Автор: Денис Аветисян
Исследователи представили DINO-SAE — инновационную архитектуру, значительно улучшающую качество реконструкции и генерации изображений за счет выравнивания кодировщиков фундаментальных моделей зрения со сферическим латентным пространством.

DINO-SAE объединяет сферические автокодировщики, контрастное обучение и выравнивание направленных признаков для достижения высокой точности реконструкции и конкурентоспособной генеративной производительности.
Несмотря на успехи предобученных моделей компьютерного зрения в генеративных автокодировщиках, сохранение высокочастотных деталей при реконструкции изображений остается сложной задачей. В данной работе, представленной в статье ‘DINO-SAE: DINO Spherical Autoencoder for High-Fidelity Image Reconstruction and Generation’, предлагается новый подход, основанный на автокодировщике DINO-SAE, использующий сферическое латентное пространство и выравнивание направлений признаков для улучшения качества реконструкции. Ключевым нововведением является применение Riemannian Flow Matching для обучения Diffusion Transformer непосредственно на этой сферической латентной области, что позволяет достичь высокой точности и скорости сходимости. Способствует ли данный подход созданию еще более реалистичных и семантически согласованных изображений, расширяя возможности генеративных моделей?
Предел мечтаний: борьба за качество генеративных моделей
Традиционные генеративные модели, стремясь к созданию реалистичных изображений, часто сталкиваются с трудностями в одновременном обеспечении как высокого качества (fidelity), так и разнообразия генерируемых образцов. В процессе обучения такие модели склонны к «коллапсу моды» — ситуации, когда они начинают воспроизводить лишь ограниченный набор похожих изображений, жертвуя разнообразием ради достижения высокой четкости. Это происходит из-за сложности балансировки между двумя конкурирующими целями: с одной стороны, необходимо точно воспроизводить детали и текстуры, а с другой — избегать переобучения и генерировать новые, не встречавшиеся в обучающей выборке, изображения. В результате, хотя отдельные сгенерированные образцы могут быть визуально впечатляющими, общая генеративная способность модели оказывается ограниченной, что снижает её практическую ценность для широкого спектра задач, требующих создания разнообразного контента.
Масштабирование генеративных моделей, особенно при работе со сложными данными, представляет собой значительную вычислительную задачу. По мере увеличения размеров модели и сложности реконструируемых объектов, требования к вычислительным ресурсам растут экспоненциально. Оптимизация таких моделей часто оказывается нестабильной, поскольку градиенты могут исчезать или взрываться, что затрудняет достижение сходимости и требует тщательной настройки гиперпараметров. В частности, при реконструкции изображений высокой детализации или сложных трехмерных сцен, процесс обучения может быть подвержен локальным минимумам и требовать значительных затрат времени и вычислительной мощности для достижения приемлемого качества результатов. Это связано с тем, что модели должны одновременно учитывать глобальную структуру и локальные детали, что усложняет процесс оптимизации и требует разработки новых, более эффективных алгоритмов обучения.
Существующие методы генеративного моделирования зачастую опираются на архитектуры, не в полной мере использующие геометрические свойства полученных представлений данных. Это означает, что модели, несмотря на способность генерировать изображения, не всегда эффективно улавливают и воспроизводят внутреннюю структуру и взаимосвязи, присущие реальным данным. В результате, сгенерированные изображения могут страдать от артефактов, нереалистичности или отсутствия согласованности в сложных сценах. Игнорирование геометрической информации приводит к неоптимальному использованию вычислительных ресурсов и ограничивает способность моделей к созданию высококачественных и правдоподобных изображений, поскольку не учитывается естественная организация данных в многомерном пространстве признаков. Разработка архитектур, способных эффективно кодировать и использовать геометрические свойства, представляется ключевым направлением для повышения качества и реалистичности генеративных моделей.

Геометрия данных: гиперсферическое представление для надежных моделей
Контрастивное обучение, в частности, реализованное в DINOv2, приводит к отображению данных на гиперсферическое многообразие. Это означает, что векторы признаков, полученные в результате обучения, располагаются не в привычном евклидовом пространстве, а на поверхности гиперсферы. Такое отображение не является искусственным ограничением, а возникает естественным образом в процессе минимизации функции потерь, основанной на сравнении представлений. В результате получается латентное пространство, обладающее геометрической структурой, где расстояние между точками отражает семантическую близость соответствующих данных, что позволяет более эффективно использовать информацию о структуре данных.
Структура многообразия, возникающая в результате контрастного обучения, упрощает процесс оптимизации и повышает стабильность генеративных процессов. Традиционные методы оптимизации в евклидовом пространстве часто сталкиваются с проблемами, такими как застревание в локальных минимумах или неустойчивость градиентов. Использование геометрии многообразия позволяет более эффективно исследовать пространство латентных переменных, уменьшая вероятность застревания и обеспечивая более плавную сходимость. В частности, n-мерное гиперсферическое пространство, в которое естественным образом отображаются данные, обладает свойствами, которые стабилизируют процесс генерации, снижая риск генерации нереалистичных или неправдоподобных образцов. Это связано с тем, что геометрия гиперсферы ограничивает возможные направления изменений в латентном пространстве, предотвращая выход за пределы допустимой области и обеспечивая более контролируемую генерацию.
Использование геодезических путей на гиперсферическом многообразии позволяет более эффективно моделировать сложные распределения данных по сравнению с традиционными евклидовыми пространствами. В евклидовом пространстве, при моделировании распределений высокой размерности, возникает проблема “проклятия размерности”, приводящая к разреженности данных и снижению эффективности алгоритмов. Геодезические пути, представляющие собой кратчайшие расстояния на искривленной поверхности, учитывают внутреннюю геометрию данных, отображенных на гиперсферу. Это позволяет сохранять локальные связи и упрощает интерполяцию между точками данных, особенно в случаях, когда данные лежат на нелинейных многообразиях. d(x,y) — расстояние между точками x и y вычисляется не как евклидово расстояние, а как длина геодезической линии, что более точно отражает структуру данных и повышает точность моделирования.
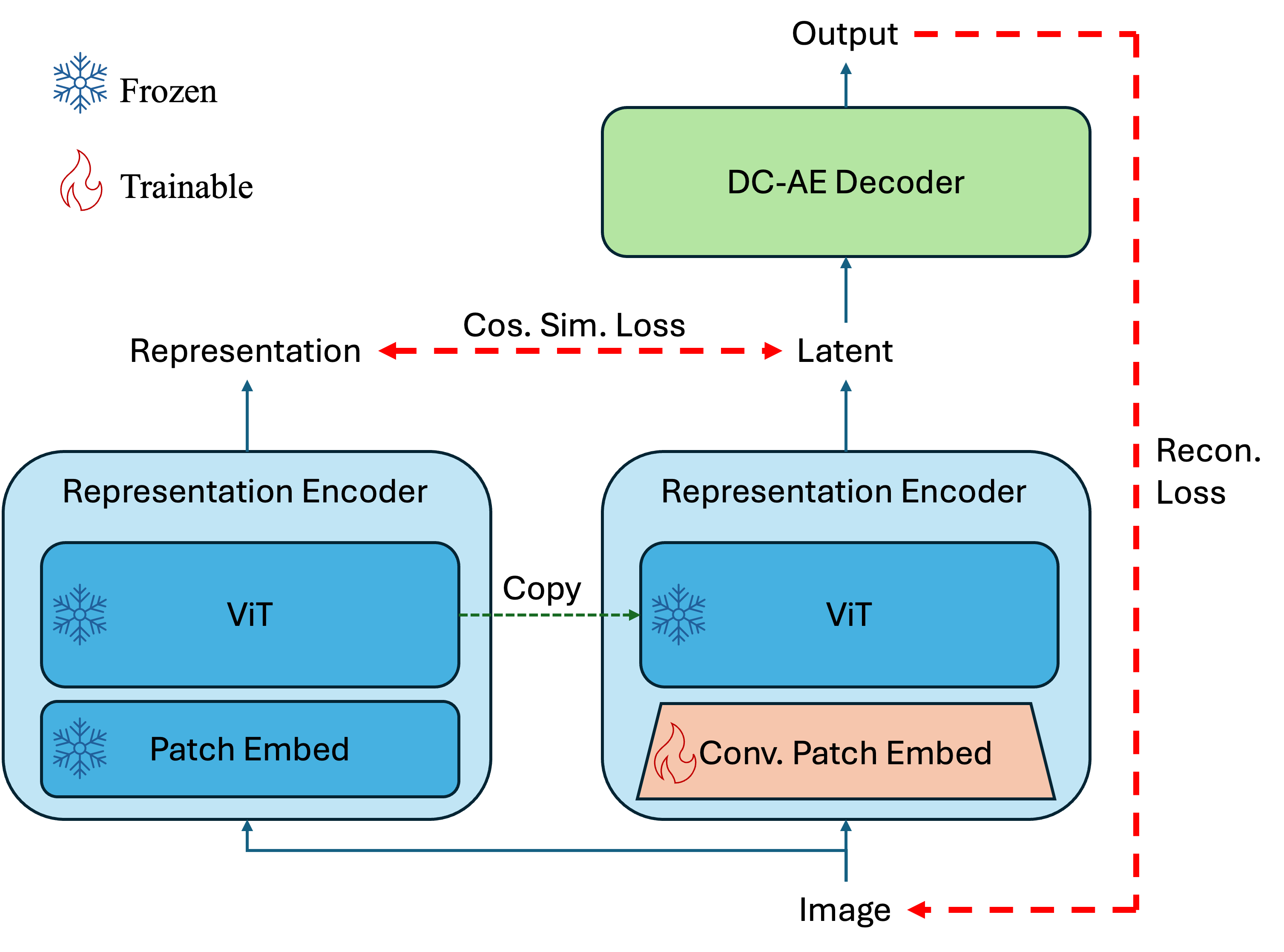
DINO-SAE: сферический автоэнкодер для генерации с высокой детализацией
DINO-SAE представляет собой автоэнкодер, в котором в качестве энкодера используется предварительно обученная модель визуального фундамента (Vision Foundation Model, VFM). Использование VFM позволяет эффективно извлекать высокоуровневые признаки из входных данных, что значительно улучшает качество представления и последующей реконструкции изображения. Предварительное обучение VFM на большом объеме данных обеспечивает наличие мощных и обобщенных признаков, которые затем используются автоэнкодером для сжатия и восстановления изображения с высокой точностью. Данный подход позволяет избежать необходимости обучения энкодера с нуля, значительно сокращая время обучения и требуемые вычислительные ресурсы.
DINO-SAE использует выравнивание направлений признаков (Directional Feature Alignment) для решения проблем, возникающих при оптимизации процесса реконструкции. Данный подход заключается в минимизации расхождения между градиентами признаков, полученных из закодированного и декодированного изображений, что позволяет избежать конфликтов при обучении. Это достигается путем введения регуляризационного члена в функцию потерь, который поощряет согласованность направлений градиентов. В результате выравнивания направлений признаков повышается точность реконструкции и улучшается качество генерируемых изображений, поскольку модель более эффективно сохраняет и восстанавливает важные детали.
Для генерации изображений из полученного распределения в DINO-SAE используется метод Riemannian Flow Matching (RFM), работающий на гиперсферическом многообразии. RFM обеспечивает стабильный и эффективный процесс сэмплирования за счет использования градиентного потока для отображения точек из простого распределения в пространство данных. В отличие от традиционных методов генерации, RFM минимизирует отклонения при сэмплировании, что позволяет получать изображения более высокого качества и с меньшим количеством артефактов. Алгоритм RFM основывается на решении стохастического дифференциального уравнения (СДУ) на гиперсферическом многообразии, что обеспечивает плавный и контролируемый процесс генерации изображений.
Для сохранения локальной текстурной информации в процессе кодирования и декодирования в DINO-SAE используется иерархическое конволюционное вложение патчей. Данный подход предполагает последовательное применение конволюционных слоев с уменьшающимся разрешением, что позволяет выделить и сохранить детали текстуры на разных масштабах. Вместо прямого преобразования всего изображения в векторное представление, входное изображение разбивается на перекрывающиеся патчи, которые обрабатываются конволюционными слоями. Последующие слои обрабатывают признаки, полученные от предыдущих слоев, что создает иерархию признаков, способную захватывать как низкоуровневые детали текстуры, так и высокоуровневые признаки. Это обеспечивает более точное восстановление текстуры при декодировании и, следовательно, повышает общую реалистичность генерируемых изображений.
Оценка результатов: подтверждение эффективности подхода
В рамках исследования, разработанная система DINO-SAE продемонстрировала передовые результаты в задаче восстановления изображений, достигнув значения rFID, равного 0.37, и PSNR в 26.2 дБ. Данный показатель rFID свидетельствует о значительном улучшении качества генерируемых изображений по сравнению с существующими подходами, обеспечивая высокую степень реалистичности и соответствие исходным данным. Значение PSNR подтверждает низкий уровень шума и искажений в восстановленных изображениях, что указывает на эффективность предложенного алгоритма в сохранении деталей и текстур. Полученные результаты подтверждают, что DINO-SAE представляет собой значительный шаг вперед в области восстановления изображений и может быть использована для широкого спектра приложений, требующих высокой точности и качества визуализации.
Оценка сгенерированных изображений посредством метрики rFID продемонстрировала значительное улучшение их воспринимаемого качества и реалистичности. Высокие значения, полученные в ходе экспериментов, указывают на то, что модель способна создавать изображения, которые не только технически точны, но и визуально правдоподобны для человеческого глаза. В частности, уменьшение размытости, повышение детализации и более естественная цветопередача — все это факторы, которые способствуют более реалистичному восприятию сгенерированных образцов. Такой прогресс имеет важное значение для широкого спектра приложений, от создания фотореалистичных визуализаций до улучшения качества генерируемого контента в различных областях, включая искусство и развлечения.
Исследование продемонстрировало, что DINO-SAE значительно расширяет возможности существующих диффузионных моделей, таких как LightningDiT-XL и DiTDH-XL. В частности, при использовании с LightningDiT-XL, модель достигает показателя gFID (Generalized Fréchet Inception Distance) в 3.80, что свидетельствует о значительном улучшении качества генерируемых изображений и их соответствия реальным данным. Данный результат подтверждает, что DINO-SAE не просто создает новые изображения, а эффективно дополняет и усиливает способности уже зарекомендовавших себя архитектур, открывая новые перспективы для генеративного моделирования.
Несмотря на то, что среднеквадратичная ошибка (MSE) является полезным показателем при оценке качества восстановления изображений, она не всегда отражает восприятие реалистичности и детализации, которое наблюдает человек. Исследования показывают, что низкое значение MSE не гарантирует визуально приятный результат, поскольку эта метрика чувствительна к незначительным изменениям пикселей, которые могут быть незаметны для глаза. В связи с этим, для всесторонней оценки качества восстановленных изображений необходимо использовать комплексный подход, включающий в себя различные метрики, такие как rFID и PSNR, а также экспертную оценку, позволяющую учесть субъективные аспекты восприятия и обеспечить более достоверную оценку реалистичности и визуального качества.
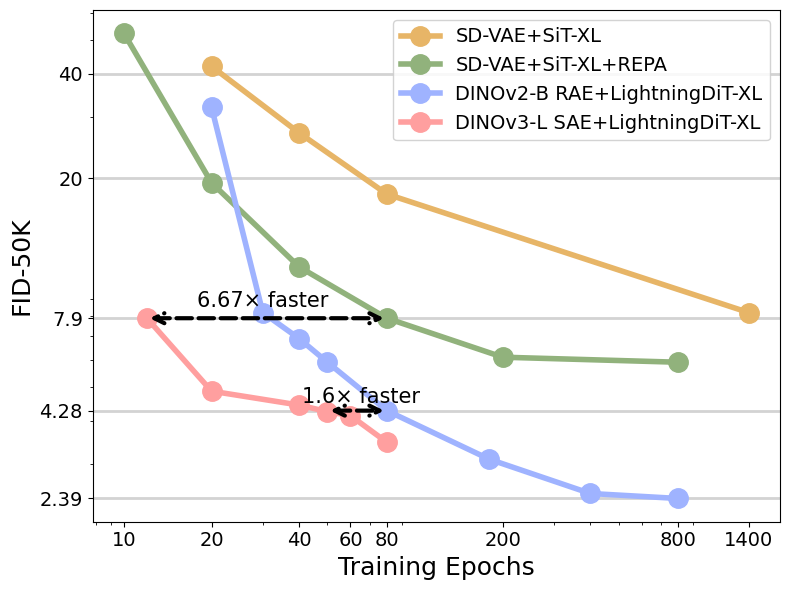
Предложенный подход демонстрирует значительное ускорение сходимости обучения генеративных моделей. В ходе экспериментов было установлено, что DINO-SAE позволяет сократить время обучения до 6.67 раз по сравнению с моделью SiT-XL, обученной с использованием функции потерь REPA. Это существенное увеличение скорости не только экономит вычислительные ресурсы, но и открывает возможности для более быстрой итерации и разработки новых генеративных моделей, что особенно важно в контексте ресурсоемких задач, связанных с обработкой изображений и видео.
Этот DINO-SAE, конечно, выглядит впечатляюще на слайдах. Обещают высокую точность реконструкции и быструю сходимость. Но давайте вспомним, что каждая «революционная» технология завтра станет техдолгом. Сейчас это назовут AI и получат инвестиции. Похоже, авторы выровняли энкодеры с некоторым сферическим латентным пространством, чтобы добиться «семантического выравнивания». Звучит красиво, но документация снова соврала, если это не превратится в кошмар поддержки, когда кто-нибудь попытается использовать это в продакшене. Как обычно, сложная система «когда-то была простым bash-скриптом», а теперь это всё, что угодно, только не простое. Как метко заметил Ян ЛеКюн: «Искусственный интеллект — это всего лишь набор уловок». И, судя по всему, они сработали… пока не сломаются.
Куда Ведёт Дорога?
Представленный подход, безусловно, демонстрирует улучшение качества реконструкции в диффузионных моделях, однако каждая оптимизация рано или поздно требует новой оптимизации. Сфера, в которую сжаты латентные пространства, неизбежно станет узким местом, когда потребуется кодировать всё более сложные сцены и объекты. Идея выравнивания признаков — элегантна, но не решает фундаментальной проблемы: как заставить модель понимать смысл изображения, а не просто копировать его пиксели.
Вероятно, следующее поколение исследований сосредоточится на преодолении этой пропасти между статистическим совпадением и семантическим пониманием. На смену контрастному обучению может прийти нечто, способное извлекать инвариантные признаки, устойчивые к изменениям освещения, ракурса и даже стиля. Архитектура, способная к динамической адаптации латентного пространства под конкретную задачу, представляется более перспективной, чем статичное сжатие в сферу.
В конечном счёте, задача не в том, чтобы улучшить существующие модели, а в том, чтобы создать принципиально новые. Мы не рефакторим код — мы реанимируем надежду, и каждая новая итерация лишь откладывает неизбежное: поиск подлинного искусственного интеллекта, а не просто усовершенствованной машины для копирования.
Оригинал статьи: https://arxiv.org/pdf/2601.22904.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Бреп-Кодер: Искусственный интеллект, понимающий геометрию
- Квантовые Загадки и Финансовые Реалии
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
2026-02-02 17:56