Автор: Денис Аветисян
Исследователи разработали систему моделирования судебных дебатов с участием нескольких искусственных интеллектов для повышения надежности и объяснимости прогнозов в сложных задачах, таких как оценка риска рецидива.

Представлен AgenticSimLaw — структурированный фреймворк для многоагентных дебатов, повышающий прозрачность и контролируемость логических выводов на основе табличных данных.
Несмотря на успехи больших языковых моделей (LLM) в решении сложных задач, обеспечение прозрачности и контролируемости процесса принятия решений остается сложной задачей. В данной работе представлена система ‘AgenticSimLaw: A Juvenile Courtroom Multi-Agent Debate Simulation for Explainable High-Stakes Tabular Decision Making’, реализующая структурированный многоагентный подход к дебатам, моделирующим судебный процесс, для повышения объяснимости и надежности работы с табличными данными. Эксперименты на задаче прогнозирования рецидивов показали, что предложенный подход обеспечивает более стабильные и обобщаемые результаты по сравнению с традиционными методами, основанными на последовательном промптинге. Возможно ли дальнейшее развитие подобных систем для решения других задач, требующих высокой степени ответственности и аудита?
Пределы «Черного Ящика» в Прогнозировании
Традиционные методы машинного обучения, такие как COMPAS и XGBoost, демонстрируют значительную прогностическую силу, однако их внутренняя работа зачастую остается непрозрачной, что вызывает серьезные опасения относительно справедливости принимаемых решений. Эти алгоритмы, эффективно предсказывающие определенные исходы, не предоставляют четких объяснений, как именно они пришли к тому или иному выводу. Отсутствие интерпретируемости затрудняет выявление потенциальных предвзятостей, встроенных в модель, и препятствует проверке корректности прогнозов. Это особенно критично в областях, где решения оказывают существенное влияние на жизнь людей, например, в системе уголовного правосудия или при оценке кредитоспособности. Невозможность понять логику работы алгоритма подрывает доверие к нему и ставит под вопрос этичность его применения.
Алгоритмы машинного обучения, функционирующие как “черный ящик”, зачастую выдают прогнозы без возможности предоставить понятное обоснование принятого решения. Эта непрозрачность критически снижает доверие к ним, особенно в ситуациях, где результаты оказывают значительное влияние на жизнь людей, например, при принятии решений о предоставлении кредитов или в судебной системе. Отсутствие объяснимости не позволяет проверить логику работы алгоритма, выявить потенциальные предубеждения и обеспечить подотчетность системы, что вызывает серьезные опасения в контексте справедливости и этичности применения подобных технологий. Невозможность понять, почему алгоритм пришел к определенному выводу, лишает людей возможности оспорить решение и требует разработки новых методов, обеспечивающих прозрачность и объяснимость в сфере искусственного интеллекта.
Непрозрачность современных предсказательных систем, таких как алгоритмы оценки рисков, существенно затрудняет эффективный контроль за их работой и выявление скрытых предубеждений. Отсутствие возможности детально проследить логику принятия решений не позволяет оценить, какие факторы оказывают решающее влияние на прогноз, и, следовательно, установить, не дискриминируют ли эти системы определенные группы населения. В результате, выявление и устранение потенциальных ошибок или предвзятости в алгоритмах становится крайне сложной задачей, что ставит под вопрос справедливость и надежность предсказаний, особенно в сферах, где ставки высоки, например, в уголовном правосудии или при приеме на работу. Подобная «черноящичность» препятствует не только внешней оценке, но и внутреннему аудиту, ограничивая возможности для улучшения и повышения доверия к этим технологиям.
Многоагентные Системы на Основе LLM: Новый Подход
Многоагентные системы на основе больших языковых моделей (LLM-based Multi-Agent Systems, LaMAS) представляют собой перспективную альтернативу традиционным подходам к решению сложных задач. В отличие от монолитных систем, LaMAS используют возможности языковых моделей для анализа, планирования и принятия решений, распределяя эти процессы между несколькими взаимодействующими агентами. Это позволяет эффективно обрабатывать задачи, требующие многоступенчатого рассуждения, адаптации к меняющимся условиям и интеграции различных источников информации. Ключевым преимуществом является возможность использования предварительно обученных языковых моделей, что значительно сокращает время и ресурсы, необходимые для разработки и развертывания системы.
Для повышения надежности и глубины рассуждений в системах на основе больших языковых моделей (LLM) используются такие методы, как Chain of Thought (CoT), Tree of Thought (ToT) и Self-Consistency (SC). Метод CoT предполагает побуждение модели к генерации промежуточных шагов рассуждений, что улучшает интерпретируемость и точность. Tree of Thought (ToT) расширяет эту концепцию, позволяя модели исследовать несколько путей рассуждений и выбирать наиболее перспективные. Self-Consistency (SC) предполагает генерацию нескольких ответов на один и тот же вопрос и выбор наиболее часто встречающегося, что повышает устойчивость системы к случайным ошибкам и вариациям в ответах модели. Комбинирование этих методов позволяет значительно улучшить производительность LLM в сложных задачах, требующих логического вывода и планирования.
Многоагентные системы на основе больших языковых моделей (LaMAS) используют распределение процесса рассуждений между несколькими агентами для повышения надежности и эффективности решения задач. Вместо централизованного подхода, каждый агент может исследовать различные аспекты проблемы и предлагать альтернативные решения. Этот параллельный анализ позволяет охватить более широкий спектр возможных подходов и снизить риск ошибок, связанных с предвзятостью или неполнотой информации, доступной одному агенту. Объединение результатов рассуждений, полученных от разных агентов, позволяет синтезировать более обоснованные и устойчивые решения, особенно в сложных и неоднозначных ситуациях.
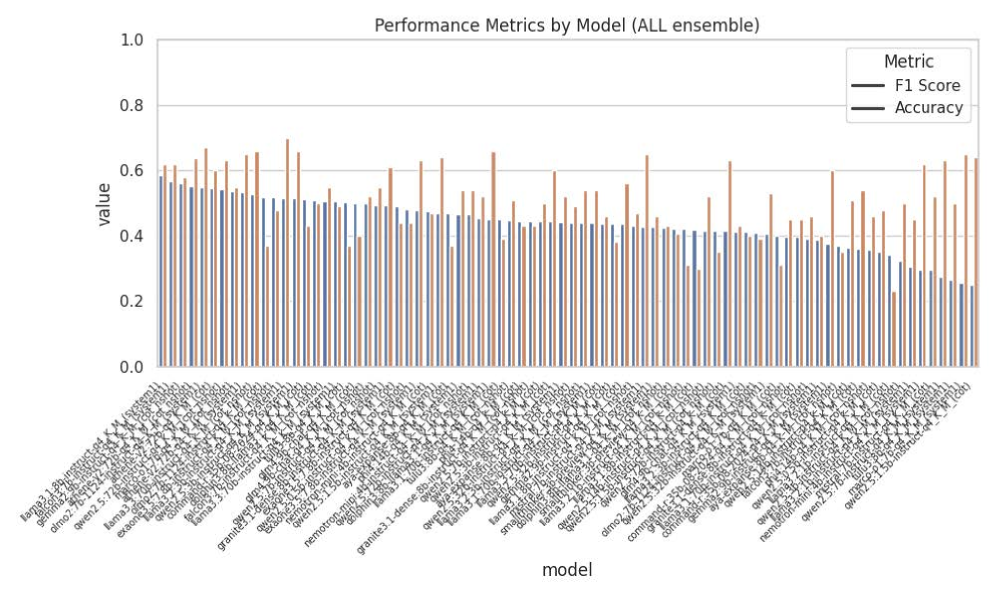
AgenticSimLaw: Рамки для Прозрачного Рассуждения
В основе AgenticSimLaw лежит структура, имитирующая судебный процесс, где несколько агентов искусственного интеллекта берут на себя чётко определённые роли — обвинителя и защитника. Этот подход предполагает совместное рассуждение о заданной ситуации, в рамках которого агенты последовательно выдвигают аргументы и контраргументы, представляя различные точки зрения. Распределение ролей позволяет систематически исследовать проблему, охватывая широкий спектр возможных обоснований и возражений, что отличает данный метод от одноагентного подхода к решению задач.
В основе AgenticSimLaw лежит структурированный 7-шаговый протокол взаимодействия, предназначенный для организации дебатов между агентами. Этот протокол последовательно определяет роли агентов (например, обвинение и защита) и предоставляет им возможность поочередно представлять аргументы и контраргументы. Каждый шаг протокола предусматривает конкретную задачу для агента, что обеспечивает всестороннее рассмотрение сценария. Первые шаги обычно посвящены изложению основных тезисов, последующие — детальному обоснованию и представлению доказательств, а завершающие — опровержению контраргументов и подведению итогов. Такая структура гарантирует систематическое и полное исследование проблемы, охватывающее различные аспекты и точки зрения.
В основе AgenticSimLaw лежит полная регистрация всех этапов рассуждений и конфиденциальная разработка стратегий каждым агентом. Это обеспечивает полную отслеживаемость и возможность анализа процесса принятия решений, что позволяет детально изучить логику каждого участника. В результате, данная архитектура демонстрирует более высокую корреляцию между точностью и F1-мерой по сравнению с подходами, использующими одиночного агента, что свидетельствует о более надежной и обоснованной системе рассуждений.
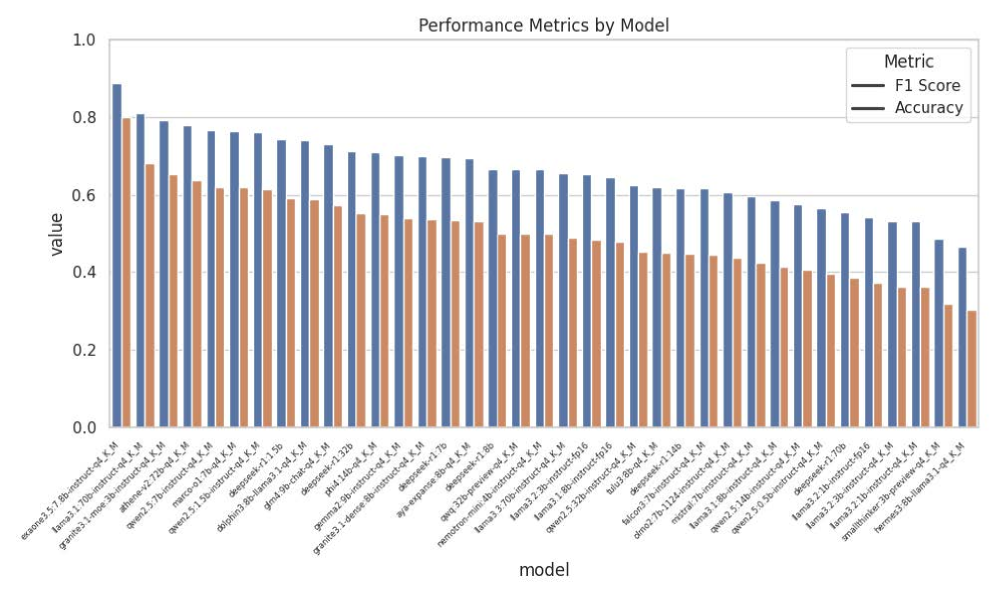
Укрепление Доверия и Ответственности в ИИ
Система AgenticSimLaw уделяет первостепенное внимание прозрачности, напрямую поддерживая принципы объяснимого искусственного интеллекта (XAI). Данный подход позволяет не просто получать результаты от алгоритмов, но и понимать логику, лежащую в основе этих решений. Обеспечивая доступность внутренних процессов, система способствует укреплению доверия к автоматизированным системам принятия решений, что критически важно для их широкого внедрения. Повышенная прозрачность позволяет заинтересованным сторонам оценивать обоснованность действий ИИ, выявлять потенциальные ошибки или предвзятости и, в конечном итоге, принимать более взвешенные решения на основе предоставленной информации. По сути, AgenticSimLaw не просто предоставляет ответы, а раскрывает процесс их получения, что является ключевым фактором для формирования устойчивого доверия и принятия ИИ.
Система AgenticSimLaw предоставляет возможности для тщательной проверки процессов рассуждений, что является ключевым фактором в выявлении и смягчении потенциальных предубеждений. Благодаря встроенным функциям аудита, исследователи и разработчики могут детально изучить логику принятия решений искусственным интеллектом, отследить последовательность шагов и выявить возможные источники систематических ошибок. Это позволяет не только повысить надежность и справедливость алгоритмов, но и обеспечить соответствие этическим нормам и требованиям регуляторов. Тщательная верификация процессов рассуждений способствует созданию более прозрачных и ответственных систем искусственного интеллекта, заслуживающих доверие со стороны пользователей и общества.
Система AgenticSimLaw способствует глубокому пониманию внутренней логики искусственного интеллекта, предоставляя заинтересованным сторонам возможность осуществлять более эффективный контроль и обеспечивать ответственность. Обеспечивая прозрачность процессов принятия решений, система позволяет не только отслеживать ход вычислений, но и анализировать факторы, влияющие на результат. В ходе тестирования, с использованием крупных моделей, AgenticSimLaw демонстрирует высокую точность — до 0.87 — и показатель F1, подтверждающие надежность и валидность системы в обеспечении контроля и понимания работы сложных алгоритмов, что критически важно для построения доверия к ИИ и его широкого внедрения.
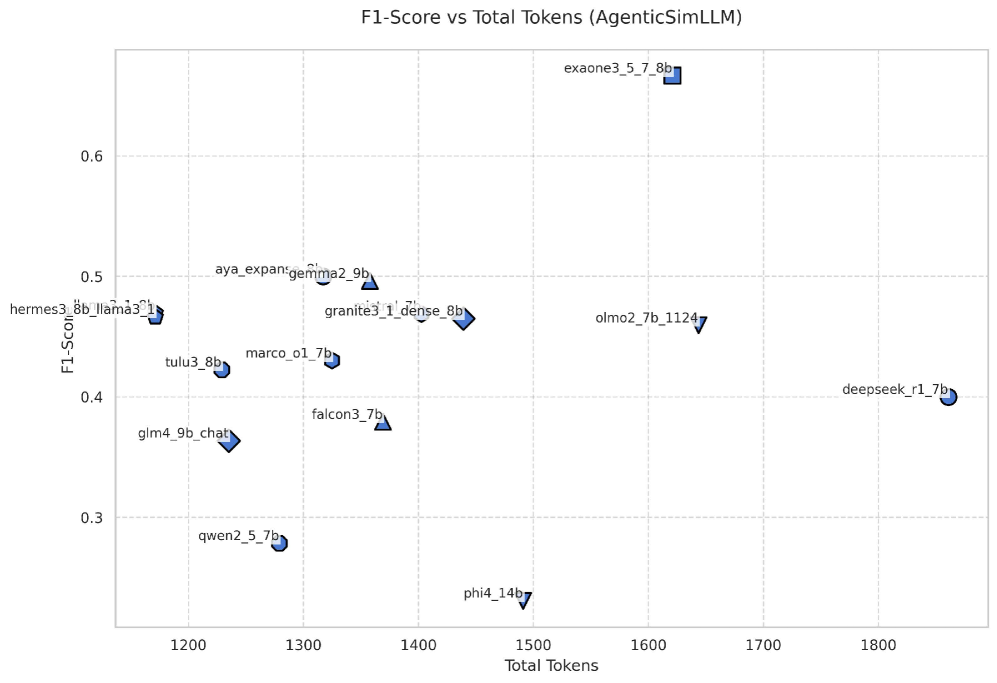
Будущее Развитие: Масштабируемость и Обобщение
Дальнейшие исследования AgenticSimLaw сосредоточены на расширении возможностей системы для обработки более сложных сценариев и больших объемов данных. Для эффективного обучения в условиях растущей сложности рассматривается применение таких методов, как Mixture of Experts (MoE) и LoRA. MoE позволяет системе распределять нагрузку между различными специализированными экспертами, что повышает ее способность к решению разнообразных задач. В свою очередь, LoRA (Low-Rank Adaptation) обеспечивает адаптацию модели к новым данным с минимальными вычислительными затратами, что особенно важно при работе с большими наборами данных. Эти подходы направлены на создание масштабируемой и эффективной системы, способной к решению задач повышенной сложности в различных областях.
Исследование способности AgenticSimLaw адаптироваться к различным областям, таким как юридическое обоснование и медицинская диагностика, представляется ключевым для раскрытия всего потенциала данной системы. Успешная генерализация позволит применять разработанный фреймворк не только для решения задач, связанных с моделированием законов, но и для анализа сложных сценариев в других областях, требующих логического вывода и интерпретации данных. Подобная универсальность значительно расширит сферу применения искусственного интеллекта, способствуя созданию более надежных и эффективных систем поддержки принятия решений в различных отраслях, где критически важна точность и обоснованность выводов.
Для дальнейшего развития искусственного интеллекта, способного к сложному рассуждению, необходимо совершенствование метрик оценки, учитывающих не только точность, но и прозрачность логических цепочек. Современные реализации, хотя и требуют значительно больше вычислительных ресурсов — около 9100 токенов, что в 11-14 раз превышает объем запроса в одношаговой логической цепочке (CoT), — демонстрируют меньшую волатильность метрики F1 и повышенную стабильность в работе. Это указывает на то, что более сложные методы оценки, несмотря на свою ресурсоемкость, способны более надежно измерять качество и обоснованность решений, принимаемых искусственным интеллектом, что является критически важным для областей, требующих высокой степени доверия и объяснимости.
Представленная работа демонстрирует, что эффективная система принятия решений требует не просто обработки данных, но и моделирования взаимодействия между различными агентами. Это особенно актуально в контексте предсказания рецидивов, где односторонний подход может упустить важные нюансы. Как заметил Клод Шеннон: «Информация — это не количество, а содержание». В данном исследовании, AgenticSimLaw, стремясь к большей прозрачности и контролируемости, фактически пытается измерить и структурировать это «содержание», представляя его в виде дебатов между агентами. Такой подход позволяет не только оценить вероятность рецидива, но и понять логику, лежащую в основе этого предсказания, что крайне важно для обеспечения справедливости и этичности принимаемых решений. Структура взаимодействия, созданная в рамках AgenticSimLaw, определяет поведение всей системы, что подтверждает идею о том, что элегантный дизайн рождается из простоты и ясности.
Куда же дальше?
Представленная работа, стремясь к большей прозрачности в принятии решений на основе табличных данных, неизбежно наталкивается на фундаментальную сложность: каждая попытка упростить процесс рассуждений, каждый элемент “объяснимости” имеет свою цену. Система, построенная на дебатах между агентами, не является панацеей, а лишь одним из способов борьбы с внутренней непрозрачностью больших языковых моделей. Очевидно, что стабильность и аудируемость, продемонстрированные в рамках предсказания рецидивов, не гарантируют успех в других, ещё более сложных областях применения.
Будущие исследования, вероятно, должны сосредоточиться не столько на совершенствовании самой модели дебатов, сколько на разработке метрик, способных адекватно оценить качество “объяснений”. Как измерить степень убедительности аргумента, предложенного агентом? Как отличить истинное рассуждение от ловкого самообмана? Эти вопросы, кажущиеся философскими, имеют решающее значение для практического применения подобных систем в областях, связанных с высокой ответственностью.
В конечном счёте, необходимо помнить, что структура определяет поведение. Усложнение системы дебатов само по себе не является решением. Более эффективным подходом может быть поиск более простых, более элегантных архитектур, способных обеспечить необходимую прозрачность без ущерба для точности. Иначе рискуем создать ещё более сложный “чёрный ящик”, прикрытый видимостью дебатов.
Оригинал статьи: https://arxiv.org/pdf/2601.21936.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Искусственный интеллект: хрупкость визуального мышления
- Квантовая механика: скрытый детерминизм?
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
- Текстуры обмана: Как взломать ИИ, управляющий роботами
2026-02-02 04:33