Автор: Денис Аветисян
Новый статистический подход позволяет оценить риск успешных атак на большие языковые модели, используя ограниченные ресурсы для тестирования.
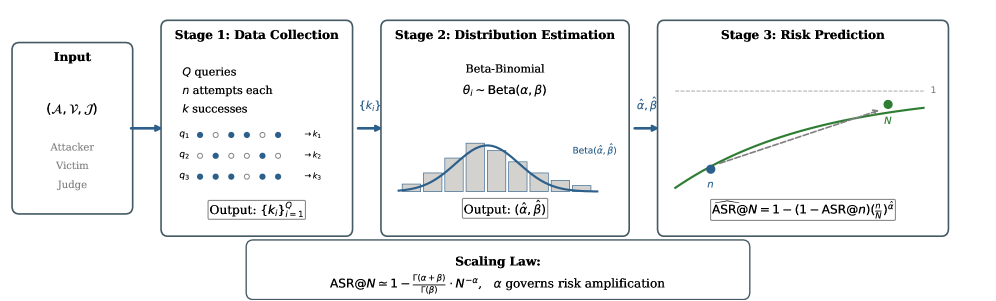
В статье представлена статистическая основа для оценки устойчивости больших языковых моделей к враждебным воздействиям, основанная на бета-биномиальном распределении и моделировании масштабирования частоты успешных атак.
Оценка безопасности больших языковых моделей (LLM) традиционно недооценивает риски, связанные с масштабными атаками. В работе «Statistical Estimation of Adversarial Risk in Large Language Models under Best-of-N Sampling» предложен статистически обоснованный подход SABER, позволяющий точно предсказывать уязвимость LLM к взлому при использовании стратегии Best-of-N путем моделирования масштабирования вероятности успеха атаки с использованием бета-биномиального распределения. Разработанный метод позволяет экстраполировать показатели успеха атак при большом числе попыток (N) на основе небольшого объема измерений, снижая погрешность оценки на 86.2% по сравнению с базовыми подходами. Может ли предложенная методология стать основой для более реалистичной и эффективной оценки безопасности LLM в условиях растущих угроз?
Растущие Ставки Безопасности Больших Языковых Моделей
Всё более широкое внедрение больших языковых моделей (БЯМ) в различные сферы жизни, от автоматизированной поддержки клиентов до создания контента, требует проведения тщательных и всесторонних оценок их безопасности. Неспособность предвидеть и предотвратить потенциально опасные или вредоносные ответы может привести к серьезным последствиям, включая распространение дезинформации, усиление предвзятости и даже нанесение репутационного ущерба организациям, использующим эти технологии. В связи с этим, разработка эффективных и масштабируемых методов оценки безопасности БЯМ становится критически важной задачей для исследователей и разработчиков, стремящихся к ответственному внедрению искусственного интеллекта. Акцент делается не только на выявлении явных ошибок, но и на понимании скрытых уязвимостей и непредсказуемого поведения моделей в различных контекстах.
Традиционные методы оценки устойчивости больших языковых моделей (LLM) часто оказываются непомерно затратными в вычислительном плане и непрактичными при масштабировании. Проверка каждой возможной входной комбинации или даже значительной её части требует огромных ресурсов, времени и энергии, что делает всесторонний анализ невозможным для моделей, развёртываемых в широком масштабе. Например, для оценки реакции модели на миллионы потенциально опасных запросов требуется инфраструктура, которая большинству разработчиков недоступна. В результате, существующие подходы часто ограничиваются небольшим набором тестовых примеров, что не позволяет гарантировать безопасность модели в реальных условиях эксплуатации и оставляет возможность для проявления нежелательного поведения в неожиданных ситуациях.
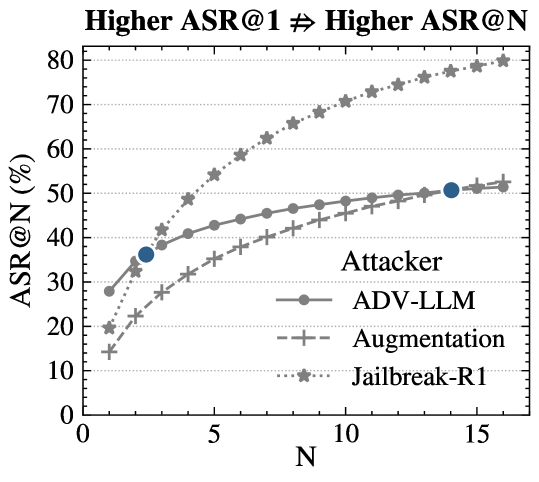
Исследования показывают, что применение метода Best-of-N при генерации ответов большими языковыми моделями, несмотря на стремление к повышению качества, несет в себе скрытую уязвимость, масштабирующую риски получения вредоносных результатов. Суть заключается в том, что с увеличением числа попыток (N) для выбора наилучшего ответа, вероятность появления хотя бы одного опасного или нежелательного ответа экспоненциально возрастает. Это происходит потому, что модель, исследуя более широкий спектр возможных ответов, увеличивает шанс «выдать» ответ, содержащий предвзятости, дезинформацию или потенциально вредоносный контент, даже если в большинстве случаев генерируемые ответы безопасны. Таким образом, стратегия, направленная на улучшение качества, парадоксальным образом может повысить общую вероятность получения опасного результата при увеличении числа генерируемых вариантов.
Количественная Оценка Риска: От Успеха на Выборке к Вероятности Атаки в Популяции
Оценка устойчивости больших языковых моделей (LLM) требует использования состязательных запросов — специально разработанных входных данных, предназначенных для выявления уязвимостей. В рамках этого подхода создаются входные последовательности, которые могут вызвать нежелательное поведение модели, например, генерацию вредоносного контента или раскрытие конфиденциальной информации. Состязательные запросы не обязательно должны быть семантически осмысленными для человека; их основная цель — заставить модель выйти за рамки ожидаемого поведения и продемонстрировать слабые места в ее архитектуре или процессе обучения. Эффективность состязательных запросов измеряется как процент успешных атак, то есть запросов, которые привели к нежелательному результату.
Метрика SampleASR, определяющая процент успешных атак на отдельные запросы, предоставляет лишь частичную картину рисков, связанных с уязвимостью языковых моделей. Хотя она показывает, насколько часто злоумышленник может вызвать нежелательный ответ на конкретном вводе, она не учитывает вероятность повторных попыток атаки. Единичная успешная атака на отдельный запрос не отражает общую вероятность получения вредоносного ответа при многократных обращениях к модели с целью обхода защитных механизмов. Таким образом, SampleASR не позволяет адекватно оценить риск для всего пользовательского пула, подвергающегося множеству запросов.
Для точной оценки рисков на уровне всей популяции пользователей необходимо рассчитывать показатель Attack Success Rate at N attempts (ASR@N), который отражает кумулятивную вероятность получения вредоносного ответа после N последовательных попыток атаки. В отличие от оценки успешности атаки на отдельных запросах (SampleASR), ASR@N учитывает, что многократные попытки могут привести к получению вредоносного результата, даже если вероятность успеха каждой отдельной атаки невелика. ASR@N = 1 - (1 - p)^N, где p — вероятность успешной атаки на один запрос, а N — количество попыток. Таким образом, ASR@N представляет собой вероятность того, что хотя бы одна из N попыток атаки завершится успехом и приведет к генерации вредоносного ответа.
SABER: Статистический Фреймворк для Эффективного Предсказания Риска
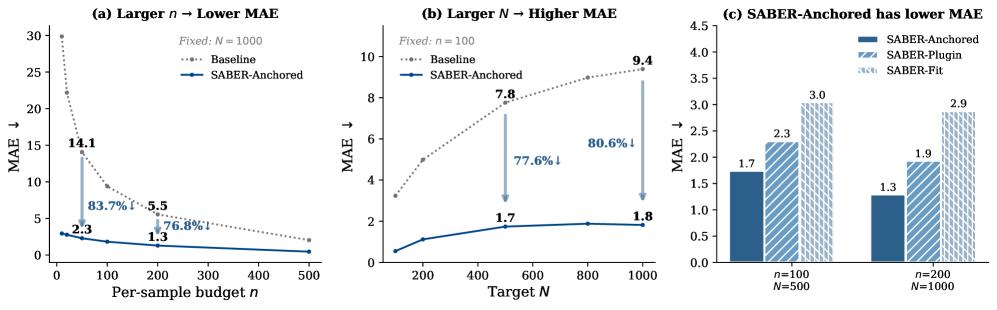
SABER — это масштабируемый фреймворк оценки рисков, предназначенный для предсказания метрики ASR@N (Attack Success Rate at N queries) на основе ограниченного количества запросов. В отличие от существующих методов, SABER позволяет значительно снизить среднюю абсолютную ошибку (Mean Absolute Error) предсказания ASR, достигая улучшения в 86.2%. Данная эффективность достигается за счет использования статистической модели, способной экстраполировать данные о вероятности успеха атаки на всю популяцию даже при небольшом количестве доступных измерений, что делает SABER особенно полезным в сценариях с ограниченными вычислительными ресурсами или временем.
В основе SABER лежит использование бета-распределения \Beta(\alpha, \beta) для моделирования распределения вероятностей успешности отдельных выборок при проведении атак. В отличие от предположения о фиксированной вероятности успеха, бета-распределение позволяет учесть неопределенность, связанную с вариативностью результатов атак на разные входные данные. Параметры α и β бета-распределения отражают априорные знания или оценки о вероятности успеха, а также позволяют корректировать эти оценки на основе наблюдаемых данных. Использование бета-распределения позволяет более точно оценить риск, особенно при ограниченном количестве запросов, поскольку оно учитывает как среднюю вероятность успеха, так и ее дисперсию.
В основе SABER лежит метод оценки рисков, использующий вероятностное сочетание Бета-распределения и Биномиального распределения, известное как BetaBinomialLikelihood. Этот подход позволяет SABER точно оценивать популяционный уровень риска, даже при ограниченном количестве запросов (queries). Бета-распределение моделирует распределение вероятностей успеха на уровне отдельных выборок, учитывая присущую adversarial атакам неопределенность. Комбинируя это с Биномиальным распределением, SABER формирует более надежную оценку общего риска, чем традиционные методы, поскольку учитывает дисперсию, возникающую из-за вариативности вероятностей успеха отдельных выборок. P(X=k) = \binom{n}{k} \frac{\alpha^k (1-\alpha)^{n-k}}{\sum_{i=0}^{n} \binom{n}{i} \alpha^i (1-\alpha)^{n-i}}, где X — количество успешных атак, n — общее количество запросов, а α — параметр Бета-распределения.
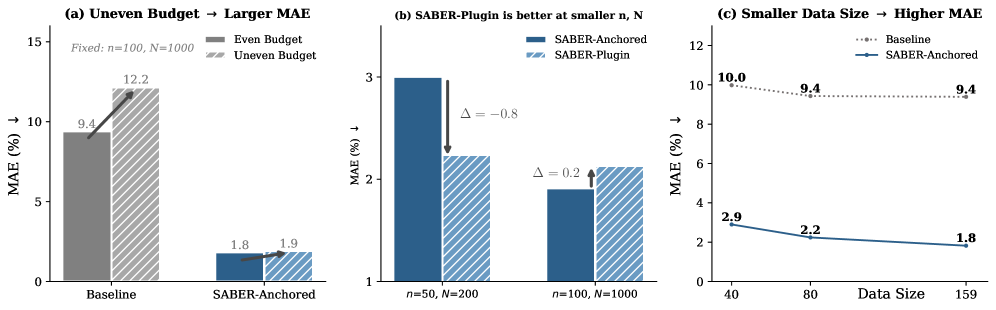
Механизм BudgetAllocation в SABER осуществляет оптимизацию распределения бюджета запросов, направляя ресурсы на наиболее информативные примеры. Вместо равномерного распределения, система динамически оценивает вклад каждого запроса в снижение неопределенности оценки риска ASR@N. Это достигается путем анализа дисперсии вероятностей успеха на уровне отдельных выборок и приоритезации запросов, которые потенциально могут наиболее существенно уменьшить эту дисперсию. Таким образом, BudgetAllocation позволяет SABER достигать более высокой точности предсказания риска при том же общем количестве запросов, эффективно используя ограниченный бюджет.
Подтверждение Эффективности SABER и Обеспечение Безопасности LLM в Масштабе
Система SABER демонстрирует значительное повышение точности оценки рисков при использовании наборов данных, таких как HarmBench, в сравнении с традиционными подходами. Тщательное тестирование на HarmBench позволило выявить существенные улучшения в способности SABER предсказывать вероятность генерации вредоносного или предвзятого контента языковыми моделями. В отличие от методов, полагающихся на ограниченные выборки или субъективные оценки, SABER использует статистически значимые данные для более надежной оценки, что позволяет разработчикам более эффективно выявлять и устранять потенциальные угрозы, связанные с развертыванием больших языковых моделей. Эта повышенная точность не только снижает вероятность выпуска небезопасных моделей, но и обеспечивает более эффективное использование ресурсов при оценке безопасности, что особенно важно при масштабировании разработки и развертывания LLM.
Разработанная система позволяет проводить всестороннюю оценку безопасности больших языковых моделей, значительно снижая вероятность развертывания систем, генерирующих вредоносный или предвзятый контент. В отличие от традиционных подходов, фокусирующихся на ограниченном наборе сценариев, данная платформа обеспечивает комплексный анализ, учитывающий широкий спектр потенциально опасных ситуаций и предубеждений. Это достигается благодаря применению специализированных наборов данных и алгоритмов, способных выявлять даже скрытые формы дискриминации и манипуляций. В результате, разработчики получают возможность не только обнаруживать уязвимости на ранних стадиях, но и эффективно смягчать риски, связанные с распространением нежелательной информации и формированием негативных стереотипов.
Система SABER предоставляет разработчикам масштабируемое и экономически выгодное решение для упреждающего выявления и смягчения потенциальных рисков, связанных с большими языковыми моделями. В отличие от трудоемких и дорогостоящих методов ручной проверки, SABER автоматизирует процесс оценки безопасности, позволяя быстро анализировать модели на предмет генерации вредоносного или предвзятого контента. Это не только снижает вероятность развертывания небезопасных моделей, но и существенно сокращает затраты на обеспечение их надежности. Благодаря своей эффективности, SABER позволяет разработчикам интегрировать оценки безопасности в существующие конвейеры разработки, обеспечивая постоянный мониторинг и своевременное устранение выявленных уязвимостей, что особенно важно при масштабировании и массовом внедрении LLM.
Исследование, представленное в статье, фокусируется на статистической оценке уязвимости больших языковых моделей к враждебным атакам. Авторы предлагают метод SABER, позволяющий предсказывать риски, связанные с такими атаками, используя небольшие вычислительные ресурсы. Этот подход особенно важен, учитывая растущие масштабы языковых моделей и сложность обеспечения их безопасности. Как однажды заметил Брайан Керниган: «Отладка — это как быть детективом в стране, которую вы создали сами». Эта фраза прекрасно иллюстрирует задачу, стоящую перед исследователями: необходимо тщательно анализировать поведение моделей, чтобы выявить и устранить потенциальные уязвимости, подобно поиску улик в сложном и запутанном пространстве кода и данных. Основываясь на бета-биномиальном распределении, SABER позволяет с высокой точностью оценивать вероятность успешных атак, что является ключевым шагом к созданию более надежных и безопасных систем.
Что Дальше?
Представленный анализ, хотя и демонстрирует элегантность статистического подхода к оценке уязвимостей больших языковых моделей, всё же оставляет ряд вопросов без ответа. Моделирование успеха атак с помощью бета-биномиального распределения — это, безусловно, шаг вперед, однако, не стоит забывать, что любая статистическая модель — лишь приближение к реальности. Оптимизация методов оценки без глубокого понимания природы самих атак — самообман и ловушка для неосторожного исследователя. Необходимо помнить, что «безопасность» модели определяется не только количеством успешно пройденных тестов, но и теоретической доказанностью её устойчивости.
Будущие исследования должны быть направлены на более точное моделирование механизмов «взлома» языковых моделей, а не только на статистическое описание наблюдаемых результатов. Особое внимание следует уделить исследованию влияния архитектурных особенностей моделей на их уязвимость, а также разработке формальных методов верификации их безопасности. Простое масштабирование существующих методов оценки на всё более крупные модели не принесёт существенных результатов, если не будет сопровождаться фундаментальным прогрессом в понимании принципов работы этих систем.
Необходимо также учитывать, что ландшафт атак постоянно меняется. Разработка новых методов «взлома» требует постоянного совершенствования методов оценки и защиты. В конечном счете, истинная элегантность в этой области заключается не в создании всё более сложных систем защиты, а в разработке принципиально новых архитектур, изначально устойчивых к известным и будущим атакам.
Оригинал статьи: https://arxiv.org/pdf/2601.22636.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Бреп-Кодер: Искусственный интеллект, понимающий геометрию
- Квантовые Загадки и Финансовые Реалии
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
2026-02-02 11:16