и неоднозначности 3D-данных. В работе ‘MetricAnything: Scaling Metric Depth Pretraining with Noisy Heterogeneous Sources’ представлена платформа MetricAnything — масштабируемый фреймворк предварительного обучения, извлекающий метрическую глубину из гетерогенных 3D-источников без ручной разработки подсказок или специализированных архитектур. Ключевым элементом подхода является разреженная метрическая подсказка, обеспечивающая универсальный интерфейс, отделяющий пространственное рассуждение от особенностей сенсоров и камер. Может ли подобный подход к масштабированию данных открыть новые горизонты в области эффективного и надежного 3D-восприятия в реальном мире?
Предел мечтаний: О проблемах точного 3D-восприятия
Точное восприятие глубины является фундаментальным требованием для функционирования робототехнических систем и создания реалистичных приложений дополненной и виртуальной реальности. Однако, традиционные методы определения глубины, такие как стереозрение или структурированное освещение, часто оказываются неэффективными в условиях реального мира, характеризующегося шумами, неполнотой данных и сложной геометрией объектов. Например, отражения, полупрозрачные поверхности и недостаток текстуры значительно снижают точность результатов. Это связано с тем, что алгоритмы, разработанные для идеальных условий, не способны адекватно обрабатывать искажения и неоднозначности, возникающие при взаимодействии с реальными объектами и окружением. В результате, роботы могут сталкиваться с препятствиями, а пользователи AR/VR испытывать дискомфорт из-за неточной визуализации.
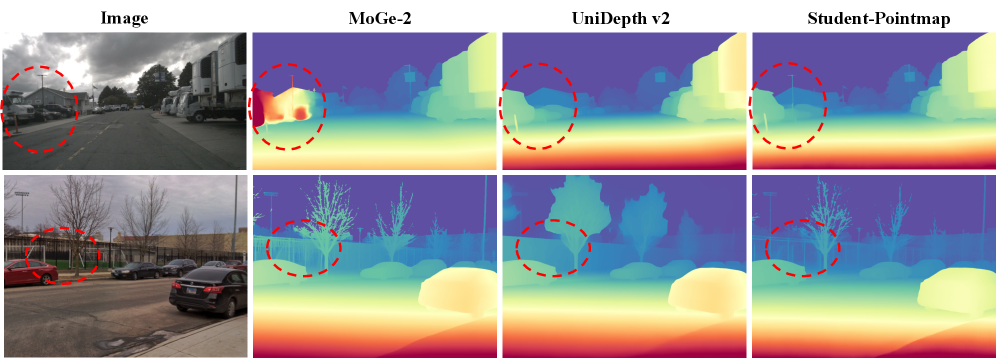
Существующие методы оценки глубины, как правило, полагаются на ограниченный набор данных или испытывают трудности с обобщением в различных условиях. Традиционные алгоритмы часто хорошо работают в контролируемой лабораторной среде, но их точность значительно снижается при обработке реальных изображений, содержащих шум, изменения освещения и сложные текстуры. Например, системы, обученные на синтетических данных, могут демонстрировать значительные ошибки при применении к изображениям, полученным в условиях низкой освещенности или при наличии помех. Более того, многие подходы испытывают проблемы при переходе от одной среды к другой — алгоритм, эффективно работающий в городской среде, может оказаться неэффективным в лесу или в помещении. Эта ограниченная обобщающая способность препятствует широкому внедрению технологий, требующих точного трехмерного восприятия, таких как автономные роботы и системы дополненной реальности.
Для создания действительно надежных и масштабируемых систем трехмерного восприятия необходимо отойти от использования однородных источников данных. Современные исследования показывают, что комбинирование информации, полученной из различных сенсоров — таких как камеры, лидары и радары — позволяет значительно повысить точность и устойчивость алгоритмов. Такой подход, известный как мультисенсорное слияние, позволяет компенсировать недостатки каждого отдельного сенсора и создавать более полную и детализированную картину окружающего мира. Разработка новых методов обучения, способных эффективно обрабатывать и интегрировать гетерогенные данные, является ключевой задачей для развития робототехники, дополненной и виртуальной реальности, а также для создания автономных транспортных средств, способных безопасно функционировать в сложных и динамичных условиях.
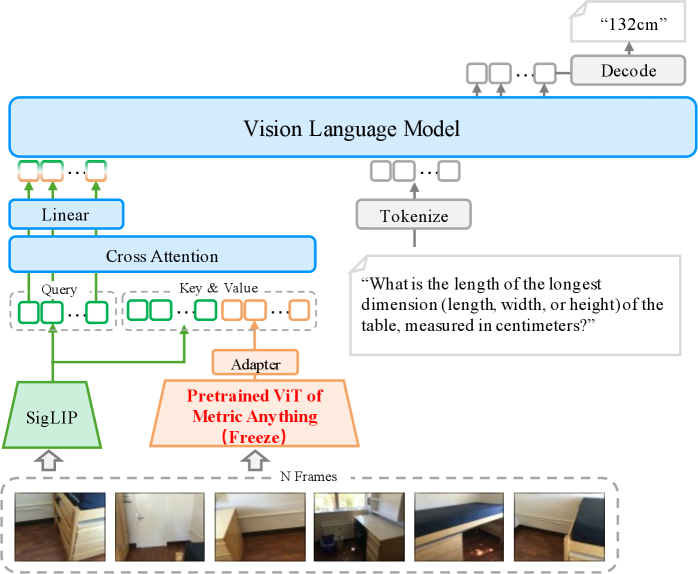
Metric Anything: Рациональный подход к предварительному обучению
Предварительное обучение в рамках ‘Metric Anything’ позволяет получить устойчивое представление о глубине на основе разнообразных и зашумленных 3D-данных. Использование большого объема данных, включающего различные сенсорные модальности и условия съемки, позволяет модели обобщить знания и снизить зависимость от специфических особенностей отдельных датчиков или сцен. Процесс предварительного обучения направлен на извлечение общих закономерностей в структуре 3D-пространства, что обеспечивает высокую точность и надежность последующей оценки глубины даже в сложных и непредсказуемых условиях. Это позволяет модели эффективно работать с данными, полученными из различных источников, включая лидары, камеры и другие 3D-сенсоры.
В основе архитектуры ‘Metric Anything’ лежат Vision Transformers (ViT) и Depth Prediction Transformer (DPT), обеспечивающие эффективную и точную оценку глубины. ViT обрабатывает входные изображения, извлекая признаки для последующего анализа. DPT, как трансформерная модель, использует механизм самовнимания для установления связей между признаками и прогнозирования карты глубины. Использование трансформеров позволяет модели эффективно обрабатывать глобальный контекст изображения и учитывать взаимосвязи между различными его частями, что повышает точность оценки глубины по сравнению с традиционными сверточными архитектурами. DPT использует кросс-внимание для интеграции визуальных признаков, полученных от ViT, с информацией о глубине, что позволяет эффективно решать задачу предсказания глубины.
Ключевым нововведением в рамках данной работы является использование “разреженных метрических подсказок” (Sparse Metric Prompts) для отделения понимания пространственной информации от систематических ошибок, вносимых различными сенсорами, в процессе предварительного обучения. Эти подсказки представляют собой набор разреженных точек в пространстве, которые служат опорными точками для оценки глубины. Использование разреженных подсказок позволяет модели научиться обобщать пространственные отношения, не привязываясь к конкретным особенностям данных, полученных от определенного типа сенсора, таким образом повышая устойчивость и точность оценки глубины на разнообразных входных данных.
В основе архитектуры ‘Metric Anything’ лежит использование механизмов перекрестного внимания (cross-attention) для эффективной интеграции информации из различных модальностей данных. Эти механизмы позволяют модели динамически взвешивать вклад каждого источника данных — например, изображения, лидара или радара — при формировании представления глубины. Перекрестное внимание применяется для вычисления зависимостей между признаками, извлеченными из разных модальностей, что позволяет модели учитывать взаимосвязи и компенсировать недостатки отдельных сенсоров. Это приводит к более точной и робастной оценке глубины, особенно в сложных условиях и при наличии шума в данных.

Надежность и обобщающая способность: Подтвержденные результаты
В рамках стандартных бенчмарков оценки глубины, система ‘Metric Anything’ демонстрирует превосходные результаты благодаря надежной процедуре предварительного обучения. На датасете KITTI, при использовании 100% обучающих данных, достигнута абсолютная относительная ошибка (AbsRel) в размере 2.34%. Данный показатель свидетельствует о высокой точности и стабильности системы в задачах оценки глубины, что обусловлено эффективной обработкой и обобщением данных на этапе предварительного обучения.
В рамках данной архитектуры продемонстрирована высокая способность к обучению без учителя (zero-shot learning), что позволяет эффективно обобщать полученные знания на новые, ранее не встречавшиеся окружения и типы данных. Это достигается за счет обучения на разнообразном наборе данных и разработки алгоритма, который не требует дополнительной адаптации или тонкой настройки для работы в незнакомых условиях. Эффективность обобщения была подтверждена в экспериментах с различными наборами данных и сценариями, демонстрируя устойчивость к изменениям в освещении, геометрии сцены и характеристикам датчиков. Данная способность позволяет применять разработанную систему в широком спектре приложений, не требуя значительных затрат на сбор и разметку данных для каждого конкретного случая.
Обучение метрическому представлению глубины в рамках ‘Metric Anything’ позволяет снизить зависимость от предвзятости и шумов в обучающих данных. В отличие от традиционных методов, которые могут переобучаться на специфические характеристики набора данных, метрический подход фокусируется на извлечении инвариантных признаков глубины. Это приводит к повышению точности оценки границ объектов, что количественно оценивается улучшением показателя Boundary F1 Score. Повышение Boundary F1 Score указывает на более четкое определение границ и сохранение геометрической детализации в результирующих картах глубины, что особенно важно для задач, требующих высокой точности, таких как робототехника и автономное вождение.
Предварительное обучение модели значительно повышает четкость границ и общее качество карт глубины, что позволяет достичь передовых результатов в различных задачах последующей обработки. В частности, отмечается существенное улучшение в задачах повышения разрешения карт глубины (depth super-resolution), восстановления пропущенных участков (completion), а также в задачах многовидовой 3D-реконструкции. Данные улучшения обусловлены более точным представлением информации о глубине и снижением влияния шумов и искажений, что критически важно для достижения высокой точности и реалистичности результатов в этих задачах.

Расширяя горизонты: Приложения и будущие направления
Разработанная система “Metric Anything” демонстрирует значительный потенциал в улучшении производительности моделей Vision-Language-Action (VLA) при решении интерактивных задач. Интеграция осуществляется бесшовно, позволяя VLA-моделям не только распознавать объекты и понимать лингвистические команды, но и точно измерять расстояния и размеры в визуальном окружении. Это открывает возможности для более точного выполнения задач, таких как навигация роботов, манипулирование объектами и интерактивное взаимодействие с пользователем. Благодаря способности системы предоставлять метрические данные, VLA-модели способны более эффективно планировать действия и адаптироваться к изменяющимся условиям, значительно повышая надежность и эффективность роботизированных систем и виртуальных ассистентов.
Архитектура разработанной системы “Metric Anything” отличается высокой эффективностью, что позволяет успешно развертывать её на платформах с ограниченными вычислительными ресурсами. Ключевым фактором является применение метода тонкой настройки на основе Low-Rank Adaptation (LoRA), который значительно сокращает количество обучаемых параметров без существенной потери в производительности. Такой подход позволяет адаптировать модель к конкретным задачам, используя минимальный объем памяти и вычислительной мощности, открывая возможности для её применения на мобильных устройствах, встраиваемых системах и других платформах, где традиционные методы глубокого обучения могут быть непрактичными. Это делает “Metric Anything” особенно ценным инструментом для широкого спектра приложений, требующих обработки визуальной информации в условиях ограниченных ресурсов.
Для расширения возможностей применения и доступности модели ‘Metric Anything’ применяются методы дистилляции знаний. Этот процесс позволяет существенно уменьшить размер модели без значительной потери точности, перенося знания из более крупной, сложной сети в компактную, эффективную. Уменьшение вычислительных требований открывает путь к развертыванию модели на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встраиваемые системы, что значительно расширяет спектр потенциальных приложений — от роботизированной навигации в реальном времени до анализа изображений непосредственно на периферийных устройствах. Благодаря дистилляции, ‘Metric Anything’ становится доступнее для более широкого круга исследователей и разработчиков, а также для пользователей, не имеющих доступа к мощным вычислительным ресурсам.
Перспективные исследования направлены на адаптацию системы ‘Metric Anything’ к более сложным и реалистичным условиям эксплуатации. В частности, планируется расширить функциональность для обработки динамических сцен, где объекты перемещаются и меняют свою форму во времени. Это потребует разработки новых алгоритмов, способных эффективно отслеживать и измерять объекты в условиях постоянного движения и деформации. Кроме того, ведется работа над повышением устойчивости системы к сложным факторам окружающей среды, таким как переменное освещение, атмосферные помехи и частичная видимость объектов. Успешная реализация этих задач позволит значительно расширить сферу применения ‘Metric Anything’, сделав ее незаменимым инструментом в робототехнике, автономном транспорте и других областях, требующих точного восприятия окружающего мира.
Данное исследование, с упором на масштабирование данных для оценки глубины, закономерно напоминает о вечном стремлении к «большим данным». Авторы, по сути, пытаются повторить успех, достигнутый в обработке естественного языка и 2D-видении, но в трёхмерном пространстве. И это, конечно, не удивительно. Как говорил Эндрю Ын: «Самый лучший способ добиться прогресса — это начать что-то делать». Звучит банально, но в контексте постоянного поиска «революционных» алгоритмов и новых архитектур, это особенно актуально. В конечном итоге, сложная система оценки глубины, какой бы элегантной она ни казалась на бумаге, когда-то была простым bash-скриптом, а её производительность напрямую зависела от объёма и качества данных. И да, сейчас это назовут AI и получат инвестиции.
Что дальше?
Представленная работа демонстрирует, что масштабирование данных для оценки глубины действительно приносит плоды. Нельзя не отметить, что это лишь повторение пройденного материала в области обработки естественного языка и двумерного зрения, просто теперь с трехмерными данными. Однако, радость от полученных результатов будет недолгой. Всё равно рано или поздно «продакшен» найдёт способ сломать даже самую элегантную модель, особенно когда речь пойдёт о реальных, шумных данных. Если система стабильно выдаёт неверную глубину, значит, по крайней мере, она последовательна в своей неточности.
Очевидно, что следующей ступенью станет поиск способов обхода ограничений, связанных с разнородностью данных. «Разреженное промптирование» — это, конечно, хорошо, но это лишь временное решение. В конечном итоге, потребуется разработка более устойчивых методов обучения, способных справляться с данными неизвестного происхождения и качества. Иначе говоря, мы снова будем писать код, чтобы оставлять комментарии для будущих археологов, пытающихся понять, что мы имели в виду.
Идея «foundation models» для 3D-восприятия, безусловно, привлекательна. Но не стоит забывать, что «cloud-native» — это просто то же самое, только дороже. Настоящий прогресс потребует не только масштабирования данных, но и разработки принципиально новых алгоритмов, способных к обобщению и адаптации. Иначе, в конечном итоге, мы просто построим более сложные системы, которые будут так же ненадежны, как и предыдущие.
Оригинал статьи: https://arxiv.org/pdf/2601.22054.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Моделирование биомолекул: новый импульс от нейросетей
- Квантовая механика: скрытый детерминизм?
- Поймать Мгновение: Эволюция Детекторов Времени
2026-01-31 18:51