Автор: Денис Аветисян
Новое исследование показывает, что предварительное обучение моделей на абстрактных данных улучшает их способность к логическому мышлению и повышает эффективность обучения.
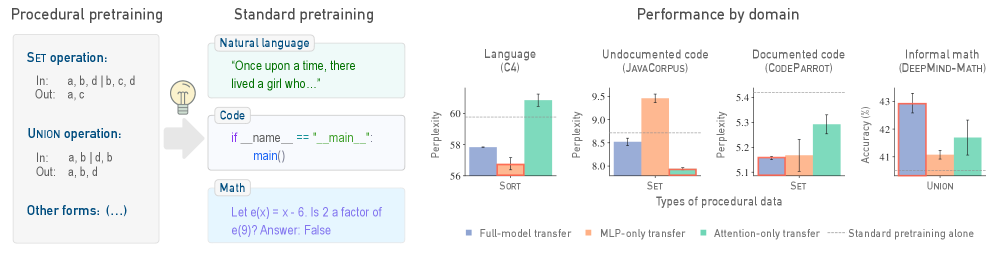
Предлагаемый метод процедурного предварительного обучения дополняет стандартные подходы и повышает способность языковых моделей к приобретению и применению знаний.
Несмотря на значительные успехи в обучении больших языковых моделей, их способность к освоению базовых алгоритмических навыков остается недостаточно изученной. В работе ‘Procedural Pretraining: Warming Up Language Models with Abstract Data’ предлагается альтернативный подход к предварительному обучению, основанный на использовании абстрактных процедурных данных, что позволяет значительно улучшить качество освоения семантических знаний. Показано, что предварительное обучение на таких данных, даже в небольшом объеме, повышает эффективность обучения и улучшает производительность моделей на различных задачах, включая работу с кодом и математикой. Возможно ли создание универсальной стратегии предварительного обучения, сочетающей различные типы процедурных данных для дальнейшего повышения эффективности и обобщающей способности больших языковых моделей?
За пределами Семантики: Необходимость Алгоритмических Оснований
Современные большие языковые модели демонстрируют впечатляющие успехи в понимании и генерации текста, превосходно справляясь с задачами, требующими семантического анализа. Однако, несмотря на кажущуюся интеллектуальность, эти модели часто терпят неудачу при решении задач, требующих систематического мышления и способности к обобщению. Проблема заключается в том, что они, по сути, являются статистическими машинами, которые выявляют закономерности в огромных объемах данных, но не обладают внутренним алгоритмическим каркасом, позволяющим им логически выстраивать цепочки рассуждений и применять знания к новым, незнакомым ситуациям. Это приводит к тому, что модели могут выдавать грамматически верные и семантически правдоподобные ответы, которые, тем не менее, лишены логической связности или основаны на поверхностных корреляциях, а не на глубоком понимании сути вопроса.
Существенное ограничение современных больших языковых моделей заключается в их опоре на статистические закономерности, а не на внутреннюю алгоритмическую структуру. Вместо того чтобы оперировать с принципами и правилами, подобными тем, что использует человек при решении задач, эти модели выявляют вероятные связи между словами и фразами на основе огромных объемов данных. Это приводит к тому, что они часто демонстрируют впечатляющие результаты в задачах, требующих понимания смысла, но испытывают трудности с систематическим мышлением и обобщением знаний в новых, незнакомых ситуациях. Отсутствие четкого алгоритмического каркаса делает их уязвимыми к ошибкам, основанным на поверхностных корреляциях, а не на истинном понимании лежащих в основе принципов.

Построение Алгоритмического Скелета: Процедурное Предварительное Обучение
Предварительное обучение моделей с использованием процедурных данных предполагает начальную фазу, в ходе которой модель обучается на абстрактных, структурированных данных до этапа стандартного семантического предварительного обучения. Данный подход направлен на формирование базовых алгоритмических навыков, позволяющих модели более эффективно решать задачи, требующие логического мышления и последовательной обработки информации. По сути, процедурное предварительное обучение создает своего рода «алгоритмический каркас», который впоследствии используется при обработке более сложных и разнообразных семантических данных. Использование структурированных данных на начальном этапе позволяет модели усвоить фундаментальные принципы обработки информации, прежде чем она столкнется со сложностями естественного языка.
Предварительное обучение на абстрактных данных формирует у модели базовые алгоритмические навыки, что существенно повышает её способность к решению задач, требующих логического мышления. Этот начальный этап позволяет модели освоить принципы последовательного выполнения операций и выявления закономерностей в структурированных данных, что в дальнейшем улучшает производительность в задачах, где необходимо планирование, дедукция или абстрактное рассуждение. В результате, модель получает преимущество при решении проблем, выходящих за рамки простого распознавания образов или статистического анализа, и демонстрирует более высокий уровень обобщения и адаптации к новым, нетривиальным ситуациям.
Абстрактные данные для процедурного претренирования генерируются с использованием различных методов, включая клеточные автоматы, трансформации последовательностей и симуляции операций с памятью. Клеточные автоматы создают данные на основе локальных правил взаимодействия, что позволяет моделировать сложные системы. Трансформации последовательностей включают в себя операции с упорядоченными данными, такие как сдвиги, вставки и удаления, формируя структуры, требующие анализа последовательностей. Симуляции операций с памятью, такие как чтение, запись и перемещение данных, позволяют модели изучать алгоритмы управления памятью и оптимизации доступа к данным. Все эти методы направлены на создание данных, не содержащих семантического значения, но обладающих четкой алгоритмической структурой.
Формальные языки, такие как контекстно-свободные грамматики и регулярные выражения, используются для точного определения правил генерации процедурных наборов данных. Это обеспечивает согласованную алгоритмическую структуру, позволяя создавать данные с предсказуемыми свойствами и взаимосвязями. Использование формальных определений гарантирует, что модели, обученные на этих данных, приобретают навыки, основанные на четко определенных логических принципах, а не на статистических закономерностях, свойственных естественным языкам. Строгое соблюдение правил формального языка позволяет контролировать сложность и разнообразие генерируемых данных, оптимизируя процесс обучения и повышая обобщающую способность модели.

Интеграция Процедурных и Семантических Знаний
В рамках стандартных парадигм предварительного обучения (pretraining) предлагается внедрение процедурного предварительного обучения в качестве начального этапа. Это предполагает предварительное обучение модели на данных, структурированных в виде последовательностей операций или алгоритмов, перед обучением на традиционных корпусах текста и кода. Такой подход позволяет модели усвоить не только статистические закономерности, присутствующие в семантических данных, но и явные алгоритмические структуры, что потенциально улучшает её способность к решению задач, требующих логического вывода и последовательного применения правил. Данный метод является расширением существующих подходов и не заменяет их, а дополняет, предоставляя модели более широкую базу знаний перед финальной тонкой настройкой.
Предварительное обучение модели осуществляется с использованием как семантических данных, представленных в наборах C4, CodeParrot и DeepMind-Math, так и явных алгоритмических структур. Наборы данных C4, CodeParrot и DeepMind-Math обеспечивают статистические закономерности, необходимые для понимания языка и кода, в то время как алгоритмические структуры предоставляют модели возможность усваивать логические связи и последовательности действий. Сочетание этих двух типов данных позволяет модели эффективно использовать как общие знания, полученные из больших объемов текста и кода, так и конкретные алгоритмические правила, что способствует улучшению ее способности к решению задач, требующих логического мышления и рассуждений.
В ходе экспериментов с архитектурой GPT-2 было показано, что предварительное обучение моделей на процедурных данных приводит к повышению эффективности при решении задач, требующих логического мышления. При этом, удалось добиться снижения объема используемых данных из набора C4 до 45%, при сохранении уровня производительности. Данный результат указывает на способность модели более эффективно использовать информацию, полученную из процедурных данных, для обобщения и решения новых задач, что позволяет сократить зависимость от больших объемов семантических данных.
В архитектуре Transformer слои внимания (Attention Layers) и многослойные перцептроны (MLP Layers) играют ключевую роль в интеграции процедурных и семантических знаний. Слои внимания позволяют модели динамически взвешивать различные части входной последовательности, эффективно улавливая зависимости между элементами, что особенно важно при обработке процедурных данных, представляющих собой последовательности действий. MLP Layers, применяемые к выходным данным слоев внимания, осуществляют нелинейные преобразования, позволяя модели извлекать более сложные признаки и обобщать информацию, полученную из как семантических, так и процедурных источников. Взаимодействие между этими слоями обеспечивает возможность модели одновременно учитывать статистические закономерности, содержащиеся в семантических данных, и явные алгоритмические структуры, что приводит к улучшению производительности в задачах, требующих рассуждений.

Сложность, Смеси и Перспективы Развития
Сложность Колмогорова абстрактных наборов данных оказывает значительное влияние на способность модели обучаться надежным алгоритмическим представлениям. По сути, чем выше сложность Колмогорова, тем больше информации необходимо для полного описания данных, что требует от модели более глубокого понимания лежащих в основе закономерностей. Исследования показывают, что модели, обученные на данных с умеренной сложностью Колмогорова, демонстрируют повышенную устойчивость к шуму и обобщающую способность. Это связано с тем, что модели учатся выделять существенные признаки и игнорировать несущественные детали, что позволяет им эффективно обрабатывать новые, ранее не встречавшиеся данные. В конечном итоге, учет сложности Колмогорова при создании обучающих наборов данных может значительно улучшить производительность и надежность алгоритмов машинного обучения.
Методы смешивания данных и взвешенных смесей позволяют объединять различные наборы процедурных данных для повышения обобщающей способности моделей. Вместо использования однородных данных, исследователи применяют комбинацию нескольких процедурных наборов, каждый из которых представляет определенный аспект решаемой задачи. Взвешивание этих наборов позволяет модели акцентировать внимание на наиболее важных аспектах, улучшая ее способность к адаптации к новым, ранее не встречавшимся ситуациям. Такой подход имитирует естественный процесс обучения, когда человек комбинирует различные знания и опыт для решения сложных задач, что приводит к созданию более устойчивых и эффективных алгоритмов.
Предложенный подход открывает перспективы для создания более устойчивых и понятных систем искусственного интеллекта, способных к сложному рассуждению. Исследования показывают, что для достижения превосходства над базовыми моделями достаточно всего 2-4 миллиона процедурных токенов. Такая эффективность объясняется тем, что процедурные данные, в отличие от статичных наборов, позволяют моделям усваивать фундаментальные принципы и алгоритмы, лежащие в основе данных, а не просто запоминать конкретные примеры. В результате, системы, обученные с использованием процедурных данных, демонстрируют повышенную обобщающую способность и более надежную работу в различных условиях, что делает их перспективными для решения сложных задач, требующих логического мышления и адаптации.
Предстоящие исследования направлены на расширение данной парадигмы предварительного обучения, охватывая другие модальности и задачи. Особый интерес представляет возможность замены до 45% стандартных данных процедурными данными без снижения производительности. Такой подход обещает значительное сокращение объема необходимых данных для обучения, а также повышение эффективности и обобщающей способности моделей искусственного интеллекта. Ученые предполагают, что замена части стандартных данных процедурными позволит создавать более устойчивые и интерпретируемые системы, способные к сложным рассуждениям и адаптации к различным условиям, что открывает новые перспективы в области машинного обучения и искусственного интеллекта.

Исследование демонстрирует, что предварительное обучение языковых моделей на абстрактных процедурных данных значительно улучшает их способность к алгоритмическому мышлению и повышает эффективность использования данных. Этот подход, дополняющий стандартные методы предварительного обучения, позволяет создавать более гибкие и адаптивные системы. Как отмечал Марвин Минский: «Лучший способ понять интеллект — создать его». Подобно тому, как сложно пересадить сердце, не понимая кровотока, невозможно эффективно обучить модель, не понимая фундаментальных процедур и алгоритмов, лежащих в основе ее работы. Успех процедурного предварительного обучения подтверждает, что структурированные данные, подобные базовым алгоритмическим концепциям, играют решающую роль в формировании интеллектуальных систем.
Куда Далее?
Представленная работа, безусловно, демонстрирует потенциал процедурного претренирования в улучшении алгоритмического мышления языковых моделей. Однако, акцент на абстрактных данных порождает вопрос: не оптимизируем ли мы скорость, жертвуя глубиной? Модель, “разогретая” абстракциями, может демонстрировать впечатляющую эффективность на узком круге задач, но останется ли эта эффективность устойчивой перед лицом реальной неоднозначности и неполноты данных? Простота алгоритмов, используемых для генерации этих данных, — это, конечно, преимущество с точки зрения масштабируемости, но и ограничение в плане репрезентации сложности мира.
Будущие исследования должны сосредоточиться на поиске баланса между абстракцией и конкретикой. Необходимо исследовать, как процедурное претренирование может быть интегрировано с традиционными методами, использующими большие объемы текстовых данных, чтобы создать более универсальные и надежные модели. Важно понимать, что любая архитектура, даже самая элегантная, — это компромисс, а зависимости от определённого типа данных — это всегда цена свободы. Хорошая архитектура незаметна, пока не ломается.
В конечном счёте, успех этого направления будет зависеть не от количества абстрактных данных, а от способности моделей к обобщению и адаптации к новым, непредсказуемым ситуациям. Иначе мы получим лишь очередную сложную систему, хрупкую и уязвимую перед лицом реальности.
Оригинал статьи: https://arxiv.org/pdf/2601.21725.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Искусственный интеллект: хрупкость визуального мышления
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Моделирование биомолекул: новый импульс от нейросетей
- Мгновенная расшифровка: Voxtral Realtime на службе у скорости
- Математический интеллект: как улучшить навыки решения задач у больших языковых моделей
2026-02-01 16:40