Автор: Денис Аветисян
Новый тест позволяет оценить, насколько хорошо языковые модели сочетают поиск информации с логическим мышлением при решении научных задач.
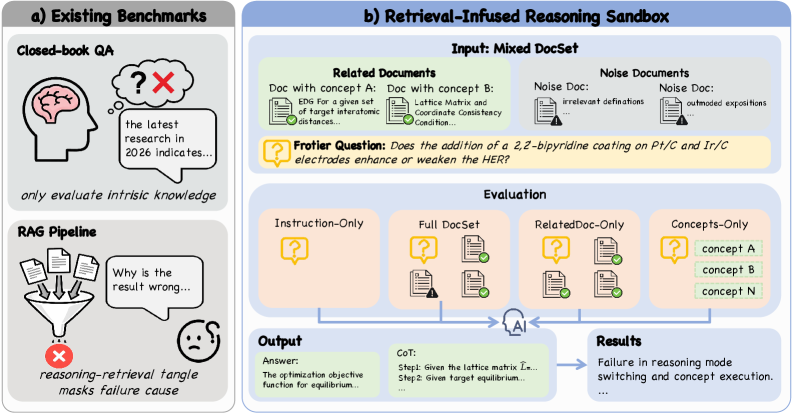
Представлен DeR2 — эталонный набор данных для раздельной оценки возможностей извлечения знаний и рассуждений в научных задачах, выявляющий ограничения современных больших языковых моделей в переключении режимов, последовательном выполнении процедур и координации концепций.
Несмотря на впечатляющие успехи больших языковых моделей в решении различных задач, остается неясным, способны ли они к осмысленному анализу принципиально новой научной информации. В работе, озаглавленной ‘Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities’, представлен контролируемый тестовый стенд DeR2, предназначенный для изоляции и оценки способности к логическому выводу на основе извлеченных данных, что позволяет отделить навыки поиска от навыков рассуждения. Эксперименты выявили значительные различия в производительности современных моделей, демонстрируя проблемы с переключением режимов работы и корректным применением концептуальных знаний. Какие новые подходы к оценке и обучению необходимы для создания действительно надежных систем, способных к глубокому научному анализу и синтезу?
Вызов Научного Мышления
Научные задачи, особенно сложные, требуют от исследователя не просто запоминания фактов или распознавания шаблонов, а глубокого анализа и синтеза информации. Успешное решение подобных проблем предполагает построение логических связей между различными понятиями, выдвижение гипотез и их проверку, а также умение экстраполировать существующие знания на новые, ранее не встречавшиеся ситуации. Простое воспроизведение заученных ответов или сопоставление с известными примерами оказывается недостаточным, поскольку реальные научные открытия часто связаны с выходом за рамки установленных представлений и поиском инновационных подходов. Таким образом, развитие критического мышления и способности к абстрактному рассуждению является ключевым фактором для продвижения в любой научной области.
Современные системы искусственного интеллекта часто сталкиваются с трудностями при интеграции внешних знаний в процессы рассуждений, что существенно ограничивает их способность решать новые, нестандартные задачи. Несмотря на впечатляющие успехи в области обработки больших данных и распознавания закономерностей, эти системы, как правило, испытывают затруднения при применении накопленных знаний к ситуациям, выходящим за рамки их изначального обучения. Проблема заключается не в отсутствии доступа к информации, а в неспособности эффективно связывать различные фрагменты знаний, делать логические выводы и адаптировать существующие модели к новым обстоятельствам. Это особенно заметно при решении задач, требующих понимания контекста, здравого смысла и способности к абстрактному мышлению, где простого сопоставления с имеющимися данными недостаточно для достижения адекватного результата.
Для эффективного решения сложных научных задач недостаточно простого доступа к информации; необходима система, способная интеллектуально применять полученные знания. Исследования показывают, что современные искусственные интеллекты часто терпят неудачу именно на этом этапе — в способности интегрировать внешние данные в процесс рассуждений и использовать их для решения новых, ранее не встречавшихся проблем. Такая система должна не только извлекать релевантную информацию из обширных баз данных, но и оценивать ее достоверность, устанавливать связи между различными фрагментами знаний и, что самое важное, творчески применять эти знания для генерации новых гипотез и решений. Успешная реализация подобного подхода позволит создать искусственный интеллект, способный к настоящему научному мышлению, а не просто к механическому выполнению заданных алгоритмов.

DeR2: Эталонная Оценка Рассуждений
DeR2 представляет собой специализированный бенчмарк, разработанный для оценки систем, использующих извлечение информации (retrieval) в процессе логических рассуждений. Ключевой особенностью DeR2 является разделение этапов извлечения и рассуждений, что позволяет изолированно оценить вклад каждого компонента в конечный результат. Такое разделение достигается посредством контролируемой среды, в которой можно точно определить, как внешние знания, полученные в процессе извлечения, влияют на способность системы решать научные задачи. Это позволяет исследователям точно оценить эффективность алгоритмов извлечения информации и их влияние на процесс рассуждений, что невозможно в традиционных бенчмарках, где эти два компонента часто тесно связаны.
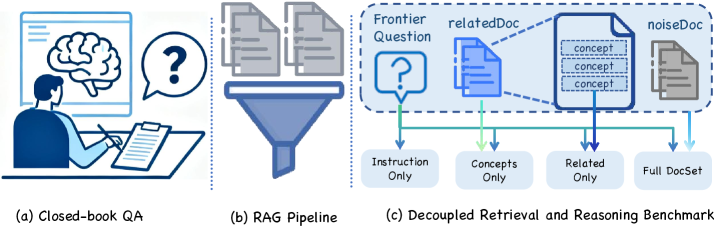
Для оценки производительности в различных условиях, связанных с наличием и характером внешних знаний, DeR2 использует четыре режима оценки. Режим Instruction-Only оценивает способность модели решать задачу, опираясь исключительно на инструкцию. Concepts-Only предполагает доступ к набору концепций, релевантных задаче, без использования полных документов. Related-Only предоставляет модели документы, содержащие информацию, связанную с задачей, но требующие извлечения необходимых концепций. Наконец, Full-Set комбинирует все три источника информации — инструкцию, концепции и релевантные документы — для комплексной оценки способности модели к рассуждениям с использованием внешних знаний. Комбинация этих режимов позволяет точно определить, как различные типы знаний влияют на общую производительность системы.
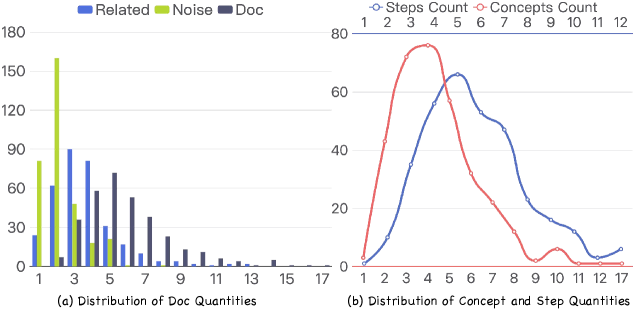
Результаты тестирования различных моделей на бенчмарке DeR2 демонстрируют значительный разброс в показателях точности, варьирующихся от приблизительно 49% до 75%. Данный диапазон указывает на существенные различия в способности моделей к решению задач, требующих сочетания извлечения информации и логического вывода. Наблюдаемая вариативность подчеркивает необходимость более глубокого анализа сильных и слабых сторон каждой модели для определения оптимальных стратегий улучшения производительности в задачах, основанных на извлечении и использовании внешних знаний.
Бенчмарк DeR2, используя наборы документов в различных настройках оценки, позволяет точно измерить эффективность интеграции внешней информации в процесс рассуждений. Анализ результатов выявил явление, названное “потерей при извлечении” (Retrieval Loss) — значительный разрыв между показателями производительности в режимах “Только концепции” (Concepts-Only) и “Только связанные документы” (Related-Only). Это указывает на трудности современных систем в точном извлечении и применении ключевых концепций из предоставленных документов, что ограничивает их способность к эффективному научному решению задач.
Конструкция эталонного набора данных DeR2 позволяет детально оценить сильные и слабые стороны современных систем в решении научных задач. Благодаря использованию различных настроек оценки — включая оценку только на основе инструкций, концепций, связанных документов и полного набора данных — DeR2 выявляет, как точно системы интегрируют внешнюю информацию в процесс рассуждений. Анализ результатов по этим настройкам позволяет определить, в каких конкретно типах задач системы демонстрируют наибольший успех, а где наблюдаются значительные затруднения, например, в извлечении релевантных концепций из предоставленных документов, что подтверждается значительным разрывом в производительности между настройками «Concepts-Only» и «Related-Only». Такой подход обеспечивает более глубокое понимание ограничений существующих моделей и направлений для дальнейших исследований в области научного искусственного интеллекта.
Теория Гравитации «Шмель»: Альтернативный Взгляд
Теория гравитации «Шмель» представляет собой модификацию стандартной общей теории относительности, вводя векторное поле, которое связывается с пространством-временем. В отличие от стандартной гравитации, описываемой тензором метрики, данная теория постулирует существование дополнительного векторного поля \phi_\mu , которое взаимодействует с геометрией пространства-времени. Это взаимодействие проявляется в модификации уравнений Эйнштейна и приводит к изменению гравитационных эффектов, особенно в экстремальных условиях или на космологических масштабах. Введение векторного поля позволяет рассматривать гравитацию не только как искривление пространства-времени, но и как взаимодействие с новым полем, что открывает возможности для объяснения различных астрофизических явлений и отклонений от предсказаний стандартной модели.
Теория гравитации «Шмель» включает в себя неминимальную связь (Non-Minimal Coupling) между гравитационным полем и материей, а также параметр, нарушающий Лоренц-инвариантность. Неминимальная связь предполагает, что взаимодействие гравитации с материей не ограничивается стандартным членом R в действии Эйнштейна-Гильберта, а включает в себя дополнительные члены, зависящие от скалярной кривизны и других инвариантов. Нарушение Лоренц-инвариантности вносит поправки к стандартным уравнениям гравитации, что потенциально позволяет объяснить наблюдаемые аномалии в космологических данных, такие как анизотропия космического микроволнового фона и ускоренное расширение Вселенной. Эти модификации могут также влиять на распространение гравитационных волн и процессы, происходящие в ранней Вселенной.
В рамках теории гравитации «Бамблби» ключевым элементом является взаимодействие со внешним связанным материйным полем, динамика которого описывается уравнениями Максвелла. Это означает, что электромагнитные поля не являются пассивными наблюдателями, а активно участвуют в гравитационных взаимодействиях, модифицируя стандартное гравитационное поле. Взаимодействие описывается через векторное поле, которое связывает метрику пространства-времени и электромагнитный тензор F_{\mu\nu}. Именно это взаимодействие, определяемое уравнениями Максвелла, позволяет теории объяснять некоторые космологические наблюдения, выходящие за рамки стандартной модели гравитации.
Для анализа сложных взаимодействий в теории гравитации «Бамблби» используются инструменты теории Шуберта и множеств спусков. Теория Шуберта, являющаяся разделом алгебраической геометрии, предоставляет методы для изучения топологеских свойств грассманианов и флаговых многообразий, что позволяет описывать конфигурационное пространство теории. Множества спусков, в свою очередь, представляют собой комбинаторные объекты, используемые для кодирования информации о перестановках и их циклах, что необходимо для вычисления амплитуд рассеяния и анализа симметрий теории. Комбинация этих математических инструментов позволяет проводить детальный анализ многомерных интегралов, возникающих при вычислении физических наблюдаемых в рамках данной модели, и эффективно исследовать ее предсказания.
Влияние на Научные Открытия и Искусственный Интеллект
Текущие достижения в области искусственного интеллекта подчеркивают необходимость создания систем, способных не только обрабатывать информацию, но и интегрировать внешние знания для решения сложных задач. Бенчмарк DeR2 и такие теоретические концепции, как гравитация Шмеля, демонстрируют, что успешное научное открытие требует от ИИ способности объединять факты из различных источников и применять их к новым, сложным вопросам. Способность ИИ к бесшовному включению внешних знаний имеет решающее значение для продвижения в областях, где требуются глубокое понимание и творческий подход, таких как космология и фундаментальная физика, где даже небольшие неточности в интерпретации данных могут привести к значительным ошибкам. Подобные системы позволят не просто автоматизировать существующие научные процессы, но и формулировать новые гипотезы и исследовать ранее недоступные области знания.
Анализ производительности моделей на бенчмарке DeR2 выявил неожиданный феномен: некоторые системы, в частности Gemini-3-Pro, демонстрируют снижение эффективности при переходе от режима, основанного исключительно на инструкциях (64.2%), к режиму, использующему полный набор данных (53.7%). Это указывает на существенные трудности в процессе переключения между различными режимами обработки информации. Очевидно, что добавление релевантных, но не напрямую связанных с задачей документов, не всегда способствует улучшению результатов, а может, напротив, приводить к ухудшению. Данный эффект подчеркивает необходимость разработки более совершенных механизмов, позволяющих моделям эффективно оценивать значимость входящей информации и отсеивать несущественные данные, обеспечивая тем самым стабильно высокую производительность в различных условиях.
Анализ результатов, полученных на бенчмарке DeR2, выявил любопытный эффект, получивший название “Потеря из-за шума”. Данный феномен проявляется в снижении производительности моделей при добавлении к релевантным документам нерелевантных. Разница между результатами, полученными при использовании только связанных документов и при использовании полного набора (включая “шум”), демонстрирует, насколько сильно нерелевантная информация может затруднить процесс логического вывода и анализа. Это подчеркивает критическую важность разработки надежных механизмов фильтрации, способных эффективно отсеивать посторонние данные и обеспечивать концентрацию на действительно значимой информации. Успешное решение этой задачи станет ключевым фактором в создании интеллектуальных систем, способных к точному и эффективному научному познанию.
Успехи в развитии искусственного интеллекта, способного эффективно интегрировать внешние знания в сложные процессы рассуждения, открывают принципиально новые перспективы для научных открытий. В частности, в таких областях как космология и фундаментальная физика, где обработка огромных массивов данных и выявление закономерностей являются ключевыми задачами, подобные системы могут значительно ускорить темпы инноваций. Способность ИИ не только решать существующие проблемы, но и формулировать новые вопросы, исследовать ранее недоступные территории, позволит ученым совершать прорывы, которые ранее казались невозможными. Это приведет к более глубокому пониманию Вселенной, ее структуры и фундаментальных законов, определяющих ее существование, а также к разработке новых технологий и материалов, основанных на этих знаниях.
Развитие искусственного интеллекта, способного к сложному рассуждению, открывает перспективы для создания инструментов, которые не просто решают существующие научные задачи, но и самостоятельно формулируют новые вопросы для исследований. Подобные системы смогут анализировать огромные массивы данных, выявлять неочевидные закономерности и предлагать гипотезы, выходящие за рамки текущих парадигм. Это позволит значительно ускорить темпы научных открытий, особенно в таких областях, как космология и фундаментальная физика, где поиск ответов требует обработки колоссальных объемов информации и креативного подхода к решению проблем. В перспективе, такие интеллектуальные системы смогут не просто автоматизировать рутинные задачи, но и стать полноценными партнерами ученых в процессе познания, расширяя границы нашего понимания Вселенной.
Исследование демонстрирует, что современные языковые модели испытывают трудности при переключении между поиском релевантной информации и её последующим логическим применением — ключевой аспект научного мышления. Эта неспособность к чёткому разделению этапов рассуждений и извлечения данных подтверждает идею о том, что кажущаяся сложность часто маскирует фундаментальную простоту. Как заметил Блез Паскаль: «Всё гениальное — просто». Декомпозиционный анализ, предложенный в данной работе, позволяет выявить узкие места в архитектуре LLM и подчеркивает важность разработки систем, в которых простота и масштабируемость являются приоритетными принципами. Недостаток координации концепций, выявленный в эксперименте, указывает на необходимость более элегантных и ясных решений в области извлечения и обработки знаний.
Куда Ведет Дорога?
Представленная работа выявляет любопытный парадокс: кажущаяся мощь больших языковых моделей часто маскирует хрупкость их способности к последовательному, декомпозиционному рассуждению. DeR2 не просто демонстрирует недостатки в переключении между поиском информации и её применением, но и подчеркивает фундаментальную проблему: масштабируется не серверная мощность, а ясность идеи. Текущие системы, по сути, имитируют понимание, а не демонстрируют его, подобно искусному механизму, повторяющему движения живого существа.
Необходимо переосмыслить архитектуру систем искусственного интеллекта, сместив акцент с простого увеличения количества параметров к созданию более элегантных и эффективных алгоритмов. Представляется важным не просто «накормить» модель данными, но и обучить её принципам процедурного исполнения и координации концепций. Экосистема искусственного интеллекта требует не просто большего количества компонентов, а более глубокого понимания их взаимодействия.
Будущие исследования должны быть направлены на разработку систем, способных не только извлекать информацию, но и адаптировать её к конкретной задаче, формируя последовательные и логичные цепочки рассуждений. Успех в этой области потребует отхода от «черных ящиков» и создания более прозрачных и интерпретируемых моделей, где структура определяет поведение, а не наоборот.
Оригинал статьи: https://arxiv.org/pdf/2601.21937.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Моделирование биомолекул: новый импульс от нейросетей
- Квантовая механика: скрытый детерминизм?
- Поймать Мгновение: Эволюция Детекторов Времени
2026-02-01 10:00