Автор: Денис Аветисян
Новое исследование показывает, что современные модели компьютерного зрения, несмотря на схожие конечные результаты, используют принципиально разные подходы к анализу изображений.

Анализ слоев сверточных нейронных сетей выявил значительные расхождения в удержании признаков и последовательности обработки информации, несмотря на конвергенцию представлений.
Несмотря на растущий интерес к универсальности представлений в современных моделях компьютерного зрения, механизмы, приводящие к этим сходствам, остаются недостаточно изученными. В работе ‘Similarity of Processing Steps in Vision Model Representations’ исследуется, как различные архитектуры достигают схожих представлений, фокусируясь на промежуточных этапах обработки. Полученные результаты показывают, что, хотя модели и сходятся к общим представлениям, пути достижения этих результатов существенно различаются, особенно в части удержания низкоуровневых признаков и последовательности изменений между слоями. Какие факторы определяют эти различия и как можно использовать эти знания для разработки более эффективных и интерпретируемых моделей компьютерного зрения?
Разоблачение Чёрного Ящика: Необходимость Интерпретируемых Представлений
Современные модели компьютерного зрения, несмотря на впечатляющую эффективность в решении различных задач, зачастую функционируют как “чёрные ящики”. Это означает, что внутренние механизмы принятия решений остаются непрозрачными для человека: сложно понять, какие признаки изображения модель считает ключевыми для распознавания объекта или принятия того или иного решения. Такая непрозрачность не только препятствует установлению доверия к системе, но и существенно затрудняет диагностику ошибок и оптимизацию производительности. Вместо четкого понимания логики работы, пользователи вынуждены полагаться исключительно на входные и выходные данные, что ограничивает возможности улучшения и адаптации моделей к новым условиям. По сути, невозможность “заглянуть внутрь” снижает потенциал этих мощных инструментов и сдерживает дальнейший прогресс в области компьютерного зрения.
Отсутствие прозрачности в работе современных моделей компьютерного зрения серьезно подрывает доверие к ним и создает значительные трудности при выявлении причин ошибок. Если сложно понять, какие признаки изображения повлияли на принятое моделью решение, становится практически невозможным эффективно диагностировать сбои и устранять уязвимости. Это, в свою очередь, ограничивает возможности дальнейшего улучшения производительности и надежности систем, поскольку без понимания внутренних механизмов оптимизация становится методом проб и ошибок. Неспособность объяснить логику работы модели особенно критична в областях, где требуются высокая точность и безошибочность, таких как медицина или автономное вождение, где последствия неправильной интерпретации данных могут быть катастрофическими.
Понимание того, как современные модели компьютерного зрения представляют визуальную информацию, является фундаментальным шагом для дальнейшего развития этой области. Вместо простого достижения высокой точности, исследователи все больше внимания уделяют анализу внутренних механизмов, определяющих, какие признаки изображения модель считает наиболее важными. Это позволяет не только выявлять и устранять предвзятости или ошибки в процессе принятия решений, но и вдохновляться принципами работы этих систем для создания более эффективных алгоритмов, имитирующих человеческое восприятие. Глубокое понимание внутренней репрезентации визуальных данных открывает путь к разработке моделей, способных не просто распознавать объекты, но и объяснять свои решения, что критически важно для применения компьютерного зрения в ответственных областях, таких как медицина и автономное вождение.
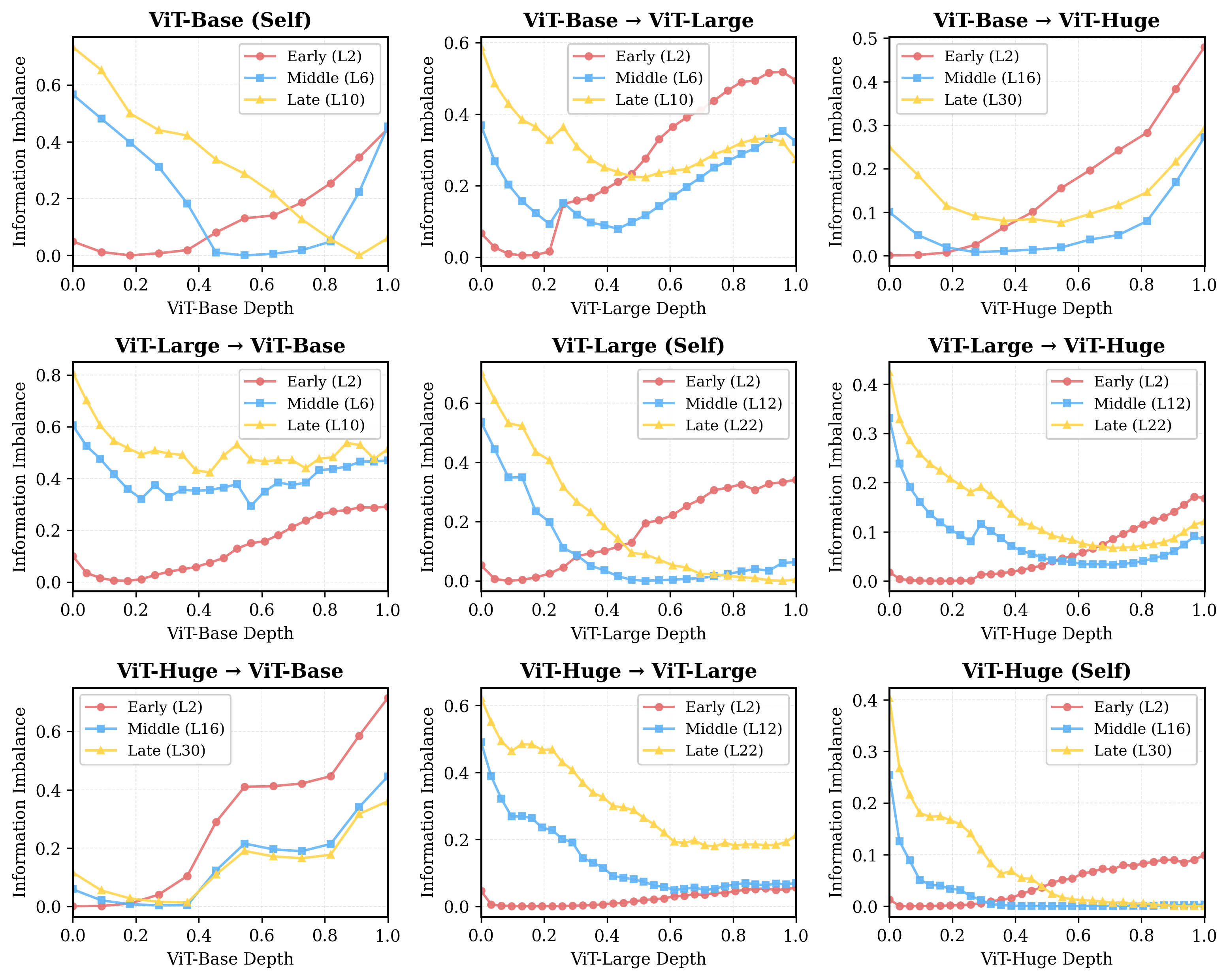
Разбор Визуального Понимания: Слои и Низкоуровневые Признаки
Начальные слои моделей компьютерного зрения преимущественно обрабатывают низкоуровневые признаки, такие как границы и текстуры. Эти признаки обнаруживаются с помощью методов анализа изображений, включая детекцию границ (например, операторы Собеля, Превитта, Канни) и анализ текстур, использующий статистические методы (например, матрицу совместной встречаемости) или фильтры Габора. Обнаружение границ позволяет выделить контуры объектов, а анализ текстур идентифицирует повторяющиеся паттерны, что обеспечивает основу для последующего распознавания более сложных форм и объектов. Эти низкоуровневые признаки служат строительными блоками для представления изображения и их извлечение является критически важным этапом в процессе визуального анализа.
Анализ последовательных слоев визуальной модели позволяет отследить трансформацию низкоуровневых признаков, таких как границы и текстуры, по мере распространения информации внутри сети. Сравнивая активации на разных слоях, можно определить, как эти базовые признаки комбинируются и преобразуются для формирования более сложных представлений. Этот метод включает в себя измерение изменений в статистических характеристиках активаций, например, среднего значения и дисперсии, а также анализ корреляции между нейронами на последовательных слоях, что позволяет выявить закономерности в процессе формирования признаков и понять, какие признаки являются наиболее важными для решения конкретной задачи.
Анализ слоев нейронных сетей компьютерного зрения демонстрирует иерархическую структуру обработки информации. Ранние слои сети специализируются на выявлении элементарных признаков, таких как простые формы, края и текстуры. По мере продвижения информации через последующие слои происходит их комбинирование и преобразование в более сложные представления. Более поздние слои отвечают за сборку этих элементарных признаков в целостные объекты и концепции, что позволяет сети распознавать сложные сцены и объекты. Таким образом, структура сети отражает постепенный переход от обнаружения базовых характеристик к пониманию сложных визуальных данных.

Согласованность Между Моделями: К Универсальным Визуальным Представлениям
Сравнение представлений, полученных различными моделями компьютерного зрения (ViT, ConvNeXt, iGPT, DINOv2), демонстрирует неожиданную согласованность в извлечении признаков. Анализ показывает, что несмотря на существенные различия в архитектуре и методах обучения, модели часто идентифицируют и кодируют одни и те же визуальные элементы. Это проявляется в высокой корреляции между векторами признаков, полученными из разных моделей для одних и тех же изображений. Выявленная согласованность не является случайной и указывает на наличие общих, фундаментальных принципов, определяющих визуальное восприятие и обработку изображений, независимо от конкретной реализации модели.
Для выявления общих признаков в представлениях, полученных различными архитектурами моделей компьютерного зрения (ViT, ConvNeXt, iGPT, DINOv2), применяются методы кросс-модельного сравнения и анализа информационного дисбаланса. Информационный дисбаланс, измеренный в диапазоне от 0.05 до 0.9, количественно оценивает степень согласованности представлений между моделями для конкретных визуальных признаков. Низкий дисбаланс указывает на высокую степень согласованности, что позволяет идентифицировать признаки, стабильно кодируемые различными моделями, несмотря на различия в их архитектуре и процессе обучения. Этот подход позволяет выделить ключевые визуальные концепции, общие для различных моделей, и оценить их относительную значимость в процессе визуального понимания.
Анализ представлений, полученных различными моделями компьютерного зрения (ViT, ConvNeXt, iGPT, DINOv2), указывает на возможность существования “универсальных представлений” — базовых визуальных концепций, которые являются основополагающими для понимания изображений независимо от используемой архитектуры модели. Это предполагает, что определенные признаки и паттерны, идентифицируемые разными моделями, отражают фундаментальные свойства визуального мира, а не являются артефактами конкретного алгоритма обучения или архитектуры сети. Обнаружение таких универсальных представлений может способствовать разработке более надежных и обобщающих систем компьютерного зрения, способных эффективно работать в различных условиях и с разными типами изображений.
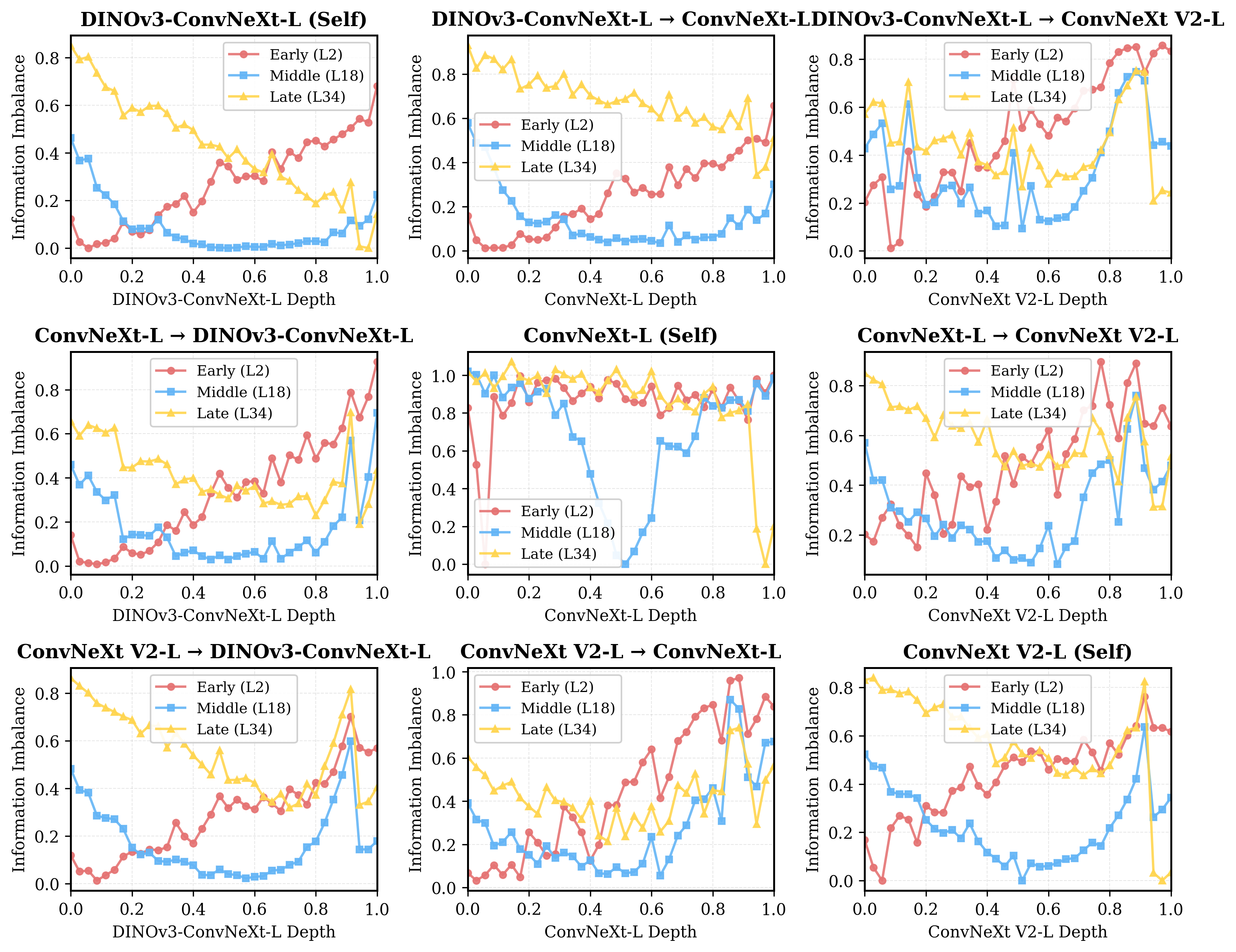
Картирование Визуального Мира: Организация Соседства и Абстрактная Семантика
Анализ организации соседних элементов в репрезентативном пространстве позволяет выявить, как модели группируют изображения, соответствующие схожим концепциям. Исследование структуры этого пространства показывает, что изображения, представляющие объекты или сцены с общими характеристиками, располагаются близко друг к другу. Близость в этом пространстве отражает семантическое сходство, то есть, насколько тесно связаны значения, которые модель извлекает из этих изображений. Таким образом, структура соседства является индикатором того, как модель категоризирует и обобщает визуальную информацию, создавая кластеры изображений, объединенных общим смыслом.
В более поздних слоях нейронных сетей наблюдается тенденция к представлению абстрактной семантики, что проявляется в группировке изображений на основе высокоуровневого значения, а не низкоуровневых признаков, таких как текстура или края. Это означает, что модель переходит от распознавания простых визуальных элементов к пониманию концептуального содержания изображений. Вместо кластеризации изображений по схожим пиксельным характеристикам, более глубокие слои формируют группы на основе общих объектов, сцен или действий, представленных на изображениях. Данный процесс отражает способность модели к извлечению и обобщению семантической информации, что позволяет ей эффективно классифицировать и понимать визуальный контент.
Повышение точности зондирования (probing accuracy) на независимых (out-of-domain) наборах данных с увеличением глубины слоя нейронной сети свидетельствует о том, что модель последовательно извлекает значимую информацию из изображений и организует ее когерентным образом. Более глубокие слои демонстрируют улучшенную способность к обобщению, поскольку они кодируют более абстрактные представления, менее зависящие от конкретных деталей входных изображений, используемых при обучении. Это подтверждает, что модель не просто запоминает тренировочные данные, а формирует обобщенные концептуальные представления, которые могут быть применены к новым, ранее не встречавшимся изображениям.
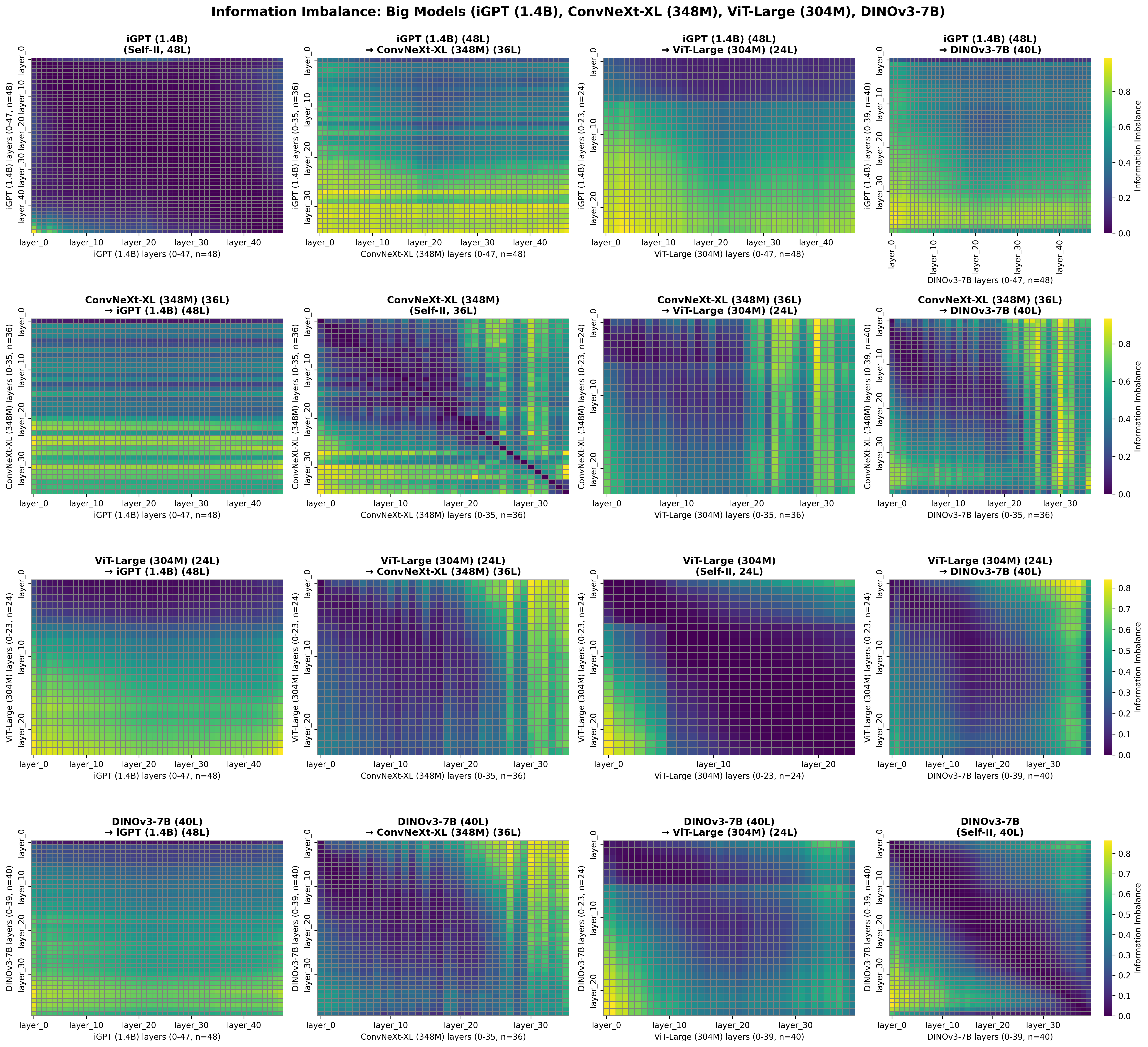
К Надёжному и Обобщающему Зрению: Перспективы Будущего
Разработка надежных и обобщающих моделей компьютерного зрения требует смещения фокуса на универсальные представления визуальной информации. Вместо обучения распознаванию конкретных объектов, перспективные исследования направлены на понимание внутренней организации визуальных данных — как различные элементы связаны между собой, как формируются паттерны и как эти паттерны позволяют интерпретировать окружающий мир. Такой подход позволяет моделям не просто «запоминать» изображения, а действительно «понимать» их содержание, что критически важно для адаптации к новым, ранее не встречавшимся ситуациям и повышения устойчивости к шуму и вариациям в данных. Подобное представление позволяет системам эффективно обобщать знания, полученные при обработке одного набора изображений, на совершенно другие визуальные сцены, приближая их к человеческому зрению и открывая новые возможности в области автоматизированного анализа изображений.
Методы самообучения и дистилляции, продемонстрированные в модели DINOv2, открывают новые возможности для углубленного изучения визуальных представлений. Самообучение позволяет модели извлекать полезные признаки из неразмеченных данных, значительно расширяя возможности обучения без необходимости в трудоемкой ручной разметке. Дистилляция, в свою очередь, позволяет передавать знания от более крупной, сложной модели к более компактной, сохраняя при этом высокую производительность. Сочетание этих техник способствует созданию более эффективных и устойчивых моделей компьютерного зрения, способных к обобщению и адаптации к различным условиям и задачам. Дальнейшие исследования в этой области направлены на оптимизацию этих методов и их применение для решения широкого круга задач обработки изображений.
Исследования архитектуры ConvNeXt выявили заметное отличие в организации внутренних представлений по сравнению с другими моделями. В частности, стандартное отклонение различий между слоями оказалось значительно выше (более 0.1), что указывает на менее плавные и согласованные переходы между последовательными уровнями обработки информации. Это свидетельствует о потенциально иной стратегии извлечения признаков, которая, несмотря на свою эффективность, требует дальнейшего изучения. Предполагается, что данная особенность может быть использована в решении специализированных задач, где требуется акцент на определенные аспекты визуальной информации. В связи с этим, будущие исследования направлены на то, чтобы понять, каким образом эти представления можно эффективно использовать в downstream-задачах и как целенаправленное обучение может улучшить согласованность внутренних слоев, потенциально повышая общую производительность и обобщающую способность модели.
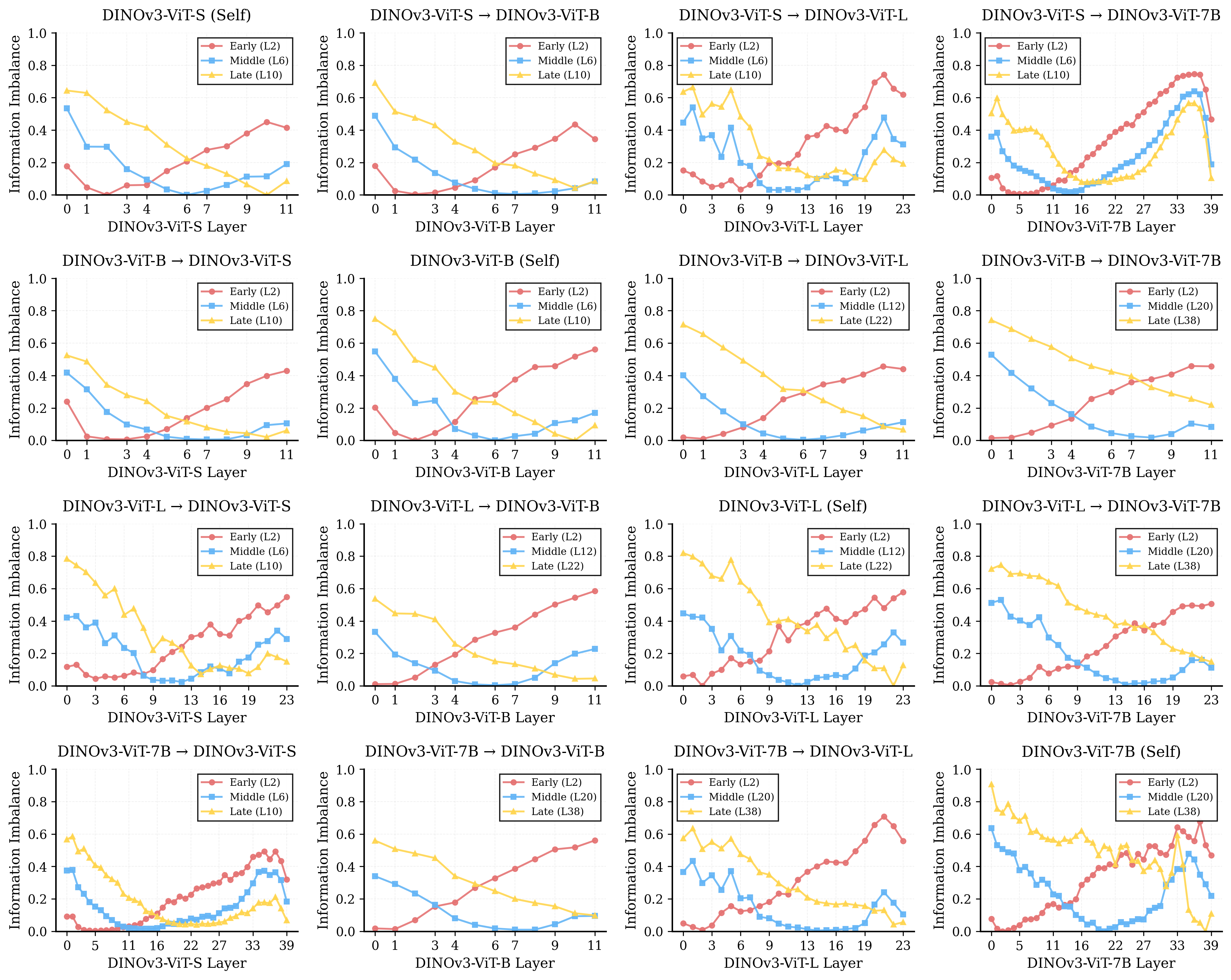
В статье рассматривается сходимость представлений в моделях компьютерного зрения, причём акцент делается на различия в способах достижения этих представлений. Забавно, что модели сходятся к похожим результатам, но пути к ним оказываются совершенно разными, с разной степенью сохранения признаков по слоям. Как точно подметил Эндрю Ын: «Самая большая проблема в машинном обучении — это не недостаток алгоритмов, а недостаток данных». В данном исследовании, наблюдая расхождения в обработке информации между слоями, можно предположить, что проблема не только в алгоритмах, но и в способах представления и балансировки данных на каждом этапе обучения. Все эти красивые схемы с «универсальными» представлениями рано или поздно выливаются в необходимость ручной настройки и тонкой балансировки, как это уже бывало не раз.
Что дальше?
Наблюдаемая конвергенция представлений в моделях компьютерного зрения, несмотря на расхождения в промежуточных этапах обработки, предсказуема. Система всегда найдёт способ достигнуть результата, вопрос лишь в количестве потраченных ресурсов и элегантности пути. Удивительно не то, что представления сходятся, а то, насколько разными могут быть маршруты к ним — и, следовательно, насколько хрупко наше понимание этих маршрутов. В конечном счёте, “универсальность” представления — это лишь констатация факта, а не объяснение принципов его формирования.
Дальнейшие исследования неизбежно столкнутся с проблемой информационного дисбаланса. Устойчивость к шуму и искажениям — это, конечно, хорошо, но куда важнее понять, что система забывает при достижении конечного результата. Какие детали, критичные для более тонкого анализа, теряются в процессе, и возможно ли их сохранить, не нарушив при этом общую производительность? Сомневаюсь, что возможно, но попытки всё равно будут. Мы не чиним продакшен — мы просто продлеваем его страдания.
Вместо поиска универсальных шагов обработки, вероятно, стоит сосредоточиться на анализе ошибок в этих шагах. Что заставляет модель игнорировать определённые признаки? Где возникают узкие места в передаче информации между слоями? Эти вопросы, возможно, окажутся более плодотворными, чем попытки создать идеальный, единообразный алгоритм. Ведь в конечном итоге, каждый релиз — это просто новый способ сломать старый.
Оригинал статьи: https://arxiv.org/pdf/2601.21621.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
2026-02-02 01:06