Автор: Денис Аветисян
Новый подход к токенизации визуальной информации позволяет создавать более качественные изображения, тесно связывая этапы анализа и синтеза.
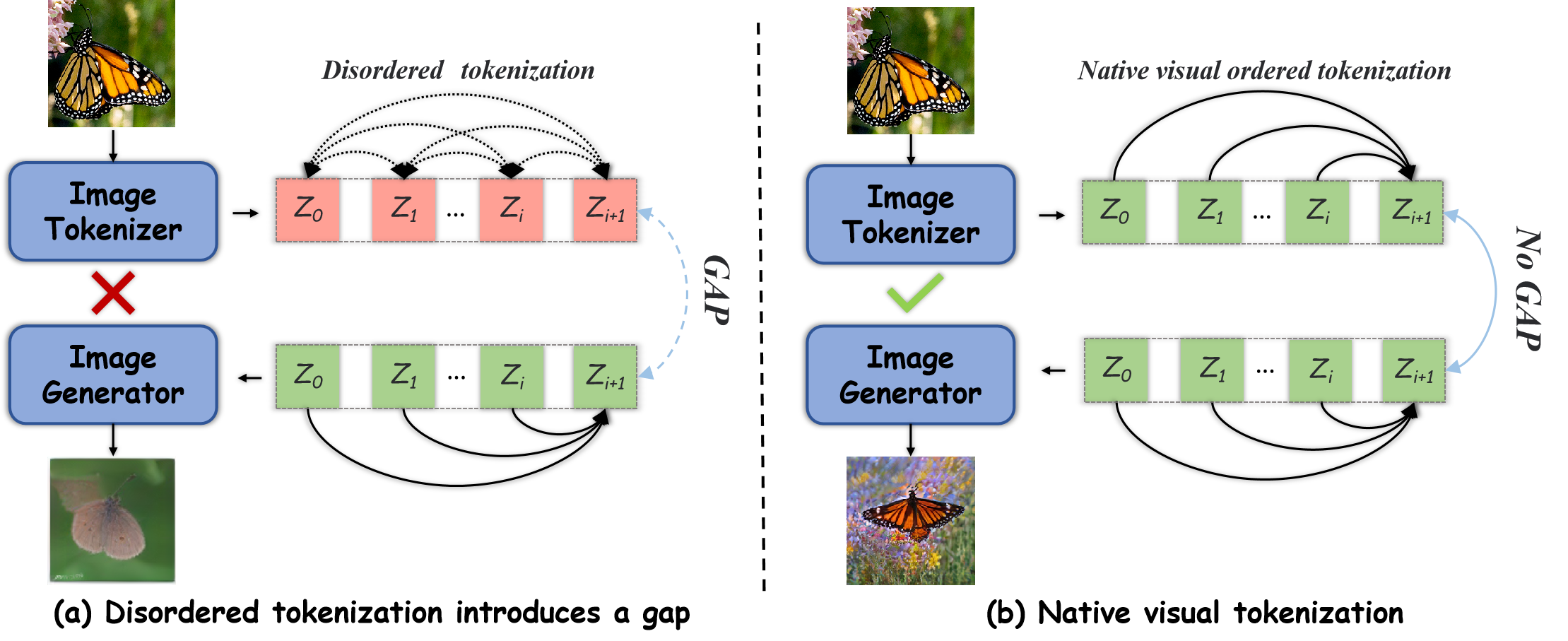
В статье представлена NativeTok — методика, использующая упорядоченные последовательности визуальных токенов для повышения эффективности генеративных моделей, включая авторегрессивные и диффузионные.
Несмотря на успехи в области генерации изображений на основе дискретных токенов, существующие методы часто не учитывают взаимосвязи между ними, что приводит к снижению качества реконструкции. В работе ‘NativeTok: Native Visual Tokenization for Improved Image Generation’ предложен новый подход к визуальной токенизации, обеспечивающий формирование упорядоченных последовательностей токенов, соответствующих процессу генерации. Ключевым элементом является NativeTok — фреймворк, использующий Meta Image Transformer и Mixture of Causal Expert Transformer для эффективной реконструкции и встраивания реляционных ограничений. Способна ли данная архитектура, с иерархической стратегией обучения, существенно улучшить когерентность и реалистичность генерируемых изображений?
За пределами пикселей: Понимание визуальных связей
Традиционные методы токенизации изображений зачастую игнорируют причинно-следственные связи внутри визуальной информации, рассматривая отдельные фрагменты изображения как независимые элементы. Этот подход, по сути, лишает систему способности понимать, как объекты и их характеристики взаимосвязаны в реальном мире. Вместо восприятия сцены как последовательности событий или взаимозависимых частей, модель оперирует лишь набором несвязанных «кусочков», что существенно ограничивает её возможности в задачах генерации и понимания изображений. В результате, сгенерированные изображения могут быть лишены логической связности и реалистичности, поскольку отсутствует понимание того, как один элемент влияет на другой в визуальном контексте.
Традиционные методы токенизации изображений зачастую игнорируют естественную последовательность, в которой человек воспринимает визуальную информацию. Вместо анализа причинно-следственных связей между элементами сцены, они рассматривают отдельные фрагменты как изолированные единицы. Это приводит к тому, что генерируемые изображения лишены целостности и реалистичности, поскольку отсутствует понимание того, как объекты взаимодействуют друг с другом и формируют общее визуальное повествование. В результате, алгоритмы испытывают трудности в создании правдоподобных и когерентных сцен, поскольку не способны воспроизвести логичную последовательность визуального восприятия, свойственную человеческому зрению.
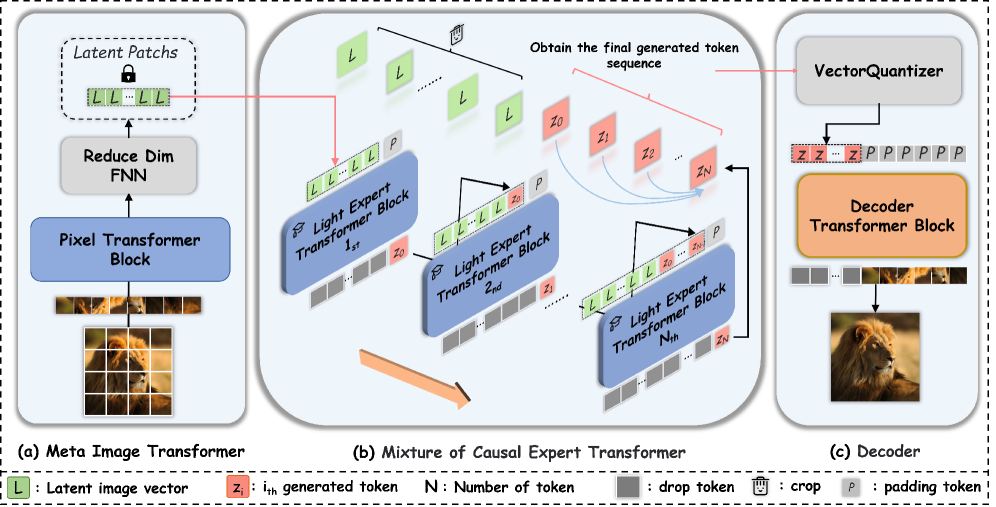
NativeTok: Каузальный подход к визуальной токенизации
Визуальная токенизация NativeTok преобразует изображения в упорядоченные последовательности токенов, что имитирует последовательный характер человеческого зрительного восприятия и причинно-следственного мышления. В отличие от традиционных подходов, рассматривающих изображения как набор независимых признаков, NativeTok моделирует визуальную информацию как серию взаимосвязанных элементов, расположенных во времени. Этот подход позволяет моделировать причинно-следственные связи между различными частями изображения, поскольку порядок токенов отражает последовательность, в которой зрительная система обрабатывает визуальную сцену. Формирование упорядоченной последовательности обеспечивает возможность применения методов, разработанных для обработки последовательностей, таких как рекуррентные нейронные сети и трансформеры, к задачам компьютерного зрения.
Метод NativeTok реализует кодирование изображений в упорядоченные последовательности токенов посредством использования Meta Image Transformer. Этот трансформатор эффективно моделирует высокоразмерный визуальный контекст, что позволяет учитывать сложные взаимосвязи между различными элементами изображения. Архитектура Meta Image Transformer позволяет обрабатывать изображение как последовательность визуальных паттернов, извлекая и кодируя информацию о пространственном расположении, текстуре и других визуальных характеристиках, что обеспечивает более полное и точное представление изображения для последующей обработки и анализа.
Ключевым компонентом архитектуры является “Mixture of Causal Expert Transformer” (MoCET), представляющий собой ансамбль из легковесных экспертных моделей. Каждая экспертная модель специализируется на обработке токенов, находящихся в определенной позиции в последовательности визуальных токенов. Такой подход позволяет эффективно моделировать причинно-следственные связи между различными частями изображения, поскольку каждая экспертная модель фокусируется на конкретном аспекте визуального контекста, что снижает вычислительную сложность и повышает точность моделирования зависимостей между токенами.
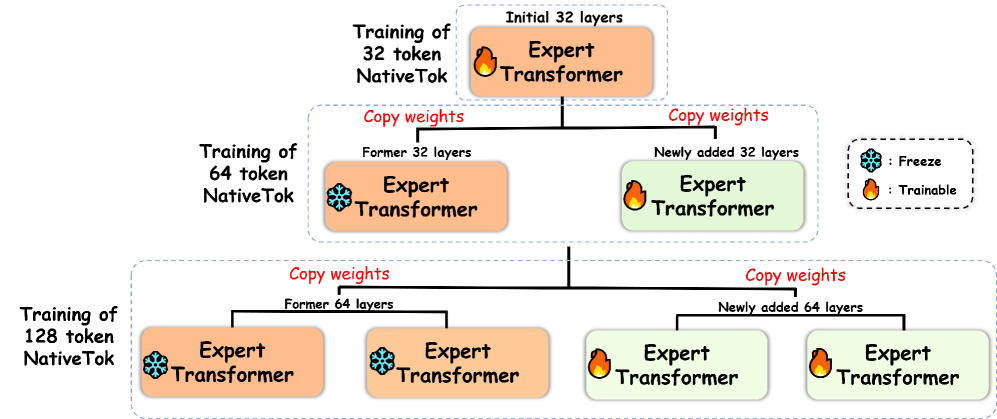
Эффективное обучение с иерархической экспертизой
Стратегия “Иерархическое нативное обучение” позволяет существенно снизить затраты на обучение за счет повторного использования и фиксации весов, полученных от ранее обученных экспертов. Данный подход предполагает, что веса, отвечающие за базовые визуальные признаки, остаются неизменными, а обучение фокусируется исключительно на новых, специфичных для текущей задачи параметрах. Это уменьшает количество обучаемых параметров и, следовательно, потребность в вычислительных ресурсах и времени. Замораживание весов предотвращает их переобучение на новых данных, обеспечивая стабильность и обобщающую способность модели.
Применение иерархического подхода к обучению позволяет быстро адаптировать модель к новым визуальным областям и ускорить процесс обучения без снижения производительности. Это достигается за счет повторного использования и заморозки весов, полученных при обучении на предыдущих задачах, что позволяет модели эффективно переносить знания и избегать необходимости обучения с нуля. В результате, модель быстро осваивает новые данные, сохраняя при этом высокую точность и стабильность работы, что критически важно для приложений, требующих быстрой адаптации к изменяющимся условиям.
В ходе экспериментов было установлено, что использование стратегии иерархического обучения с переносом знаний позволило сократить время обработки одной партии данных до 1.15 секунды. Для сравнения, стандартные методы обучения демонстрировали время обработки партии в 1.53 секунды. Данное снижение времени вычислений достигается за счет повторного использования и фиксации весов, полученных от предварительно обученных экспертов, что значительно повышает эффективность обучения и снижает общие вычислительные затраты.
Подтверждение эффективности: Генерация высококачественных изображений
Исследования, проведенные с использованием моделей LlamaGen и MaskGIT, наглядно демонстрируют превосходство NativeTok в генерации изображений высокого качества. В ходе экспериментов NativeTok последовательно превосходил существующие подходы, создавая более реалистичные и детализированные изображения. Этот подход позволяет добиться значительно лучшей визуальной достоверности, что особенно важно для задач, требующих высокой точности и фотореалистичности генерируемого контента. Результаты подтверждают, что NativeTok является перспективным решением для широкого спектра приложений в области компьютерного зрения и генеративного моделирования.
Оценка производительности модели NativeTok с использованием метрики Fréchet Inception Distance (FID) подтверждает её выдающиеся возможности в генерации высококачественных изображений. Эксперименты показали, что NativeTok достигает значения FID, равного 2.16, при использовании всего 287 миллионов параметров. Это демонстрирует впечатляющую эффективность модели в создании реалистичных и детализированных изображений, несмотря на относительно небольшое количество параметров, что указывает на оптимизированную архитектуру и эффективное использование ресурсов. Полученный результат свидетельствует о значительном прогрессе в области генеративных моделей и открывает новые возможности для создания высококачественного визуального контента.
В ходе сравнительного анализа производительности моделей генерации изображений, NativeTok продемонстрировал превосходство над существующими подходами. В частности, метрика gFID для NativeTok составила 5.23, что значительно ниже показателя TiTok-L-32, равного 7.45. Кроме того, метрика rFID для NativeTok32 зафиксирована на уровне 2.57, что подтверждает высокую степень реалистичности и детализации генерируемых изображений. Эти результаты свидетельствуют о значительном улучшении качества генерации и эффективности использования параметров в модели NativeTok по сравнению с аналогами, что делает её перспективной для широкого спектра приложений в области компьютерного зрения и создания контента.

Исследование, представленное в статье, стремится оптимизировать процесс генерации изображений, вводя концепцию упорядоченной токенизации — NativeTok. Это, однако, лишь очередная попытка обуздать сложность, добавить слой абстракции между замыслом и результатом. Как метко заметил Ян ЛеКюн: «Машинное обучение — это программирование, где вы не знаете, что именно программируете.» И это особенно актуально здесь: стремясь к более качественной генерации, авторы неизбежно сталкиваются с проблемой контроля над тем, как именно модель интерпретирует и воспроизводит визуальную информацию. В конечном счете, элегантная теория столкнется с суровой реальностью продакшена, где каждый новый уровень абстракции — это потенциальный источник ошибок и головной боли для тех, кто будет поддерживать систему.
Куда Поведёт Нас Эта История?
Представленный подход, безусловно, элегантен. Преобразование визуального пространства в упорядоченную последовательность токенов — это, конечно, красиво. Но не стоит забывать, что любая «естественность» в машинном обучении — это иллюзия, тщательно выстроенная на статистических закономерностях. Продакшен обязательно найдёт способ заставить эту «упорядоченность» спотыкаться на самых неожиданных изображениях — например, на фотографиях котиков в шляпах. Вопрос не в улучшении качества генерации как таковом, а в отсрочке неизбежного столкновения с хаосом реального мира.
Наиболее интересным направлением представляется не дальнейшее усложнение токенизаторов, а исследование устойчивости этих систем к «враждебным» изображениям. Насколько легко можно обмануть генеративную модель, подсунув ей слегка изменённое изображение? Сколько ресурсов потребуется для создания действительно робастного токенизатора? И, наконец, не проще ли просто смириться с тем, что идеальной генерации не существует, и сосредоточиться на создании инструментов для исправления неизбежных артефактов?
В конечном итоге, NativeTok — это ещё один шаг на пути к созданию всё более сложных и хрупких систем. Вместо того, чтобы мечтать об автоматической генерации идеальных изображений, стоит подумать о создании инструментов для автоматического исправления тех проблем, которые эти системы неизбежно создают. Тесты — это форма надежды, а не уверенности, и каждый новый «прорыв» — это всего лишь отложенный технический долг.
Оригинал статьи: https://arxiv.org/pdf/2601.22837.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Бреп-Кодер: Искусственный интеллект, понимающий геометрию
- Квантовые Загадки и Финансовые Реалии
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
2026-02-02 16:19