Автор: Денис Аветисян
Исследователи предлагают инновационный подход к автоматической озвучке видео, основанный на совместном анализе звука и изображения.
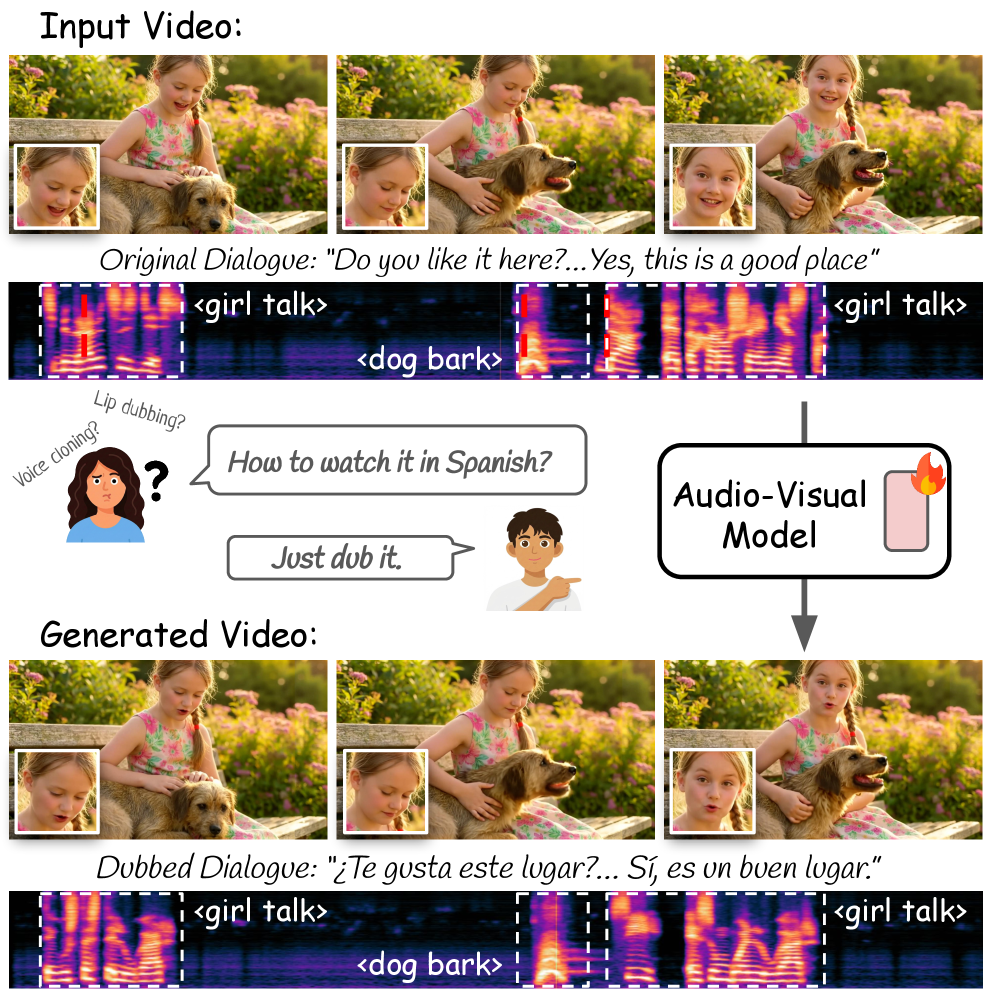
Представлена модель, использующая диффузионные модели и механизм кросс-модального внимания для создания более реалистичной и связной озвучки.
Несмотря на значительный прогресс в области мультимодального моделирования, задача автоматической озвучки видео остается сложной из-за необходимости сохранения синхронизации губ и идентичности говорящего. В данной работе, представленной под названием ‘JUST-DUB-IT: Video Dubbing via Joint Audio-Visual Diffusion’, предлагается новый подход к озвучке видео, рассматривающий ее как задачу совместной генерации аудио и видео с использованием диффузионной модели. Предложенный метод, основанный на адаптации фундаментальной аудио-визуальной модели посредством легковесного LoRA, позволяет генерировать реалистичные и синхронизированные дублированные видео. Сможет ли подобный подход значительно упростить процесс локализации видеоконтента и открыть новые возможности для создания персонализированного мультимедийного опыта?
Иллюзия Реальности: Сложности Бесшовного Дублирования
Традиционные методы видеодублирования часто сталкиваются с проблемой сохранения визуальной достоверности при точной передаче смысла. Несоответствие между оригинальным изображением и синхронизированной речью приводит к заметным артефактам, таким как рассинхронизация губ и неестественные движения лица. В результате, даже незначительные погрешности в синхронизации звука и видео могут существенно ухудшить восприятие контента, создавая ощущение искусственности и отвлекая зрителя от повествования. Эта проблема особенно остро ощущается при дублировании сложных сцен с быстрой речью или выразительной мимикой, где даже малейшие отклонения от оригинала могут разрушить иллюзию реализма и вызвать дискомфорт у аудитории.
Для достижения подлинного реализма в дубляже недостаточно просто заменить аудиодорожку. Современные исследования направлены на целостную генерацию видеоконтента, способного сохранить индивидуальность говорящего и естественность его движений. Это предполагает не только синхронизацию губ с новым звуком, но и воссоздание мимики, жестов и даже незначительных нюансов выражения лица, характерных для оригинала. Такой подход требует сложных алгоритмов, способных анализировать видеоматериал, выявлять ключевые параметры и генерировать реалистичное изображение, неотличимое от исходного. В результате, зритель получает возможность воспринимать контент на другом языке, не испытывая дискомфорта от несоответствия визуального и звукового ряда, что значительно повышает качество восприятия и погружение в происходящее.
Современные методы дубляжа часто сталкиваются с проблемой временной когерентности, что приводит к заметным несоответствиям между речью и движениями губ, а также к неестественным выражениям лица. Несмотря на прогресс в области искусственного интеллекта, сохранение плавности и реалистичности во времени остается сложной задачей. Эти несоответствия, даже незначительные, способны разрушить иллюзию реализма и отвлечь зрителя от повествования, создавая эффект «неестественности». Исследования показывают, что зрители особенно чувствительны к расхождениям во времени между артикуляцией и звуком, что подчеркивает важность разработки алгоритмов, способных точно синхронизировать видео и аудио компоненты для достижения бесшовного дубляжа.

Аудиовизуальная Генерация: Новый Подход к Синхронизации
В современной дубляжной индустрии ключевым элементом является аудиовизуальная генерация, представляющая собой одновременное создание как переведенной звуковой дорожки, так и соответствующего визуального контента. Этот подход позволяет не просто заменить звук, но и синхронизировать его с артикуляцией персонажей на видео, создавая эффект реалистичного соответствия. В отличие от традиционных методов дубляжа, где звук и изображение обрабатывались последовательно, аудиовизуальная генерация обеспечивает целостный и автоматизированный процесс, что значительно ускоряет и удешевляет производство многоязычного контента.
В основе современной автоматической дубляжа лежит использование мощных предварительно обученных моделей, известных как Аудио-Визуальные Базовые Модели (AVFM). Эти модели, обученные на обширных мультимодальных данных, способны выявлять и моделировать сложные взаимосвязи между звуком и изображением. AVFM не просто распознают отдельные аудио- и визуальные элементы, но и устанавливают корреляции между ними, что позволяет им генерировать реалистичные и синхронизированные аудиовизуальные последовательности. Эффективность этих моделей обеспечивается использованием глубоких нейронных сетей, способных к извлечению и представлению абстрактных признаков из аудио- и видеоданных, а также к установлению соответствий между различными модальностями.
Современные модели аудио-визуальной генерации используют такие методы, как латентные переменные и кросс-модальное внимание, для эффективного сопоставления аудио-признаков с соответствующими визуальными представлениями. Латентные переменные позволяют моделировать скрытые факторы, влияющие на связь между звуком и изображением, улавливая тонкие нюансы и вариации. Кросс-модальное внимание, в свою очередь, позволяет модели динамически фокусироваться на наиболее релевантных частях аудио- и визуальных данных при установлении соответствий, что повышает точность синхронизации и реалистичность генерируемого контента. Эти методы обеспечивают не просто сопоставление признаков, но и понимание семантической связи между звуком и изображением, необходимое для создания убедительной аудио-визуальной синхронизации.
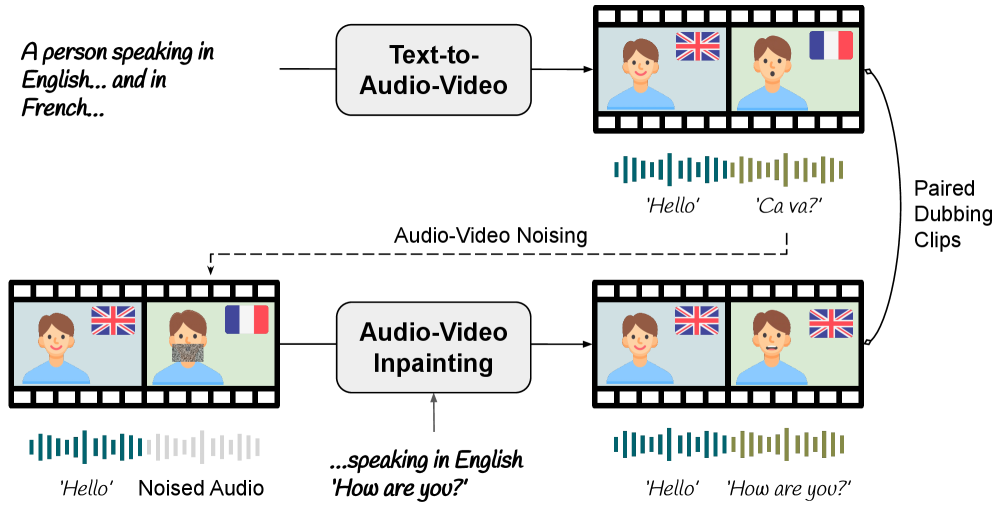
Диффузионные Модели и Эффективное Обучение: Инструменты Реалистичного Дублирования
Диффузионные модели в настоящее время являются передовым подходом к генерации аудиовизуального контента, демонстрируя превосходное качество и реалистичность по сравнению с предшествующими методами, такими как генеративно-состязательные сети (GAN) и вариационные автоэнкодеры (VAE). В отличие от GAN, которые могут быть нестабильными в обучении и склонны к коллапсу моды, диффузионные модели обеспечивают более стабильный процесс обучения за счет постепенного добавления шума к данным и последующего его удаления. Это позволяет генерировать более разнообразные и высококачественные образцы, особенно в сложных областях, таких как генерация изображений высокого разрешения и синтез реалистичного звука. Объективные метрики, такие как FID (Fréchet Inception Distance) и IS (Inception Score), последовательно демонстрируют превосходство диффузионных моделей над альтернативными подходами в задачах генерации.
Для повышения эффективности обучения диффузионных моделей применяются методы сопоставления потоков (Flow Matching). В отличие от стандартных диффузионных моделей, где процесс диффузии описывается стохастическим дифференциальным уравнением, Flow Matching предполагает построение непрерывного потока, направленного по прямым траекториям в пространстве латентных переменных. Это позволяет упростить процесс обучения, поскольку модель обучается предсказывать векторное поле, определяющее эти прямые траектории, что приводит к более быстрой сходимости и снижению вычислительных затрат по сравнению с традиционными подходами, требующими моделирования сложного стохастического процесса. \frac{dx}{dt} = f(x, t) — типичное уравнение, описывающее этот процесс, где x — состояние системы, t — время, а f — векторное поле, определяющее траекторию потока.
Тонкая настройка диффузионных моделей часто осуществляется с использованием LoRA (Low-Rank Adaptation), метода, позволяющего значительно снизить вычислительные затраты. LoRA замораживает веса предварительно обученной модели и внедряет обучаемые матрицы низкого ранга в каждый слой. Это существенно уменьшает количество обучаемых параметров, что приводит к снижению требований к памяти и времени обучения. Адаптация к конкретным наборам данных достигается за счет обучения только этих матриц низкого ранга, оставляя исходную модель неизменной. Такой подход особенно полезен при работе с ограниченными вычислительными ресурсами или при необходимости адаптации модели к нескольким различным задачам или наборам данных.
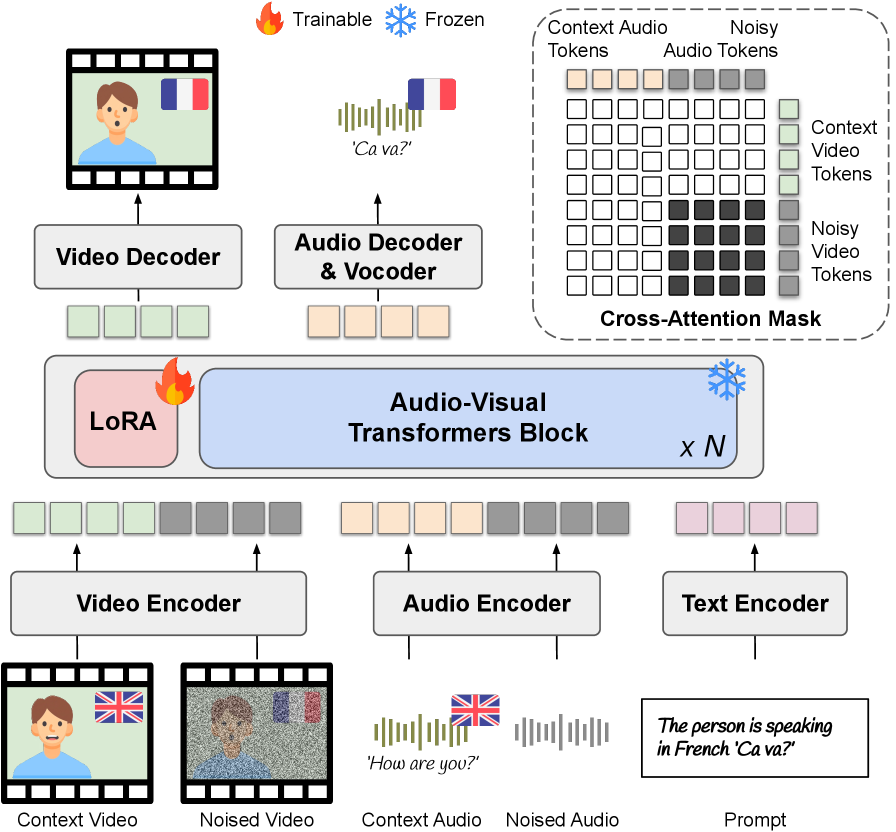
Оценка и Совершенствование для Реалистичного Дублирования: Стремление к Безупречности
Для объективной оценки и сопоставления различных методов дублирования крайне важны специализированные наборы данных, такие как TalkVid и HDFT. Эти коллекции видеоматериалов, содержащие синхронизированные речь и движения губ, позволяют исследователям проводить количественный анализ и сравнивать эффективность новых алгоритмов. Использование стандартизированных наборов данных обеспечивает воспроизводимость результатов и способствует прогрессу в области автоматического дублирования, позволяя выявлять сильные и слабые стороны различных подходов и направлять дальнейшие исследования к созданию более реалистичных и естественных дублированных видео.
Оценка синхронизации аудио и видео является ключевым аспектом в создании реалистичного даббинга. Для этого используется метрика SyncNet, позволяющая количественно оценить соответствие между речью и движениями губ. В ходе исследований, предложенный метод демонстрирует впечатляющий результат — асинхронный показатель SyncNet ASync в 3.00 на сложных, неконтролируемых видеоматериалах. Этот показатель свидетельствует о высокой степени физической согласованности между сгенерированной речью и визуальными данными, что является важным шагом к созданию правдоподобных и естественных дублированных видеороликов. Достижение подобной точности позволяет существенно улучшить восприятие контента и повысить степень погружения зрителя.
Для повышения реалистичности дубляжа применялись методы маскирования и аугментации губ, направленные на увеличение разнообразия обучающих данных и устойчивости генерируемого контента. В частности, увеличение разнообразия соотношения сторон рта (Mouth Aspect Ratio Diversity) и снижение расстояния между ключевыми точками губ (Lip Landmark Distance) позволили добиться более естественного и правдоподобного соответствия речевых движений. Предложенный подход продемонстрировал 100%-ный процент успешной генерации, что свидетельствует о значительном улучшении качества дубляжа и его способности создавать реалистичные и убедительные видеоматериалы.
Достижения в области автоматической дубляжа представляют собой значительный прорыв в создании реалистичного и бесшовного опыта для зрителей. Новые методы, основанные на тщательной оценке и усовершенствовании алгоритмов, позволяют добиться впечатляющей синхронизации звука и видео, что ранее было сложной задачей. Благодаря применению разнообразных наборов данных, таких как TalkVid и HDFT, и использованию метрик, оценивающих физическую согласованность, создаются дублированные видеоматериалы, практически неотличимые от оригинальных. Успешное применение техник маскирования и аугментации губ не только повышает разнообразие данных, но и обеспечивает устойчивость генерируемого контента, гарантируя 100% успешность генерации и приближая технологии дубляжа к уровню, необходимому для профессионального использования.

Исследование, представленное в данной работе, демонстрирует инновационный подход к проблеме дублирования видео, рассматривая её как задачу совместной генерации аудио- и визуального контента. Авторы предлагают использовать диффузионные модели, что позволяет добиться большей реалистичности и временной согласованности в итоговом видео. Этот метод особенно актуален в контексте концепции «технического долга», поскольку позволяет избежать накопления артефактов и несоответствий, часто возникающих при традиционных подходах к дублированию. Как однажды заметил Бертран Рассел: «Чем больше я узнаю людей, тем больше люблю собак». Эта фраза, на первый взгляд острая, отражает понимание сложности систем и предпочтение гармоничных, предсказуемых решений — что, безусловно, применимо и к области генерации видеоконтента, где поддержание целостности и согласованности является ключевой задачей.
Куда Ведет Этот Дубляж?
Представленная работа, хотя и демонстрирует заметный шаг вперед в автоматическом дубляже видео, лишь обнажает глубину нерешенных проблем. Совершенствование моделей диффузии, безусловно, важно, но истинный вызов заключается не в генерации правдоподобного звука, а в понимании временной когерентности самой системы. Ведь любой дубляж — это не просто замена звуковой дорожки, а реконструкция смыслового потока, адаптированного к новой временной среде.
Очевидно, что текущие подходы, фокусирующиеся на совместном аудио-визуальном моделировании, ограничены необходимостью больших объемов размеченных данных. Более устойчивые решения, вероятно, потребуют отхода от прямого обучения и перехода к системам, способным к самообучению и адаптации, подобно тому, как зрелая система исправляет собственные ошибки со временем. Инциденты, несоответствия в дубляже, должны восприниматься не как недостатки, а как шаги на пути к более совершенной модели.
В конечном счете, будущее автоматического дубляжа связано не с достижением идеальной точности, а с созданием систем, способных к элегантному старению. Систем, которые, подобно любому сложному механизму, со временем становятся не только более эффективными, но и более мудрыми, извлекая уроки из каждой собственной неудачи. Ведь время — это не метрика, а среда, в которой формируется любая система.
Оригинал статьи: https://arxiv.org/pdf/2601.22143.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Квантовая механика: скрытый детерминизм?
- Агенты SERA: Код, Созданный с Подтверждением
2026-02-01 01:35