Автор: Денис Аветисян
Исследователи разработали инновационную систему, позволяющую большим языковым моделям самостоятельно улучшать свои навыки решения математических задач, не требуя внешнего контроля или обучения на размеченных данных.
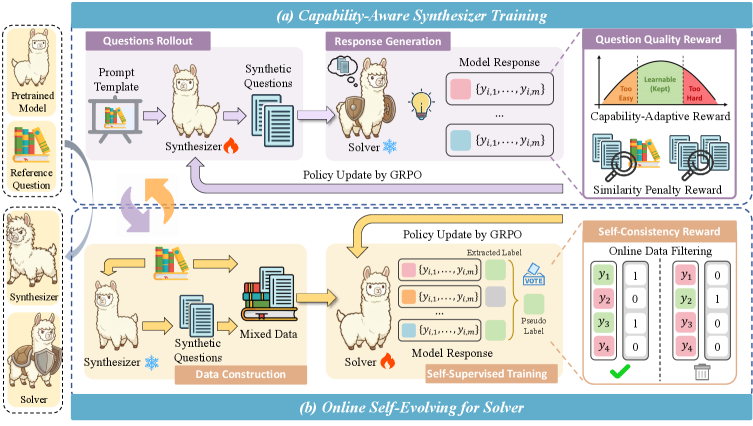
Предложена методика TTCS (Test-Time Curriculum Synthesis), использующая принцип учебного плана для синтеза упрощенных вариантов сложных задач и повышения способности к самообучению.
Существующие подходы к адаптации больших языковых моделей (LLM) в процессе тестирования сталкиваются с трудностями при решении сложных задач из-за низкого качества псевдометок и нестабильности обучения. В данной работе представлена методика ‘TTCS: Test-Time Curriculum Synthesis for Self-Evolving’, предлагающая новый фреймворк для синтеза учебных материалов непосредственно в процессе тестирования, что позволяет модели самообучаться и улучшать свои навыки рассуждения. Ключевая идея заключается в одновременной эволюции двух политик — генератора вопросов и решателя задач — с использованием принципов curriculum learning и самосогласованности. Не приведет ли это к созданию более надежных и масштабируемых LLM, способных к динамическому самосовершенствованию без внешнего контроля?
Пределы Статического Рассуждения
Традиционные системы рассуждений часто оказываются неэффективными при решении сложных задач, требующих последовательной доработки и уточнения. В отличие от человеческого мышления, способного к итеративному подходу — формулировке гипотезы, проверке, и последующей корректировке на основе полученных результатов — эти системы, как правило, полагаются на фиксированные алгоритмы и заранее заданные правила. В результате, они испытывают трудности при столкновении с неоднозначными или неполными данными, а также не способны эффективно адаптироваться к новым ситуациям, требующим творческого подхода и пересмотра изначальных предположений. Неспособность к самокоррекции и постепенному улучшению решений ограничивает их применимость в динамичных и сложных областях, где требуется гибкость и адаптивность.
Ограничения статических наборов данных и фиксированных параметров моделей существенно снижают способность систем к адаптации к новым, непредсказуемым ситуациям и ранее не встречавшимся данным. Традиционные подходы, полагающиеся на заранее собранные и размеченные данные, оказываются неэффективными при столкновении с информацией, выходящей за рамки изначального обучения. Это связано с тем, что модели, обученные на статичном наборе, не способны к обобщению и экстраполяции знаний на новые контексты, что приводит к снижению точности и надежности их работы. Необходимость в динамическом обновлении и самообучении становится критически важной для создания систем, способных эффективно функционировать в постоянно меняющемся окружении, где заранее предвидеть все возможные сценарии практически невозможно.
Эффективное рассуждение, как показывает современная когнитивная наука, не является пассивным применением логических правил к заданным фактам. Вместо этого, оно представляет собой динамичный процесс, в котором генерация новых проблем и проверка предлагаемых решений тесно переплетены. Исследования демонстрируют, что способность к формированию гипотез и последующей их проверке на соответствие реальности является ключевым фактором успешного решения сложных задач. Этот итеративный цикл — от постановки вопроса до оценки ответа — позволяет системе не только находить решения, но и адаптироваться к изменяющимся условиям, а также выявлять и исправлять собственные ошибки. Таким образом, рассуждение предстает как непрерывный процесс самопроверки и самокоррекции, а не как однократное применение зафиксированного алгоритма.
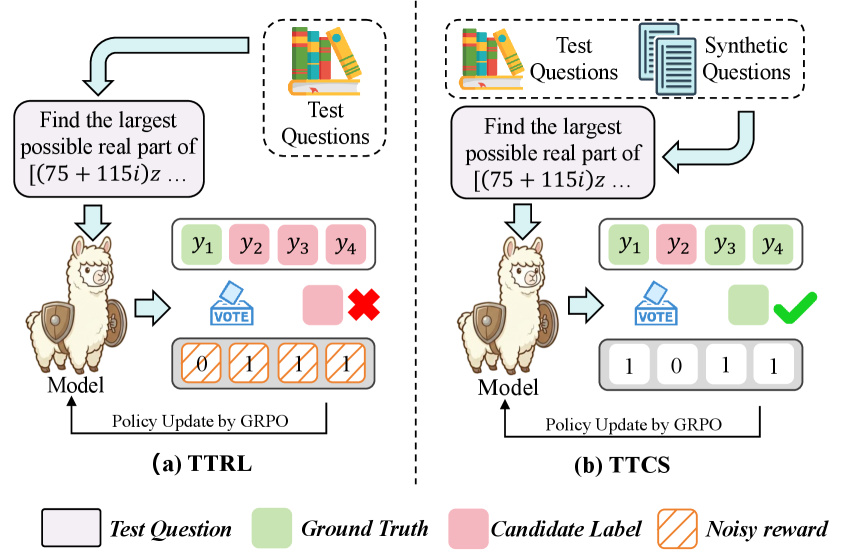
TTCS: Фреймворк Совместной Эволюции
TTCS — это разработанный нами фреймворк, расширяющий возможности обучения во время тестирования (Test-Time Training) и обучения по учебному плану (Curriculum Learning). В его основе лежит сочетание двух компонентов: синтезатора и решателя. Синтезатор генерирует специализированные вопросы или задачи, а решатель предпринимает попытки их решения. Эта взаимосвязь позволяет создать непрерывный цикл обучения, где производительность решателя влияет на сложность генерируемых вопросов, и наоборот. Фреймворк TTCS направлен на повышение эффективности и адаптивности моделей машинного обучения в условиях реального времени, используя принципы совместной эволюции компонентов.
В рамках предложенной системы, синтезатор генерирует специализированные запросы (вопросы), адаптированные к текущему состоянию решателя. Решатель, в свою очередь, предпринимает попытки ответить на эти запросы. Результаты ответа решателя используются для корректировки стратегии генерации запросов синтезатором, и наоборот. Этот процесс формирует непрерывный цикл обучения, в котором синтезатор и решатель совместно развиваются, улучшая свои способности в решении поставленной задачи. Такая организация позволяет эффективно использовать данные, полученные в процессе тестирования, для непрерывной адаптации и улучшения модели.
Оптимизация групповой относительной политики (GRPO) является ключевым механизмом, обеспечивающим совместную эволюцию синтезатора и решателя в рамках TTCS. GRPO позволяет одновременно уточнять политики обоих компонентов, что достигается путем вычисления относительных преимуществ действий каждого агента в группе, а не абсолютных. Этот подход обеспечивает более стабильное и эффективное обучение, поскольку учитывает взаимосвязь между синтезатором и решателем. Экспериментальные результаты демонстрируют, что применение GRPO приводит к значительному повышению производительности системы по сравнению с традиционными методами обучения, обеспечивая более быструю адаптацию и улучшение показателей в процессе обучения во время тестирования.
Направляя Исследование: Вознаграждения, Учитывающие Возможности, и Максимизация Дисперсии
Синтезатор направляется системой вознаграждений, учитывающей возможности решателя (Capability-Aware Reward). Эта система приоритизирует вопросы, представляющие собой оптимальный баланс между сложностью и разрешимостью. Вопросы, слишком простые, не способствуют развитию, а неразрешимые — приводят к неэффективному использованию ресурсов. Таким образом, вознаграждение максимизируется при выборе задач, которые находятся на границе текущих возможностей решателя, стимулируя его к обучению и расширению функциональности. Данный подход позволяет целенаправленно увеличивать сложность решаемых задач, последовательно подталкивая решателя к освоению новых навыков и повышению общей производительности.
Метод генеративного синтеза, основанный на дисперсии, дополнительно усиливает процесс исследования, направленно выбирая образцы с максимальным разбросом результатов. Выбор образцов, демонстрирующих наибольшую дисперсию в прогнозируемых исходах, максимизирует информативность сигнала обучения. Это позволяет модели эффективнее различать и усваивать новые знания, поскольку такие образцы содержат больше информации о неопределенности и границах ее возможностей. В результате, модель быстрее совершенствуется и лучше адаптируется к различным задачам, поскольку фокусируется на тех примерах, которые наиболее полезны для улучшения ее производительности.
Решающая модель (Solver) использует механизм самообучения с подкреплением, основанный на анализе собственных ответов. Этот подход позволяет извлекать полезную информацию из немаркированных данных, избегая необходимости в ручной разметке. Оценка собственных ответов осуществляется на основе внутренних критериев согласованности и правдоподобия, формируя сигнал вознаграждения. В результате, система способна к непрерывному улучшению и адаптации, самостоятельно выявляя и исправляя ошибки без внешнего контроля, что существенно расширяет возможности обучения и применения в задачах, где доступ к размеченным данным ограничен или отсутствует.
Выходя за рамки Производительности: К Надежным и Самосовершенствующимся Системам
Решение, предложенное в данной работе, использует механизм псевдо-меток, генерируемых на основе собственных результатов, что позволяет системе обучаться на синтезированных вопросах без необходимости внешнего контроля. Этот подход, по сути, создает замкнутый цикл самообучения, где выходные данные системы служат входными данными для дальнейшего совершенствования. Система самостоятельно создает и решает задачи, используя собственные прогнозы в качестве «правильных ответов» для обучения, что позволяет ей непрерывно повышать свои способности к рассуждениям и адаптироваться к новым вызовам, не требуя постоянного вмешательства человека или использования размеченных данных.
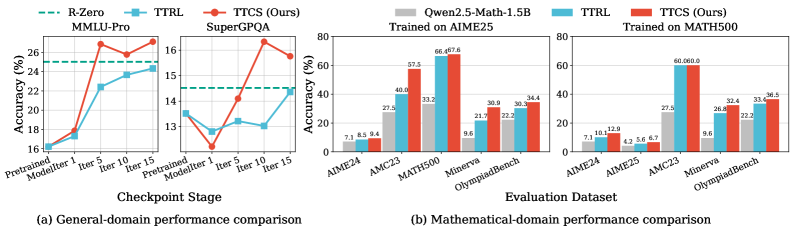
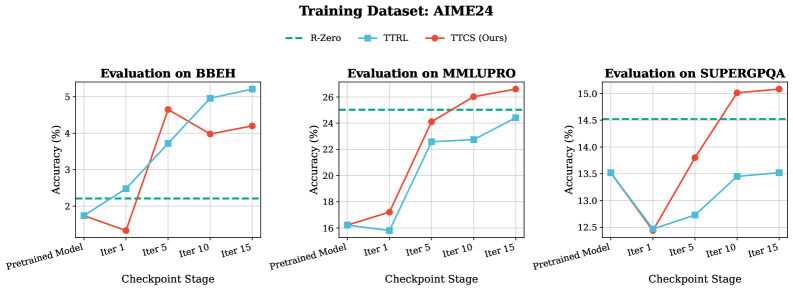
Система демонстрирует способность к непрерывному совершенствованию своих навыков рассуждения и адаптации к новым задачам благодаря циклу самообучения. Этот процесс позволяет ей генерировать и использовать псевдометки, полученные из собственных решений, что, по сути, создает синтезированные обучающие примеры без необходимости внешнего контроля. В результате, на сложном бенчмарке AIME24 система достигла среднего результата в 41.49 балла, что свидетельствует о значительном прогрессе в области создания самообучающихся систем, способных к постоянному улучшению производительности и решению задач, ранее недоступных.
Система TTCS представляет собой новый подход к построению надежных и самообучающихся систем рассуждений, основанный на динамической генерации и решении задач. В отличие от традиционных методов, требующих внешних размеченных данных, TTCS способен самостоятельно создавать учебные примеры, тем самым непрерывно совершенствуя свои способности к логическому мышлению. Результаты демонстрируют значительный прогресс в эффективности: система превзошла модель Qwen2.5-Math-1.5B на 24.19 пункта и модель TTRL на 4.12 пункта в бенчмарке AIME24, что свидетельствует о потенциале данного подхода для создания более устойчивых и адаптивных систем искусственного интеллекта.
Представленная работа демонстрирует подход к саморазвитию больших языковых моделей, где ключевым элементом является синтез решаемых вариантов сложных задач в процессе обучения. Это напоминает о важности ясного и структурированного подхода к проектированию систем. Как однажды заметила Грейс Хоппер: «Лучший способ объяснить программу — запустить её». Подобно тому, как программа должна быть понятной в исполнении, так и система обучения должна быть построена на четких принципах, позволяющих модели постепенно осваивать более сложные задачи. TTCS, фокусируясь на создании управляемого учебного плана, позволяет модели развивать навыки рассуждения без внешней помощи, что подчеркивает элегантность и эффективность простоты в дизайне.
Что дальше?
Представленная работа, демонстрируя возможность самообучения языковых моделей посредством синтеза учебных задач, открывает, скорее, вопросы, чем дает ответы. Элегантность подхода заключается в отказе от внешнего надзора, однако эта же простота обнажает зависимость от качества генерируемых «решаемых» вариантов. Возникает закономерный вопрос: насколько надежно модель способна оценить собственную «решаемость» задачи, и не приведёт ли самообучение к укреплению существующих предубеждений или зацикливанию на локальных оптимумах?
Перспективы развития, вероятно, лежат в области углублённого анализа процесса генерации учебных задач. Необходима разработка метрик, позволяющих оценивать не только успешность решения, но и «здоровье» самого процесса обучения — его способность к диверсификации и избежанию стагнации. Поиск баланса между сложностью задач и способностью модели к их освоению — задача тонкая, требующая выхода за рамки простых эвристик.
Хорошая архитектура незаметна, пока не ломается, и только тогда видна настоящая цена решений. Данный подход, безусловно, интересен, но его истинная ценность проявится в способности преодолеть неизбежные ограничения и продемонстрировать устойчивость к непредсказуемости реальных данных.
Оригинал статьи: https://arxiv.org/pdf/2601.22628.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Бреп-Кодер: Искусственный интеллект, понимающий геометрию
- Квантовые Загадки и Финансовые Реалии
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
2026-02-02 09:36