Автор: Денис Аветисян
Исследователи представили ChipBench — комплексный инструмент для оценки возможностей больших языковых моделей в автоматизации проектирования микросхем.

ChipBench позволяет всесторонне протестировать модели генерации, отладки и создания эталонных моделей для разработки микросхем, выявляя текущие ограничения и определяя направления для дальнейших исследований.
Несмотря на растущий потенциал больших языковых моделей (LLM) в аппаратном проектировании, существующие бенчмарки зачастую не отражают реальные промышленные задачи и быстро достигают насыщения. В данной работе представлена новая комплексная методика оценки, ‘ChipBench: A Next-Step Benchmark for Evaluating LLM Performance in AI-Aided Chip Design’, предназначенная для всестороннего анализа LLM в задачах генерации кода Verilog, отладки и создания эталонных моделей. Полученные результаты демонстрируют существенные ограничения современных LLM, таких как Claude-4.5-opus, в решении этих задач, показывая низкий процент успешной генерации Verilog (30.74%) и Python-моделей (13.33%). Сможет ли предложенный автоматизированный инструментарий для генерации обучающих данных стать основой для существенного улучшения производительности LLM в области автоматизированного проектирования микросхем?
Растущий интерес к LLM в аппаратном проектировании
В последнее время наблюдается растущий интерес к применению больших языковых моделей (LLM) в автоматизации задач проектирования аппаратного обеспечения. Исследователи и инженеры активно изучают возможности LLM для повышения эффективности на различных этапах, от разработки спецификаций до генерации кода и верификации. Перспектива автоматизации рутинных операций позволяет значительно сократить время, необходимое для создания новых чипов и электронных устройств, а также снизить вероятность ошибок, возникающих при ручном проектировании. Подобный подход обещает революционизировать индустрию, сделав процесс разработки более быстрым, экономичным и инновационным, открывая новые возможности для создания сложных и высокопроизводительных систем.
Несмотря на растущий интерес к применению больших языковых моделей (LLM) в автоматизации разработки аппаратного обеспечения, их эффективность в решении сложных задач верификации и генерации схем остается ограниченной. Исследования показывают, что современные LLM демонстрируют лишь 37.41% точность при работе с бенчмарком ChipBench, что указывает на необходимость разработки надежных методологий оценки и более специализированных тестовых наборов. Отсутствие адекватных критериев и стандартизированных тестов затрудняет объективное сравнение различных моделей и выявление их слабых мест, препятствуя дальнейшему прогрессу в данной области. Таким образом, создание комплексных бенчмарков, учитывающих специфику аппаратного обеспечения, является ключевым фактором для раскрытия потенциала LLM в проектировании и верификации микросхем.
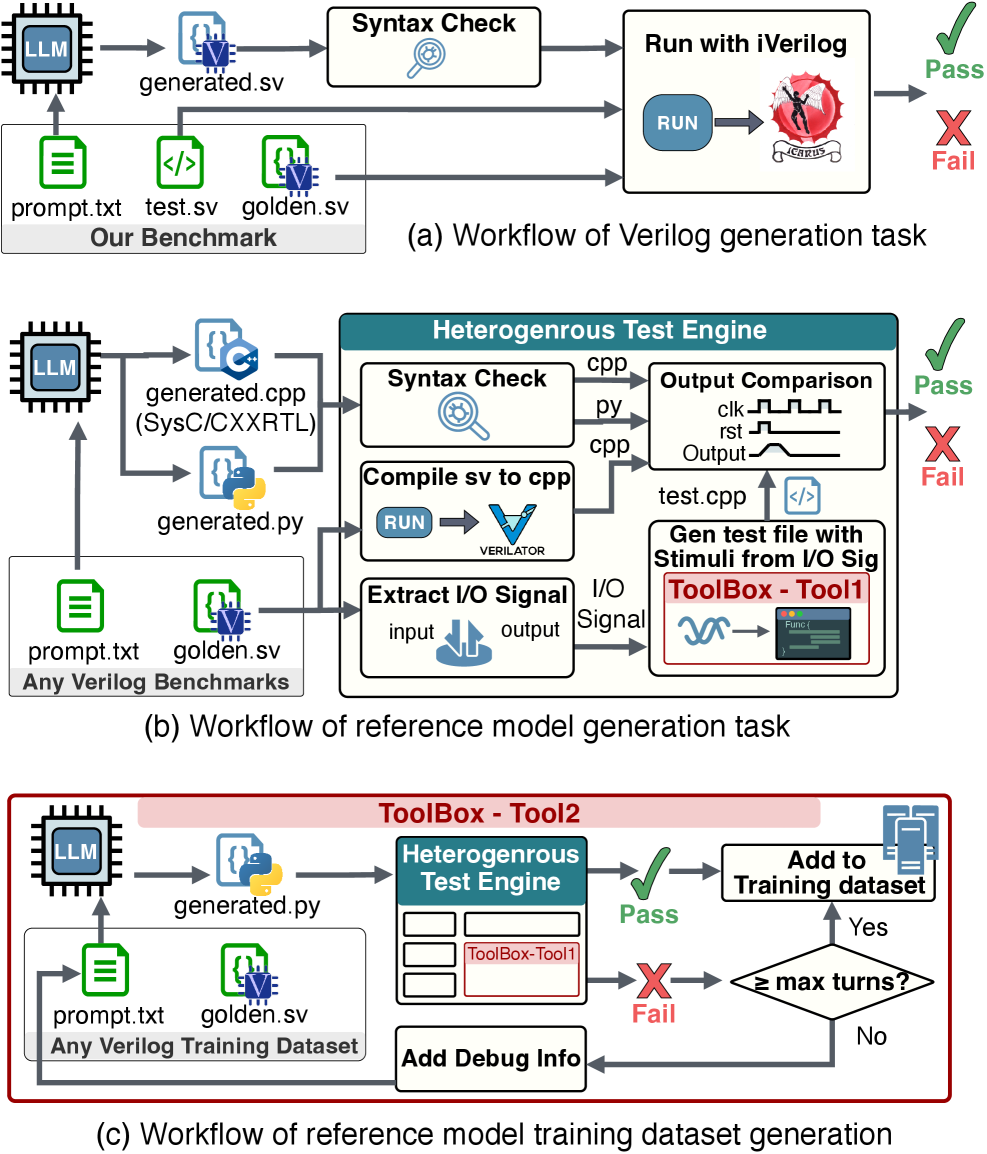
ChipBench: Комплексная платформа для оценки аппаратного обеспечения
ChipBench представляет собой комплексную платформу для оценки возможностей больших языковых моделей (LLM) в области разработки аппаратного обеспечения. В отличие от существующих бенчмарков, ChipBench объединяет в себе этапы генерации кода на Verilog, отладки и создания эталонной модели. Это позволяет оценить не только способность LLM к синтаксически правильному коду, но и умение создавать функционально корректные и отлаживаемые аппаратные проекты, охватывая весь цикл разработки. Платформа предоставляет унифицированную среду для комплексной оценки, что позволяет более точно определить сильные и слабые стороны различных LLM в контексте аппаратного дизайна.
Тест ChipBench выходит за рамки простого завершения кода, требуя от больших языковых моделей (LLM) понимания сложных нюансов аппаратного проектирования и логической корректности. Результаты показывают значительный разрыв в производительности: модель MAGE достигает всего 37.41% точности на ChipBench, в то время как на VerilogEval V2 она демонстрирует 95%. Этот контраст указывает на то, что LLM испытывают трудности при переходе от решения простых задач по завершению кода к более сложным задачам, требующим глубокого понимания принципов аппаратного обеспечения.
Модули ChipBench в среднем содержат 47.8 строк кода и 323.3 элемента, что значительно превышает показатели VerilogEval V2, где средние значения составляют 16.1 строку кода и 31.4 элемента. Данное различие в размере и сложности указывает на то, что ChipBench требует от оцениваемых моделей более глубокого понимания аппаратного обеспечения и способности работать с более крупными и сложными проектами, в отличие от VerilogEval V2, ориентированного на более простые задачи.
Автоматизированная генерация эталонных моделей и верификация
Автоматизированный инструментарий упрощает создание эталонных моделей, поддерживая генерацию на языках SystemC и CXXRTL. Это позволяет автоматизировать процесс разработки, который традиционно требовал значительных ручных усилий. Поддерживаемые языки, SystemC и CXXRTL, широко используются в индустрии для моделирования и верификации аппаратного обеспечения, обеспечивая совместимость с существующими рабочими процессами и инструментами. Инструментарий позволяет генерировать эталонные модели, необходимые для проведения верификации разрабатываемых аппаратных блоков и систем, снижая время и затраты на разработку.
Инструментарий автоматизации использует модель DeepSeek-V3.2 для генерации обучающих наборов данных, предназначенных для повышения качества и эффективности верификации эталонных моделей. Применение DeepSeek-V3.2 позволяет автоматизировать процесс создания данных, необходимых для обучения и улучшения алгоритмов, отвечающих за генерацию эталонных моделей. Это, в свою очередь, способствует повышению надежности и точности верификации аппаратного обеспечения за счет более качественных и репрезентативных эталонных моделей, используемых в процессе.
Несмотря на автоматизацию процесса, создание точных эталонных моделей остается сложной задачей. Эксперименты показали, что модель Claude-4.5-opus демонстрирует всего 15.93% успешных попыток (Pass@1) при генерации эталонных моделей на языке Python. Даже наиболее эффективные модели, используемые для генерации эталонных моделей для сложных модулей, достигают показателя менее 50% Pass@1, что указывает на существенные ограничения автоматизированных инструментов в обеспечении высокой точности и надежности генерируемого кода.
Автоматизированный подход к созданию эталонных моделей значительно сокращает трудозатраты, связанные с ручной разработкой и отладкой, что напрямую влияет на ускорение жизненного цикла верификации аппаратного обеспечения. Традиционно, создание эталонных моделей требовало значительных временных и человеческих ресурсов, особенно для сложных модулей. Автоматизация позволяет генерировать эти модели быстрее и с меньшими усилиями, освобождая инженеров для решения более сложных задач и сокращая общее время, необходимое для завершения процесса верификации. Это особенно важно в условиях растущей сложности современных аппаратных систем и необходимости быстрого вывода продукции на рынок.
LLM в действии: Отладка и валидация аппаратных проектов
Современные платформы, такие как MAGE, активно используют большие языковые модели (LLM) для автоматической генерации кода Verilog, что открывает новые возможности в проектировании аппаратного обеспечения. Исследования показывают, что применение LLM позволяет добиться существенного прироста производительности на этапах разработки, о чём свидетельствуют результаты тестирования на бенчмарке ChipBench. Данный бенчмарк, специально разработанный для оценки эффективности LLM в задачах, связанных с проектированием цифровых схем, демонстрирует, что автоматическая генерация кода с использованием LLM способна значительно ускорить процесс создания и оптимизации аппаратных решений, хотя и требует дальнейшей доработки для решения более сложных задач.
Несмотря на значительный прогресс в генерации кода, современные большие языковые модели, такие как GPT-4o, демонстрируют ограниченные возможности в решении сложных задач отладки аппаратного обеспечения. Исследования, проведенные с использованием эталонного набора ChipBench, показали крайне низкий показатель успешности — всего 10.37% Pass@1. Это указывает на то, что, хотя модели способны создавать синтаксически верный код на Verilog, их способность выявлять и исправлять функциональные ошибки в сложных аппаратных проектах остается крайне недостаточной. Данный результат подчеркивает необходимость разработки специализированных методов и инструментов для повышения надежности и эффективности LLM в области верификации и отладки цифровых схем.
Анализ формы сигнала, или вейвформ-анализ, играет ключевую роль в подтверждении правильности функционирования сгенерированного кода Verilog. Этот метод позволяет детально исследовать изменения электрических сигналов во времени, выявляя любые отклонения от ожидаемого поведения. В процессе вейвформ-анализа сравниваются полученные сигналы с эталонными, что позволяет оперативно обнаруживать логические ошибки, проблемы с синхронизацией или другие дефекты в аппаратном обеспечении. Эффективный вейвформ-анализ не просто подтверждает работоспособность схемы, но и предоставляет ценную информацию для оптимизации дизайна и повышения его надежности, особенно в контексте автоматической генерации кода с использованием больших языковых моделей.
Для всесторонней оценки возможностей больших языковых моделей (LLM) в задачах проектирования цифровых схем на уровне передачи регистров (RTL) разработан специализированный набор тестов — RTLLM. Этот бенчмарк позволяет детально проанализировать способность LLM понимать и генерировать корректный код на языке Verilog, а также выявлять слабые места в алгоритмах отладки. Использование RTLLM не только способствует количественной оценке производительности LLM в сложных RTL-задачах, но и предоставляет ценную информацию для улучшения архитектуры и обучения моделей, что в конечном итоге повышает надежность и эффективность процесса верификации аппаратного обеспечения.
Исследование, представленное в статье, подчеркивает важность целостного подхода к разработке сложных систем, таких как микросхемы. Подобно тому, как нельзя починить одну деталь, не понимая работу целого механизма, современные языковые модели демонстрируют ограниченные возможности в контексте AI-помощника при разработке чипов, если не учитывается общая архитектура и логика. Как заметил Дональд Кнут: «Преждевременная оптимизация — корень всех зол». Это особенно актуально в данном исследовании, поскольку попытки создать отдельные модули без понимания общей структуры приводят к системам, держащимся на «костылях» и требующим постоянного исправления, а не к элегантному и надежному решению.
Что дальше?
Представленный анализ, воплощенный в ChipBench, обнажил неожиданную хрупкость современных больших языковых моделей в сфере проектирования микросхем. Подобно тщательно спланированному городу, где незначительная ошибка в инфраструктуре приводит к коллапсу всей системы, текущие модели демонстрируют ограниченность в понимании семантики Verilog и способности к отладке сложных конструкций. Очевидно, что простого увеличения масштаба недостаточно; требуется фундаментальный сдвиг в архитектуре и методах обучения.
Вместо слепого наращивания параметров, необходимо сосредоточиться на создании моделей, способных к структурному пониманию, аналогично тому, как опытный инженер читает схему. Акцент должен быть сделан на эволюционном развитии, позволяющем постепенно адаптировать и совершенствовать систему без необходимости полной перестройки квартала. Следующим шагом видится разработка более компактных, но эффективных моделей, способных к логическому выводу и самокоррекции.
Подобно тому, как в биологических системах форма определяет функцию, структура модели должна отражать сложность задачи проектирования. Будущие исследования должны быть направлены на создание моделей, способных не просто генерировать код, но и понимать его последствия, предвидеть потенциальные ошибки и предлагать оптимальные решения. Иначе, мы рискуем создать лишь иллюзию искусственного интеллекта, красивую, но непрактичную.
Оригинал статьи: https://arxiv.org/pdf/2601.21448.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Квантовая механика: скрытый детерминизм?
- Сопоставление объектов в разных ракурсах: новый подход с использованием ИИ
2026-02-01 10:05