Автор: Денис Аветисян
Новый подход позволяет оптимизировать сложные запросы в системах, использующих извлечение информации и генерацию текста, повышая их эффективность и качество ответов.
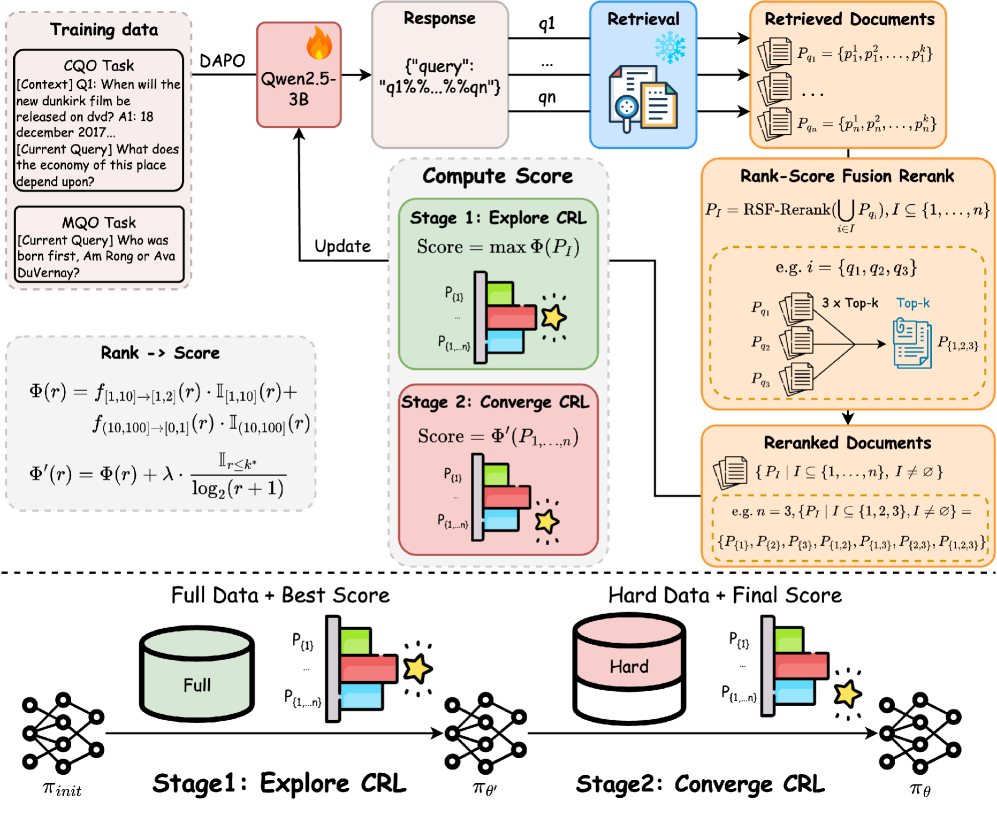
В статье представлена ACQO — платформа обучения с подкреплением, адаптирующая сложные запросы для систем Retrieval-Augmented Generation и обеспечивающая передовые результаты.
Несмотря на значительные успехи в области генеративных систем, оптимизация запросов для извлечения релевантной информации остаётся сложной задачей, особенно при работе со сложными пользовательскими запросами. В статье ‘When should I search more: Adaptive Complex Query Optimization with Reinforcement Learning’ предложен новый подход к адаптивной оптимизации запросов, использующий обучение с подкреплением для эффективной обработки многокомпонентных поисковых задач. Разработанный фреймворк ACQO динамически определяет необходимость расширения поиска и обеспечивает стабильное обучение за счёт модулей адаптивной декомпозиции запросов и агрегации результатов. Способен ли этот подход кардинально повысить эффективность систем Retrieval-Augmented Generation и открыть новые горизонты для работы с большими языковыми моделями?
Поиск в Хаосе: Проблема Понимания Естественного Языка
Несмотря на впечатляющий прогресс в области больших языковых моделей, эффективное преобразование естественного языка в действенные поисковые запросы остаётся серьёзной проблемой. Современные системы часто испытывают трудности с интерпретацией сложных формулировок и многозначных выражений, что приводит к неточным результатам поиска и ограниченному доступу к необходимой информации. Проблема заключается не только в сопоставлении ключевых слов, но и в способности системы правильно понять запрос пользователя и сформулировать запрос, точно отражающий его намерения. Даже самые продвинутые модели иногда не могут уловить контекст и нюансы языка, что существенно ограничивает их эффективность в реальных сценариях поиска и анализа данных.
Традиционные методы обработки естественного языка часто оказываются неэффективными при работе с тонкостями значения и сложными логическими конструкциями. Это приводит к тому, что поисковые системы выдают неоптимальные результаты, не соответствующие истинным потребностям пользователя. Проблема заключается не только в простом сопоставлении ключевых слов, но и в неспособности систем уловить контекст и смысл запроса, что существенно ограничивает доступ к релевантной информации. В результате, даже при наличии огромных объемов данных, пользователи сталкиваются с трудностями в поиске действительно нужных сведений, поскольку системы не могут адекватно интерпретировать сложные вопросы и запросы, требующие глубокого понимания языка.
Суть сложности в области понимания естественного языка заключается не в простом сопоставлении ключевых слов, а в распознавании истинного намерения пользователя и формулировании запроса, точно отражающего это намерение. Современные системы часто терпят неудачу, когда сталкиваются с неявными запросами или многозначностью, поскольку они фокусируются на поверхностном анализе текста, а не на глубоком понимании контекста и скрытых потребностей. Успешная обработка естественного языка требует способности выходить за рамки буквального смысла слов, анализировать смысл фразы в целом и предвидеть, какую информацию пользователь действительно ищет. Именно способность к интерпретации и точному переводу намерений является ключевым фактором для создания эффективных систем поиска и интеллектуальных помощников.
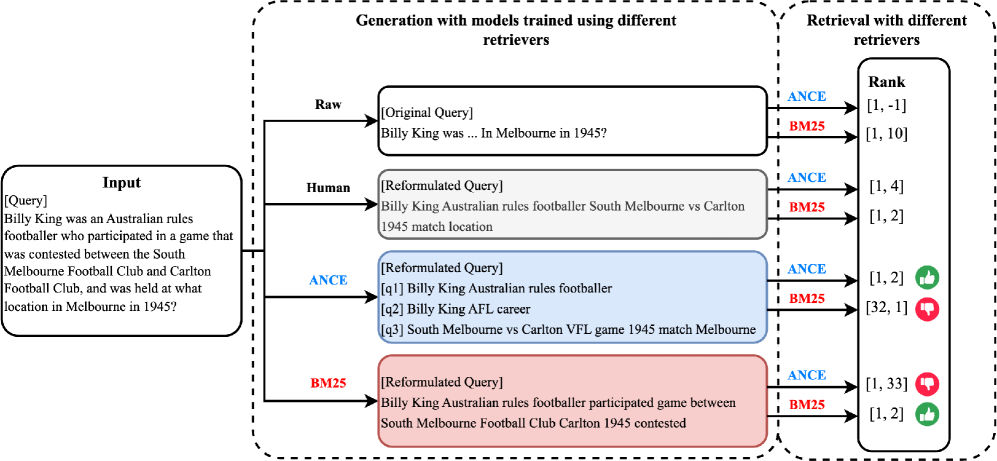
Расширение Горизонтов: Одиночные и Псевдодокументальные Подходы
Расширение исходного запроса с включением связанных понятий является ключевой стратегией для повышения охвата поиска (recall) без снижения точности (precision). Метод Single-Query Expansion (SQE) реализует этот подход, добавляя к первоначальному запросу термины, семантически связанные с ним. Это позволяет системе находить документы, которые могут не содержать точные ключевые слова из исходного запроса, но релевантны по смыслу. На наборе данных HotpotQA, при использовании извлекателя ANCE, применение SQE демонстрирует улучшение показателей MAP@10 до 49.6% и точности (ACCL) до 31.6%, подтверждая эффективность данного метода расширения запросов.
Генерация псевдодокументов представляет собой проактивный метод расширения поискового запроса, заключающийся в преобразовании исходного запроса в более длинный и детализированный документ. Этот расширенный документ служит источником более богатого контекста для поиска, позволяя системе извлечения информации лучше понять намерения пользователя и идентифицировать релевантные результаты. В частности, при использовании на наборе данных HotpotQA с извлекателем ANCE, наблюдается улучшение показателей MAP@10 до 49.6% и точности (ACCL) до 31.6%, что демонстрирует эффективность данного подхода.
Целью применения методов расширения запроса и генерации псевдо-документов является преодоление семантического разрыва между запросом пользователя и доступной информацией, что способствует повышению релевантности и полноты результатов поиска. На наборе данных HotpotQA при использовании поисковой системы ANCE наблюдается улучшение метрики MAP@10 до 49.6% и точности (ACCL) до 31.6%, что демонстрирует эффективность данных подходов в задачах вопросно-ответных систем.

Динамическая Подстройка: Интерактивное и Агентное Обучение
Интерактивное обучение предполагает создание обратной связи, позволяющей системе уточнять поисковые запросы на основе взаимодействия с пользователем и его предпочтений. Этот процесс выходит за рамки пассивного извлечения информации, обеспечивая совместный опыт поиска, в котором система адаптируется к потребностям пользователя со временем. Пользовательские действия, такие как выбор релевантных результатов или явное указание на неточность, используются для корректировки алгоритма формирования запросов, что приводит к повышению точности и релевантности последующих ответов. Такой подход позволяет системе обучаться на индивидуальных особенностях каждого пользователя, оптимизируя процесс поиска и обеспечивая более персонализированный опыт.
В отличие от традиционного пассивного поиска информации, предлагаемый подход обеспечивает совместный опыт взаимодействия, где система адаптируется к потребностям пользователя со временем. Это достигается за счет реализации обратной связи, позволяющей системе уточнять поисковые запросы на основе действий и предпочтений пользователя. В результате система не просто предоставляет результаты, соответствующие исходному запросу, а активно изучает и понимает намерения пользователя, что приводит к повышению релевантности и точности предоставляемой информации. Данный процесс обучения позволяет системе динамически адаптироваться к изменяющимся потребностям пользователя, обеспечивая более эффективный и персонализированный поиск.
В рамках развития интерактивного обучения, агентное обучение с использованием обучения с подкреплением (RL) и расширенными возможностями рассуждения позволяет создавать агентов, способных автономно оптимизировать запросы и анализировать информацию. Предложенный нами фреймворк Adaptive Complex Query Optimization (ACQO) демонстрирует значительное повышение производительности: ускорение в 9.1 раза и задержку вывода 355 мс по сравнению с ConvSearch-R1 (3255 мс). При использовании разреженной выборки (sparse retrieval) ACQO достигает показателя MRR@3 равного 34.9% и R@10 равного 62.6% на датасете TopiOCQA.
Эта работа, посвященная адаптивной оптимизации сложных запросов с использованием обучения с подкреплением, не вызывает особого удивления. Постоянно приходится наблюдать, как элегантные теоретические построения разбиваются о суровую реальность продакшена. Авторы предлагают ACQO — систему, которая, судя по всему, пытается выжать максимум из Retrieval-Augmented Generation, оптимизируя запросы на лету. Как всегда, сначала всё выглядит красиво в научных статьях, а потом начинается самое интересное — интеграция и масштабирование. Как сказал Давид Гильберт: «В математике нет рая, а только блаженное удовлетворение от поиска». Похоже, в разработке программного обеспечения та же история — сначала блаженство от поиска решения, а потом — вечное исправление багов и накопление технического долга. И не удивляйтесь, если через пару лет это снова назовут AI и получат инвестиции.
Что дальше?
Представленный подход, использующий обучение с подкреплением для оптимизации сложных запросов в системах генерации с поиском, несомненно, демонстрирует улучшение показателей. Однако, если система стабильно падает, значит, она хотя бы последовательна. Вопрос в том, насколько быстро эта «оптимизация» деградирует при столкновении с реальностью, а именно — с бесконечным разнообразием пользовательских запросов и постоянно меняющимися данными. Забудьте о «state-of-the-art» — скоро появятся новые «state-of-the-art», и все придется начинать сначала.
Вместо погони за очередным алгоритмом, возможно, стоит обратить внимание на фундаментальные ограничения самой архитектуры. «Cloud-native» — это просто то же самое, только дороже. Более того, настоящей проблемой является не оптимизация запросов как таковая, а необходимость их постоянной генерации. Если мы не пишем код — мы просто оставляем комментарии будущим археологам, пытающимся понять, почему всё так сложно.
Будущие исследования, вероятно, будут направлены на создание более устойчивых и адаптивных систем, способных самостоятельно диагностировать и исправлять ошибки. Но, как показывает опыт, каждое «революционное» решение неизбежно порождает новый техдолг. И в конечном итоге, всё сведется к тому, чтобы снова и снова переписывать код, пытаясь удержаться на плаву в море данных.
Оригинал статьи: https://arxiv.org/pdf/2601.21208.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Робот-исследователь: новый подход к автономной навигации
- Самообучающиеся признаки: новый подход к машинному обучению
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Биомолекулярные связи: новый тест для искусственного интеллекта
2026-02-01 21:51