Автор: Денис Аветисян
Исследователи предлагают метод, позволяющий обучать крупные языковые модели с использованием низкоточной квантизации, существенно снижая потребление памяти без потери производительности.
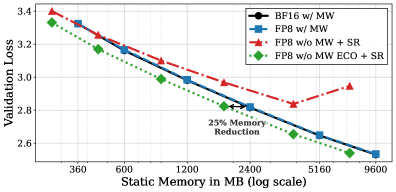
Представлен алгоритм Error Compensation Optimizer (ECO), исключающий необходимость использования полноточных мастер-весов при обучении.
Квантование значительно повысило эффективность обучения больших языковых моделей (LLM) с точки зрения вычислений и памяти, однако существующие подходы по-прежнему требуют хранения промежуточных результатов с высокой точностью. В данной работе, представленной под названием ‘ECO: Quantized Training without Full-Precision Master Weights’, предложен метод Error-Compensating Optimizer (ECO), устраняющий необходимость в использовании «главных весов» (master weights) за счет непосредственного применения обновлений к квантованным параметрам. ECO компенсирует ошибку квантования путем включения ее в импульс оптимизатора, создавая обратную связь без дополнительного увеличения потребления памяти, и демонстрирует сходимость к окрестности оптимума. Может ли подобный подход кардинально изменить баланс между потреблением памяти и производительностью при обучении и развертывании масштабных LLM?
Точность как узкое место: Эволюция требований к ресурсам
Современные модели глубокого обучения демонстрируют экспоненциальный рост в количестве параметров и объеме обрабатываемых данных. Это обуславливает колоссальные потребности в вычислительных ресурсах, включая память, пропускную способность и энергопотребление. Растущая сложность задач, таких как обработка естественного языка и компьютерное зрение, требует все более крупных и емких моделей для достижения приемлемого уровня точности. Например, для обучения крупных языковых моделей, способных генерировать связные тексты и отвечать на сложные вопросы, требуются датацентры, оснащенные тысячами специализированных ускорителей. В результате, обучение и развертывание таких моделей становится дорогостоящим и недоступным для многих исследователей и организаций, что создает серьезные препятствия для дальнейшего развития области искусственного интеллекта.
Традиционное обучение глубоких нейронных сетей исторически опиралось на 32-битные числа с плавающей точкой (FP32) для представления весов и активаций. Этот формат, обеспечивающий высокую точность вычислений, одновременно накладывает значительные ограничения на производительность. Объём памяти, необходимый для хранения моделей, растёт пропорционально числу параметров и используемому формату, что затрудняет обучение масштабных сетей, особенно на устройствах с ограниченными ресурсами. Более того, операции с FP32 требуют значительных вычислительных затрат, замедляя процесс обучения и увеличивая энергопотребление. Таким образом, высокая точность, обеспечиваемая FP32, становится узким местом в современных системах обучения, препятствуя масштабированию и эффективности.
Снижение разрядности представления данных посредством квантизации представляет собой перспективный путь к повышению эффективности обучения глубоких нейронных сетей, однако сопряжено с определенными трудностями. Переход от традиционных 32-битных чисел с плавающей точкой (FP32) к более компактным форматам, таким как 8-битные целые числа (INT8), значительно уменьшает объем памяти, необходимый для хранения параметров модели и промежуточных вычислений, а также ускоряет операции. Тем не менее, уменьшение точности может приводить к потере информации и, как следствие, к снижению точности модели и нестабильности процесса обучения. Это требует разработки инновационных методов оптимизации, направленных на смягчение негативных последствий квантизации, включая адаптивные схемы квантизации и техники обучения, устойчивые к снижению точности, чтобы обеспечить сохранение высокой производительности и надежности модели.
Для преодоления сложностей, возникающих при снижении точности вычислений в глубоком обучении, разрабатываются инновационные стратегии оптимизации. Эти подходы направлены на минимизацию потери точности, неизбежной при переходе от форматов высокой точности, таких как FP32, к более экономичным, например, INT8 или даже меньше. Ключевыми направлениями исследований являются адаптивные методы квантизации, позволяющие динамически определять оптимальный уровень квантизации для различных слоев сети или даже отдельных параметров. Кроме того, активно изучаются техники смешанной точности, сочетающие использование разных форматов данных для максимизации эффективности и сохранения высокой точности. Применение градиентного сжатия и специальных регуляризаторов также способствует повышению устойчивости обучения в условиях пониженной точности, позволяя создавать более компактные и быстрые модели без существенной потери в производительности.
![Сравнение кривых валидации для Gemma 3 1B и SMoE 2.1B, а также сглаженная кривая обучения при дообучении DeepSeek-MoE-16B-Base[deepseekmoe], демонстрирует эффективность подхода к обучению.](https://arxiv.org/html/2601.22101v1/x4.png)
ECO: Компенсация ошибок в квантованном обучении
Оптимизатор с компенсацией ошибок (ECO) представляет собой новый подход к обучению моделей пониженной точности, который позволяет достичь сопоставимой с методами, использующими основные веса, потери на валидационной выборке, при этом обходясь без их хранения. Традиционные методы обучения с квантованием часто требуют сохранения копии весов в полной точности (“master weights”) для стабилизации процесса обучения и предотвращения деградации производительности. ECO отказывается от этого требования, что позволяет существенно снизить потребление памяти, сохраняя при этом высокую точность модели после квантования. Этот подход позволяет обучать модели с пониженной точностью без дополнительных затрат на хранение и обновление “master weights”, делая его привлекательным для задач с ограниченными ресурсами.
Оптимизатор ECO компенсирует потерю информации при квантовании, напрямую внедряя оценку ошибки квантования в расчет момента. Вместо использования мастер-весов, ECO динамически учитывает ошибку, возникающую при преобразовании весов модели к пониженной точности, и добавляет её к накопителю момента. Это позволяет корректировать направление шага оптимизации, уменьшая влияние квантования на процесс обучения и поддерживая стабильность сходимости. Фактически, ошибка квантования становится частью градиента, используемого для обновления весов, что позволяет более эффективно компенсировать снижение точности представления параметров модели. \Delta w = \eta (g + \Delta Q) , где η — скорость обучения, g — градиент, а \Delta Q — оценка ошибки квантования.
Оптимизатор ECO поддерживает стабильность обучения и минимизирует снижение производительности за счет стратегического включения ошибки квантования непосредственно в расчет момента. Вместо использования «мастерских» весов, ECO динамически компенсирует потерю информации, возникающую при квантовании, в процессе обновления параметров модели. Такой подход позволяет избежать накопления ошибок и поддерживает градиентный спуск на стабильной траектории, обеспечивая сопоставимые результаты с методами, использующими «мастерские» веса, но при этом снижая потребление памяти на 25% за счет их исключения.
Оптимизатор ECO позволяет снизить потребление статической памяти на 25% за счет отказа от использования «мастер-весов». Традиционные методы квантованного обучения часто сохраняют копии весов в полной точности (мастер-веса) для вычисления градиентов и обновления параметров модели. ECO устраняет необходимость в этих дополнительных копиях, напрямую компенсируя ошибку квантования в процессе вычисления момента, что позволяет достичь сопоставимой точности модели без увеличения объема необходимой статической памяти. Это особенно важно для развертывания моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встраиваемые системы.
Валидация и масштабируемость ECO на различных архитектурах
Эффективный метод оптимизации ECO был успешно протестирован и применен не только к стандартным плотным моделям, но и к архитектурам с разреженными смесями экспертов (Sparse Mixture of Experts, SMoE), таким как DeepSeek-MoE-16B. Это демонстрирует универсальность метода и его способность адаптироваться к различным структурам нейронных сетей, обеспечивая улучшение производительности в различных сценариях машинного обучения.
Эксперименты показали, что применение ECO приводит к стабильному улучшению производительности моделей различных размеров. Наблюдения проводились на моделях, начиная с Gemma 3 1B и охватывая более крупные архитектуры. Результаты демонстрируют, что ECO последовательно повышает точность и эффективность моделей, независимо от их масштаба, что подтверждает его универсальность и применимость в широком спектре задач машинного обучения.
Метод ECO поддерживает различные форматы квантизации, включая INT8, BF16 и FP8, что демонстрирует его гибкость и адаптируемость к различным аппаратным и программным платформам. Поддержка INT8 обеспечивает значительное снижение требований к памяти и увеличение скорости вычислений, особенно на специализированном оборудовании. BF16 (Brain Floating Point) представляет собой формат с половинной точностью, обеспечивающий компромисс между точностью и скоростью. Использование FP8 (Floating Point 8) позволяет добиться еще большей компрессии и ускорения, хотя и с потенциальным снижением точности. Возможность выбора формата квантизации позволяет оптимизировать производительность и точность модели в зависимости от конкретных требований и доступных ресурсов.
В отличие от наивных подходов к квантизации, приводящих к расходимости процесса обучения, ECO обеспечивает стабилизацию обучения и достижение конечной стационарной ошибки. Данная ошибка ограничена сверху и контролируется дисперсией шума квантизации (σ²) и параметром момента (β). Математически, стационарный порог ошибки выражается как L²σ² / (1-β²), где L представляет собой параметр, зависящий от архитектуры модели и используемого метода оптимизации. Это позволяет предсказуемо ограничивать влияние квантизации на точность модели и предотвращать потерю сходимости в процессе обучения.
К эффективному и масштабируемому глубокому обучению
Разработанный подход ECO открывает возможность значительно снизить требования к памяти и вычислительным ресурсам при обучении глубоких нейронных сетей. Вместо традиционного хранения полновесных копий параметров модели, ECO использует инновационную схему, позволяющую эффективно кодировать и хранить информацию о весах, что приводит к существенному уменьшению объема необходимой памяти. Это достигается за счет оптимизации процесса обучения и использования специализированных алгоритмов, которые позволяют достичь сопоставимой, а в некоторых случаях и превосходящей точности, при значительно меньших затратах ресурсов. В результате, ECO предоставляет перспективное решение для обучения сложных моделей на устройствах с ограниченными ресурсами, расширяя возможности применения искусственного интеллекта в самых различных областях.
Технология ECO открывает новые перспективы для развертывания моделей глубокого обучения на устройствах с ограниченными ресурсами. Благодаря возможности обучения с пониженной точностью без потери производительности, ECO позволяет значительно снизить требования к памяти и вычислительной мощности. Это особенно важно для мобильных устройств, встроенных систем и периферийных вычислений, где энергоэффективность и компактность являются ключевыми факторами. Такой подход позволяет создавать интеллектуальные приложения, работающие непосредственно на устройствах, без необходимости подключения к облачным серверам, что обеспечивает более высокую скорость обработки данных и конфиденциальность.
Устранение мастер-весов в процессе обучения глубоких нейронных сетей значительно упрощает алгоритм и позволяет существенно снизить потребность в оперативной памяти. Традиционно, в существующих методах, мастер-веса служат основой для создания рабочих весов, требуя дополнительного хранения и манипулирования. Отказ от этой концепции позволяет напрямую оптимизировать рабочие веса, освобождая ценные ресурсы памяти и уменьшая вычислительную сложность. Это особенно важно при работе с большими моделями и обширными наборами данных, где экономия памяти может стать критическим фактором. Данный подход не только ускоряет обучение, но и открывает возможности для эффективного развертывания моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встраиваемые системы.
Исследования показали, что разработанный подход ECO демонстрирует высокую совместимость с широким спектром архитектур глубокого обучения, включая сверточные нейронные сети, рекуррентные сети и трансформеры. Более того, ECO эффективно работает с различными форматами квантования, позволяя оптимизировать модели для различных аппаратных платформ и задач. Эта универсальность делает ECO ценным инструментом для разработчиков, стремящихся к созданию эффективных и масштабируемых решений в области искусственного интеллекта, открывая возможности для развертывания сложных моделей даже на устройствах с ограниченными ресурсами и обеспечивая гибкость в адаптации к будущим инновациям в области нейронных сетей. Такая адаптивность позволяет рассматривать ECO как ключевой элемент в развитии глубокого обучения, способствуя его более широкому внедрению и применению.
Исследование демонстрирует, что системы действительно не строятся, а скорее взращиваются, подобно живым организмам. Предложенный метод ECO, устраняющий необходимость в полноточных мастер-весах, является ярким тому подтверждением. Он не навязывает жесткую структуру, а позволяет модели развиваться, используя квантование и компенсацию ошибок. В этом подходе прослеживается философия, что каждый архитектурный выбор — это пророчество о будущем сбое, поскольку система, лишенная избыточности, вынуждена адаптироваться к неточностям. Как заметил Дональд Дэвис: «Простота — это конечное совершенство, достигнутое после долгой работы». Эта простота, достигаемая за счет отказа от полноточных весов, и является ключом к эффективному обучению больших языковых моделей.
Что Дальше?
Представленная работа демонстрирует умение обучать большие языковые модели с пониженной точностью, избегая необходимости в полноточных «мастер-весах». Однако, это лишь временное облегчение. Система, освобожденная от одной зависимости, неминуемо обретет другие. Уменьшение объема памяти — это иллюзия контроля, поскольку сложность системы всегда найдет способ проявиться — будь то в увеличении вычислительных затрат на компенсацию ошибок, или в появлении новых, непредсказуемых артефактов.
Оптимизаторы, как и все сложные механизмы, стремятся к состоянию минимальной энергии — то есть, к предсказуемому сбою. Отказ от полноточных весов — это не решение проблемы, а лишь перенос её в другую область. Следующим шагом, вероятно, станет поиск способов уменьшить точность не только весов, но и состояний оптимизатора — шаг, который, несомненно, приведет к новым, еще более изощренным формам нестабильности.
В конечном счете, задача не в том, чтобы построить идеальный оптимизатор, а в том, чтобы смириться с неизбежной энтропией. Разделение системы на микросервисы, отказ от полноточных представлений — всё это лишь попытки отсрочить момент, когда вся взаимосвязанная конструкция рухнет синхронно. И это падение — не ошибка, а закономерность.
Оригинал статьи: https://arxiv.org/pdf/2601.22101.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Квантовая механика: скрытый детерминизм?
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Облачные вычисления для науки: гибкость и масштабируемость
2026-01-31 23:52