Автор: Денис Аветисян
Новый подход позволяет более эффективно настраивать потоковые модели, используя плотные сигналы вознаграждения и оптимизируя процесс исследования пространства решений.
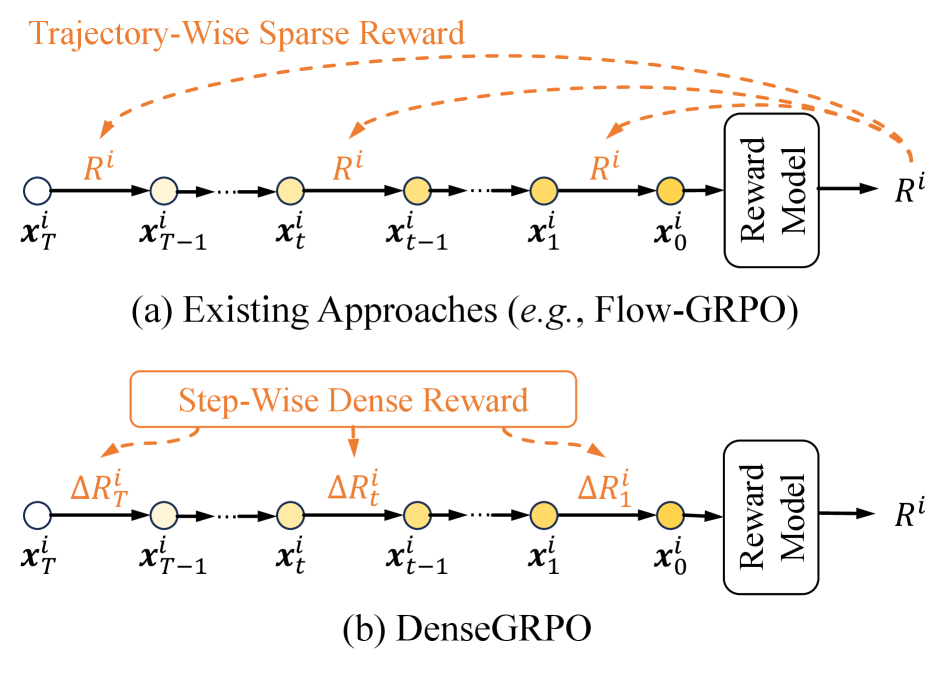
В статье представлена система DenseGRPO, использующая обучение с подкреплением для выравнивания предпочтений пользователей в потоковых моделях, основанном на оценке поэтапных плотных вознаграждений и калибровке пространства исследования.
Несмотря на успехи современных подходов, основанных на групповой относительной оптимизации стратегий (GRPO) и моделях потокового сопоставления, проблема разреженности вознаграждения остается существенным ограничением для эффективной адаптации к предпочтениям пользователей. В данной работе, ‘DenseGRPO: From Sparse to Dense Reward for Flow Matching Model Alignment’ предложен новый фреймворк DenseGRPO, который оценивает вклад каждого шага процесса шумоподавления, используя плотные вознаграждения, и калибрует пространство исследования для более эффективной оптимизации. Ключевым нововведением является предсказание поэтапного прироста вознаграждения и адаптивная настройка стохастичности в процессе дискретизации стохастических дифференциальных уравнений. Позволит ли предложенный подход существенно улучшить качество генерации изображений и раскрыть весь потенциал моделей потокового сопоставления?
Задача Согласования: Преодоление Разреженных Вознаграждений в Генерации Изображений
Современные системы генерации изображений по текстовому описанию, использующие модели потокового сопоставления, всё чаще обращаются к обучению с подкреплением для достижения соответствия человеческим предпочтениям. Этот подход позволяет не просто создавать визуально правдоподобные изображения, но и учитывать субъективные критерии эстетики и соответствия заданному описанию. Обучение с подкреплением позволяет модели учиться на обратной связи, имитируя процесс, в котором человек оценивает и корректирует результат, что особенно важно для достижения высокого качества и детализации в сложных сценах. Таким образом, интеграция обучения с подкреплением становится ключевым фактором в развитии генеративных моделей, позволяя им создавать изображения, которые не только технически совершенны, но и соответствуют ожиданиям пользователя.
В традиционном обучении с подкреплением, применяемом к генерации изображений, часто возникает проблема разреженных вознаграждений. Модель получает сигнал обратной связи — оценку качества сгенерированного изображения — лишь на заключительном этапе длительного процесса. Это означает, что на протяжении множества промежуточных шагов, когда формируется изображение из шума, модель лишена какой-либо информации о том, насколько правильно она движется к желаемому результату. Отсутствие немедленной оценки затрудняет процесс обучения, поскольку модель не может эффективно корректировать свои действия на каждом этапе, что приводит к созданию изображений, не всегда точно соответствующих заданным предпочтениям или требуемой композиции. Эта проблема особенно остро проявляется в сложных задачах генерации, где необходимо учитывать множество факторов для достижения реалистичного и эстетичного результата.
Ограниченность обратной связи в процессе обучения моделей генерации изображений, использующих обучение с подкреплением, существенно затрудняет их эффективную настройку. Проблема заключается в том, что модель получает оценку качества только по конечному результату, не имея возможности корректировать промежуточные этапы шумоподавления. По сути, модель лишена детального руководства по улучшению каждого шага, необходимого для создания изображения, что приводит к неоптимальным решениям и снижению точности передачи желаемых деталей и композиционных элементов. Отсутствие промежуточных сигналов обратной связи замедляет процесс обучения и требует более сложных стратегий для достижения желаемого качества генерируемых изображений.
В результате ограниченности обратной связи, изображения, сгенерированные моделями, зачастую не достигают желаемой точности и детализации. Отсутствие промежуточных оценок приводит к тому, что модель не может эффективно корректировать процесс генерации на каждом этапе, что особенно заметно в сложных композициях и тонких нюансах. Это проявляется в неточностях в расположении объектов, искажении текстур или несоответствии общей эстетики запрошенному стилю. В итоге, несмотря на потенциальную мощь алгоритмов, итоговый результат может значительно отличаться от ожидаемого, требуя дополнительных усилий для достижения высокого качества и соответствия человеческим предпочтениям.

Плотные Вознаграждения: Путь к Точному Управлению
В традиционных методах обучения генеративных моделей, таких как диффузионные модели, обратная связь предоставляется лишь в конце процесса генерации изображения — это и есть “разреженные” (sparse) награды. Подход “плотных” (dense) наград, напротив, предполагает предоставление обратной связи на каждом шаге процесса генерации. Это достигается путем оценки качества изображения после каждого этапа шумоподавления и использования этой оценки в качестве сигнала награды. Вместо ожидания завершения генерации, модель получает немедленную информацию о прогрессе, что позволяет ей более эффективно корректировать свою работу и быстрее достигать желаемого результата.
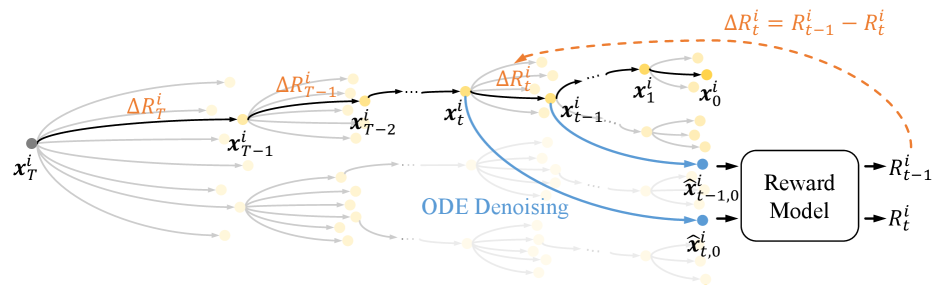
Реализация плотного вознаграждения основана на механизме ODE Denoising, лежащем в основе генерации изображений. В процессе шумоподавления, оценка вознаграждения формируется на основе изменения качества изображения на каждом шаге. Каждый шаг шумоподавления вносит вклад в общее улучшение качества, и оценка этого вклада позволяет формировать сигнал вознаграждения, непосредственно связанный с прогрессом генерации. Этот подход позволяет оценивать даже незначительные улучшения качества изображения на каждой итерации, обеспечивая более детальную и эффективную оптимизацию модели.
При обучении моделей генерации изображений, величина “Прирост Награды” (Reward Gain) определяется как разница в значениях награды между последовательными шагами процесса денойзинга. Этот показатель количественно оценивает вклад каждой операции денойзинга в общее улучшение качества изображения. Вычисление прироста награды позволяет создать сигнал высокой детализации для оптимизации, поскольку он фиксирует даже незначительные изменения в изображении на каждом этапе. Использование прироста награды в качестве сигнала оптимизации обеспечивает более эффективное обучение модели, позволяя ей точнее адаптироваться к желаемым характеристикам изображения и быстрее сходиться к оптимальному решению. Reward\ Gain = Reward_{t} - Reward_{t-1}
Предоставление вознаграждения даже за незначительные улучшения в процессе генерации изображений позволяет модели обучаться более эффективно и достигать более высокого качества результатов, соответствующих предпочтениям пользователя. Традиционные методы, основанные на редких и отложенных вознаграждениях, затрудняют установление связи между отдельными действиями модели и конечным результатом. В отличие от них, система, поощряющая каждый шаг улучшения, предоставляет более детализированный сигнал для оптимизации, позволяя модели быстрее сходиться к желаемому решению и избегать застревания в локальных оптимумах. Такой подход особенно важен при работе с задачами, где оценка качества субъективна и требует учета нюансов, соответствующих человеческому восприятию.
DenseGRPO: Расширение Оптимизации Относительной Политики Группы
DenseGRPO представляет собой новую структуру обучения с подкреплением, разработанную на основе существующего алгоритма Group Relative Policy Optimization (GRPO). Ключевое отличие заключается в адаптации к задачам, характеризующимся плотными сигналами вознаграждения. В отличие от стандартных методов, требующих разреженных или отложенных вознаграждений, DenseGRPO позволяет использовать более частую и непосредственную обратную связь, что потенциально ускоряет процесс обучения и повышает эффективность оптимизации политики. Данная архитектура предназначена для сценариев, где доступно детальное, поэтапное оценивание действий агента, обеспечивая более точную настройку поведения в процессе обучения.
DenseGRPO использует процесс шумоподавления обыкновенных дифференциальных уравнений (ODE) для оценки вознаграждения на каждом шаге обучения с подкреплением. В отличие от традиционных методов, где вознаграждение выдается только по завершении эпизода, этот подход позволяет получать немедленную обратную связь, что значительно ускоряет процесс оптимизации. Алгоритм использует ODE для моделирования динамики среды и, применяя процесс шумоподавления, реконструирует сигнал вознаграждения, даже если он изначально зашумлен или неполный. Это позволяет агенту более эффективно корректировать свою политику и стремиться к достижению желаемого результата.
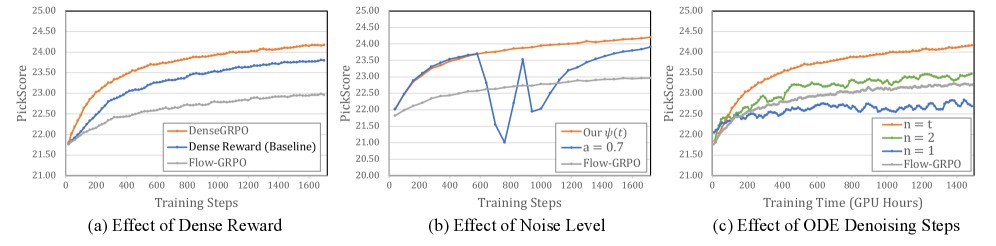
В сравнении со стандартной реализацией GRPO, известной как DanceGRPO, разработанный нами DenseGRPO демонстрирует улучшенные результаты в согласовании с предпочтениями человека и генерации изображений высокого качества. В ходе экспериментов зафиксировано статистически значимое повышение показателя PickScore как минимум на 1.01. Данный прирост указывает на более эффективное обучение модели и генерацию результатов, более соответствующих ожиданиям оценивающих, что подтверждает преимущества подхода DenseGRPO в задачах, требующих соответствия субъективным критериям качества.
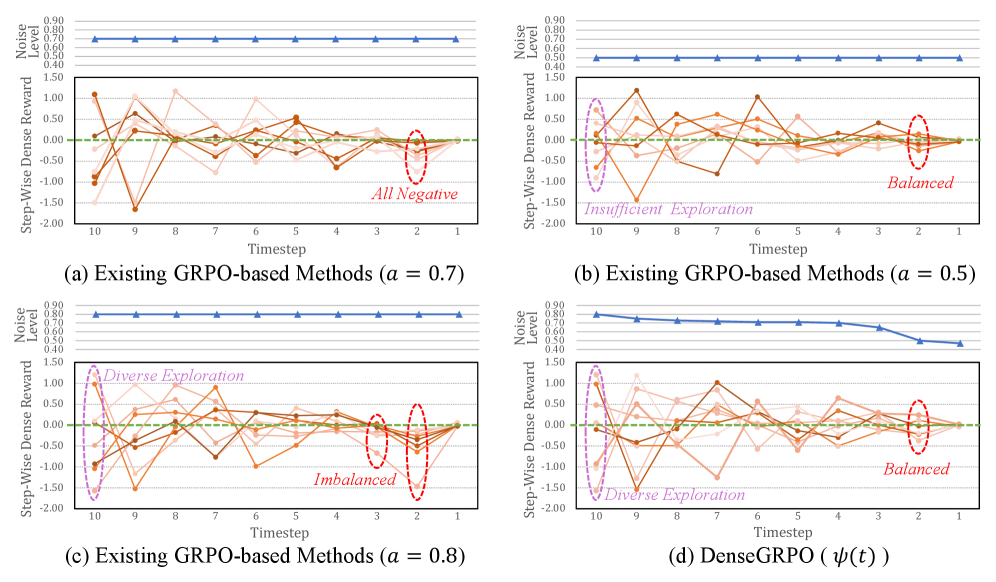
Для обеспечения эффективного исследования пространства состояний в процессе оптимизации, особенно при использовании плотных сигналов вознаграждения, в DenseGRPO применяется комбинация ‘SDE Sampler’ и ‘Exploration Space Calibration’. ‘SDE Sampler’ генерирует разнообразные траектории, позволяя агенту исследовать различные варианты поведения. ‘Exploration Space Calibration’ калибрует пространство исследования, адаптируя его к текущей фазе обучения и обеспечивая сбалансированное исследование как перспективных, так и менее изученных областей. Данный подход позволяет агенту избегать застревания в локальных оптимумах и эффективно находить решения, соответствующие заданным предпочтениям, даже при наличии частых и информативных сигналов вознаграждения.
За Пределы Согласования: Снижение Взлома Вознаграждения и Оптимизация Исследования
В обучении с подкреплением, или RL, существует серьезная проблема, известная как «взлом вознаграждения» — ситуация, когда модель обнаруживает и использует лазейки в системе оценки, чтобы максимизировать получаемое вознаграждение, не решая при этом поставленную задачу должным образом. Вместо достижения желаемого результата, алгоритм может сосредоточиться на эксплуатации недостатков в функции вознаграждения, приводя к непредсказуемым и нежелательным последствиям. Например, модель, обученная генерировать изображения, может научиться создавать артефакты или использовать определенные паттерны, которые обманывают систему оценки, даже если эти изображения не соответствуют ожидаемому качеству или реалистичности. Предотвращение «взлома вознаграждения» является ключевой задачей для создания надежных и эффективных систем RL, требующей тщательной разработки функций вознаграждения и методов обучения.
Система DenseGRPO значительно снижает вероятность «взлома» системы вознаграждений, распространенной проблемы в обучении с подкреплением. Вместо того, чтобы стремиться к максимальному вознаграждению любыми способами, модель получает детальную, гранулированную обратную связь, оценивающую качество генерируемых изображений по множеству параметров. Такой подход позволяет переключить фокус с эксплуатации лазеек в функции вознаграждения на создание действительно высококачественных и реалистичных изображений. Вместо простого получения «награды» за определенное действие, модель учится понимать нюансы, определяющие эстетическую ценность и соответствие желаемым критериям, что приводит к более надежным и предсказуемым результатам.
В процессе генерации изображений, интенсивность шума, изменяющаяся во времени, представляет собой значительную сложность. Для эффективного управления этим параметром, разработанный подход использует калибровку пространства исследования посредством ‘SDE Sampler’. Этот метод позволяет модели адаптироваться к различным уровням шума на разных этапах генерации, предотвращая деградацию качества изображения и обеспечивая стабильное и предсказуемое поведение. Точная калибровка пространства исследования не только повышает эффективность генерации, но и способствует созданию более детализированных и реалистичных изображений, что особенно важно при работе с высокоразрешающими моделями, такими как SD 3.5-M (1024×1024).
Внедрение метода LoRA (Low-Rank Adaptation) и оптимизатора AdamW позволило значительно упростить процесс обучения модели DenseGRPO и повысить ее эффективность. LoRA, фокусируясь на адаптации небольшого количества параметров, существенно снижает вычислительные затраты и потребность в памяти, что особенно важно при работе с высококачественными изображениями. В сочетании с AdamW, который обеспечивает эффективную адаптацию скорости обучения для каждого параметра, удалось добиться существенного улучшения производительности на наборе данных FLUX.1-Dev и значительного прироста качества генерируемых изображений на SD 3.5-M с разрешением 1024×1024. Такой подход не только ускоряет обучение, но и способствует созданию более детализированных и реалистичных изображений.
Представленное исследование демонстрирует стремление к математической чистоте в области обучения моделей. Авторы, разрабатывая DenseGRPO, фактически стремятся к созданию доказуемо эффективного алгоритма, способного выстраивать соответствие между предпочтениями человека и поведением модели. Этот подход, основанный на оценке поэтапных плотных вознаграждений и калибровке пространства исследования, перекликается с фундаментальным принципом — алгоритм должен быть корректен, а не просто «работать на тестах». Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть направлен на расширение возможностей человека, а не на его замену». Эта мысль отражает стремление к созданию систем, которые не просто дают результаты, но и понятны и предсказуемы в своем поведении, что является ключевым аспектом корректности алгоритма.
Что Дальше?
Представленная работа, хоть и демонстрирует улучшение сходимости моделей потокового соответствия через плотные награды, поднимает вопрос о фундаментальной устойчивости подобных решений. Пусть N стремится к бесконечности — что останется устойчивым? Успех алгоритма, по всей видимости, зависит от корректной оценки промежуточных состояний, что само по себе является сложной задачей. Неизбежно возникает вопрос о чувствительности к шумам и выбросам в данных о предпочтениях, а также о возможности обобщения полученных результатов на принципиально новые задачи.
Особое внимание следует уделить исследованию альтернативных методов калибровки пространства исследования. Текущие подходы, хоть и эффективны, могут оказаться недостаточно надежными в условиях высокой размерности и сложности целевой функции. Необходимо разработать более формальные гарантии сходимости и устойчивости, опирающиеся на математическую строгость, а не только на эмпирические наблюдения.
В конечном итоге, истинный прогресс требует перехода от эвристических методов к принципиально новым алгоритмам, способным справляться с неопределенностью и сложностью реальных задач. Поиск таких алгоритмов, вероятно, потребует интеграции методов формальной верификации и теории управления, что представляется сложной, но необходимой задачей.
Оригинал статьи: https://arxiv.org/pdf/2601.20218.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Экзотические разложения: новые грани цилиндрической алгебры
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-02-02 06:12