Автор: Денис Аветисян
Новый подход к формированию вознаграждений позволяет значительно повысить эффективность обучения агентов в сложных задачах.
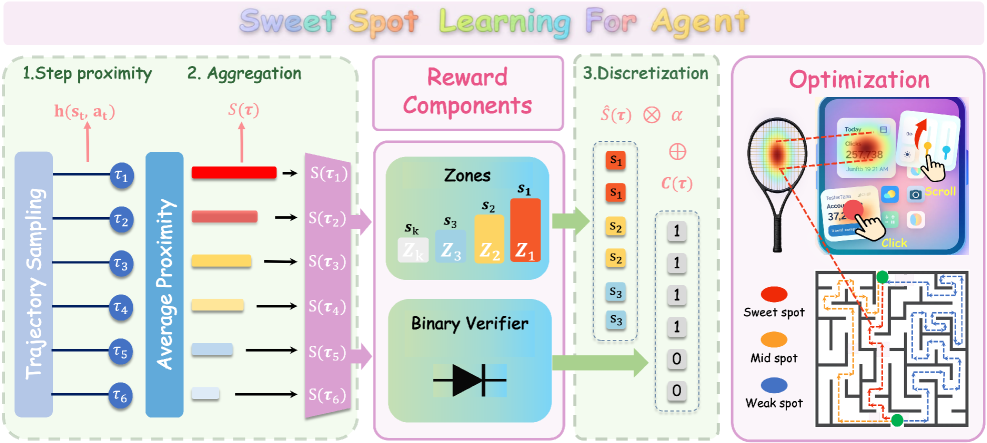
В статье представлена методика Sweet Spot Learning (SSL), использующая многоуровневую систему вознаграждений для улучшения скорости обучения и производительности агентов в различных областях, включая пространственное мышление.
Обучение с подкреплением, использующее верифицируемые награды, демонстрирует значительный потенциал, однако существующие подходы часто упускают из виду нюансы качества траекторий, приводящих к одинаковым результатам. В статье «SSL: Sweet Spot Learning for Differentiated Guidance in Agentic Optimization» представлен новый подход — Sweet Spot Learning (SSL), использующий многоуровневую систему наград, основанную на принципе поиска оптимальной «сладкой точки» в пространстве решений. Данный метод позволяет агентам более эффективно ориентироваться в сложных задачах, улучшая соотношение сигнал/шум в градиенте и повышая эффективность обучения. Способно ли подобное дифференцированное руководство стать основой для создания более надежных и универсальных интеллектуальных агентов?
Вызов разреженных вознаграждений в сложных задачах
Традиционные алгоритмы обучения с подкреплением часто опираются на бинарные вознаграждения, предоставляя агенту лишь простейшую обратную связь — успех или неудача. В сложных средах, где требуется выполнение множества последовательных действий для достижения цели, подобная схема оказывается крайне неэффективной. Отсутствие промежуточных сигналов затрудняет процесс исследования и обучения, поскольку агент не получает информации о том, насколько его действия приближают его к желаемому результату. В результате, агент может долгое время блуждать в пространстве состояний, не получая полезного сигнала, что значительно замедляет обучение и снижает вероятность нахождения оптимальной стратегии. Такой подход особенно проблематичен в задачах, требующих точного пространственного планирования или соблюдения сложных ограничений, где даже небольшое отклонение от правильного пути может привести к неудаче и отсутствию вознаграждения.
Недостаток четких и частых сигналов вознаграждения существенно затрудняет процесс обучения агентов в сложных задачах, особенно когда требуется точное пространственное мышление или соблюдение определенных ограничений. В ситуациях, где полезные действия редки или отложены во времени, агент испытывает трудности с обнаружением причинно-следственных связей между своими действиями и получаемыми результатами. Это приводит к замедлению обучения и снижению эффективности исследования пространства возможных решений. Например, в задачах, требующих планирования траектории или сборки сложных конструкций, отсутствие немедленной обратной связи может привести к тому, что агент будет блуждать в пространстве состояний, не находя оптимальный путь к цели, или игнорировать важные ограничения, что приводит к неудачам и затягиванию процесса обучения.
Эффективное обучение агентов в сложных задачах требует тщательно разработанных сигналов вознаграждения, которые выходят за рамки простых бинарных оценок. Вместо этого, необходимо создавать вознаграждения, отражающие тонкости и нюансы конкретной задачи. Это означает, что система должна учитывать промежуточные шаги, прогресс в достижении цели, а также степень близости к оптимальному решению. Например, в задачах пространственного ориентирования, вознаграждение может быть пропорционально уменьшению расстояния до цели, а не только присуждаться при её достижении. Такой подход позволяет агенту получать более детальную и полезную информацию о своей деятельности, что существенно ускоряет процесс обучения и повышает его эффективность, особенно в задачах, где редкие и отложенные вознаграждения затрудняют исследование и адаптацию.
SweetSpotLearning: Структура вознаграждения, основанная на близости
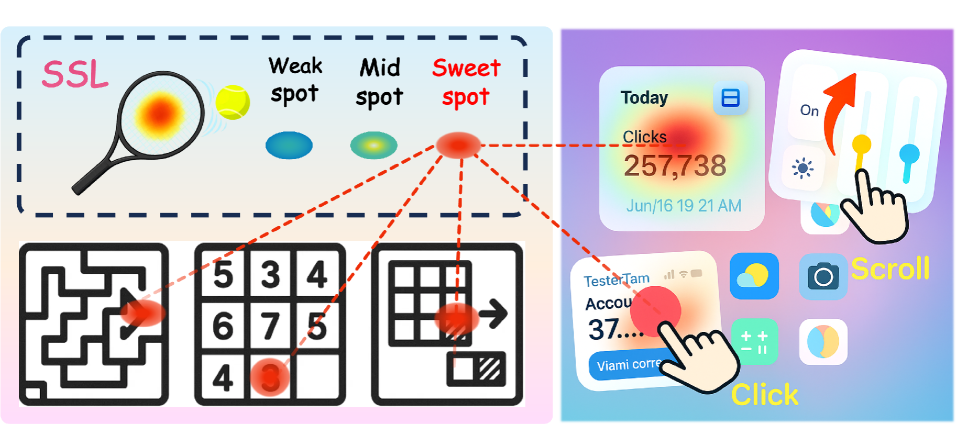
В основе SweetSpotLearning лежит новая структура вознаграждения, отличающаяся от традиционных подходов, где оценка действий основывается исключительно на успехе или неудаче. Вместо этого, система оценивает действия агента, исходя из степени приближения к оптимальному решению задачи. Это позволяет агенту получать положительное вознаграждение даже за частичные успехи или действия, приближающие его к цели, что способствует более стабильному и эффективному обучению, особенно в сложных задачах, где достижение идеального результата может быть затруднено или маловероятно на начальных этапах.
В основе SweetSpotLearning лежит система “TieredRewards”, предназначенная для дискретизации непрерывных сигналов вознаграждения. Вместо использования одного непрерывного значения, система разделяет пространство вознаграждений на несколько дискретных уровней. Это позволяет получить более стабильные оценки градиента во время обучения, что критически важно для алгоритмов, использующих градиентный спуск. Дискретизация снижает шум в оценках градиента, что, в свою очередь, ускоряет процесс обучения и повышает его эффективность, особенно в сложных задачах, где непрерывные сигналы могут быть подвержены значительным колебаниям.
В основе SweetSpotLearning лежит использование Гауссова поля для количественной оценки близости к оптимальному решению. Это позволяет системе формировать награды, пропорциональные расстоянию до целевого состояния, что обеспечивает более плавное и эффективное обучение агента. В ходе экспериментов было установлено, что применение Гауссова поля в качестве метрики близости повышает эффективность использования данных на 2.5 раза по сравнению с традиционными методами обучения с подкреплением, что подтверждается результатами тестирования в различных задачах, включая навигацию и манипулирование объектами.
Реализация и применение: GRPO и за его пределами
Реализация SweetSpotLearning базируется на алгоритме оптимизации политики GRPO (Generalized Reward-based Policy Optimization). GRPO обеспечивает стабильную основу для обучения и оценки, позволяя эффективно исследовать пространство действий и находить оптимальные стратегии. Алгоритм позволяет максимизировать ожидаемое вознаграждение, используя обобщенный подход к оценке политики и ее последующей оптимизации. Использование GRPO в SweetSpotLearning позволяет добиться высокой производительности и надежности в различных задачах обучения с подкреплением.
Метод ‘BlockwiseSweetSpot’ расширяет функциональность разработанного фреймворка, позволяя применять его к задачам, основанным на сетках, таким как ‘MazeNavigation’ (навигация по лабиринту) и ‘ConstraintSatisfaction’ (удовлетворение ограничений). Данный подход позволяет адаптировать алгоритм к задачам, где пространство решений структурировано в виде дискретной сетки, что демонстрирует его универсальность и применимость за пределами задач, изначально ориентированных на непрерывные пространства состояний. Реализация включает в себя адаптацию функции вознаграждения и пространства действий для эффективной работы в сетчатой среде.
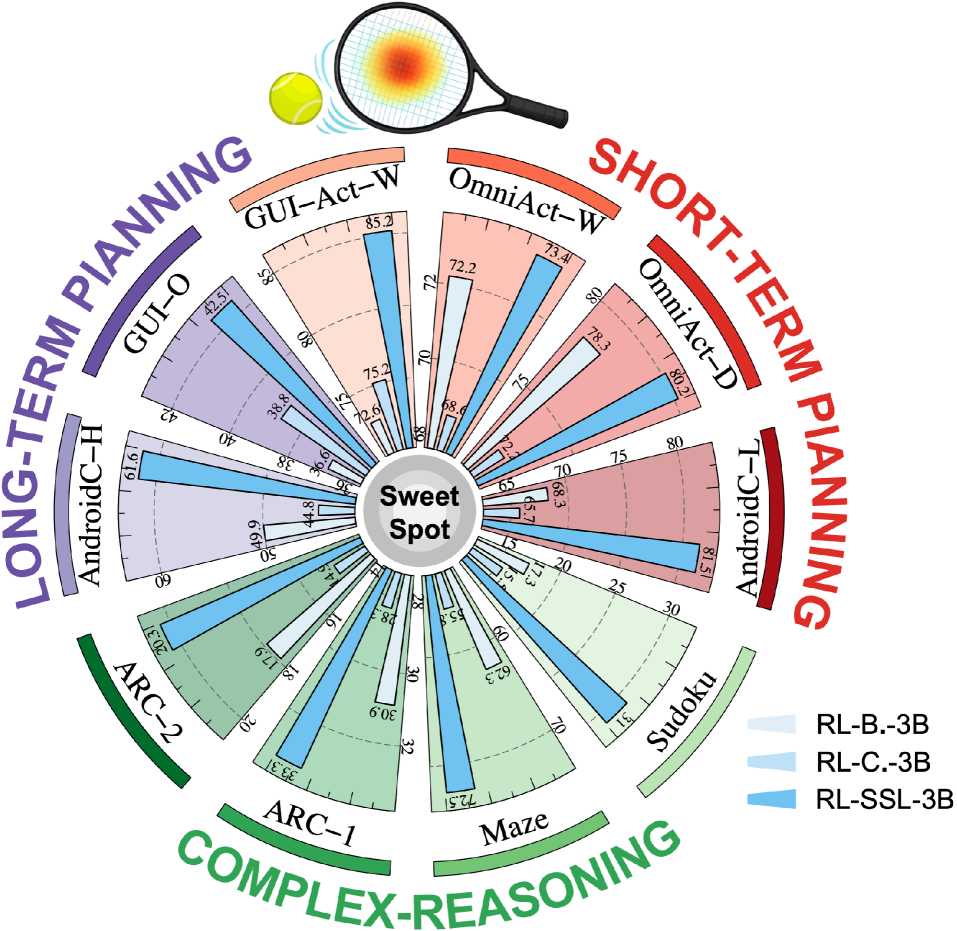
Предложенная методология демонстрирует значительное повышение эффективности использования данных (Sample Efficiency), превосходя базовые методы в 2.5 раза. В частности, при решении задач судоку с использованием 3B-параметрической модели, наблюдается 100%-ное улучшение производительности. Это указывает на способность алгоритма к более быстрому обучению и достижению оптимальных решений при ограниченном объеме обучающих данных, что критически важно для задач, где сбор данных является дорогостоящим или трудоемким.

Переосмысление дизайна вознаграждений: Процессный подход
Вместо традиционного подхода к разработке систем вознаграждений, ориентированного на достижение конечных результатов, SweetSpotLearning предлагает принципиально иную стратегию. Данный метод акцентирует внимание на моделировании самого процесса, ведущего к успеху, а не на простом определении желаемой цели. Вместо жесткого фиксирования конечных точек, система вознаграждает агента за приближение к оптимальному поведению на каждом этапе, обеспечивая более гибкую и адаптивную систему обучения. Такой подход позволяет агентам не просто запоминать решения для конкретных задач, но и обобщать полученный опыт, эффективно применяя его в новых, незнакомых ситуациях. Это существенно повышает устойчивость и эффективность обучения, особенно в сложных задачах, требующих последовательного выполнения действий.
Подход, основанный на акценте на близость к оптимальному поведению и непрерывную обратную связь, значительно повышает способность агентов к адаптации и обобщению. Вместо дискретных наград, система поощряет постепенное приближение к цели, что позволяет агенту быстрее осваивать новые задачи и эффективно действовать в незнакомых ситуациях. Подобный механизм обучения стимулирует исследование пространства решений, способствуя формированию более устойчивых и гибких стратегий, не зависящих от конкретных условий. В результате, агенты демонстрируют повышенную устойчивость к шумам и изменениям в окружающей среде, а также способность успешно применять полученные навыки в различных контекстах, что делает данный подход особенно ценным для решения сложных и динамичных задач.
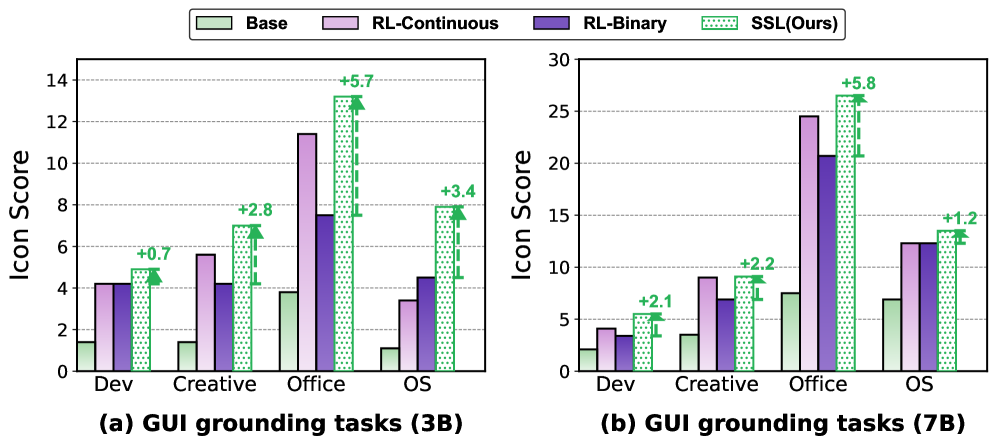
Исследования показали, что предложенный подход оказался эффективным в разнообразных областях, включая автоматизацию графического интерфейса пользователя и решение сложных задач. Статистический анализ продемонстрировал значительное улучшение результатов во всех протестированных категориях, с p-значениями менее 0.05, что свидетельствует о высокой статистической значимости полученных данных. В частности, удалось добиться снижения дисперсии градиента на 2.1-3.5 раза по сравнению с использованием непрерывных наград, что позволяет агентам обучаться быстрее и стабильнее, избегая проблем, связанных с нестабильными градиентами и локальными оптимумами.
Исследование, представленное в статье, демонстрирует, что эффективное обучение агентов требует не просто предоставления им цели, но и создания тщательно продуманной системы вознаграждений. Подход Sweet Spot Learning, основанный на многоуровневых вознаграждениях, подчеркивает важность понимания “кругооборота” в системе — как каждое изменение влияет на общую производительность агента. Грейс Хоппер однажды заметила: «Лучший способ объяснить — это демонстрация». Эта фраза прекрасно иллюстрирует суть SSL — предлагая не абстрактные принципы, а конкретный метод, который показывает, как улучшить эффективность обучения за счет тонкой настройки вознаграждений, приближая агента к оптимальному решению. Такой подход, как и элегантный дизайн, рождается из простоты и ясности, позволяя агенту лучше ориентироваться в пространстве задач.
Куда Ведет Дорога?
Представленная работа, исследуя принцип “сладких точек” в обучении с подкреплением, неизбежно поднимает вопрос о природе самой оптимизации. Каждое уточнение функции вознаграждения, каждая попытка направить агента к решению, создает новые узлы напряжения в системе. Попытка “ускорить” обучение, кажется, лишь перераспределяет сложность, а не устраняет ее. Следующим шагом представляется не поиск более совершенных алгоритмов формирования вознаграждений, а более глубокое понимание того, как агенты справляются с неполнотой информации и внутренней неопределенностью.
Особое внимание следует уделить взаимодействию между различными уровнями вознаграждения. Как обеспечить согласованность между краткосрочными и долгосрочными целями? Как избежать ситуации, когда агент оптимизируется для получения “сладкого вознаграждения”, игнорируя более важные аспекты задачи? Архитектура системы определяет ее поведение во времени, а не схема на бумаге; поэтому, необходимо переходить от оценки отдельных алгоритмов к анализу динамики всей обучающей системы.
В конечном счете, ключ к успеху лежит не в создании более “умных” агентов, а в построении более “элегантных” систем обучения. Систем, способных к самоорганизации и адаптации, где вознаграждение является не директивой, а скорее, инструментом для исследования и открытия.
Оригинал статьи: https://arxiv.org/pdf/2601.22491.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-02-02 07:48