Автор: Денис Аветисян
Исследователи предлагают инновационную архитектуру, позволяющую значительно снизить энергопотребление мощных языковых моделей без потери производительности.
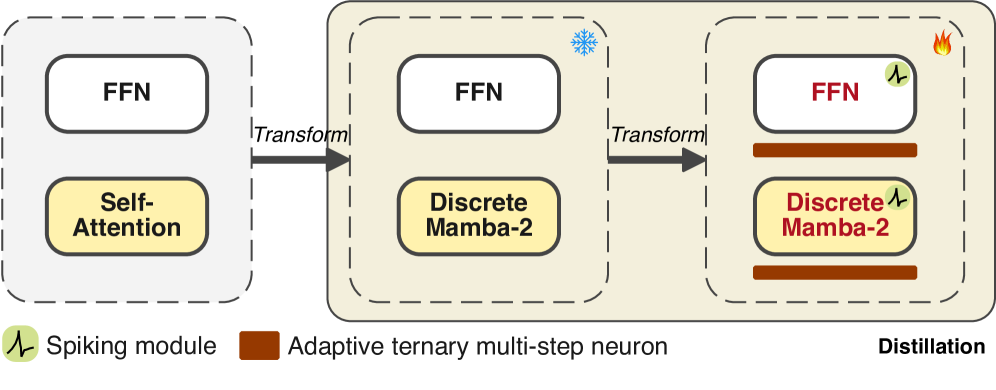
В статье представлена система MAR, объединяющая модели состояний, нейронные сети с импульсной передачей и двунаправленную дистилляцию знаний для повышения эффективности и экономии энергии.
Несмотря на впечатляющие возможности, большие языковые модели (LLM) характеризуются значительными затратами энергии из-за квадратичной сложности механизма внимания и вычислительно-интенсивных полносвязных слоев. В данной работе, ‘MAR: Efficient Large Language Models via Module-aware Architecture Refinement’, предложен инновационный фреймворк MAR, объединяющий модели пространства состояний (SSM) для линейной обработки последовательностей и активационную разреженность для снижения вычислительной нагрузки. Разработанные адаптивный тернарный нейрон (ATMN) и двунаправленная стратегия дистилляции (SBDS) позволяют эффективно интегрировать Spiking Neural Networks (SNN) с SSM, преодолевая проблемы низкой информационной плотности. Сможет ли предложенный подход MAR стать основой для создания энергоэффективных и практичных LLM нового поколения?
Увязшие в Вычислениях: Преодолевая Ограничения Больших Языковых Моделей
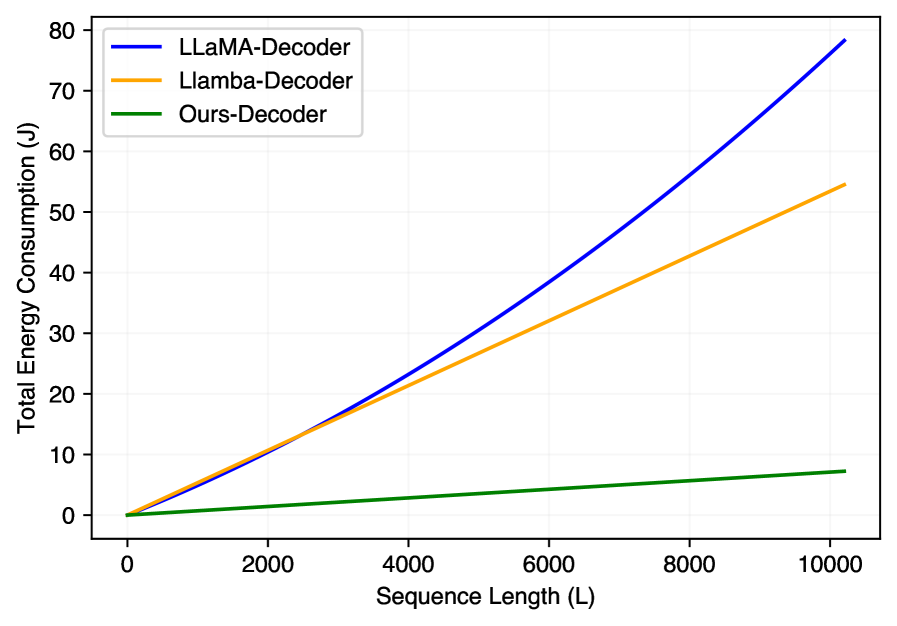
Несмотря на впечатляющие достижения в области обработки естественного языка, большие языковые модели (БЯМ) сталкиваются с серьезными ограничениями, связанными с вычислительными затратами и энергопотреблением. Обучение и эксплуатация таких моделей требуют огромных ресурсов, что делает их недоступными для многих исследователей и организаций. Этот фактор препятствует широкому внедрению БЯМ и замедляет прогресс в различных областях, включая машинный перевод, генерацию текста и анализ данных. Высокое энергопотребление также вызывает опасения с точки зрения экологической устойчивости, поскольку обучение одной большой модели может генерировать значительные выбросы углекислого газа. Поэтому, поиск путей повышения эффективности и снижения затрат на обучение и использование БЯМ является ключевой задачей для обеспечения их долгосрочной применимости и доступности.
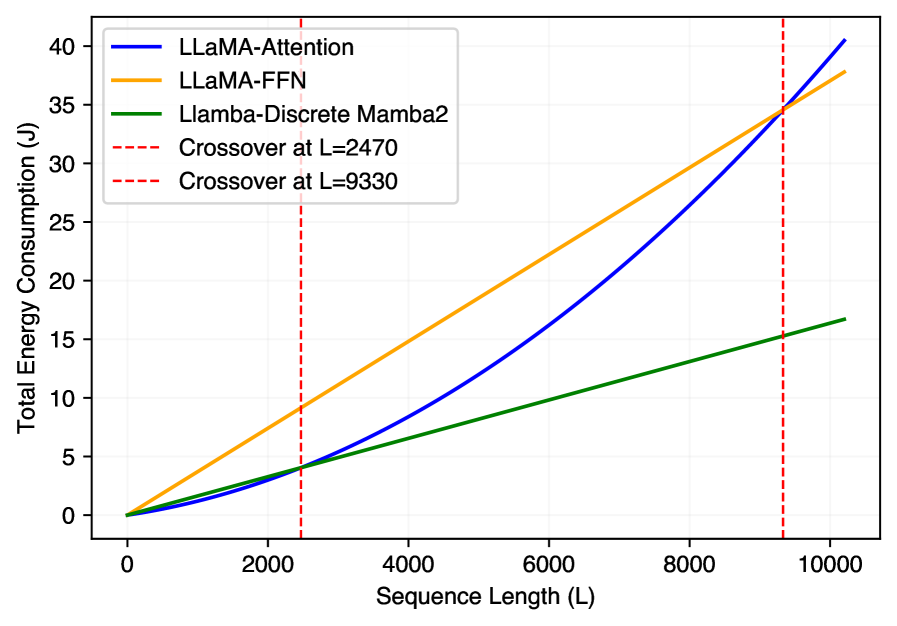
Традиционные механизмы внимания, лежащие в основе больших языковых моделей, сталкиваются с серьезным ограничением: их вычислительная сложность растет пропорционально квадрату длины обрабатываемой последовательности. Это означает, что при увеличении текста, например, при анализе длинных документов или сложных диалогов, потребность в вычислительных ресурсах и времени экспоненциально возрастает. В результате, модели испытывают трудности с установлением связей между удаленными элементами в тексте — так называемыми «долгосрочными зависимостями». Неспособность эффективно обрабатывать эти зависимости негативно сказывается на качестве выполнения задач, требующих глубокого понимания контекста и логических связей, таких как суммирование текста, машинный перевод и ответы на вопросы, что подталкивает исследователей к разработке более эффективных архитектур для моделирования последовательностей.
Ограниченная эффективность обработки длинных последовательностей серьезно сказывается на способности больших языковых моделей решать сложные задачи, требующие логического вывода и анализа контекста. Неспособность эффективно учитывать отдаленные зависимости в тексте приводит к ошибкам в понимании и генерации связного текста, особенно в задачах, требующих глубокого анализа. В связи с этим, активно ведутся исследования и разработки альтернативных архитектур, направленных на повышение эффективности обработки последовательностей, таких как разреженное внимание и линейные трансформаторы. Эти подходы стремятся снизить вычислительную сложность, сохранив или улучшив качество моделирования, что открывает перспективы для создания более мощных и доступных языковых моделей.
Взгляд в Будущее: Архитектуры Без Внимания
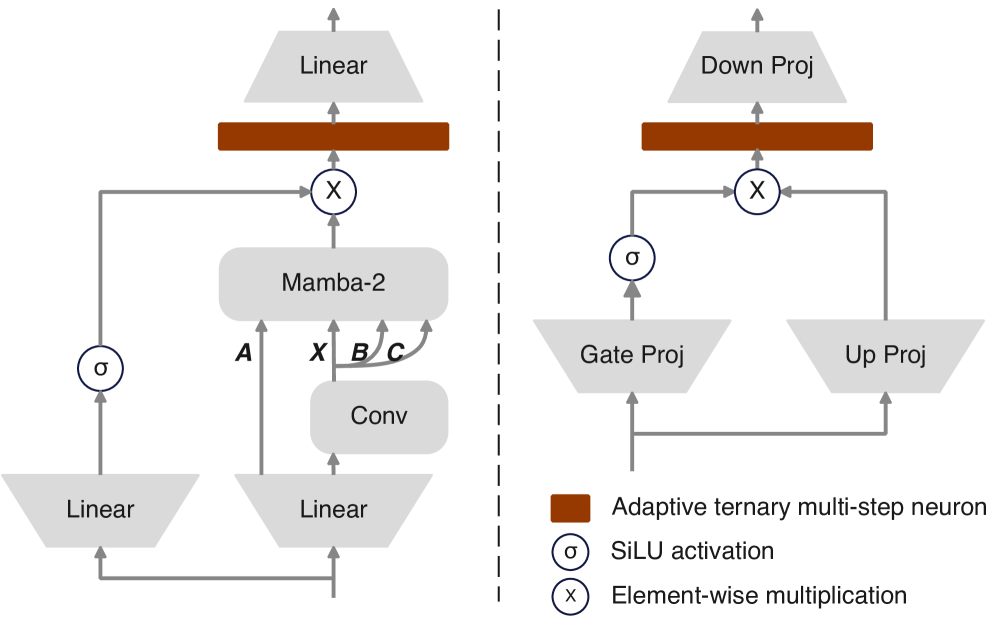
Llamba представляет собой альтернативу традиционным Transformer-архитектурам, отказавшись от механизма внимания и используя дискретные многоголовые модули Mamba-2 для эффективной обработки последовательностей. В отличие от квадратичной сложности вычислений внимания в Transformer, Mamba-2 использует выборочное сканирование состояний, что позволяет добиться линейной сложности по длине последовательности. Это достигается за счет параметризованного преобразования входных данных и последующего применения операции выборочного сканирования, что снижает вычислительные затраты и потребление памяти, особенно при обработке длинных последовательностей текста или других данных. Архитектура Llamba направлена на повышение эффективности и масштабируемости больших языковых моделей (LLM) без значительной потери производительности.
Модульно-ориентированная оптимизация архитектуры больших языковых моделей (LLM) направлена на повышение эффективности и производительности за счет одновременной доработки механизмов внимания и полносвязных сетей (Feed-Forward Networks). Данный подход предполагает анализ и корректировку параметров каждого модуля с учетом его влияния на общую производительность модели. Оптимизация механизмов внимания включает в себя снижение вычислительной сложности за счет использования разреженных или приближенных методов. Улучшение полносвязных сетей достигается за счет применения техник, таких как квантизация весов или использование более эффективных функций активации. В результате, модульно-ориентированная оптимизация позволяет добиться значительного снижения потребления памяти и вычислительных ресурсов, сохраняя или даже улучшая точность и скорость работы LLM.
Инновации, представленные в архитектуре Llamba, направлены на снижение вычислительной сложности и энергопотребления больших языковых моделей (LLM). Это достигается за счет отказа от механизмов внимания в пользу дискретных многоголовых модулей Mamba-2, что позволяет существенно уменьшить количество операций и объем памяти, необходимых для обработки последовательностей. Снижение требований к ресурсам делает возможным развертывание LLM на устройствах с ограниченными возможностями, таких как мобильные телефоны, встроенные системы и периферийные вычислительные устройства, расширяя область их применения и доступность.
Перенос Знаний: Обучение Компактных Моделей
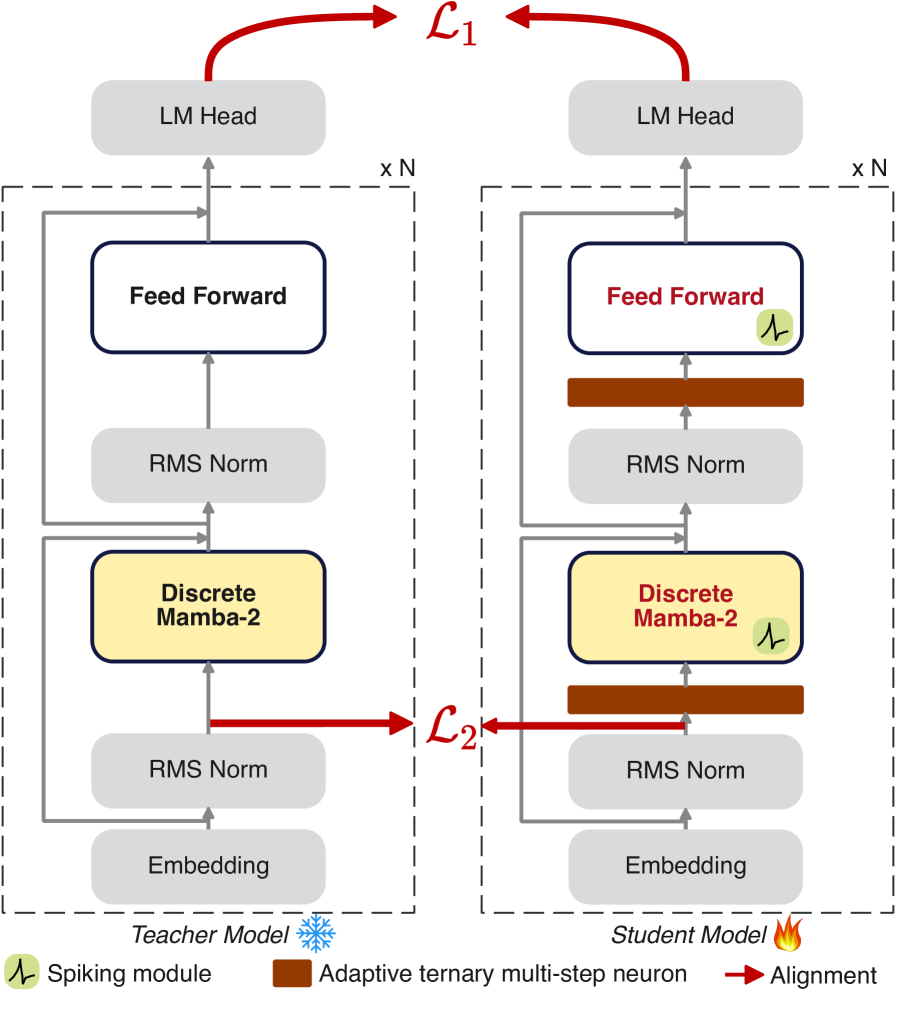
Стратегия двунаправленной дистилляции знаний, учитывающая особенности работы спайковых нейронных сетей (Spike-aware Bidirectional Distillation), используется для передачи знаний от больших, вычислительно сложных моделей-учителей к меньшим, более эффективным моделям-ученикам. Этот подход позволяет уменьшить разрыв в производительности между моделями разного размера за счет эффективного переноса информации, полученной учителем, в более компактную архитектуру ученика. Процесс дистилляции направлен на обучение ученика не только правильным ответам, но и логике принятия решений, демонстрируемой учителем, что способствует повышению точности и эффективности модели-ученика при меньшем количестве параметров.
Стратегия использует выравнивание по предварительной нормализации (Pre-Normalization Alignment) для повышения согласованности представлений между учителем и учеником. Этот метод позволяет минимизировать расхождения в распределениях активаций между моделями, что способствует более эффективной передаче знаний. Кроме того, применяется обратное расхождение Кульбака-Лейблера (Reverse KL Divergence), которое акцентирует внимание на высокоуверенных предсказаниях учителя. Вместо того, чтобы стремиться к соответствию во всех предсказаниях, обратное KL-расхождение фокусируется на тех случаях, когда учитель наиболее уверен в своем ответе, тем самым направляя обучение ученика на наиболее значимые и надежные сигналы.
Эффективная дистилляция знаний позволяет минимизировать разрыв в производительности между большими и малыми моделями. В ходе экспериментов, средняя точность модели, полученной посредством дистилляции, составила 57.93% на шести различных задачах. Это позволяет практически восстановить производительность исходной (teacher) модели, демонстрирующей точность в 61.88%, и превзойти модель SpikeLLM на 5.45 процентных пункта, при этом используя лишь 1.4 миллиарда параметров.
Проверка в Действии: Оценка на Ключевых Наборах Данных
Для всесторонней оценки предложенных методов была проведена серия экспериментов на различных авторитетных наборах данных, включающих HellaSwag, Winogrande, ARC Easy, ARC Challenge, Boolean Questions, Physical Interaction QA и InfinityInstruct. Данные наборы охватывают широкий спектр задач, связанных с здравым смыслом и ответами на вопросы, что позволило оценить способность моделей к обобщению и адаптации к различным сценариям. Использование таких разнообразных наборов данных гарантирует надежность полученных результатов и подтверждает эффективность предложенного подхода в решении сложных задач искусственного интеллекта, требующих понимания контекста и логических рассуждений.
Предложенные модели продемонстрировали конкурентоспособные результаты в задачах, требующих здравого смысла и ответов на вопросы. В ходе экспериментов удалось превзойти показатели Bi-Mamba на 8.55 процентных пункта, достигнув точности в 57.93%. Данный результат свидетельствует о высокой эффективности разработанного подхода в решении сложных когнитивных задач и открывает перспективы для его применения в системах искусственного интеллекта, где важна способность к логическому мышлению и пониманию контекста.
Исследования показали, что применение двунаправленной дистилляции потерь, настроенной с оптимальными гиперпараметрами — альфа равным 0.2 и бета равным 0.7 — значительно повышает эффективность предложенного подхода. Достигнутая точность в 56.40% подтверждает, что подобная калибровка позволяет модели более эффективно извлекать и обобщать знания из обучающих данных. Данный результат демонстрирует потенциал оптимизации параметров для достижения максимальной производительности в задачах, требующих глубокого понимания контекста и логических связей, что особенно важно для систем, работающих с ограниченными вычислительными ресурсами.
Полученные результаты, демонстрирующие конкурентоспособность предложенного подхода на различных эталонных наборах данных, подтверждают его эффективность и открывают перспективы для практического применения в условиях ограниченных вычислительных ресурсов. Данная методика позволяет достигать высокой точности, не требуя при этом значительных аппаратных затрат, что особенно важно для мобильных устройств, встроенных систем и других сценариев, где энергоэффективность и компактность являются приоритетными. Возможность эффективной работы в условиях ограниченных ресурсов делает предложенный подход привлекательным для широкого спектра задач, связанных с обработкой естественного языка и искусственным интеллектом, расширяя область его потенциального использования за пределы традиционных вычислительных платформ.
К Устойчивому и Доступному Языковому ИИ
Сочетание архитектур, свободных от механизма внимания, с эффективными стратегиями дистилляции знаний открывает новые возможности для создания устойчивых и доступных систем искусственного интеллекта, работающих с естественным языком. Традиционные модели, использующие внимание, требуют значительных вычислительных ресурсов и энергии, особенно при обработке длинных последовательностей текста. Альтернативные архитектуры, такие как многослойные персептроны (MLP) и состояния рекуррентной сети (RNN), позволяют снизить сложность вычислений, сохраняя при этом высокую производительность. Эффективная дистилляция знаний, в свою очередь, позволяет передать навыки от большой, сложной модели к более компактной и энергоэффективной, без существенной потери точности. Это особенно важно для развертывания языковых моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны и встроенные системы, расширяя тем самым доступ к мощным технологиям обработки языка для более широкой аудитории и способствуя их применению в различных областях, от образования до здравоохранения.
Дальнейшие исследования в области спиковых нейронных сетей и адаптивных троичных многошаговых нейронов представляют значительный потенциал для существенного снижения энергопотребления в системах искусственного интеллекта. В отличие от традиционных нейронных сетей, использующих непрерывные значения, спиковые сети имитируют принципы работы биологических нейронов, передавая информацию посредством дискретных импульсов. Адаптивные троичные многошаговые нейроны, в свою очередь, позволяют оптимизировать вычислительный процесс, используя всего три состояния, что значительно упрощает аппаратную реализацию и снижает энергозатраты. Эти подходы обещают создание более эффективных и устойчивых моделей обработки естественного языка, открывая возможности для развертывания сложных ИИ-систем на устройствах с ограниченными ресурсами и способствуя развитию экологически ответственных технологий.
Обеспечение широкого доступа к мощным языковым технологиям является ключевым шагом на пути к их демократизации и расширению сферы применения. Ранее сложные и ресурсоемкие модели искусственного интеллекта, требующие значительных вычислительных мощностей, становятся все более доступными для исследователей, разработчиков и конечных пользователей с ограниченными ресурсами. Это открывает возможности для внедрения передовых языковых инструментов в различные области, включая образование, здравоохранение, сельское хозяйство и социальные услуги, особенно в регионах с ограниченным доступом к технологиям. Упрощение и удешевление доступа способствует инновациям, позволяя решать локальные задачи и создавать специализированные решения, адаптированные к конкретным потребностям, что, в конечном итоге, способствует общему технологическому прогрессу и повышению качества жизни.
Исследование представляет собой очередную попытку обуздать ненасытный аппетит больших языковых моделей. Авторы предлагают MAR — архитектурное усовершенствование, объединяющее state space models и spiking neural networks. Заманчиво, конечно, снизить энергопотребление, но история учит, что любая «революционная» оптимизация рано или поздно превратится в новый вид техдолга. Впрочем, сама идея использования двунаправленной дистилляции — шаг в правильном направлении. Как говорил Блез Паскаль: «Все проблемы человечества происходят от того, что люди не умеют спокойно сидеть в комнате». В данном контексте, эта фраза намекает на постоянную потребность в инновациях, даже если стабильная, пусть и не идеальная, система уже существует. Энергоэффективность — это хорошо, но продлить жизнь очередному монолиту — задача куда более приземленная.
Что дальше?
Представленный подход, объединяющий модели состояний, импульсные нейронные сети и дистилляцию, безусловно, демонстрирует потенциал снижения энергопотребления больших языковых моделей. Однако, следует признать, что любая «эффективная» архитектура неизбежно станет очередной ступенькой в лестнице сложности, требующей всё более изощрённых инструментов для отладки и сопровождения. Проблема не в оптимизации алгоритмов, а в экспоненциальном росте ожиданий проджект-менеджеров.
Вопрос не в том, чтобы создать «зелёный» искусственный интеллект, а в том, чтобы отсрочить момент, когда серверная ферма окончательно поглотит бюджет. Заманчиво говорить о перспективах масштабирования, но история показывает, что каждая инновация порождает новые узкие места. Вместо погони за идеальной архитектурой, возможно, стоит сосредоточиться на более прозаичных задачах — например, на разработке инструментов, позволяющих быстро откатываться к предыдущим версиям, когда «оптимизированный» код начинает генерировать случайные иероглифы.
Нам не нужны новые парадигмы — нам нужно больше здравого смысла. Предложенные методы дистилляции и урезания параметров, вероятно, найдут применение в ближайшем будущем. Но стоит помнить, что любая оптимизация — это компромисс. И рано или поздно, проджект-менеджер найдёт способ превратить экономию энергии в требование к увеличению вычислительной мощности.
Оригинал статьи: https://arxiv.org/pdf/2601.21503.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Иллюзия Компетентности: Как ИИ Переоценивает Себя
2026-02-01 20:14