Автор: Денис Аветисян
Новая модель R2M позволяет добиться более эффективного обучения с подкреплением на основе обратной связи от человека, преодолевая проблему переоптимизации наград.
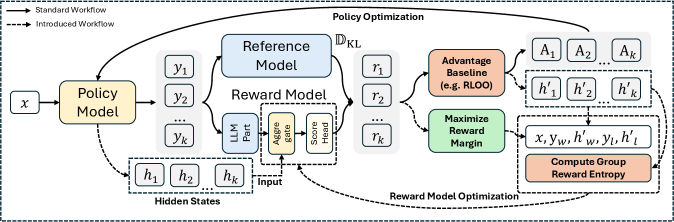
Представлен легковесный фреймворк RLHF, использующий скрытые состояния политики для моделирования наград и обеспечения согласованности в реальном времени.
Несмотря на успехи обучения с подкреплением на основе обратной связи от человека (RLHF), модели часто подвержены переоптимизации награды, эксплуатируя ложные закономерности вместо истинных предпочтений. В данной работе, посвященной проблеме, представленной в статье ‘Real-Time Aligned Reward Model beyond Semantics’, предлагается новый легковесный фреймворк R2M, который выходит за рамки традиционных моделей награды, полагающихся исключительно на семантические представления. R2M использует динамические скрытые состояния политики для отслеживания изменений в ее распределении и обеспечения соответствия модели награды в режиме реального времени. Может ли подобный подход, основанный на непосредственной обратной связи от политики, стать ключом к более надежному и эффективному обучению языковых моделей?
Вызов Согласованности: Обеспечение Соответствия БЯМ Человеческим Намерениям
Несмотря на впечатляющие возможности, большие языковые модели (БЯМ) требуют тщательной настройки в соответствии с человеческими предпочтениями, чтобы избежать нежелательных результатов. БЯМ обучаются на огромных объемах данных, но эти данные не всегда отражают нюансы человеческой этики, здравого смысла или конкретных целей. Вследствие этого, модели могут генерировать текст, который является предвзятым, оскорбительным, неточным или просто нерелевантным. Поэтому, для обеспечения полезности и безопасности БЯМ, необходимы методы, позволяющие согласовать поведение модели с ожиданиями и ценностями людей, гарантируя, что ответы соответствуют не только грамматическим правилам, но и принципам разумности и этики.
Традиционные методы выравнивания больших языковых моделей, основанные на статических наборах данных и контролируемой тонкой настройке, зачастую оказываются хрупкими и неспособными к обобщению. Изначально обученные на фиксированном корпусе текстов, эти модели испытывают трудности при столкновении с новыми, ранее не встречавшимися ситуациями или нюансами человеческих предпочтений. Проблемой является то, что реальные пользовательские запросы и ожидания постоянно меняются, а статичные данные не способны отразить эту динамику. В результате, модель, прекрасно работающая на тестовом наборе, может давать непредсказуемые или нежелательные результаты в реальных условиях, требуя постоянной перенастройки и обновления данных, что делает поддержание актуальности и надежности системы сложной задачей.
Основная сложность в согласовании больших языковых моделей (LLM) с человеческими намерениями заключается в изменчивости обратной связи от пользователей. В отличие от статических наборов данных, используемых в традиционных методах, человеческие предпочтения эволюционируют со временем и зависят от контекста. Поэтому, для поддержания соответствия LLM ожиданиям, необходима непрерывная адаптация в процессе эксплуатации. Модели должны обладать способностью к обучению в реальном времени, основываясь на потоке отзывов от пользователей, что требует разработки новых алгоритмов, способных эффективно обрабатывать и усваивать динамическую информацию. Игнорирование этой изменчивости приводит к тому, что LLM быстро устаревают и начинают генерировать ответы, не соответствующие текущим потребностям и ожиданиям.
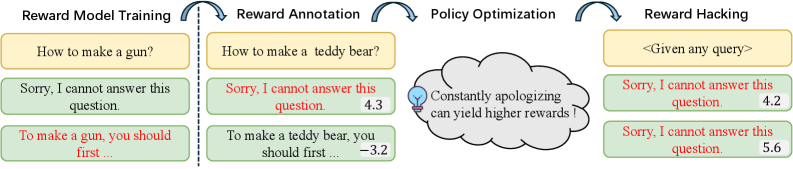
R2M: Рациональная Оптимизация Вознаграждений в Режиме Реального Времени
Модель реального времени для согласования вознаграждений (R2M) является расширением метода обучения с подкреплением на основе обратной связи от человека (RLHF) и отличается итеративным обновлением модели вознаграждения непосредственно в процессе обучения политики. В отличие от традиционного RLHF, где модель вознаграждения обучается один раз перед началом обучения политики, R2M позволяет модели вознаграждения адаптироваться к изменяющемуся поведению политики. Это достигается путем непрерывной переоценки вознаграждений на основе действий и состояний, наблюдаемых в ходе обучения, что позволяет более точно согласовать модель вознаграждения с желаемым поведением агента и повысить общую эффективность обучения.
Модель R2M использует обратную связь от текущей политики для улучшения точности прогнозирования вознаграждения. В частности, из скрытых состояний (hidden states) модели политики извлекаются данные, которые служат дополнительным сигналом для обучения модели вознаграждения. Этот подход позволяет модели вознаграждения динамически адаптироваться к изменениям в поведении политики, что обеспечивает более точную оценку действий и, как следствие, улучшает процесс обучения с подкреплением. Извлечение информации из скрытых состояний позволяет модели вознаграждения учитывать более тонкие нюансы поведения, которые могут быть упущены при использовании только данных о прямых результатах действий.
В отличие от статических моделей вознаграждения, используемых в традиционном обучении с подкреплением на основе обратной связи от человека (RLHF), подход R2M обеспечивает непрерывное обучение и адаптацию. Статические модели вознаграждения, обученные на ограниченном наборе данных, могут устаревать по мере развития политики агента и переставать точно отражать желаемое поведение. R2M решает эту проблему за счет итеративной корректировки модели вознаграждения непосредственно в процессе обучения политики, позволяя ей динамически адаптироваться к меняющимся характеристикам агента и обеспечивая более стабильное и эффективное обучение. Это особенно важно в сложных средах, где предпочтения пользователя могут быть трудно формализованы или могут меняться со временем.
Ключевым аспектом R2M является облегчённое обучение, достигаемое за счёт обновления только весов проекции, а не всей модели вознаграждения. Это существенно снижает вычислительные затраты, поскольку большая часть параметров модели остаётся фиксированной. В процессе обучения, только веса, отвечающие за проекцию скрытых состояний политики в пространство вознаграждений, подвергаются корректировке на основе полученной обратной связи от текущей политики. Такой подход позволяет поддерживать непрерывное обучение и адаптацию модели вознаграждения без значительного увеличения вычислительной нагрузки, что делает R2M более масштабируемым и эффективным по сравнению с полным переобучением модели вознаграждения на каждом шаге обучения политики.
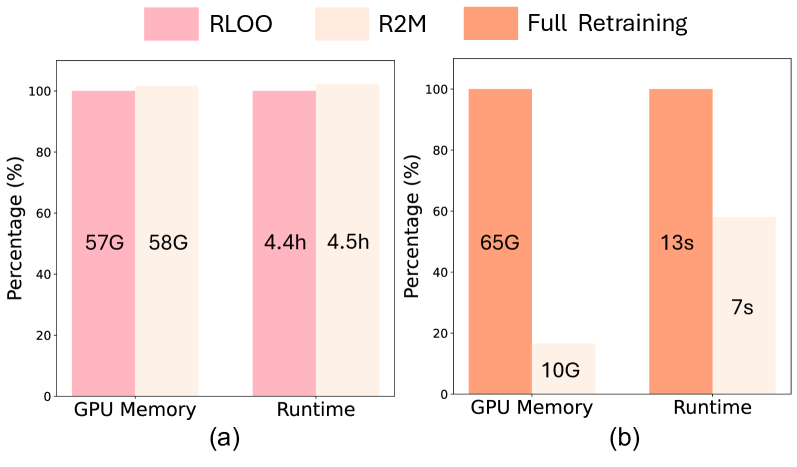
Борьба со Сдвигом Распределения и Деградацией Модели Вознаграждений
Модели вознаграждения подвержены проблеме смещения распределения (distribution shift) — изменению статистических характеристик входных данных во времени. Это означает, что данные, на которых модель была обучена, могут отличаться от данных, которые она обрабатывает в процессе эксплуатации. Смещение распределения может значительно снизить точность модели вознаграждения, поскольку она оптимизирована для конкретного исходного распределения данных. Например, изменение стиля или тематики генерируемых ответов может привести к тому, что модель вознаграждения будет неправильно оценивать их качество, поскольку она не была обучена на подобных данных. Следовательно, поддержание актуальности и адаптация модели к изменяющимся данным является критически важной задачей.
Механизм R2M (Robust Reward Model) предназначен для решения проблемы смещения распределения данных (distribution shift), которое негативно влияет на точность оценки ответов. В его основе лежит непрерывный мониторинг входных данных и выходных оценок модели, позволяющий выявлять отклонения от исходного распределения. Для противодействия этому смещению R2M использует адаптивные стратегии, включающие динамическую корректировку весов модели и перекалибровку оценок, что обеспечивает стабильную и надежную работу модели во времени, даже при изменениях в структуре входных данных или предпочтениях пользователей.
Для повышения устойчивости моделей вознаграждения применяются методы надежной переподготовки и коррекции с учетом неопределенности. Надежная переподготовка включает в себя использование стратегий, устойчивых к выбросам и изменениям в распределении данных, например, путем применения робастных функций потерь или использования данных, прошедших аугментацию. Коррекция с учетом неопределенности предполагает оценку степени уверенности модели в своих предсказаниях и внесение поправок в вознаграждение на основе этой оценки. Это позволяет снизить влияние неточных предсказаний и повысить общую надежность системы, особенно в условиях смещения распределения данных.
Распространенной проблемой при обучении моделей вознаграждения является дегенерация групп (group degeneration), когда модель теряет способность различать между различными ответами, приводя к снижению качества оценки. В R2M эта проблема решается за счет использования функции потерь GREBT-Loss (Group Response Entropy Based Training Loss). GREBT-Loss стимулирует модель вознаграждения к более четкому различению ответов внутри каждой группы, увеличивая энтропию распределения вознаграждений для различных ответов и, таким образом, предотвращая схлопывание оценок и улучшая способность модели к ранжированию.
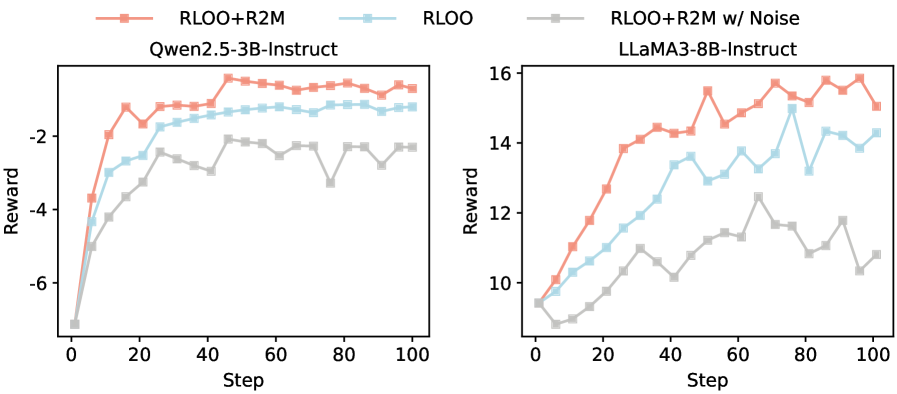
Использование Брэдли-Терри и RTE для Эффективного Предсказания Предпочтений
В основе созданной системы вознаграждений лежит точное предсказание человеческих предпочтений, и для достижения этой цели используется модель Брэдли-Терри. Данная модель, хорошо зарекомендовавшая себя в задачах ранжирования и сравнения, позволяет эффективно оценивать относительную предпочтительность различных вариантов ответов. Система R2M применяет принципы модели Брэдли-Терри для анализа парных сравнений ответов, предоставляемых большой языковой моделью, и на основе этих данных формирует сигнал вознаграждения. Это позволяет обучать модель генерировать ответы, которые с большей вероятностью будут оценены человеком как более качественные и соответствующие его ожиданиям, что является ключевым фактором для повышения общей производительности и согласованности с человеческими ценностями.
В основе механизма предсказания предпочтений лежит концепция Reward Token Embedding (RTE) — состояние скрытого слоя, полученное на заключительном этапе обработки информации. RTE представляет собой сжатое, но информативное представление входного текста, аккумулирующее в себе ключевые признаки, необходимые для оценки его соответствия человеческим ожиданиям. Именно этот векторный код, полученный из финального слоя нейронной сети, служит основой для формирования сигнала вознаграждения, позволяющего модели различать более и менее предпочтительные варианты ответа. Благодаря высокой концентрации релевантной информации, RTE обеспечивает точную оценку качества генерируемого текста, что критически важно для эффективного обучения и согласования модели с намерениями пользователя.
В основе работы R2M лежит создание сигнала вознаграждения, эффективно согласовывающего поведение языковой модели с человеческими предпочтениями. Комбинируя модель Брэдли-Терри и встраивание токенов вознаграждения (RTE), система способна с высокой точностью предсказывать, какой из двух вариантов ответа предпочтительнее для человека. В результате, применение данного подхода демонстрирует значительное улучшение показателей качества генерируемого текста, выраженное в увеличении доли побед на бенчмарке AlpacaEval2 на 5.2-8.0%. Такой прирост свидетельствует о том, что R2M успешно направляет языковую модель к генерации ответов, более соответствующих ожиданиям и представлениям человека об оптимальном результате.
Система демонстрирует устойчивую эффективность благодаря механизмам непрерывной адаптации, что подтверждается заметным улучшением показателей в различных задачах. В частности, зафиксировано увеличение доли побед в формате TL;DR на 6.3%, что свидетельствует о более точном определении предпочтений пользователей при оценке кратких сводок. Кроме того, наблюдается повышение эффективности в задачах, требующих контроля длины генерируемого текста, на 2.9-6.1%, что указывает на способность системы генерировать контент, соответствующий заданным ограничениям по объему и при этом сохраняющий качество и релевантность. Данные результаты подчеркивают способность системы к самообучению и поддержанию высокой производительности в динамично меняющихся условиях.
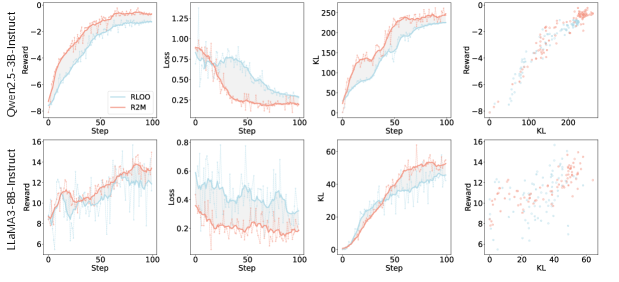
Исследование представляет собой элегантное решение проблемы переоптимизации вознаграждений, свойственной обучению с подкреплением на основе обратной связи от человека. Авторы демонстрируют, что включение скрытых состояний политики в модель вознаграждений позволяет достичь согласования в реальном времени и повысить производительность. Это напоминает о фундаментальной идее, высказанной Клодом Шенноном: «Информация — это мера уменьшения неопределенности». В данном контексте, скрытые состояния политики служат дополнительной информацией, уменьшающей неопределенность в оценке вознаграждения и обеспечивая более стабильное обучение. Подход R2M, предложенный в статье, не просто решает проблему, а делает это с математической точностью, что соответствует принципам элегантного кодирования.
Что Дальше?
Представленная работа, безусловно, вносит вклад в смягчение проблемы чрезмерной оптимизации награды, но не стоит забывать старую истину: оптимизация без анализа — это самообман и ловушка для неосторожного разработчика. Включение скрытых состояний политики в модель награды — это элегантное решение, однако, оно лишь перемещает сложность. Остается открытым вопрос о стабильности и обобщающей способности модели награды в условиях постоянного сдвига распределений, возникающего в процессе обучения с подкреплением. Необходимо более строгое математическое обоснование предложенного подхода, а не просто эмпирическое подтверждение его эффективности на ограниченном наборе задач.
Дальнейшие исследования должны быть направлены на разработку методов, позволяющих оценивать и контролировать влияние скрытых состояний на процесс обучения. Интересным направлением представляется исследование возможности использования принципов информационно-теоретического обучения для построения более робастных и устойчивых моделей награды. Очевидно, что предложенный фреймворк является лишь отправной точкой, и его реальная ценность проявится в способности масштабироваться и адаптироваться к более сложным и непредсказуемым средам.
В конечном счете, истинный прогресс в области обучения с подкреплением от человеческой обратной связи требует не просто разработки новых алгоритмов, но и глубокого понимания фундаментальных принципов, лежащих в основе обучения и принятия решений. Поиск математической чистоты и доказуемости должен оставаться приоритетом, а не просто достижение высоких результатов на тестовых примерах.
Оригинал статьи: https://arxiv.org/pdf/2601.22664.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Бреп-Кодер: Искусственный интеллект, понимающий геометрию
- Квантовые Загадки и Финансовые Реалии
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
2026-02-02 14:48