Автор: Денис Аветисян
Исследователи предлагают эффективный метод дистилляции и гибридную архитектуру, позволяющие значительно улучшить производительность при работе с очень длинными последовательностями данных.
Представлены HALO, процедура дистилляции, и HypeNet, гибридная архитектура, сочетающая внимание и рекуррентные нейронные сети для эффективной обработки длинного контекста.
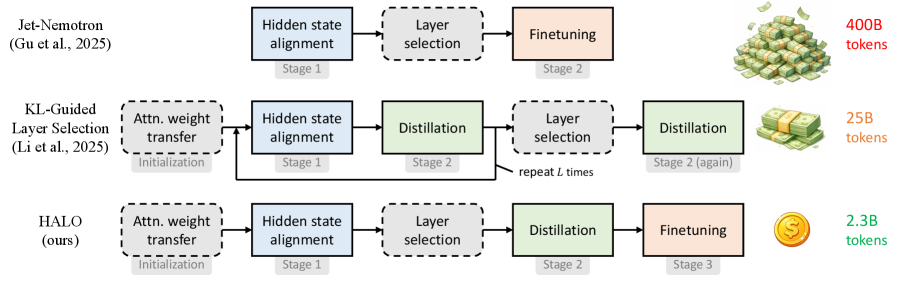
Гибридные архитектуры, объединяющие механизмы внимания и рекуррентные нейронные сети, демонстрируют перспективные результаты в моделировании длинных контекстов, однако их широкое внедрение сдерживается высокой стоимостью обучения с нуля. В работе ‘Hybrid Linear Attention Done Right: Efficient Distillation and Effective Architectures for Extremely Long Contexts’ предложен HALO — новый пайплайн дистилляции Transformer-моделей в гибридные RNN-attention сети, а также архитектура HypeNet, обеспечивающая превосходную экстраполяцию на длинные последовательности. Авторы показали, что преобразование моделей Qwen3 в HypeNet с помощью HALO позволяет достичь сопоставимой производительности, при этом значительно повысив эффективность обработки длинных контекстов, используя лишь 2.3 миллиарда токенов — менее 0.01% от объема данных, использованных для предварительного обучения. Возможно ли дальнейшее снижение затрат на дистилляцию и расширение возможностей гибридных архитектур для решения еще более сложных задач?
Вызовы длинного контекста: Преодоление ограничений
Традиционные архитектуры Transformer, несмотря на свою мощь, испытывают значительные трудности при обработке длинных последовательностей данных. Эта проблема обусловлена квадратичной сложностью вычислений, возникающей при расчете внимания между всеми парами токенов в последовательности. O(n^2), где n — длина последовательности, означает, что требуемые вычислительные ресурсы и время обработки экспоненциально возрастают с увеличением длины входных данных. В результате, модели Transformer сталкиваются с ограничениями по памяти и скорости при работе с большими текстами, что существенно снижает их эффективность в задачах, требующих анализа обширного контекста, таких как обобщение длинных документов, машинный перевод больших объемов текста или ответы на вопросы, основанные на детальном понимании развернутых текстов.
Ограничение в обработке больших объемов данных существенно снижает эффективность моделей при решении задач, требующих глубокого анализа и логических выводов на основе обширной информации. Это создает узкое место во многих областях обработки естественного языка, таких как анализ юридических документов, обработка медицинских карт, написание длинных текстов и ответы на вопросы, требующие синтеза информации из различных источников. Например, модели испытывают трудности с пониманием сложных повествований или выявлением тонких взаимосвязей в больших базах знаний, что приводит к снижению точности и надежности результатов. В результате, разработка эффективных методов обработки длинных последовательностей данных становится ключевой задачей для дальнейшего развития и применения искусственного интеллекта в различных сферах деятельности.
Несмотря на то, что разреженные механизмы внимания предлагают определенные улучшения в обработке длинных последовательностей, они зачастую сопряжены с компромиссами. Исследования показывают, что стремление к снижению вычислительной сложности может приводить к потере выразительности модели, ограничивая её способность улавливать тонкие зависимости в данных. Кроме того, реализация разреженных механизмов внимания нередко осложняется нестабильностью процесса обучения, требуя более тщательной настройки гиперпараметров и применения специальных методов регуляризации. Таким образом, хотя разреженное внимание и является перспективным направлением, необходимо дальнейшее развитие методов, позволяющих сохранить как эффективность, так и надежность обучения моделей, работающих с обширными текстовыми данными.
Гибридные архитектуры: Мост между эффективностью и выразительностью
Гибридные архитектуры, объединяющие преимущества трансформеров и рекуррентных нейронных сетей (RNN), представляют собой перспективное направление для эффективной обработки длинных последовательностей данных. Традиционно, RNN эффективно справляются с последовательной обработкой данных благодаря встроенной памяти, однако испытывают сложности с параллелизацией и обработкой глобального контекста. Трансформеры, напротив, обеспечивают высокую степень параллелизации и механизм внимания, но требуют значительных вычислительных ресурсов и могут быть менее эффективны при обработке очень длинных последовательностей. Комбинируя эти подходы, гибридные модели стремятся обеспечить оптимальный баланс между эффективностью, параллелизмом и способностью улавливать как локальные последовательные зависимости, так и глобальный контекст в данных.
Рекуррентные нейронные сети (RNN) эффективно обрабатывают последовательные данные благодаря встроенной памяти, позволяющей учитывать предыдущие состояния при обработке текущего элемента последовательности. В отличие от них, архитектуры Transformer обеспечивают высокую степень параллелизации вычислений, что значительно ускоряет обработку больших объемов данных. Механизм внимания (attention) в Transformer позволяет модели устанавливать зависимости между различными частями входной последовательности, не ограничиваясь последовательным доступом, как в RNN. Эта комбинация позволяет Transformer эффективно обрабатывать длинные последовательности и улавливать глобальные зависимости, в то время как RNN остаются полезными для задач, требующих учета последовательности и контекста в реальном времени.
Интеграция трансформеров и рекуррентных нейронных сетей (RNN) направлена на одновременное моделирование как последовательных зависимостей, так и глобального контекста в данных. RNN, благодаря своей внутренней памяти, эффективно обрабатывают последовательности, улавливая зависимости между соседними элементами. Трансформеры, в свою очередь, используют механизмы внимания для оценки значимости различных частей последовательности, обеспечивая доступ к глобальному контексту без ограничений, присущих RNN при обработке длинных последовательностей. Комбинируя эти подходы, гибридные архитектуры стремятся получить преимущества обоих типов сетей, позволяя моделировать сложные зависимости в данных, сохраняя при этом вычислительную эффективность и возможность параллельной обработки.
HyPE: Новая схема позиционного кодирования для гибридных моделей
Мы представляем HyPE — новую схему позиционного кодирования, разработанную для улучшения производительности гибридных архитектур, сочетающих в себе слои Transformer и RNN. HyPE объединяет преимущества RoPE (Rotary Positional Embeddings) и NoPE (No Positional Embeddings). RoPE используется для кодирования позиций во входных данных, обрабатываемых слоями Transformer, что обеспечивает эффективное моделирование относительных позиций токенов. В свою очередь, NoPE применяется для слоев RNN, где абсолютные позиции менее критичны, а использование позиционных кодировок может снизить производительность. Такое комбинированное применение позволяет HyPE эффективно обрабатывать последовательности различной длины и улучшать общую производительность гибридных моделей.
Схема позиционного кодирования HyPE использует преимущества RoPE (Rotary Positional Embeddings) для слоев Transformer и NoPE (Non-autoregressive Positional Embeddings) для слоев RNN. Применение RoPE в Transformer-слоях обеспечивает эффективное кодирование относительной позиции токенов, что критически важно для механизмов внимания. В свою очередь, NoPE в RNN-слоях позволяет эффективно обрабатывать последовательности переменной длины, улучшая обобщающую способность модели на более длинных последовательностях. Такое комбинированное использование позволяет оптимизировать передачу информации между различными типами слоев, повышая эффективность и производительность гибридных архитектур, особенно при работе с длинными последовательностями данных. RoPE(x, i) = R_i x, где R_i — матрица поворота, зависящая от позиции i.
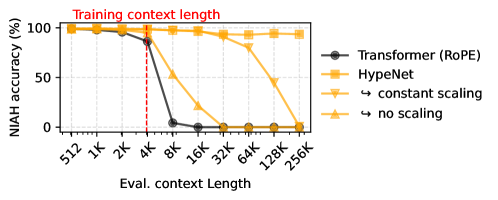
Для оптимизации производительности схемы позиционного кодирования HyPE применяются методы масштабирования внимания (Attention Scaling). Эти методы направлены на стабилизацию процесса обучения и повышение вычислительной эффективности, особенно при работе с длинными последовательностями. Масштабирование внимания корректирует значения весов внимания, предотвращая их экспоненциальный рост и связанные с этим проблемы, такие как неустойчивость градиентов и увеличение потребления памяти. Конкретные реализации масштабирования внимания могут включать деление весов на \sqrt{d}, где d — размерность вектора внимания, или использование других адаптивных стратегий, регулирующих масштаб в зависимости от длины последовательности и архитектуры модели.
HypeNet: Реализация и валидация
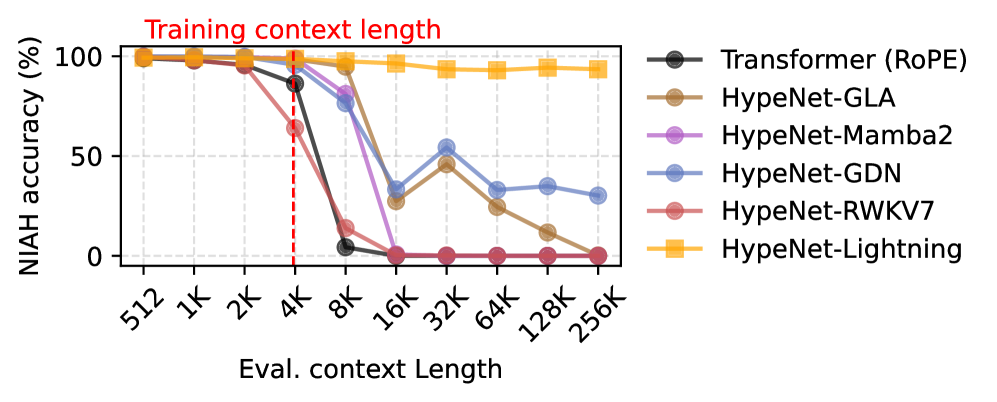
HypeNet представляет собой семейство гибридных моделей, основанных на архитектуре Qwen3, и реализует схему HyPE (Hybrid Parallel Expert). Данная схема позволяет добиться значительного улучшения в моделировании длинного контекста за счет комбинирования различных подходов к обработке последовательностей. В отличие от традиционных трансформеров, HypeNet использует параллельную обработку экспертов, что позволяет более эффективно использовать вычислительные ресурсы и повысить пропускную способность при работе с длинными входными данными. Реализация HyPE в HypeNet направлена на оптимизацию баланса между вычислительной сложностью и эффективностью моделирования длинных зависимостей в тексте.
Для повышения производительности HypeNet был использован метод HALO (Hybrid Approach to Learning from Observations) — процедура дистилляции знаний из предварительно обученных Transformer-моделей. HALO позволяет перенести знания, накопленные более крупными и сложными моделями, в HypeNet, что приводит к улучшению его способности к моделированию длинных контекстов. В процессе дистилляции, HypeNet обучается имитировать поведение более мощных моделей, что позволяет ему достичь сравнимой или даже превосходящей производительности при меньшем количестве параметров и вычислительных затратах. Этот подход особенно эффективен при работе с длинными последовательностями, где традиционные Transformer-модели испытывают трудности.
Оценка производительности HypeNet на бенчмарке NIAH продемонстрировала превосходство в задачах извлечения информации из длинных контекстов по сравнению с базовыми моделями. В частности, при длине контекста 512K, HypeNet обеспечивает до 3-кратного ускорения процесса декодирования и 3.4-кратного ускорения предварительного заполнения (prefilling) по сравнению с моделью Qwen3. Эти улучшения свидетельствуют о более эффективной обработке и извлечении релевантной информации из длинных последовательностей текста при использовании HypeNet.

Будущие направления: Эффективные и выразительные архитектуры
В настоящее время активно исследуется возможность объединения моделей пространства состояний, таких как Mamba, с гибридными архитектурами нейронных сетей. Данный подход направлен на достижение большей эффективности и масштабируемости при обработке данных. Идея заключается в том, чтобы использовать сильные стороны каждой из архитектур: способность Mamba эффективно моделировать длинные последовательности и обрабатывать большие объемы информации в сочетании с гибкостью и адаптивностью гибридных систем. Ученые стремятся создать модели, которые не только быстрее и экономичнее в плане вычислительных ресурсов, но и способны к более сложному и выразительному моделированию данных, открывая новые перспективы в задачах обработки естественного языка, компьютерного зрения и других областях искусственного интеллекта.
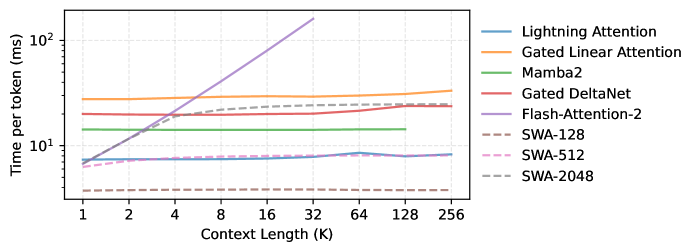
Механизмы линейного внимания с управляющими элементами, интегрированные в современные модели, демонстрируют значительный потенциал для повышения производительности и снижения вычислительных затрат. В отличие от традиционного внимания, требующего квадратичной сложности по отношению к длине последовательности, линейное внимание позволяет достичь линейной сложности, что критически важно при обработке длинных текстов или последовательностей данных. Управляющие элементы, или гейты, позволяют модели динамически регулировать поток информации, фокусируясь на наиболее релевантных частях входной последовательности и подавляя шум. Это приводит к более эффективному использованию вычислительных ресурсов и ускоряет процесс обучения и инференса, открывая возможности для создания более сложных и производительных моделей обработки естественного языка и других задач машинного обучения. O(n) сложность делает эти механизмы особенно привлекательными для приложений, требующих обработки больших объемов данных.
Техники оптимизации, такие как Flash Attention, остаются ключевыми для обработки длинных последовательностей данных в современных моделях машинного обучения. Flash Attention, в частности, существенно снижает потребность в памяти при вычислении механизма внимания, что позволяет обрабатывать последовательности, значительно превышающие возможности традиционных подходов. Вместо хранения всех промежуточных результатов в высокоскоростной памяти, Flash Attention использует стратегию разделения и повторного вычисления, минимизируя перемещение данных между памятью и процессором. Это приводит к значительному ускорению процесса обучения и инференса, особенно при работе с большими объемами текста, аудио или видео. Помимо Flash Attention, продолжаются исследования и разработки других методов оптимизации, направленных на снижение вычислительной сложности и повышение эффективности обработки длинных последовательностей, что открывает новые возможности для создания более мощных и масштабируемых моделей.
Представленная работа демонстрирует стремление к созданию систем, способных эффективно обрабатывать большие объемы информации, что перекликается с идеями о целостности и взаимосвязанности всех элементов системы. Как однажды заметила Ада Лавлейс: «То, что можно выразить в виде алгоритма, можно и выполнить». HALO и HypeNet, предложенные в статье, представляют собой алгоритмические решения, направленные на оптимизацию обработки длинных контекстов. Авторы подчеркивают важность не только повышения производительности, но и сохранения ясности структуры, что позволяет системе масштабироваться без потери эффективности. Особенно значимо, что исследование фокусируется на дистилляции и создании гибридных архитектур, что соответствует принципу проектирования систем, где каждая часть влияет на целое, а не является изолированным элементом.
Куда Ведет Этот Путь?
Представленная работа, словно аккуратно спроектированный квартал, демонстрирует возможность эволюционного развития архитектур обработки длинных последовательностей. HALO и HypeNet — это не финальная точка, а скорее, демонстрация принципа: инфраструктуру внимания можно усовершенствовать, не перестраивая весь “город” с нуля. Однако, остаётся вопрос о масштабируемости этих подходов к действительно экстремальным длинам контекста. Успешное дистилляционное обучение, безусловно, полезно, но его эффективность может зависеть от качества исходных данных и архитектуры “учителя”.
Пожалуй, более фундаментальный вопрос заключается в самой природе внимания. Существующие механизмы, включая гибридные, все еще имитируют процесс фокусировки, а не воспроизводят его глубинные принципы. Следующим шагом, вероятно, станет разработка архитектур, которые смогут не просто “выбирать” релевантную информацию, но и активно формировать контекст, подобно тому, как мозг интегрирует сенсорные данные.
Наконец, стоит задуматься о границах применимости этих моделей. Улучшение эффективности и производительности — это, несомненно, важно, но истинная ценность архитектур обработки длинных последовательностей проявится лишь в тех задачах, где они смогут действительно “понять” и “интерпретировать” сложные данные, а не просто обрабатывать их статистически. И здесь, возможно, потребуется более радикальный пересмотр существующих подходов.
Оригинал статьи: https://arxiv.org/pdf/2601.22156.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Моделирование биомолекул: новый импульс от нейросетей
- Квантовая механика: скрытый детерминизм?
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Отчетность об устойчивом развитии: Автоматизация анализа с помощью искусственного интеллекта
2026-02-01 06:47