Автор: Денис Аветисян
Новое исследование показывает, что оптимальная длина аудиосегментов критически важна для эффективного поиска и идентификации аудиоматериалов.
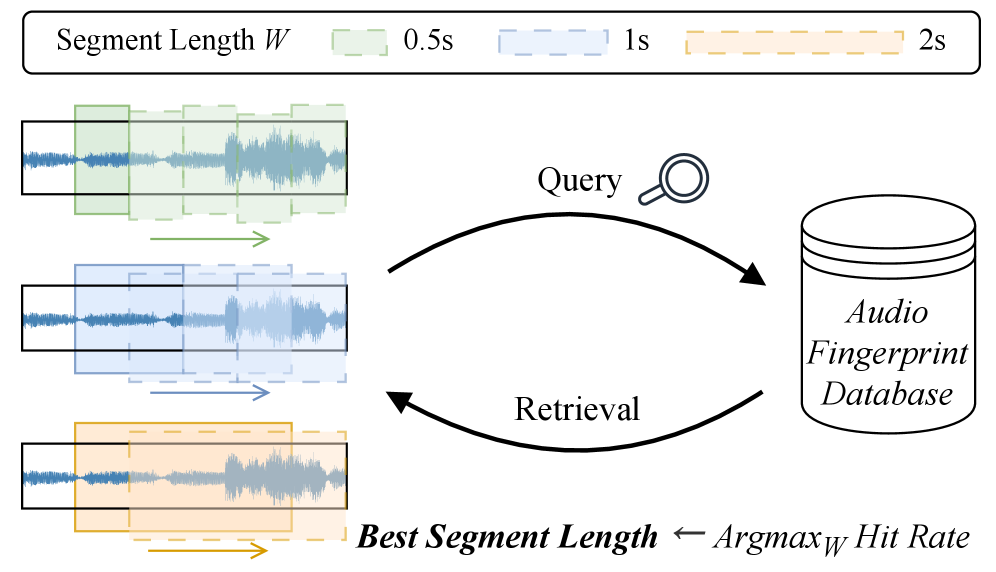
Изучение влияния длины сегментов на производительность систем аудио-идентификации, включая использование больших языковых моделей для определения оптимальных параметров.
Несмотря на широкое распространение систем идентификации аудио по отпечаткам, вопрос оптимальной длины сегментов для анализа звуковых сигналов часто остается без должного внимания. В работе ‘Segment Length Matters: A Study of Segment Lengths on Audio Fingerprinting Performance’ проведено исследование влияния длины сегментов на эффективность нейронных систем аудио-идентификации. Полученные результаты демонстрируют, что использование коротких сегментов (0.5 секунды) обеспечивает более высокую точность, особенно при работе с короткими запросами, а также что языковая модель GPT-5-mini способна эффективно рекомендовать оптимальные параметры сегментации. Возможно ли дальнейшее повышение производительности систем аудио-идентификации за счет адаптивной длины сегментов, основанной на характеристиках конкретного звукового сигнала?
Суть аудиоидентификации: вызовы и ограничения
Эффективная идентификация аудиоконтента, осуществляемая посредством создания и сопоставления «аудиоотпечатков», играет ключевую роль в современных системах управления цифровыми правами, автоматическом определении музыкальных произведений и обнаружении нелегального контента. Однако, несмотря на значительный прогресс в этой области, существуют существенные ограничения, препятствующие достижению высокой точности и скорости работы. Эти «узкие места» связаны с такими факторами, как искажения сигнала, вызванные сжатием, шумами и другими помехами, а также с вариациями во времени воспроизведения. Преодоление этих трудностей является важной задачей, требующей разработки новых алгоритмов и методов обработки аудиоданных, способных эффективно справляться с реальными условиями эксплуатации систем идентификации.
Традиционные методы аудио-идентификации сталкиваются с существенными трудностями при обработке реальных аудиозаписей. Изменения в качестве звука, вызванные сжатием, шумами или эхом, а также колебания скорости воспроизведения или временные искажения, приводят к снижению точности идентификации. Это особенно заметно при сравнении записей, полученных из разных источников или записанных с использованием различного оборудования. Неспособность эффективно справляться с этими вариациями ограничивает применимость существующих алгоритмов в практических сценариях, таких как автоматическое распознавание музыки, обнаружение плагиата или мониторинг контента в сети, где аудиозаписи часто подвергаются различным видам обработки и искажений.
Исследования показали, что продолжительность аудиофрагментов, используемых в процессе создания “отпечатков” звука, является ключевым параметром, существенно влияющим на точность идентификации. В частности, оптимальной длиной сегмента для достижения максимальной производительности признана продолжительность в 0,5 секунды. Более короткие отрезки могут оказаться недостаточно информативными для надежного сопоставления, в то время как более длинные — снижают скорость обработки и увеличивают вероятность ошибок, вызванных временными искажениями или шумами. Таким образом, тщательный подбор длительности сегмента, с акцентом на 0,5 секунды, является важным фактором для создания эффективных и надежных систем аудиоидентификации.

NAFP: Современный подход к аудио-отпечаткам
Нейронное Аудио Фильтрование (NAFP) представляет собой современный подход к созданию аудио-отпечатков, основанный на методах контрастного обучения. В отличие от традиционных методов, NAFP генерирует компактные векторные представления — эмбеддинги — аудиосигналов, оптимизированные для устойчивости к различным искажениям и шумам. Контрастное обучение позволяет модели научиться различать схожие аудиофрагменты и идентифицировать уникальные характеристики, что обеспечивает высокую точность при поиске и сопоставлении аудиозаписей. Такой подход позволяет создавать более надежные и эффективные аудио-отпечатки по сравнению с методами, основанными на ручном проектировании признаков.
В основе Neural Audio Fingerprinting (NAFP) лежит использование Mel-спектрограмм для извлечения признаков из аудиосигналов. Mel-спектрограмма представляет собой визуальное представление частотного состава аудиосигнала во времени, полученное путем применения Mel-фильтров к результатам кратковременного преобразования Фурье. Этот метод позволяет эффективно анализировать аудио в частотно-временной области, выделяя доминирующие частоты и их изменения во времени. Использование Mel-спектрограмм, в отличие от обычных спектрограмм, учитывает особенности человеческого восприятия звука, что повышает эффективность системы в задачах распознавания и идентификации аудио.
Эффективность Neural Audio Fingerprinting (NAFP) напрямую зависит от выбранной длины сегмента аудиосигнала, используемого для формирования признаков. Экспериментальные данные показывают, что оптимальная производительность достигается при длительности сегмента в 0.5 секунды. Более короткие или длинные сегменты приводят к снижению точности сопоставления аудио, что обусловлено необходимостью улавливать достаточное количество информации о спектральных характеристиках сигнала для надежного формирования отпечатков. Таким образом, выбор длительности сегмента является критическим параметром при настройке системы NAFP.
Использование больших языковых моделей для оптимизации длины сегментов
В рамках исследования изучается возможность использования больших языковых моделей (LLM) для предсказания оптимальных значений длины сегмента при создании аудио-отпечатков. Целью является повышение эффективности алгоритмов поиска и идентификации аудиоматериалов за счет динамической адаптации длины анализируемых сегментов. LLM используются для прогнозирования оптимальной длины сегмента, исходя из характеристик аудиофайла, что позволяет улучшить точность и скорость сопоставления аудио-отпечатков, особенно в условиях ограниченной длительности запроса.
Для оценки возможности использования больших языковых моделей (LLM) в оптимизации длины сегментов при создании аудио-отпечатков были протестированы модели GPT-5-mini, Gemini-2.5-flash и Claude-Sonnet-4.5. В процессе оценки модели обучались на наборах данных, содержащих характеристики аудиозаписей и соответствующие оптимальные длины сегментов, после чего их способность предсказывать подходящие значения длины сегментов была измерена с использованием стандартных метрик, таких как точность и полнота. Особое внимание уделялось способности моделей адаптироваться к различным типам аудиоконтента и находить оптимальные значения длины сегментов для повышения эффективности поиска и идентификации аудиозаписей.
Предварительные результаты исследований демонстрируют, что использование больших языковых моделей (LLM) для определения оптимальной длины сегмента значительно повышает эффективность аудио-идентификации. Особенно заметный эффект наблюдается при обработке коротких запросов длительностью до 3 секунд, где применение более коротких сегментов позволяет достичь существенно более высоких показателей успешного поиска совпадений. Данное улучшение производительности указывает на потенциал LLM в динамической оптимизации параметров аудио-идентификации для различных типов запросов и условий работы системы.
NAFP+: Адаптивные отпечатки и повышение устойчивости
Система NAFP+ использует возможности больших языковых моделей (LLM) для адаптации длины сегментов аудио, что позволяет динамически подстраиваться под характеристики конкретной записи. В отличие от традиционных методов, применяющих фиксированную длину сегмента, NAFP+ анализирует аудиопоток и определяет оптимальную длину сегмента для каждого фрагмента, учитывая такие факторы, как сложность звука, наличие шумов и темп. Такой подход позволяет более эффективно извлекать ключевые характеристики аудио, повышая точность идентификации даже в сложных условиях, например, при наличии временных сдвигов или фонового шума. Адаптация длины сегмента, управляемая LLM, значительно улучшает устойчивость системы к различным искажениям и обеспечивает более надежную работу в реальных сценариях использования.
Исследования, проведённые с использованием обширного набора данных FMA, продемонстрировали повышенную устойчивость предложенного метода к различным искажениям аудиосигналов. В ходе экспериментов искусственно вносились временные сдвиги и фоновый шум, имитирующие реальные условия эксплуатации систем идентификации аудио. Результаты показали, что алгоритм эффективно справляется с такими помехами, сохраняя высокую точность распознавания даже в сложных акустических средах. Данная устойчивость достигается за счёт адаптивной обработки сегментов аудио, позволяющей алгоритму выделять ключевые характеристики сигнала, несмотря на наличие искажений и шумов, что существенно повышает надежность системы в практических приложениях.
Исследования показали, что система NAFP+ демонстрирует значительное улучшение в задачах идентификации аудио, используя стандартные метрики, такие как ‘Top-K Exact Hit’ и ‘Top-K Near Hit’. В частности, при использовании оптимизированной длины сегмента, показатель ‘Top-K Exact Hit’ превышает 80%, что свидетельствует о высокой точности распознавания аудиофайлов даже в сложных условиях. Данный результат подчеркивает эффективность адаптивного подхода к формированию отпечатков, позволяющего системе более надежно идентифицировать аудиоконтент по сравнению с традиционными методами. Высокая точность идентификации делает NAFP+ перспективным решением для широкого спектра приложений, включая поиск аудиоконтента, обнаружение дубликатов и системы цифровых прав.
Исследование демонстрирует, что эффективность алгоритмов аудио-идентификации напрямую зависит от длительности сегментов, что подтверждает стремление к лаконичности и ясности. Как отмечал Г.Х. Харди: «Чистая математика — это искусство логического мышления». Подобно тому, как математик стремится к элегантности доказательства, так и разработчики аудио-идентификаторов должны стремиться к оптимизации длины сегментов. Уменьшение длительности до 0.5 секунды, как показано в статье, является примером этого принципа — удаление избыточности для достижения максимальной производительности, особенно при работе с короткими запросами. Использование LLM, таких как GPT-5-mini, для определения оптимальной длины сегмента подчеркивает важность автоматизации и интеллектуального подхода к решению задач.
Куда Дальше?
Представленные результаты указывают на неожиданную простоту. Короткие сегменты, как выясняется, эффективнее. Абстракции стареют, принципы — нет. Но это лишь констатация факта, а не решение проблемы. Оптимальная длина сегмента зависит от контекста запроса, и универсального ответа не существует. Вопрос о динамической адаптации длины сегмента, управляемой, например, языковыми моделями, остаётся открытым.
Более того, необходимо критически оценить влияние выбора обучающей выборки. Чем разнообразнее акустическая среда, тем сложнее задача. Контрастное обучение, как и любой метод, подвержено предвзятостям. Каждая сложность требует алиби. Следует исследовать устойчивость системы к шумам, искажениям и различным типам аудиоконтента.
В конечном счете, данная работа — это не пункт назначения, а лишь указатель. Будущие исследования должны сосредоточиться на разработке более гибких и адаптивных систем, способных эффективно работать в реальных условиях. И, конечно, необходимо помнить: совершенство достигается не когда нечего добавить, а когда нечего убрать.
Оригинал статьи: https://arxiv.org/pdf/2601.17690.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Самообучающиеся признаки: новый подход к машинному обучению
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Навыки агентов: Новый уровень интеллекта ИИ
- Наука на Автопилоте: Система для Самостоятельных Исследований
2026-02-01 16:38