Автор: Денис Аветисян
Новое исследование показывает, как современные языковые модели помогают понять механизмы влияния родного языка на изучение иностранного.
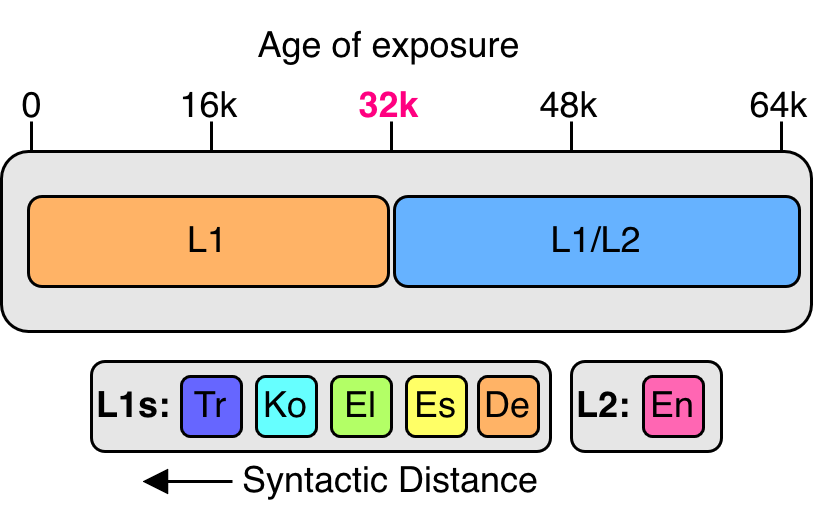
Исследование посвящено изучению двунаправленного влияния структур родного языка на обработку и освоение второго языка с использованием нейронных сетей.
Несмотря на центральную роль межъязыкового влияния в билингвальной практике, результаты эмпирических исследований часто оказываются противоречивыми из-за трудностей контроля экспериментальных переменных. В данной работе, озаглавленной ‘Language Models as Artificial Learners: Investigating Crosslinguistic Influence’, предпринята попытка систематического изучения межъязыкового влияния с использованием языковых моделей в качестве контролируемых статистических обучающихся систем. Полученные результаты демонстрируют, что доминирование и уровень владения первым языком являются ключевыми предикторами межъязыкового влияния, при этом общие синтаксические структуры активируются двунаправленно, а влияние несовпадающих структур носит асимметричный характер. Могут ли языковые модели стать полноценным вычислительным инструментом для углубленного понимания механизмов билингвального овладения языком и формирования новых теоретических моделей?
Разум Двуязычия: Вызов для Машинного Сознания
Понимание того, как человек обрабатывает несколько языков, является ключевым для развития современных систем обработки естественного языка, однако существующие языковые модели зачастую сталкиваются с трудностями при анализе явлений, связанных с влиянием разных языков друг на друга. В то время как человек легко переключается между языками и использует знания из одного языка при понимании и генерации текста на другом, современные модели, как правило, рассматривают каждый язык изолированно. Это приводит к ошибкам при переводе, неточностям в понимании многоязычного контента и общей неспособности адекватно моделировать когнитивные процессы, происходящие в многоязычном мозге. Преодоление этих ограничений требует разработки принципиально новых подходов к обучению языковых моделей, способных учитывать и эффективно использовать взаимосвязи между различными языками.
Традиционные языковые модели, как правило, рассматривают каждый язык обособленно, что не позволяет адекватно отразить сложность когнитивных процессов, происходящих у билингвов. В то время как человеческий мозг, оперируя двумя или более языками, постоянно устанавливает связи и взаимовлияния между ними, существующие модели зачастую игнорируют эти взаимодействия. Это приводит к неточностям при переводе, затруднениям в понимании контекста и неспособности эффективно обрабатывать смешанную речь, характерную для билингвов. Игнорирование перекрестных языковых влияний (CLI) ограничивает возможности создания действительно интеллектуальных систем обработки естественного языка, способных отразить всю глубину и нюансы человеческого билингвизма.
Для адекватного моделирования билингвального мышления требуется принципиально новый подход к обучению языковых моделей, который явно учитывает явление кросс-лингвистического влияния (CLI). Традиционные методы, рассматривающие языки изолированно, оказываются неспособны отразить сложную динамику взаимодействия между ними в сознании двуязычного человека. Новые модели стремятся интегрировать механизмы, позволяющие одному языку модулировать обработку другого, учитывая как активацию лексических единиц, так и грамматических структур. Такой подход предполагает не просто параллельное обучение на нескольких языках, а создание единой архитектуры, способной улавливать тонкие взаимосвязи и взаимное влияние между ними, что, в свою очередь, открывает перспективы для разработки более реалистичных и эффективных систем обработки естественного языка.

Билингвальное Обучение: Симуляция Языкового Взаимодействия
Для обучения модели используется билингвальный подход, при котором трансформерная языковая модель (GPT2) одновременно подвергается воздействию двух языков. Данный режим позволяет модели формировать кросс-лингвистические представления, то есть общие представления о языковых структурах, не зависящие от конкретного языка. Одновременное обучение на двух языках способствует развитию способности модели к переносу знаний между языками и обобщению лингвистических закономерностей, что потенциально улучшает ее производительность в задачах, требующих понимания и генерации текста на обоих языках.
Для обучения билингвальной модели используется корпус OSCAR, предоставляющий обширный многоязычный набор данных, включающий тексты на различных языках, собранные из сети Интернет. Для эффективного управления словарём и обработки текста применяется токенизатор SentencePiece, который осуществляет сегментацию текста на подсловные единицы (токены), что позволяет уменьшить размер словаря и улучшить обобщающую способность модели, особенно при работе с языками, имеющими сложную морфологию или большое количество редких слов. Такой подход обеспечивает эффективную обработку и представление многоязычных данных, необходимых для обучения кросс-лингвистических представлений.
В ходе обучения билингвальной модели наблюдается, что возраст внедрения второго языка является ключевым параметром, влияющим на лингвистическое доминирование и уровень владения языками (доминирование L1, владение L2). Анализ скрытых состояний модели при обработке второго языка (L2) показал, что отношение токенов первого языка (L1) к общему числу токенов в этих состояниях увеличивается с увеличением возраста, когда второй язык был введен в процесс обучения. Это свидетельствует об усилении влияния первого языка (L1) на обработку второго языка (L2) по мере увеличения времени, прошедшего после его внедрения, что может ограничивать развитие независимых представлений для L2.

Декодирование Кросс-Лингвистического Влияния: Методы и Доказательства
Для декодирования внутренних представлений языковой модели (LM) используется методика LogitLens, позволяющая количественно оценить вклад каждого языка в процессе обработки. LogitLens анализирует выходные вероятности LM для каждого токена, определяя степень активации лингвистических признаков, характерных для конкретного языка. Это позволяет выявить перекрестную языковую активацию — то есть, насколько признаки одного языка влияют на обработку другого. Полученные количественные показатели позволяют объективно оценить степень и характер влияния исходного языка на целевой язык во время обработки текста, предоставляя информацию о механизмах кросс-лингвистического влияния (CLI).
Для дополнения анализа используется кросс-лингвистический прайминг — метод, основанный на облегчении обработки структур в одном языке посредством предварительного воздействия структур из другого языка. Для генерации сопоставимых стимулов, необходимых для прайминга, используется модель машинного перевода NLLB. Этот подход позволяет создать пары предложений, эквивалентные по смыслу, но принадлежащие разным языкам, что необходимо для оценки степени влияния родного языка (L1) на обработку целевого языка.
Оценка проводилась на базе эталонных наборов данных BLiMP и FCE для анализа грамматической точности и выявления особенностей, связанных с родным языком (L1), что позволило получить конкретные доказательства межъязыкового влияния (CLI). Наблюдается зависимость эффекта CLI (изменение точности) от синтаксической дистанции: для языков, таких как немецкий и испанский, зафиксирован положительный перенос, в то время как для турецкого и корейского — отрицательный. В частности, использование прайминга позволило добиться значительного улучшения результатов по 9 явлениям в тесте BLiMP для немецкого языка, в то время как для турецкого — лишь по 2.
Соперничающие Теории Двуязычного Представления
Результаты исследования демонстрируют, что языковые модели (LM) способны проявлять характеристики как единой, так и модульной синтаксической организации. Данные подтверждают положения как теории общего синтаксиса, предполагающей использование общих механизмов для обработки разных языков, так и теории раздельного, но связанного синтаксиса, согласно которой языки обрабатываются отдельными, но взаимодействующими модулями. Это указывает на то, что языковые модели не придерживаются строго одной из этих концепций, а демонстрируют гибкость в организации синтаксических представлений, адаптируясь к особенностям конкретных языковых пар и их взаимосвязи. Наблюдаемая способность к проявлению признаков обеих теорий подчеркивает сложность синтаксической организации в языковых моделях и необходимость дальнейшего изучения механизмов, определяющих выбор между унифицированным и модульным подходом.
Исследования показывают, что степень совпадения порядка слов в разных языках, наряду с синтаксической удаленностью между ними, оказывает существенное влияние на степень кросслингуальной интерференции (CLI). Выяснилось, что чем больше языки схожи в структуре предложений, тем сильнее проявляется CLI, указывая на то, что языковая модель склонна использовать общие синтаксические представления. Напротив, при увеличении синтаксической дистанции между языками, наблюдается ослабление CLI, что свидетельствует о тенденции модели к формированию более раздельных, модульных представлений для каждого языка. Таким образом, CLI не является универсальным явлением, а представляет собой динамический процесс, зависящий от лингвистических характеристик языков и архитектурных особенностей модели, что позволяет предположить гибкость в способах представления информации в нейронных сетях.
Исследования показывают, что кросслингвальная интерференция (CLI) — это не единое явление, а сложное взаимодействие лингвистических характеристик и архитектурных особенностей языковых моделей. В частности, обнаружено, что степень перекрытия нейронов, специфичных для второго языка, уменьшается с увеличением синтаксической дистанции между языками. Данная закономерность коррелирует с наблюдаемыми эффектами CLI, указывая на то, что языковые модели адаптируют свои стратегии обработки в зависимости от степени структурного сходства между языками. Таким образом, CLI представляет собой динамический процесс, формирующийся под влиянием как лингвистических факторов, так и внутренней организации языковой модели.
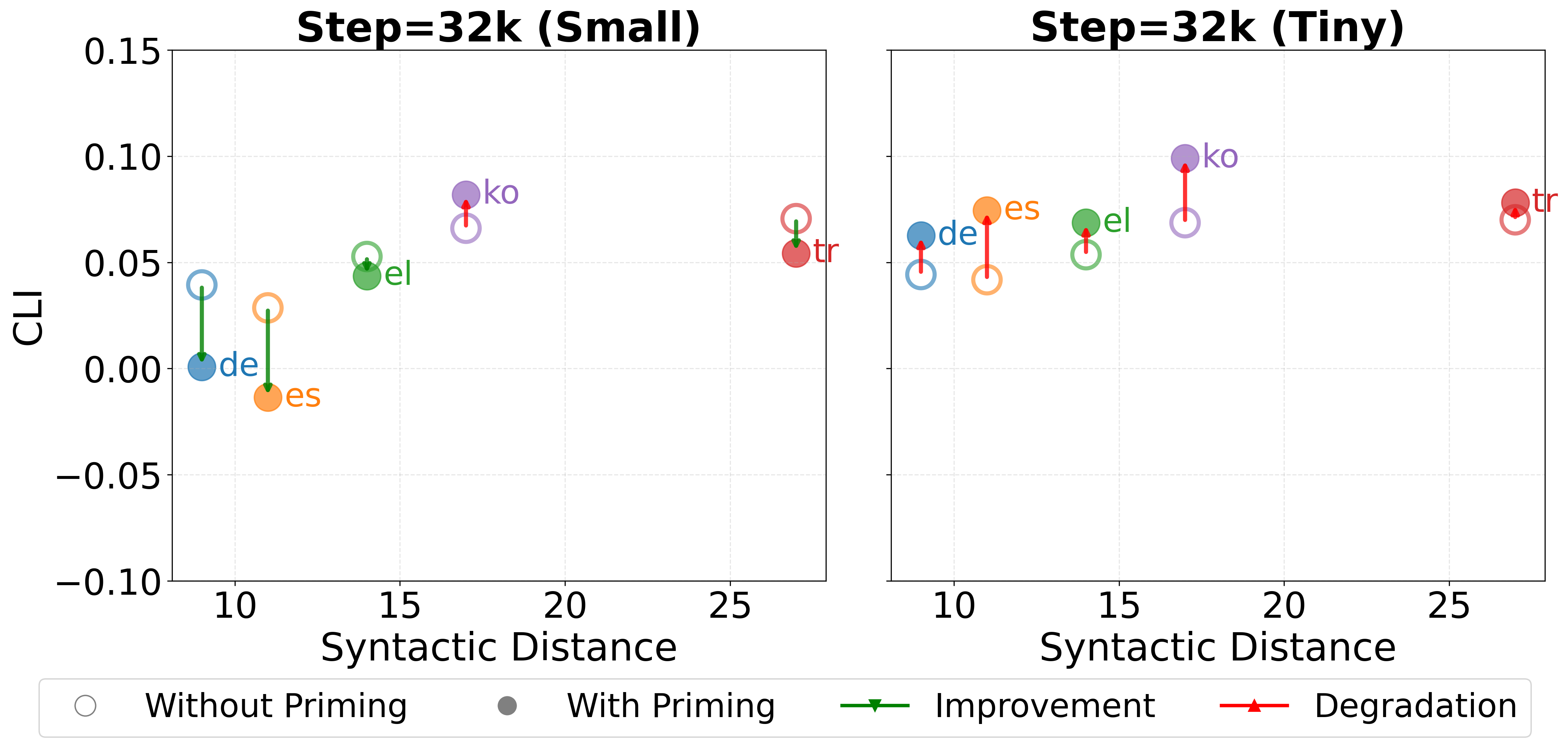
Исследование демонстрирует, что языковые модели, будучи искусственными обучающимися системами, позволяют проследить гибридное влияние родного языка на освоение нового. При этом, как показывает работа, общие структуры обрабатываются в обоих направлениях, формируя двусторонний перенос знаний. Необщие же структуры демонстрируют асимметричный перенос, что подтверждает сложность взаимодействия языковых систем. Как однажды заметила Барбара Лисков: «Изменение интерфейса — это изменение контракта.» Этот принцип применим и к языкам: изменение структуры одного языка (интерфейса) неизбежно влияет на восприятие и обработку другого, формируя новый «контракт» между ними. Изучение этого взаимодействия открывает новые горизонты в понимании билингвизма и когнитивных процессов.
Куда же дальше?
Представленное исследование, хоть и проливает свет на механизмы межъязыкового влияния, лишь подчёркивает сложность этой самой системы. Языковые модели, как инструменты, демонстрируют свою способность моделировать аспекты билингвизма, но остаются лишь приближением к реальному когнитивному процессу. Необходимо помнить: имитация не равно пониманию. Особого внимания требует исследование нелинейных эффектов — как взаимодействие между языками меняется в зависимости от контекста, когнитивной нагрузки и индивидуальных особенностей обучающегося.
Очевидным направлением представляется расширение спектра исследуемых языковых пар. Ограничение фокусом на доминирующих структурах и асимметричном переносе оставляет за кадром множество нюансов, особенно в отношении языков, существенно различающихся по типологии. Следует также признать, что текущие модели, в силу своей архитектуры, склонны к упрощению, игнорируя вероятностную природу языка и роль случайных факторов. Истинная безопасность в понимании — это прозрачность этих ограничений, а не их маскировка.
В конечном счёте, задача состоит не в создании идеальной модели билингва, а в реверс-инжиниринге когнитивных механизмов, лежащих в основе этой способности. Понимание принципов, управляющих межъязыковым взаимодействием, позволит не просто предсказывать, но и, возможно, оптимизировать процесс овладения новыми языками — взломать систему изнутри, используя её же инструменты.
Оригинал статьи: https://arxiv.org/pdf/2601.21587.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Моделирование биомолекул: новый импульс от нейросетей
- Квантовая механика: скрытый детерминизм?
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Защита от вредоносных данных в федеративном обучении: новый подход
2026-02-01 11:41