Автор: Денис Аветисян
Новое исследование демонстрирует, как объединение текста, изображений и трёхмерных данных позволяет создавать детализированный и согласованный 3D-контент с помощью передовых языковых моделей.
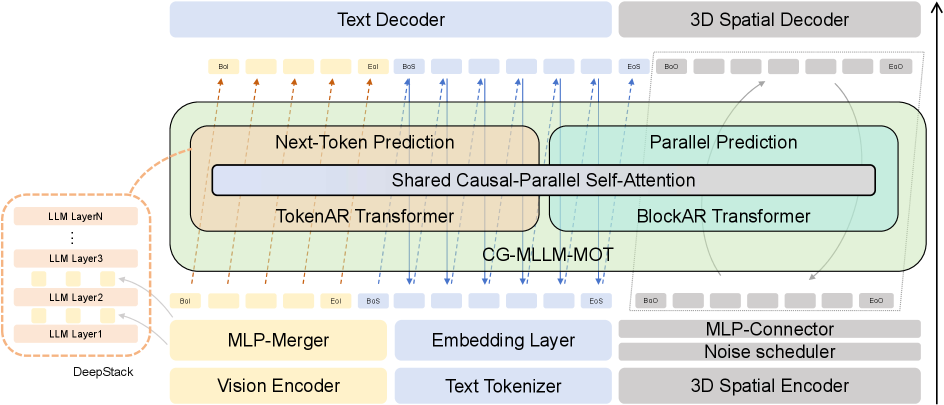
Представлена модель CG-MLLM, использующая мультимодальный подход и авторегрессивные/диффузионные методы для генерации высококачественных трёхмерных объектов с улучшенной пространственной связностью.
Несмотря на революционный прорыв больших языковых моделей (LLM) в генерации текста и мультимодальном восприятии, их возможности в области создания 3D-контента остаются недостаточно изученными. В данной работе представлена модель CG-MLLM: Captioning and Generating 3D content via Multi-modal Large Language Models, использующая архитектуру Mixture-of-Transformers для одновременного описания и генерации 3D-объектов высокого разрешения. CG-MLLM, интегрируя предобученную модель для обработки изображений и текста с 3D VAE латентным пространством, обеспечивает эффективное взаимодействие между токенами и пространственными блоками, значительно превосходя существующие мультимодальные LLM в качестве генерируемых 3D-моделей. Сможет ли данный подход открыть новую эру доступного и высококачественного 3D-контента, создаваемого с помощью LLM?
За гранью пикселей: Необходимость пространственного интеллекта
Современные генеративные модели, несмотря на впечатляющие успехи в создании визуального контента, часто демонстрируют непоследовательное понимание трехмерного пространства. Это приводит к появлению визуальных артефактов — искажений, нелогичных соединений и общей несогласованности в структуре генерируемых объектов. Например, модель может создать стул с невозможной геометрией или дом, в котором комнаты не соединяются друг с другом реалистичным образом. Проблема заключается в том, что большинство моделей обучаются на двумерных изображениях, не получая достаточного опыта в понимании глубины, перспективы и физических свойств трехмерного мира. В результате, генерируемые объекты часто лишены внутренней логики и выглядят неестественно, что ограничивает их применение в областях, требующих высокой степени реализма и точности.
Традиционные методы создания трехмерного контента зачастую сталкиваются с ограничениями в способности моделировать и понимать пространственные взаимосвязи, что приводит к созданию нереалистичных или логически несогласованных структур. Эти подходы, как правило, полагаются на ручное моделирование или процедурные правила, которые не обладают врожденным пониманием геометрии, масштаба и физических свойств объектов. В результате, даже сложные модели могут демонстрировать несоответствия в перспективе, неестественные деформации или отсутствие правдоподобного взаимодействия с окружающей средой. Отсутствие встроенной «пространственной логики» вынуждает разработчиков вручную исправлять эти недостатки, что требует значительных временных и вычислительных затрат, а также ограничивает возможности автоматизированного создания контента.
Основная сложность в создании реалистичных трехмерных моделей заключается в эффективном объединении понимания естественного языка и трехмерного геометрического представления. Современные генеративные модели часто испытывают трудности с последовательным восприятием пространства, что приводит к визуальным артефактам и нелогичным структурам. Для преодоления этого препятствия необходимо разработать системы, способные не просто интерпретировать текстовые описания объектов и сцен, но и точно преобразовывать эти описания в соответствующие трехмерные геометрические формы. Это требует новых подходов к моделированию языка, которые учитывают пространственные отношения и позволяют системам «понимать» не только что описывается, но и где объекты расположены и как они взаимодействуют друг с другом в трехмерном пространстве. Успешная интеграция этих двух областей позволит создавать более правдоподобные и сложные виртуальные миры, а также значительно улучшит возможности автоматизированного моделирования и дизайна.

CG-MLLM: Новая архитектура для 3D-генерации
CG-MLLM представляет собой новую мультимодальную большую языковую модель, объединяющую обработку языка, изображений и 3D-данных. Архитектура разработана для точного понимания пространственных отношений и генерации 3D-контента высокого качества. В отличие от существующих моделей, CG-MLLM обеспечивает комплексное взаимодействие между текстовыми запросами, визуальными данными и геометрическими представлениями, что позволяет создавать детализированные и реалистичные 3D-модели на основе текстовых описаний или изображений. Модель ориентирована на задачи, требующие понимания трехмерного пространства и точного воспроизведения геометрических форм.
В основе архитектуры CG-MLLM лежит предварительно обученная модель Qwen3-VL, выполняющая роль базового модуля. Qwen3-VL обеспечивает надежную обработку как визуальной, так и лингвистической информации, что позволяет системе эффективно понимать текстовые запросы и сопоставлять их с визуальными данными. Использование предварительно обученной модели значительно снижает потребность в больших объемах данных для обучения с нуля и позволяет сразу же использовать существующие знания о языке и изображениях для генерации 3D-контента. Модель Qwen3-VL предоставляет богатый набор признаков, необходимых для последующей обработки и формирования трехмерных объектов.
В архитектуре CG-MLLM ключевым элементом является интеграция пространственного вариационного автоэнкодера (Spatial VAE) Hunyuan3D-2.1-VAE. Этот автоэнкодер формирует высокопорядковое латентное пространство для представления трехмерных данных, что позволяет эффективно моделировать геометрию объектов. Hunyuan3D-2.1-VAE кодирует трехмерную сцену в компактное латентное представление, сохраняя при этом существенную геометрическую информацию. Это латентное пространство оптимизировано для последующей генерации детализированных и когерентных 3D-моделей, значительно снижая вычислительные затраты по сравнению с прямым моделированием геометрии.

Последовательная и параллельная обработка: Освоение конвейера генерации
Архитектура CG-MLLM использует Mixture-of-Transformers для разделения режимов последовательной и параллельной генерации, что позволяет оптимизировать эффективность обработки. Данный подход предполагает использование нескольких трансформеров, каждый из которых специализируется на определенном типе генерации. Последовательная генерация, осуществляемая одним из трансформеров, обеспечивает когерентность и согласованность выходных данных, в то время как параллельная генерация, выполняемая другим трансформером, ускоряет процесс создания сложных структур. Комбинация этих режимов позволяет динамически адаптировать процесс генерации в зависимости от конкретных требований задачи, минимизируя задержки и максимизируя производительность.
Модель TokenAR реализует последовательное (серийное) моделирование на уровне токенов, что обеспечивает связность и согласованность генерируемого контента. В отличие от параллельного подхода, TokenAR обрабатывает каждый токен последовательно, учитывая предыдущие токены в последовательности для прогнозирования следующего. Такой подход позволяет модели учитывать контекст и зависимости между токенами, что критически важно для поддержания логической структуры и семантической целостности генерируемого текста или данных. Использование серийного моделирования на уровне токенов способствует генерации более когерентного и правдоподобного контента, особенно в задачах, требующих высокой точности и согласованности.
Блок-ориентированное параллельное моделирование, реализованное в BlockAR, позволяет значительно ускорить генерацию сложных трехмерных структур. Вместо последовательной генерации каждого токена, BlockAR разделяет трехмерную сцену на отдельные блоки и обрабатывает их параллельно. Это достигается за счет разделения задачи на независимые подзадачи, которые могут быть выполнены одновременно на различных вычислительных ресурсах. Такой подход особенно эффективен для генерации детализированных и сложных объектов, где обработка каждого токена по отдельности потребовала бы значительных временных затрат. Параллельная обработка блоков существенно снижает общее время генерации, сохраняя при этом качество и детализацию итоговой 3D-модели.
Метод Rectified Flow повышает эффективность процесса дискретизации в базовых диффузионных моделях. В отличие от стандартных диффузионных моделей, требующих большого количества шагов для генерации, Rectified Flow использует нормализующие потоки для преобразования сложного распределения данных в более простое, что позволяет значительно сократить количество шагов дискретизации и, следовательно, ускорить процесс генерации. Это достигается за счет обучения потока, который «выпрямляет» траектории диффузии, делая их более прямолинейными и предсказуемыми. В результате снижаются вычислительные затраты и повышается скорость получения высококачественных результатов, особенно в задачах генерации изображений и 3D-структур. p(x) = \in t p(z) \nabla_z \log p(x|z) dz уравнение показывает связь между вероятностью данных и градиентом логарифма условной вероятности.
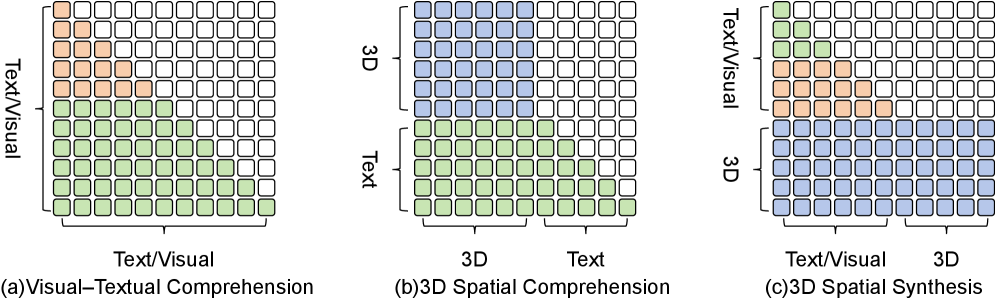
Количественная оценка: Измерение качества 3D-генерации
Для оценки качества генерации 3D-моделей CG-MLLM используется комплексный набор метрик, включающий p-FID, p-KID, MUSIQ, Uni3D и CLIP-IQA+. Метрика p-FID (Perceptual Fréchet Inception Distance) измеряет сходство распределений признаков между сгенерированными и реальными 3D-моделями. p-KID (Perceptual Kernel Inception Distance) является альтернативной метрикой, также оценивающей перцептуальное сходство. MUSIQ (Multiscale Structural Similarity Index Quality) оценивает структурное сходство на различных масштабах. Uni3D оценивает геометрическую согласованность и полноту сгенерированных моделей. CLIP-IQA+ (Contrastive Language-Image Pre-training for Image Quality Assessment) оценивает соответствие сгенерированных моделей текстовым описаниям, используя модель CLIP для вычисления сходства между визуальными признаками и текстовым входом.
Используемые метрики, такие как p-FID, p-KID, MUSIQ, Uni3D и CLIP-IQA+, позволяют оценить как геометрическую точность (fidelity) сгенерированных 3D-структур, так и качество визуального представления. Геометрическая точность определяет, насколько точно сгенерированная модель соответствует ожидаемой форме и структуре, в то время как визуальное качество оценивает реалистичность текстур, освещения и общей эстетики модели. Комбинированное использование этих метрик обеспечивает всестороннюю оценку качества генерации, охватывая как структурные, так и визуальные аспекты.
Оценка качества генерации 3D-моделей также включает в себя метрику CLIP (Contrastive Language-Image Pre-training), которая измеряет семантическую согласованность между текстовым запросом (prompt) и сгенерированной 3D-моделью. CLIP вычисляет сходство между векторными представлениями текста и изображения (в данном случае, рендером 3D-модели), полученными с помощью предварительно обученной нейронной сети. Более высокое значение CLIP указывает на более тесное соответствие между запросом и сгенерированным результатом, что свидетельствует о лучшем понимании и интерпретации текстового описания моделью генерации.
Результаты экспериментов демонстрируют значительное улучшение качества 3D-генерации по сравнению с существующими методами. В частности, разработанная система стабильно превосходит SAR3D и ShapeLLM-Omni по всем использованным метрикам оценки: p-FID, p-KID, MUSIQ, Uni3D, CLIP-IQA+ и CLIP. Это указывает на более высокую геометрическую точность и визуальное качество генерируемых 3D-структур, а также на лучшую семантическую согласованность между текстовым запросом и полученным 3D-объектом, подтвержденную метрикой CLIP.

Перспективы развития: Расширение границ 3D-создания
Модель CG-MLLM открывает новые горизонты для развития виртуальной, дополненной реальности и метавселенных. Благодаря способности генерировать трехмерный контент на основе текстовых запросов, она позволяет создавать иммерсивные среды и интерактивные объекты с беспрецедентной скоростью и гибкостью. Это потенциально революционизирует процесс разработки виртуальных миров, позволяя создавать сложные и детализированные сцены без необходимости трудоемкого ручного моделирования. Представьте себе возможность мгновенно воплощать в жизнь фантастические пейзажи или реалистичные прототипы продуктов, просто описав их словами — именно это становится возможным благодаря CG-MLLM, что значительно расширяет возможности для дизайнеров, разработчиков и создателей контента в этих быстро развивающихся областях.
Разработка модели CG-MLLM открывает новые возможности для автоматизированного создания трехмерного контента, значительно сокращая временные и финансовые затраты, традиционно связанные с ручным моделированием. Вместо трудоемкого процесса, требующего квалифицированных специалистов и длительного времени, модель способна генерировать сложные 3D-объекты и сцены на основе текстовых запросов или изображений. Это позволяет значительно ускорить процесс создания виртуальных миров, игровых активов и визуализаций, делая 3D-графику более доступной для широкого круга пользователей и предприятий, которым ранее создание качественного 3D-контента было непосильным из-за высоких затрат и нехватки ресурсов.
Система CG-MLLM обладает потенциалом для развития в сторону интерактивного 3D-редактирования и кастомизации, что открывает широкие возможности для создания персонализированного опыта взаимодействия. Вместо пассивного восприятия сгенерированных объектов, пользователи смогут активно влиять на их форму, текстуру и функциональность, непосредственно в процессе создания. Это позволяет адаптировать виртуальные пространства и объекты под индивидуальные предпочтения, создавать уникальные аватары и персонализированные виртуальные миры. Представьте, что можно изменить дизайн мебели в виртуальной комнате, настроить внешний вид персонажа в игре или даже создать собственные 3D-модели, не обладая специализированными навыками моделирования — всё это становится возможным благодаря расширению возможностей CG-MLLM в области интерактивного редактирования.
Дальнейшие исследования в области CG-MLLM сосредоточены на повышении способности модели к обработке сложных сцен и детализированных объектов. Разработчики стремятся преодолеть текущие ограничения в воссоздании реалистичных текстур, сложных геометрических форм и взаимодействия множества элементов в виртуальном пространстве. Особое внимание уделяется оптимизации алгоритмов для эффективной обработки больших объемов данных и снижения вычислительной нагрузки, что позволит создавать еще более масштабные и детализированные 3D-миры. Улучшение способности к пониманию контекста и семантической информации также является ключевым направлением, позволяющим модели генерировать более правдоподобные и осмысленные объекты и сцены, расширяя возможности автоматизированного 3D-моделирования.
В статье описывается CG-MLLM, модель, стремящаяся объединить мир языка и трёхмерных данных. Заманчиво, конечно, но стоит помнить, что любая элегантная архитектура рано или поздно упрется в ограничения железа и необходимость оптимизации под реальные задачи. Как говорил Эндрю Ын: «Самый верный способ узнать, работает ли что-то — это попробовать это в продакшене». Идея интеграции различных модальностей — не нова, и часто красивая схема оказывается сложнее в реализации, чем кажется на бумаге. Особенно когда дело касается генерации контента, где даже небольшие несоответствия в пространственной логике могут разрушить всю иллюзию. Впрочем, время покажет, насколько эта попытка преодолеет неизбежный техдолг.
Что дальше?
Представленная работа, безусловно, демонстрирует очередной шаг в направлении интеграции языковых моделей с трёхмерным контентом. Однако, за элегантностью архитектуры и впечатляющими результатами неизбежно скрывается вопрос масштабируемости. «Улучшенная пространственная согласованность» — это хорошо, пока не попытаться сгенерировать сложную сцену, состоящую из тысяч объектов. Проверка на практике, как обычно, покажет, где заканчивается теория и начинается необходимость в ручной доработке.
Акцент на Mixture-of-Transformers и autoregressive модели — это, конечно, интересно. Но не стоит забывать, что каждое новое «решение» порождает новую головную боль в виде сложности развертывания и обслуживания. В конечном итоге, вся эта красота превратится в техдолг, который придётся выплачивать годами. И, вероятно, через пару лет кто-нибудь скажет, что монолитная система, генерирующая простые примитивы, была куда надежнее и предсказуемее.
Hunyuan3D-2.1 — это, безусловно, впечатляющий результат. Но за каждым шагом вперед в области генерации контента неизбежно следует гонка вооружений в области детектирования фейков. В конечном итоге, настоящим прорывом станет не способность генерировать реалистичные изображения, а способность отличать их от реальности.
Оригинал статьи: https://arxiv.org/pdf/2601.21798.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Облачные вычисления для науки: гибкость и масштабируемость
2026-02-01 18:26