Автор: Денис Аветисян
Новый метод позволяет восстанавливать латентные сетевые структуры по наблюдаемым данным, открывая возможности для прогнозирования и понимания сложных процессов.

Исследование представляет подход, основанный на использовании дробных степеней ковариационной матрицы для восстановления структурных связей и обнаружения зарождающихся явлений в различных системах, от клиентской базы до нейронных сетей.
Обнаружение зарождающихся явлений в сложных системах, от оттока клиентов до приступов эпилепсии, часто затруднено скрытыми причинно-следственными связями. В работе ‘The Powers of Precision: Structure-Informed Detection in Complex Systems — From Customer Churn to Seizure Onset’ предложен метод машинного обучения, позволяющий выявлять эти связи и предсказывать критические события, используя дробные степени матрицы ковариации для восстановления латентной сетевой структуры. Показано, что предложенный подход обеспечивает структурную согласованность даже при частичной наблюдаемости данных и демонстрирует конкурентоспособные результаты в задачах прогнозирования. Способен ли этот метод, объединяющий предсказательную силу и интерпретируемую статистическую структуру, пролить свет на фундаментальные механизмы, управляющие сложными системами?
Раскрытие Скрытых Структур в Сложных Системах
Многие явления окружающего мира, от приступов эпилепсии до финансовых крахов, являются проявлением так называемых “сложных систем”. Эти системы характеризуются не просто большим количеством взаимодействующих компонентов, но и способностью к возникновению эмерджентных свойств — характеристик, которые невозможно предсказать, исходя из свойств отдельных элементов. Например, скоординированная активность миллиардов нейронов порождает сознание, а взаимодействие множества трейдеров на рынке формирует тренды и волатильность. Понимание этих систем требует выхода за рамки линейных моделей и признания важности нелинейных взаимодействий, обратной связи и самоорганизации, поскольку поведение системы в целом является результатом сложного взаимодействия её частей, а не просто их суммой.
Традиционные аналитические методы, такие как линейная регрессия или простой статистический анализ, зачастую оказываются неспособными адекватно отразить сложность взаимосвязей в системах, характеризующихся нелинейностью и множеством взаимодействующих элементов. Это происходит из-за того, что эти методы предполагают упрощенные модели, игнорируя скрытые зависимости и обратные связи, которые определяют поведение системы. В результате, построенные модели дают неточные прогнозы, особенно в долгосрочной перспективе, и не позволяют эффективно управлять этими сложными системами. Неспособность учесть все факторы, влияющие на систему, приводит к ошибкам в прогнозировании, будь то финансовые рынки, эпидемиологические модели или даже климатические изменения, подчеркивая необходимость разработки новых, более совершенных аналитических подходов.
Изучение структурных закономерностей, управляющих взаимодействиями в сложных системах, представляется крайне важным, однако традиционные методы анализа, основанные на простой корреляции, оказываются недостаточными для выявления этих закономерностей. Корреляция лишь указывает на статистическую связь между переменными, но не раскрывает причинно-следственные связи и скрытые механизмы, формирующие поведение системы. Для более глубокого понимания необходимы методы, способные учитывать нелинейные зависимости, топологию взаимодействий и динамические процессы, происходящие внутри системы. Такие подходы, как анализ сетей, теория графов и методы машинного обучения, позволяют выявлять ключевые узлы, кластеры и паттерны, определяющие устойчивость, адаптивность и эволюцию сложных систем. Игнорирование структурных закономерностей приводит к созданию упрощенных моделей, не способных адекватно описывать реальное поведение и прогнозировать будущие изменения.
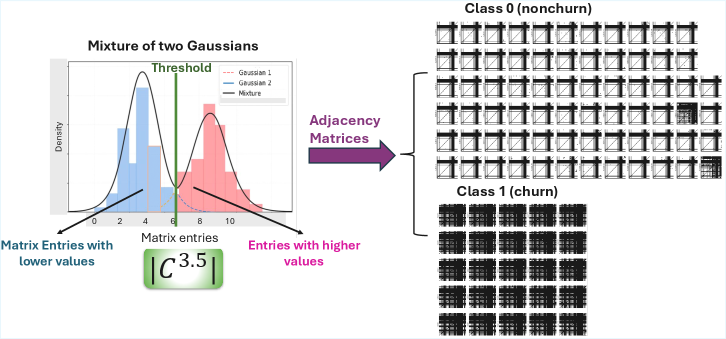
Структурно-Информированное Представление Признаков: Новый Подход
Предлагаемый метод “Структурно-информированное представление признаков” (Structure-Informed Feature Representation) предполагает явное включение в процесс моделирования информации об underlying network structure системы. В отличие от традиционных подходов, игнорирующих взаимосвязи между переменными, данная методология делает акцент на использовании сетевой структуры для формирования признаков. Это достигается путем анализа и кодирования взаимосвязей между элементами системы, что позволяет модели более эффективно улавливать закономерности и зависимости в данных. По сути, представленные признаки отражают не только значения переменных, но и их позицию и связи в сети, что способствует повышению точности и интерпретируемости моделей.
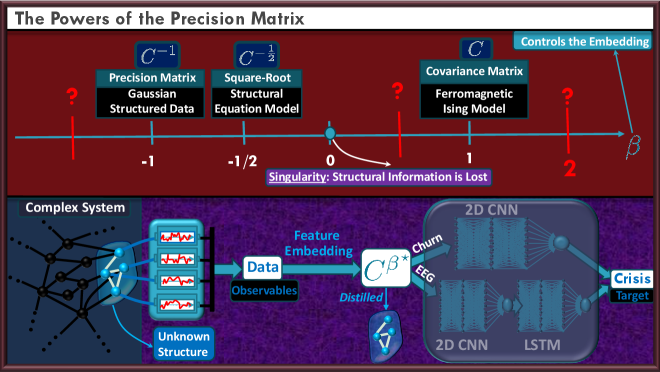
В основе предлагаемого подхода лежит использование матрицы ковариации для фиксации взаимосвязей между переменными. Однако, для выявления скрытых зависимостей, помимо стандартного расчета, применяется возведение матрицы ковариации в дробную степень. Данная операция позволяет усилить или ослабить определенные связи, что способствует более точному представлению структуры данных и выявлению неявных корреляций, которые могут быть не видны при стандартном анализе ковариации. Σ^{α}, где Σ — матрица ковариации, а α — дробный показатель степени, позволяет регулировать чувствительность к различным типам зависимостей.
Предлагаемый подход к представлению данных, основанный на их внутренней структурной организации, направлен на создание более устойчивых и интерпретируемых моделей. Достигается это за счет явного учета взаимосвязей между переменными, что позволяет добиться последовательного восстановления структуры в различных системах. Математически обоснованная точность восстановления структуры подтверждается ограничением погрешности Δβ, которое определяет максимальное отклонение восстановленной структуры от истинной. Ограничение Δβ служит гарантией надежности и предсказуемости модели, обеспечивая ее стабильную работу в различных условиях и на различных наборах данных.
Моделирование Зависимостей с Помощью Графовых Случайных Полей
В основе нашего подхода лежит ‘Графовое Матерновское Случайное Поле’ (Graph-Based Matérn Random Field), представляющее собой расширение классического ‘Матерновского Случайного Поля’ для работы с сетевыми данными. Традиционное Матерновское поле оперирует с пространственными данными, определяя корреляцию между точками в зависимости от расстояния. Графовое Матерновское поле адаптирует эту концепцию, заменяя евклидово расстояние на структуру графа, что позволяет моделировать зависимости между переменными, определенными в узлах графа, даже в отсутствие явной пространственной близости. Это достигается путем определения ковариационной матрицы на основе структуры графа, что позволяет учитывать сложные взаимосвязи между узлами и их влиянием друг на друга.
Использование графов позволяет моделировать зависимости между переменными, определенными в узлах сети. Для представления этих условных взаимосвязей используется матрица точности \textbf{Q}, обратная ковариационной матрице \textbf{Σ}. Элемент Q_{ij} матрицы точности отражает силу условной зависимости между переменными i и j при условии всех остальных переменных. Недиагональные элементы матрицы точности указывают на прямые зависимости, а диагональные элементы соответствуют точности (дисперсии) каждой переменной. Таким образом, матрица точности предоставляет компактное представление о структуре условных зависимостей в графовой модели.
Интеграл Данфорда-Тейлора является мощным инструментом для анализа и манипулирования сложными зависимостями в графовых случайных полях. Он обеспечивает согласованное восстановление параметров модели даже при наличии скрытых (латентных) узлов, оказывающих когерентное влияние на наблюдаемую подсистему. Это достигается за счет возможности аналитического представления и ограничения матрицы взаимодействия между блоками A_{SS'}, где S и S' обозначают подсистемы наблюдаемых и латентных переменных соответственно. Ограниченность данной матрицы гарантирует стабильность и предсказуемость процесса восстановления параметров модели, что особенно важно при работе с неполными или зашумленными данными.
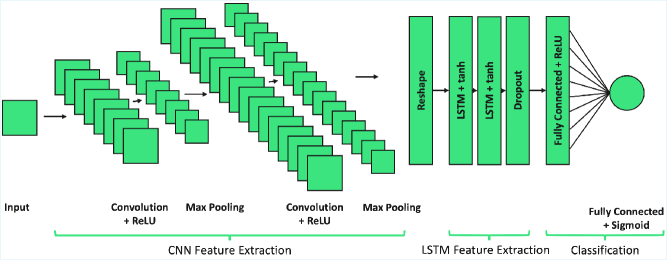
Применение и Перспективы Развития
Предложенная методология демонстрирует значительный потенциал в различных областях, в частности, в обнаружении эпилептических приступов и прогнозировании оттока клиентов. В обоих случаях ключевым фактором является выявление и анализ скрытых взаимосвязей между данными. В отличие от традиционных подходов, фокусирующихся исключительно на корреляциях, данный метод позволяет более глубоко понять структуру данных и выявить факторы, влияющие на исследуемые явления. Это особенно важно в медицинской диагностике, где точное определение признаков приступа критично, и в бизнесе, где понимание причин оттока клиентов позволяет разрабатывать эффективные стратегии удержания. Возможность выявления этих сложных взаимосвязей открывает новые горизонты для разработки более точных и надежных моделей прогнозирования и принятия решений.
Исследование продемонстрировало значительное повышение эффективности благодаря явному учету структурной информации в анализируемых данных. В частности, в задаче обнаружения эпилептических приступов, предложенный подход превзошел существующие эталонные методы, обеспечивая более надежные и применимые результаты. Включение структурных связей позволило не просто идентифицировать закономерности, но и точнее прогнозировать возникновение приступов, что особенно важно для систем раннего предупреждения и оперативного вмешательства. Полученные данные свидетельствуют о потенциале данного метода для решения широкого спектра задач, где понимание взаимосвязей между компонентами системы играет ключевую роль.
Предлагаемый метод выявления структуры данных открывает возможности для перехода от простого установления корреляций к пониманию причинно-следственных связей. Анализ, основанный на представлении данных, демонстрирует чёткое разделение признаков, что подтверждается значительно большим расстоянием между классами, чем внутри них. Такое разделение не только повышает надёжность прогнозов, но и позволяет выявить ключевые факторы, определяющие наблюдаемые явления, представляя собой важный шаг к построению моделей, способных не просто предсказывать, но и объяснять происходящее. Данный подход позволяет перейти от описания «что» происходит к пониманию «почему», открывая перспективы для более глубокого анализа и принятия обоснованных решений.
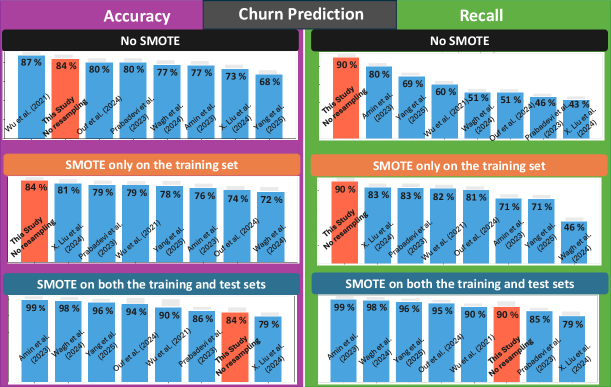
Адаптация к Ограниченным Данным и Дальнейшее Развитие
В условиях реальных задач часто возникает дефицит данных, что существенно ограничивает возможности обучения эффективных моделей. Для преодоления этой проблемы разработаны методы “Адаптации обучения-тестирования”, которые фокусируются на сохранении структурной информации в процессе обучения. Вместо того, чтобы просто подгонять модель под имеющиеся данные, эти техники стремятся выявить и сохранить фундаментальные зависимости и взаимосвязи, присутствующие в данных. Это позволяет создавать более устойчивые и обобщающие модели, способные эффективно работать даже при ограниченном количестве наблюдений и в ситуациях, когда тестовые данные отличаются от обучающих. Подход особенно ценен в областях, где сбор большого объема данных затруднен или невозможен, например, в медицине, геологии или при изучении редких явлений.
Возможность создания устойчивых моделей при ограниченном объеме данных существенно расширяет сферу применения данного подхода к решению разнообразных задач. В ситуациях, когда сбор большого количества информации затруднен или невозможен, предложенные методы позволяют эффективно использовать имеющиеся наблюдения, сохраняя при этом высокую точность и надежность прогнозов. Это особенно актуально для областей, где данные дороги или их получение сопряжено с трудностями, таких как медицина, экологический мониторинг и анализ редких событий. Таким образом, преодоление зависимости от больших массивов данных открывает новые перспективы для применения разработанной системы в широком спектре практических приложений, ранее считавшихся недостижимыми.
Предстоящие исследования направлены на расширение существующей системы с целью адаптации к динамическим системам и интеграции внешних знаний. Это позволит не только учитывать изменяющиеся условия в реальном времени, но и использовать накопленный опыт и экспертные оценки для повышения точности и надежности моделей. Интеграция внешних знаний, например, в виде онтологий или баз данных, потенциально способна значительно улучшить способность системы к обобщению и решению сложных задач, открывая новые возможности для понимания и моделирования окружающего мира. В результате, появляется возможность разрабатывать системы, способные не просто реагировать на текущие данные, но и предсказывать будущие изменения и принимать обоснованные решения в условиях неопределенности.
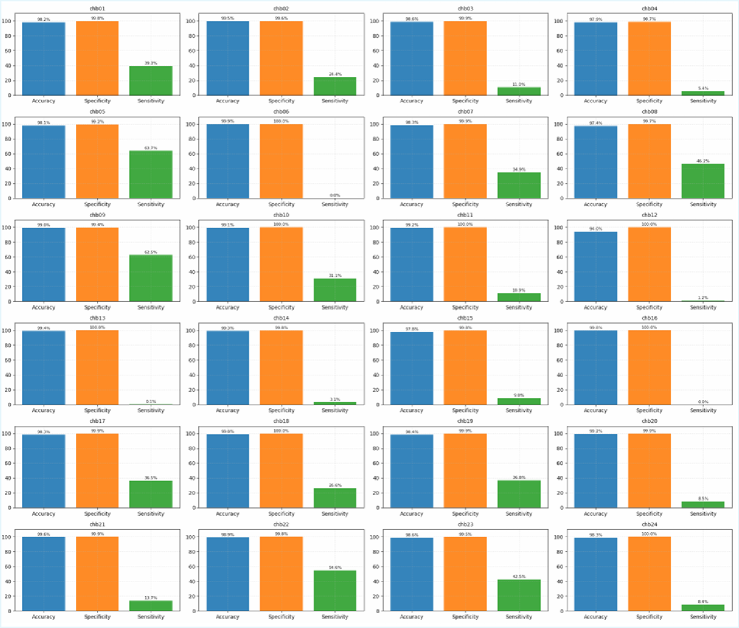
Исследование демонстрирует, что выявление скрытых структурных связей в сложных системах, таких как сети, позволяет прогнозировать и понимать их поведение. Авторы предлагают метод восстановления этих связей, используя математический аппарат дробных степеней матрицы ковариации, что особенно ценно при неполном наблюдении данных. Этот подход, по сути, позволяет увидеть закономерности, скрытые в хаосе, и предсказать возникновение новых, неожиданных явлений. Как однажды заметил Марвин Минский: «Лучший способ понять — это построить». Данное исследование воплощает эту идею, строя модель, позволяющую реконструировать и анализировать внутреннюю структуру сложных систем, раскрывая их потенциал для предсказания и контроля.
Куда же это всё ведёт?
Представленный подход, выстраивающий картину скрытой структуры по фрагментам ковариационных матриц, открывает, скорее, ящик Пандоры, нежели даёт окончательные ответы. Восстановление сетевой организации — это, конечно, интересно, но куда деть возникающий соблазн интерпретировать полученные связи как причинно-следственные? Найти истинный порядок в хаосе данных — задача, требующая не только математической точности, но и, пожалуй, изрядной доли цинизма.
Очевидным направлением представляется расширение инструментария для работы с неполнотой данных. Фрактальные степени ковариации — лишь один из возможных способов, и вполне вероятно, что существуют более элегантные, более эффективные методы. Однако, ключевым остаётся вопрос: достаточно ли вообще «восстанавливать» структуру, или же следует искать признаки самоорганизации непосредственно в потоке данных, не пытаясь навязать ему заранее заданную модель?
Настоящий вызов — это выход за рамки статических сетей. Реальные системы меняются, эволюционируют, и адекватное описание требует учитывать динамику связей. Поиск универсальных индикаторов возникновения новых, непредсказуемых явлений в таких системах — вот где кроется настоящая прелесть этой области, и, возможно, её главная головная боль.
Оригинал статьи: https://arxiv.org/pdf/2601.21170.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Моделирование биомолекул: новый импульс от нейросетей
- Квантовая механика: скрытый детерминизм?
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Оптические солитоны: новый материал для нейроморфных вычислений
2026-02-01 01:38