Автор: Денис Аветисян
Исследователи предлагают инновационный метод оптимизации языковых моделей, основанный на состязательном обучении в латентном пространстве, для улучшения соответствия заданным предпочтениям.
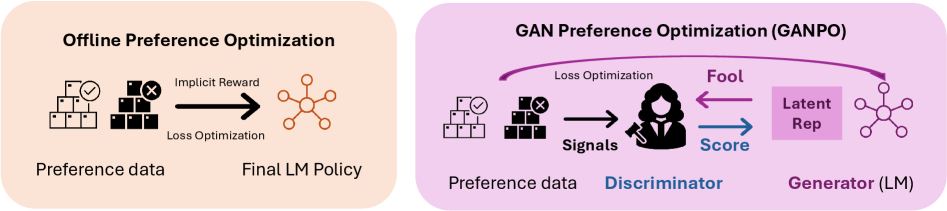
В статье представлен GANPO — метод оптимизации предпочтений, использующий структурную регуляризацию в латентном пространстве для обучения языковых моделей в режиме offline.
Оптимизация языковых моделей на основе предпочтений пользователей сталкивается с трудностями, поскольку сходство токенов не всегда отражает семантическую близость. В работе, озаглавленной ‘Latent Adversarial Regularization for Offline Preference Optimization’, предложен новый подход, использующий регуляризацию в латентном пространстве для улучшения процесса выравнивания. Авторы представляют GANPO — метод, применяющий состязательное обучение для минимизации расхождения между внутренними представлениями модели и эталонной, тем самым повышая устойчивость и производительность. Сможет ли предложенный подход стать основой для разработки более надежных и эффективных систем обучения языковых моделей на основе обратной связи от пользователей?
Суть Выравнивания: Преодолевая Ограничения Обучения на Основе Предпочтений
Несмотря на впечатляющие масштабы современных языковых моделей, достижение последовательного соответствия человеческим предпочтениям остается сложной задачей. Эти модели, обученные на огромных объемах данных, нередко генерируют результаты, которые, хотя и грамматически корректны, оказываются нежелательными или неуместными с точки зрения человеческих ценностей и ожиданий. Проблема заключается не в отсутствии знаний, а в трудностях точного улавливания нюансов человеческих предпочтений и их надежного воспроизведения в процессе генерации текста. Это проявляется в склонности моделей к созданию предвзятых, токсичных или попросту бессмысленных ответов, что подчеркивает необходимость разработки более эффективных методов выравнивания, способных гарантировать, что генерируемый контент соответствует ожиданиям пользователей и этическим нормам.
Традиционные методы оптимизации предпочтений, такие как Direct Preference Optimization (DPO), зачастую полагаются на построение сложных моделей вознаграждения, что создает уязвимость к манипуляциям и эксплуатации. Суть проблемы заключается в том, что модель вознаграждения, предназначенная для оценки желательности различных ответов, может быть обманута, если в обучающих данных присутствуют неверные или предвзятые примеры. Например, специально сконструированный ввод, который кажется модели вознаграждения предпочтительным, может привести к генерации нежелательного или даже вредоносного контента. Это особенно актуально в условиях, когда обучающие данные собираются из разнообразных и не всегда надежных источников. Таким образом, сложность и потенциальная уязвимость моделей вознаграждения ограничивают эффективность DPO и подобных подходов, подчеркивая необходимость разработки более устойчивых и надежных методов оптимизации предпочтений.
Исследования показывают, что существующие методы оптимизации предпочтений, несмотря на свою эффективность в определенных условиях, часто демонстрируют хрупкость и ограниченную способность к обобщению. Модели, обученные на конкретном наборе данных о предпочтениях, могут давать непредсказуемые результаты при столкновении с новыми, ранее не встречавшимися ситуациями. Эта проблема особенно актуальна в задачах, где предпочтения пользователей разнообразны и динамично меняются. Неспособность к адаптации к новым данным о предпочтениях подчёркивает необходимость разработки более устойчивых и гибких техник, способных эффективно работать в условиях неопределенности и обеспечивать стабильно высокое качество генерируемых ответов, независимо от входных данных. Разработка таких методов является ключевой задачей для создания действительно полезных и надежных языковых моделей.
![В отличие от DPO, чувствительного к шуму и полагающегося на жадный поиск, GANPO выступает в роли структурного регуляризатора, обеспечивая сохранение соответствия предпочтениям и соблюдение ограничений даже при генерации с высокой энтропией <span class="katex-eq" data-katex-display="false">T \in [0.0, 1.5]</span>.](https://arxiv.org/html/2601.22083v1/x4.png)
GANPO: Состязательная Регуляризация для Надежного Обучения на Основе Предпочтений
GANPO использует возможности генеративно-состязательных сетей (GAN) для введения регуляризационного члена, основанного на состязательном обучении, в процесс обучения предпочтениям. В основе подхода лежит состязание между генератором и дискриминатором: генератор стремится создавать латентные представления, а дискриминатор — отличать их от реальных. Включение этого состязательного процесса в функцию потерь заставляет модель обучаться более устойчивым и обобщающим латентным представлениям, что повышает качество обучения предпочтениям и улучшает способность модели различать предпочтительные и непредпочтительные ответы.
В основе GANPO лежит принцип состязательного обучения, где генератор стремится создавать латентные представления, неотличимые от предпочтительных, а дискриминатор — отличать их от нежелательных. Такое состязание заставляет модель изучать более устойчивые и обобщенные латентные представления, поскольку генератор вынужден учитывать все возможные вариации предпочтений, чтобы обмануть дискриминатор. В результате, модель становится менее чувствительной к незначительным изменениям во входных данных и способна лучше обобщать полученные знания на новые, ранее не встречавшиеся примеры, что повышает надежность и точность обучения предпочтениям.
Обучение с состязательным противодействием (adversarial training) в GANPO усиливает способность модели к различению предпочтительных и непредпочтительных ответов. Этот процесс заключается в одновременной оптимизации модели для генерации ответов и дискриминатора, оценивающего степень соответствия этих ответов человеческим предпочтениям. Повышая чувствительность модели к различиям между желаемыми и нежелательными результатами, GANPO способствует более точному выравниванию модели с человеческими намерениями и улучшает её способность предоставлять ответы, соответствующие ожиданиям пользователей. Такой подход позволяет модели более эффективно обобщать знания и избегать выдачи нежелательных или неудовлетворительных ответов.

Подтверждение Эффективности GANPO: Устойчивость и Обобщение на Практике
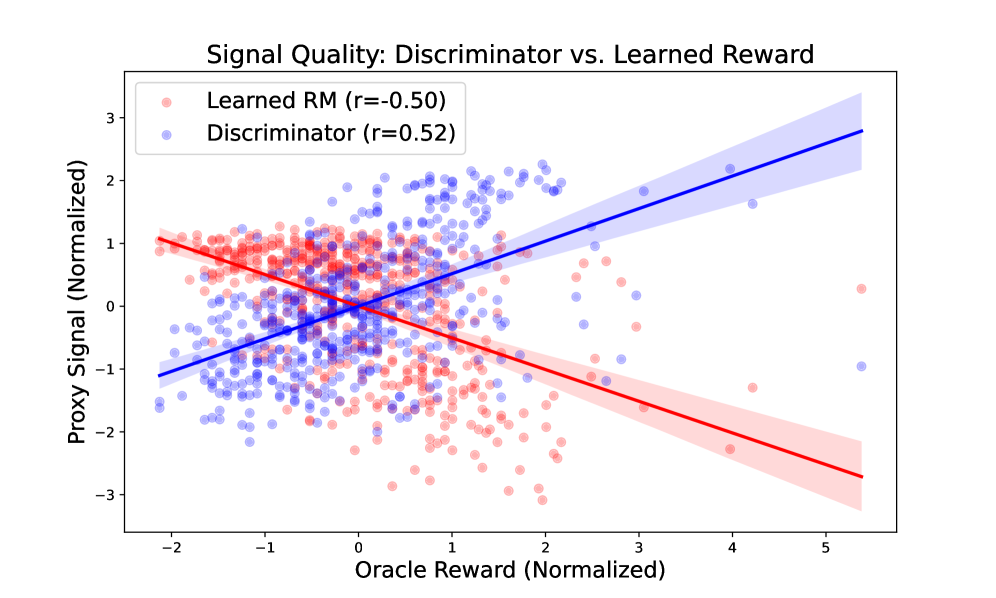
Эксперименты показали, что GANPO значительно повышает устойчивость к взлому системы вознаграждения (reward hacking), предотвращая эксплуатацию уязвимостей в сигнале предпочтений. В ходе тестирования, GANPO продемонстрировал способность эффективно избегать генерации ответов, которые искусственно максимизируют вознаграждение, не соответствуя при этом фактическим предпочтениям пользователя. Это достигается за счет архитектуры GANPO, которая обучает модель отличать желательные ответы от тех, которые эксплуатируют несовершенства в функции вознаграждения, что обеспечивает более надежное и предсказуемое поведение модели в различных сценариях.
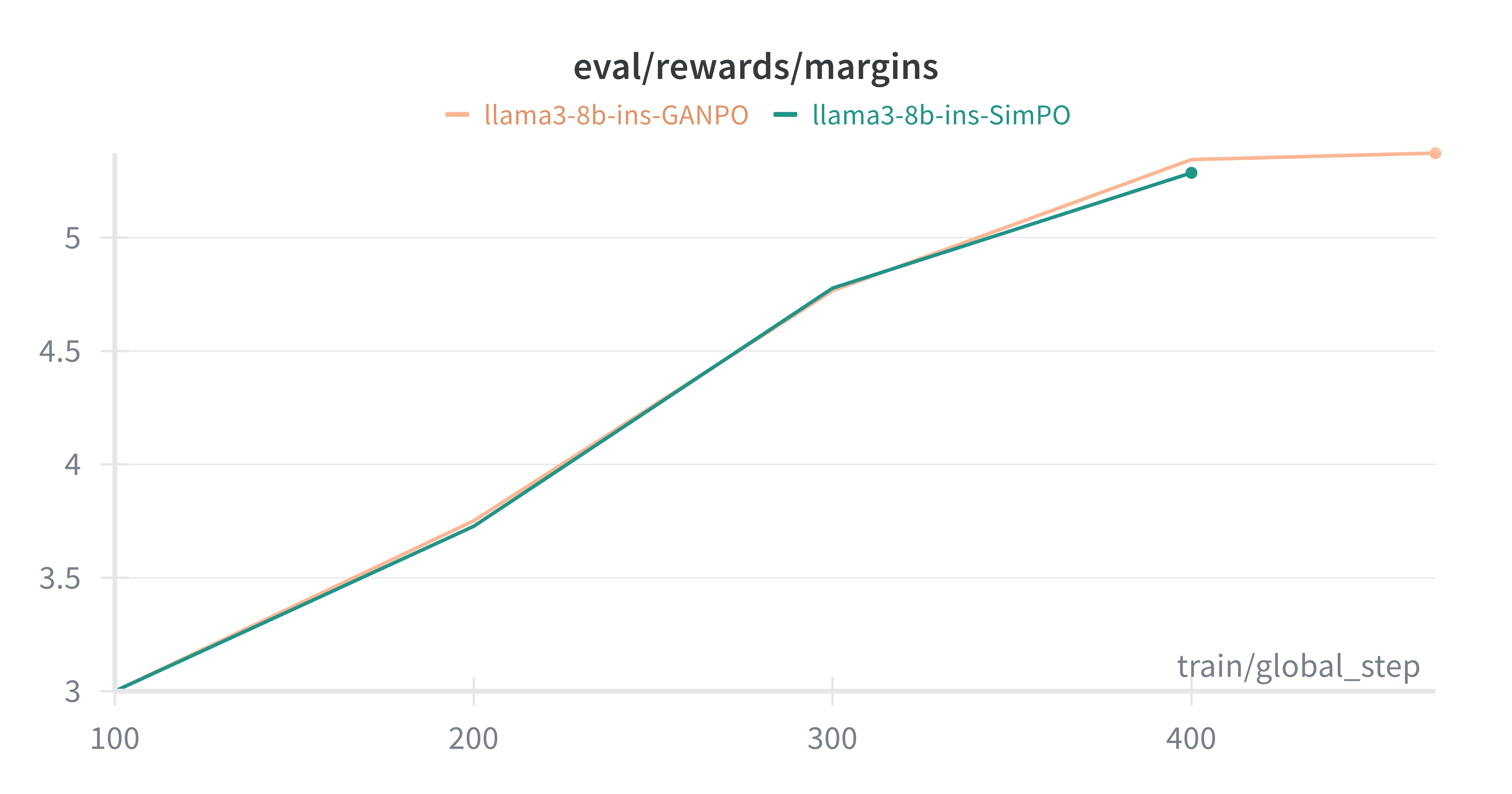
Эксперименты показали, что GANPO демонстрирует превосходящую обобщающую способность при работе с новыми данными о предпочтениях. В частности, при сравнении с базовым методом Direct Preference Optimization, GANPO обеспечивает прирост до 1.41% в метрике LC-Win Rate на модели Gemma2-2B-it. Данный результат подтверждает способность GANPO эффективно адаптироваться к ранее не встречавшимся данным о предпочтениях пользователей и генерировать более соответствующие ответы.
Внедрение структурной регуляризации в GANPO способствует улучшению качества извлеченных латентных представлений, что приводит к генерации более связных и согласованных ответов. Эксперименты на модели Llama-3-8B-Instruct продемонстрировали повышение показателя LC-Win Rate в диапазоне от 1.5% до 2.0% по сравнению с базовыми моделями. Структурная регуляризация обеспечивает более упорядоченное и информативное представление данных в латентном пространстве, что напрямую влияет на качество генерируемых текстов и их соответствие заданным предпочтениям.
За Пределами Сравнения с Ориентирами: Более Широкие Последствия GANPO
Оценки, проведенные с использованием AlpacaEval, продемонстрировали, что GANPO значительно повышает способность языковых моделей следовать инструкциям и генерировать ответы высокого качества. Этот подход позволяет моделям более точно интерпретировать запросы пользователя и предоставлять релевантную, связную и информативную информацию. Результаты показывают, что GANPO не просто улучшает общую производительность, но и способствует более надежному и предсказуемому поведению модели при обработке различных типов инструкций, что особенно важно для приложений, требующих высокой точности и последовательности в ответах.
Исследования подтвердили эффективность GANPO на различных языковых моделях, включая Gemma2-2B-it и Llama-3-8B-Instruct. Данный подход демонстрирует свою универсальность, успешно адаптируясь к архитектурным особенностям и предварительной подготовке этих моделей. В ходе экспериментов было установлено, что GANPO последовательно улучшает способность моделей следовать инструкциям и генерировать более качественные ответы, независимо от их базовой конструкции. Это указывает на то, что GANPO представляет собой ценный инструмент для повышения общей производительности и надежности языковых моделей в широком спектре приложений.
Исследования показали, что методика GANPO предоставляет эффективное решение для улучшения соответствия языковых моделей заданным инструкциям без значительных затрат вычислительных ресурсов. В частности, при обучении на модели Gemma2-2B-it, увеличение времени обучения составило менее 4%, что делает GANPO практичным инструментом для повышения качества генерируемых ответов. Важно отметить, что данный подход не только не снижает, но и улучшает точность соблюдения строгих требований к промптам, даже при использовании вероятностного декодирования, как подтверждается результатами тестирования на IFEval. Таким образом, GANPO представляет собой экономически выгодный и эффективный способ оптимизации языковых моделей для различных задач.
Исследование, представленное в данной работе, демонстрирует стремление к упрощению сложных процессов оптимизации языковых моделей. Авторы предлагают метод GANPO, фокусирующийся на регуляризации в латентном пространстве, что позволяет добиться более эффективного выравнивания и устойчивости моделей. Этот подход, избегающий трудоемкой оптимизации на уровне токенов, соответствует принципу плотности смысла — новому минимализму. Как однажды заметил Давид Гильберт: «Вся математика должна быть сведена к логике». Подобно этому, представленная работа стремится свести сложную задачу оптимизации предпочтений к более ясной и логичной структуре, избавляясь от избыточности и фокусируясь на сущности проблемы.
Что Дальше?
Представленная работа, хоть и демонстрирует потенциал использования состязательных сетей в латентном пространстве для оптимизации предпочтений, лишь слегка приоткрывает дверь в сложный мир выравнивания языковых моделей. Проблема не в тонкой настройке токенов, а в фундаментальном понимании того, что вообще означает «предпочтение» для машины. Оптимизация в латентном пространстве — это элегантный обход, но не решение. Поиск истинной структуры предпочтений, а не их суррогатов, остаётся нерешенной задачей.
Особое внимание следует уделить устойчивости к манипуляциям. Состязательные сети, по своей природе, подвержены атакам. Если «дискриминатор» легко обмануть, вся система теряет смысл. Необходимо разрабатывать методы, гарантирующие надежность и предсказуемость, а не полагаться на хрупкое равновесие в латентном пространстве. Код должен быть очевиден, как гравитация, а не как квантовая запутанность.
И, наконец, необходимо признать, что оптимизация предпочтений — это лишь часть более широкой проблемы. Задача состоит не в том, чтобы научить машину следовать инструкциям, а в том, чтобы научить её понимать смысл. Интуиция — лучший компилятор, и её нельзя заменить бесконечным количеством параметров. Попытки упростить эту задачу — тщеславие.
Оригинал статьи: https://arxiv.org/pdf/2601.22083.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Квантовая механика: скрытый детерминизм?
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Магнитные волны нового типа: к спиновому транспорту без потерь
2026-01-31 22:15