Автор: Денис Аветисян
Исследователи предлагают новый метод оценки способности генеративных моделей создавать изображения, неотличимые от личного визуального вкуса конкретного человека.
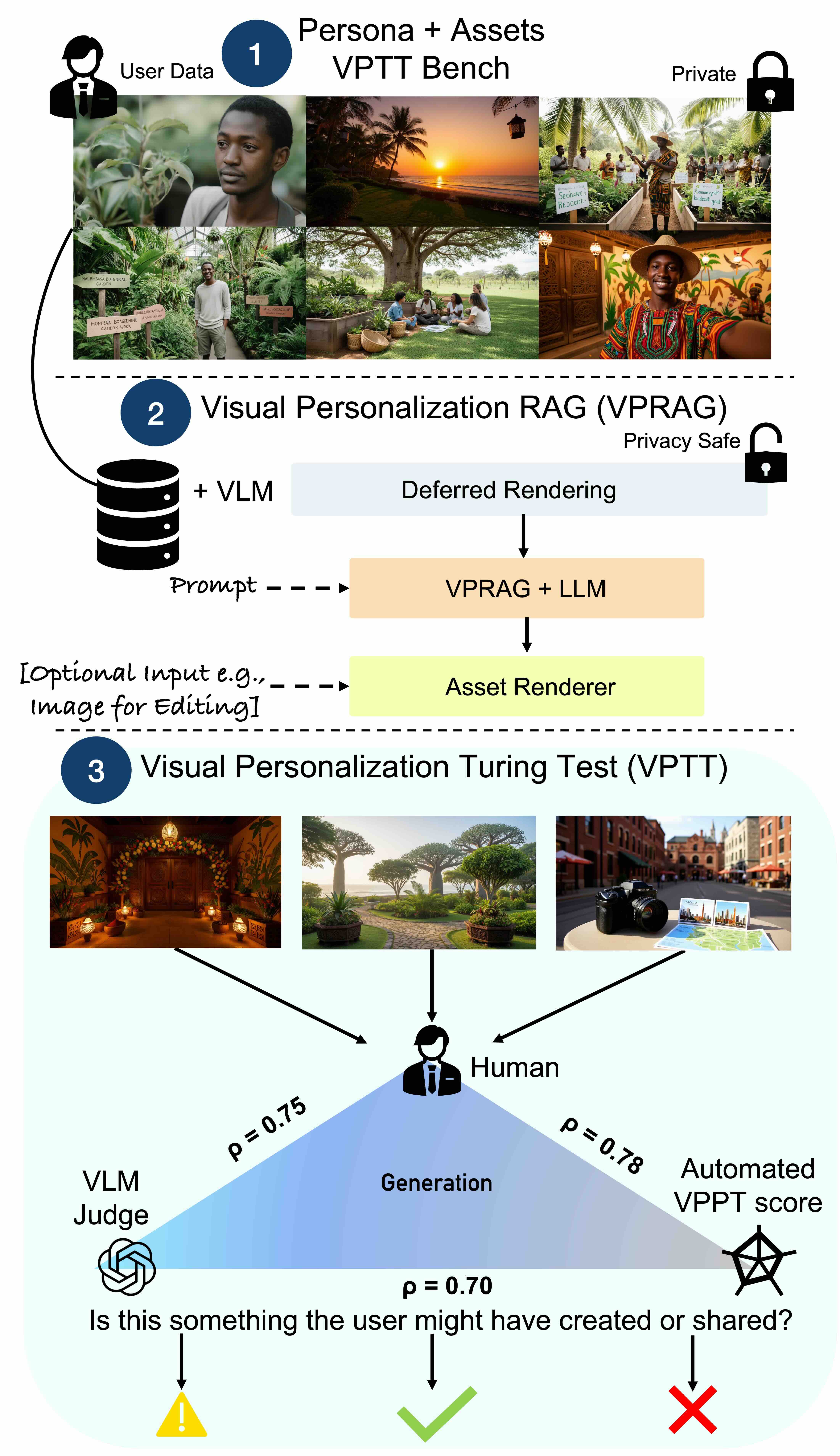
Представлен тест Visual Personalization Turing Test (VPTT) и масштабный датасет VPTT-Bench для оценки и улучшения персонализации визуального контента.
Оценка персонализации визуального контента традиционно фокусируется на точном воспроизведении стиля, упуская из виду субъективное восприятие. В данной работе представлена концепция ‘Visual Personalization Turing Test’ (VPTT) — новый подход к оценке персонализированной генерации визуального контента, основанный на принципах перцептивной неразличимости. Предложенный тест и соответствующий бенчмарк VPTT-Bench позволяют оценить, насколько сгенерированный контент неотличим от того, что мог бы создать конкретный пользователь, обеспечивая надежную прокси-метрику, коррелирующую с оценками людей и калиброванных моделей VLM. Возможно ли создание масштабируемых и конфиденциальных систем генерации контента, способных к действительно персонализированному визуальному самовыражению?
Преодолевая Границы Персонализации: Вызов Контекстуальной Релевантности
Современные системы генерации контента зачастую сталкиваются с проблемой недостаточной персонализации, что приводит к созданию обобщенных и нерелевантных результатов. Несмотря на значительный прогресс в области искусственного интеллекта, алгоритмы часто не способны учитывать тонкие нюансы индивидуальных предпочтений пользователя, выдавая усредненный продукт, не отвечающий конкретным запросам. Это особенно заметно в визуальном контенте, где эстетические предпочтения крайне субъективны, и стандартные подходы не могут эффективно уловить индивидуальный вкус. В результате, пользователь сталкивается с потоком информации, которая, хотя и технически корректна, не вызывает отклика и не соответствует его ожиданиям, снижая эффективность взаимодействия и вызывая чувство разочарования.
Масштабирование персонализации сталкивается с серьезной задачей: необходимо эффективно управлять сложными предпочтениями и визуальными стилями каждого пользователя, не нарушая при этом его право на конфиденциальность. Современные подходы к сбору и обработке данных часто требуют избыточной информации, что создает риски утечки личных данных. Поэтому, разрабатываются новые методы, основанные на дифференциальной приватности и федеративном обучении, позволяющие создавать персонализированный контент, используя только агрегированные данные или локальные вычисления на устройстве пользователя. Это позволяет сохранить баланс между предоставлением релевантного опыта и защитой личной информации, открывая путь к действительно индивидуализированному контенту в больших масштабах.
Традиционные методы персонализации визуального контента часто оказываются неэффективными из-за сложности улавливания тонких связей между индивидуальностью пользователя и его эстетическими предпочтениями. Стандартные алгоритмы, как правило, опираются на ограниченный набор характеристик или явных указаний, что приводит к упрощенным и зачастую нерелевантным результатам. Вместо того чтобы учитывать многогранность личного вкуса, включающую в себя культурные влияния, эмоциональные ассоциации и подсознательные предпочтения, существующие системы склонны к обобщениям. Это приводит к тому, что генерируемый контент, несмотря на формальное соответствие заданным параметрам, не вызывает ожидаемого отклика у пользователя и не соответствует его истинным потребностям в визуальном самовыражении. Таким образом, для достижения подлинной персонализации необходимо преодолеть ограничения существующих подходов и разработать более утонченные методы, способные учитывать всю сложность человеческого восприятия и вкуса.
Для создания действительно персонализированного контента требуется принципиально новый подход, выходящий за рамки традиционных методов. Существующие системы часто оперируют обобщенными предпочтениями, не учитывая тонкие нюансы индивидуального вкуса и контекста. Новая парадигма должна позволять не просто адаптировать контент под определенные категории, но и генерировать его, отражая уникальное сочетание эстетических предпочтений каждого пользователя. Это подразумевает разработку алгоритмов, способных улавливать сложные взаимосвязи между визуальными элементами и личными вкусами, а также учитывать динамически меняющиеся предпочтения. Такой подход откроет возможности для создания контента, который будет не просто релевантным, но и по-настоящему резонировать с индивидуальностью каждого зрителя, формируя более глубокую и осмысленную связь с представленной информацией.
![Используя VPTT-Bench, наша система Visual Personalization RAG (VPRAG) генерирует персонализированные изображения и редактирует их, основываясь на заданном профиле пользователя (стиль, активы), демонстрируя возможности кросс-модельной персонализации, где активы генерируются QWEN-image-model[65], а сами изображения и их редактирование - Nano-Banana[23], ориентируясь только на исходное изображение.](https://arxiv.org/html/2601.22680v1/sec/figures/main.jpg)
VPTT: Новый Взгляд на Персонализацию Визуального Контента
В отличие от традиционной разработки запросов (prompt engineering), VPTT оценивает сгенерированные изображения на основе принципа “неотличимости от созданных человеком”. Это означает, что система не просто стремится к соответствию текстовому описанию, а оценивает реалистичность и правдоподобность изображения с точки зрения восприятия человеком. Оценка проводится с использованием откалиброванной большой языковой модели (VLM) в качестве судьи, а также путем проведения сравнительного анализа с изображениями, созданными людьми. Основная цель — достижение такого уровня генерации, при котором сгенерированное изображение сложно отличить от реального, что является ключевым фактором для создания персонализированного визуального контента высокого качества.
В основе VPTT лежит система оценки качества и реалистичности персонализированного визуального контента, использующая калиброванного VLM Judge (Visual Language Model Judge) в сочетании с оценкой, проводимой людьми. VLM Judge, предварительно откалиброванный для соответствия человеческому восприятию, автоматически оценивает сгенерированные изображения по ряду параметров, включая визуальную когерентность и соответствие заданным характеристикам. Для обеспечения высокой точности и надежности, результаты, полученные VLM Judge, верифицируются посредством оценки, проводимой людьми-экспертами. Такой комбинированный подход позволяет добиться объективной и достоверной оценки качества персонализированного визуального контента, необходимой для оптимизации и улучшения процесса генерации.
Система VPTT расширяет границы контекстной персонализации, фокусируясь на генерации визуально связных и соответствующих идентичности результатов. В отличие от традиционных методов, VPTT стремится не просто адаптировать контент к контексту, но и обеспечить его согласованность с индивидуальными характеристиками и предпочтениями пользователя. Это достигается за счет анализа и учета различных факторов, определяющих визуальную идентичность, таких как стиль, цветовая гамма, композиция и другие визуальные элементы, что позволяет создавать изображения, максимально соответствующие ожиданиям и потребностям конкретного пользователя.
Подход, реализованный в VPTT, открывает возможности для создания визуального контента, адаптированного к индивидуальным предпочтениям и особенностям каждого пользователя. В отличие от традиционных методов, ориентированных на усредненные запросы, VPTT позволяет генерировать изображения, точно отражающие личные характеристики и визуальный стиль, что обеспечивает более персонализированный и релевантный пользовательский опыт. Это достигается за счет оценки сгенерированных изображений на основе критериев, приближенных к человеческому восприятию, и калибровки модели для достижения высокой степени реалистичности и соответствия индивидуальным запросам пользователя.
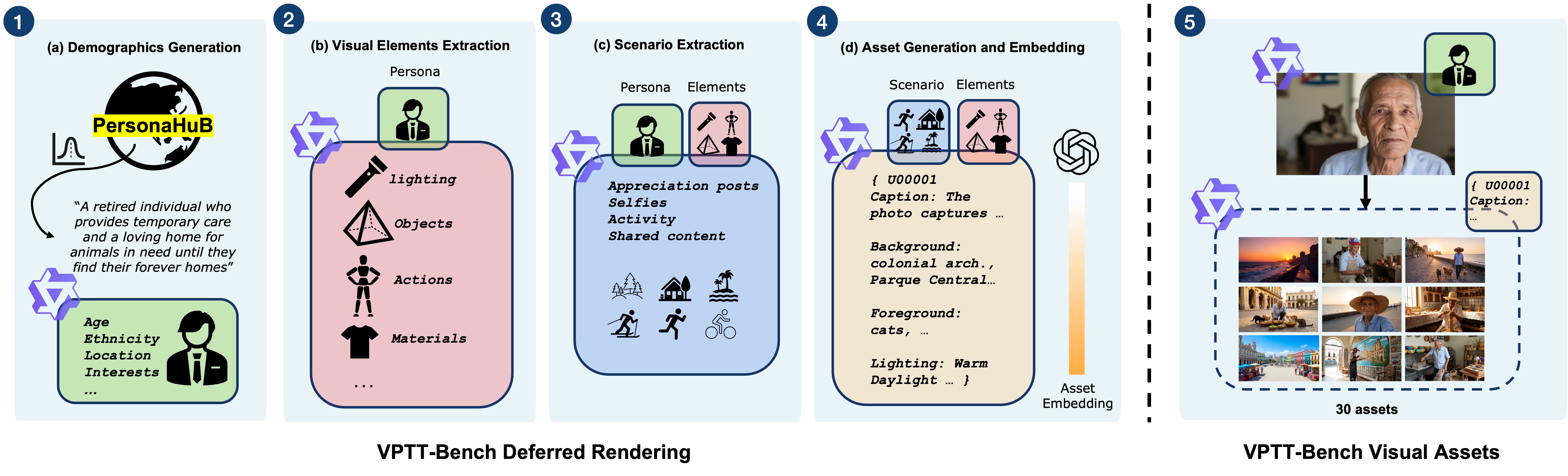
VPTT-Bench: Масштабный Эталон для Конфиденциальной Персонализации
VPTT-Bench предоставляет масштабный набор данных, включающий 10 000 персон и 300 000 сгенерированных ими сообщений. Этот объем данных позволяет проводить всестороннюю оценку методов персонализации, охватывая широкий спектр индивидуальных предпочтений и стилей. Набор данных специально разработан для обеспечения количественной оценки эффективности различных алгоритмов в задачах, требующих адаптации к уникальным характеристикам пользователей. Масштабность набора данных позволяет проводить статистически значимые сравнения и выявлять незначительные различия в производительности различных моделей персонализации, что критически важно для разработки надежных и эффективных систем.
Для представления персональных данных в наборе данных VPTT-Bench используются методы отложенной визуализации (Deferred Rendering). Вместо непосредственного хранения личной информации, каждый персона описывается набором параметров, определяющих его предпочтения и стиль. Эти параметры затем используются для генерации текстового контента, имитирующего поведение данного персона. Такой подход позволяет избежать хранения конфиденциальных данных в явном виде, обеспечивая повышенную конфиденциальность. Кроме того, параметрическое представление персонажей упрощает масштабирование набора данных, поскольку добавление новых персонажей требует лишь определения новых наборов параметров, а не сбора и обработки большого объема личной информации.
Бенчмарк VPTT-Bench позволяет проводить всестороннюю оценку генеративных моделей посредством анализа их способности адаптироваться к широкому спектру индивидуальных предпочтений и визуальных стилей. Оценка охватывает различные аспекты персонализации, включая вариативность в выражении личных интересов и адаптацию к разнообразным эстетическим требованиям. Это достигается за счет использования большого набора данных, включающего 10,000 персон и 300,000 сгенерированных постов, что позволяет оценить производительность моделей в условиях высокой степени разнообразия и сложности. В результате, исследователи могут объективно сравнивать различные генеративные модели и определять их эффективность в задачах персонализированного контента.
Набор данных VPTT-Bench характеризуется разнообразием этнической и географической представленности. В него включены данные, отражающие широкий спектр этнических групп и стран происхождения, что обеспечивает более высокую обобщающую способность моделей персонализации. Распределение данных по этнической принадлежности и странам было тщательно продумано для приближения к реальному распределению населения, что позволяет оценивать производительность моделей в различных культурных контекстах и снижает риск предвзятости, связанной с недостаточной представленностью определенных групп. Это особенно важно для систем, предназначенных для глобального использования, где учет культурных особенностей и разнообразия является критически важным для обеспечения справедливости и эффективности.
![Используя VPTT-Bench, наша система визуальной персонализации на основе RAG (VPRAG) генерирует и редактирует изображения, адаптированные к конкретному пользовательскому профилю, определяемому набором активов и стилистических ориентиров, как показано на примере социальных публикаций, культурных объектов и интерьеров, сгенерированных QWEN-image-model[65] и отредактированных Nano-Banana[23] на основе лишь одного исходного изображения.](https://arxiv.org/html/2601.22680v1/sec/figures/main2.jpg)
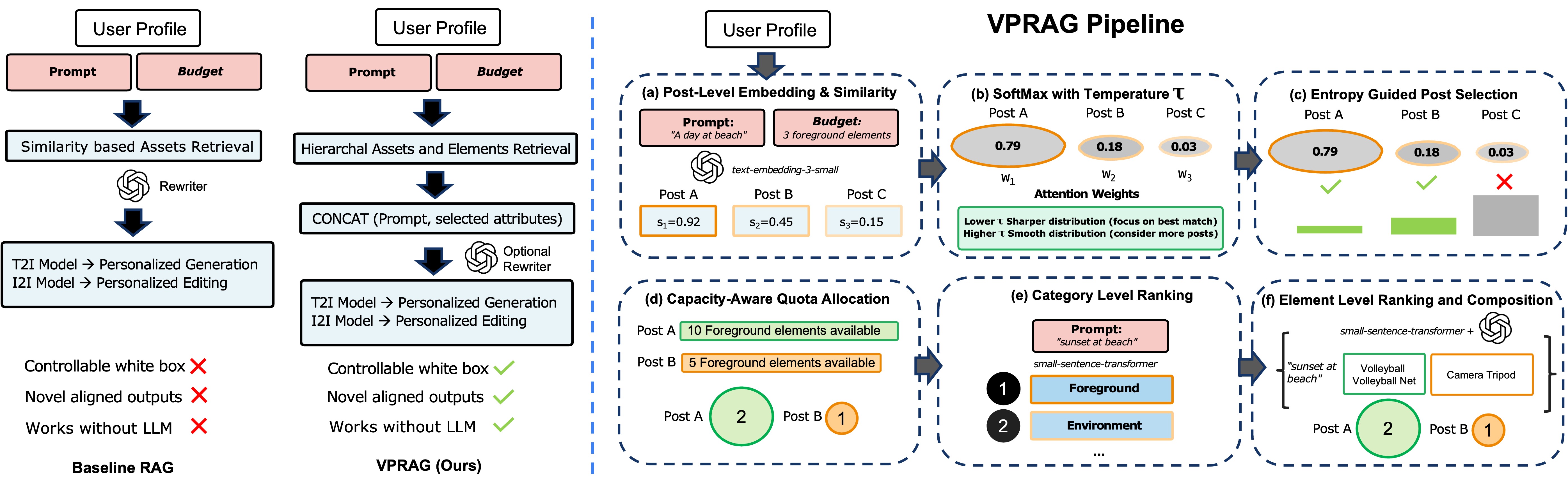
VPRAG: Генерация на Основе Извлечения для Персонализированных Визуальных Элементов
В основе системы VPRAG лежит концепция обогащенной генерации (Retrieval-Augmented Generation), которая позволяет учитывать структурированные данные о предпочтениях пользователя при формировании запросов для генерации изображений. Вместо прямой генерации на основе исходного запроса, система сначала извлекает релевантную информацию из “памяти” пользователя — структурированного набора данных о его визуальном стиле и предпочтениях. Эта извлеченная информация затем используется для переформулировки исходного запроса, делая его более точным и соответствующим индивидуальным особенностям. Таким образом, VPRAG не просто генерирует изображения, а адаптирует процесс генерации к конкретному пользователю, обеспечивая высокую степень персонализации и соответствие визуальной идентичности.
Система VPRAG обеспечивает соответствие генерируемых изображений индивидуальным предпочтениям и визуальной идентичности посредством эффективного поиска релевантной информации. В основе подхода лежит извлечение данных из структурированной памяти, представляющей собой профиль персональных визуальных установок. Этот механизм позволяет VPRAG учитывать специфические вкусы пользователя при создании изображений, гарантируя, что они будут не только технически качественными, но и отражать личные предпочтения в стиле, композиции и цветовой гамме. Таким образом, система выходит за рамки простого создания визуального контента, предлагая персонализированный опыт, основанный на глубоком понимании визуальной идентичности каждого пользователя.
Система VPRAG демонстрирует высокую эффективность в генерации персонализированного визуального контента, что подтверждается стабильно высокими показателями по шкале VPTTscore. Многочисленные эксперименты показали, что VPRAG последовательно превосходит базовые методы, обеспечивая более точное соответствие сгенерированных изображений индивидуальным предпочтениям и визуальной идентичности. Данный результат указывает на значительный прогресс в области создания персонализированных визуальных решений, позволяя системе VPRAG генерировать контент, который не только соответствует заданным параметрам, но и превосходит ожидания пользователей в плане качества и соответствия их стилю.
Исследование демонстрирует высокую степень согласованности между оценками, данными экспертами-людьми, и автоматизированной оценкой, полученной с помощью визуальной языковой модели (VLM). Этот факт подтверждает способность разработанной системы VPRAG генерировать изображения, точно отражающие индивидуальный визуальный стиль. Особенно важно, что система успешно балансирует три ключевых аспекта: соответствие заданному образу (Persona Alignment), точность воспроизведения деталей (Fidelity) и оригинальность создаваемых изображений (Novelty). Такое сочетание факторов позволяет VPRAG создавать не просто персонализированный, но и эстетически привлекательный визуальный контент, соответствующий уникальным предпочтениям каждого пользователя.
Исследование представляет собой элегантный подход к оценке визуальной персонализации, ставя задачу не просто генерировать изображения, а создавать контент, неотличимый от индивидуального стиля конкретного человека. Этот акцент на тонких нюансах и субъективном восприятии визуальной информации требует от моделей глубокого понимания эстетики и способности к адаптации. Как однажды заметил Эндрю Ын: «Самое сложное — это не построить что-то, а понять, что нужно строить». Именно это понимание, стремление к созданию действительно персонализированного опыта, лежит в основе предложенного Visual Personalization Turing Test (VPTT) и лежащего в его основе набора данных VPTT-Bench. Подобный подход позволяет выйти за рамки простого соответствия запросам и перейти к созданию визуального контента, отражающего уникальность каждого пользователя.
Куда Ведет Эта Дорога?
Предложенный тест Тьюринга для визуальной персонализации, несомненно, ставит важный вопрос: достаточно ли просто воспроизвести стилистические особенности, чтобы говорить о настоящем понимании индивидуальности? Кажется, что текущие генеративные модели преуспевают в имитации, но едва ли способны к эмпатии или истинному творчеству, отражающему уникальный внутренний мир. Задача, однако, не ограничивается лишь точностью воспроизведения; настоящим вызовом является создание систем, способных к эволюции визуального стиля, к пониманию его контекста и мотивации.
Неизбежно возникает вопрос о метриках. VPTT-Bench — это лишь первый шаг. Оценка визуальной персонализации требует не только количественных показателей, но и качественного анализа, учитывающего нюансы, которые ускользают от автоматизированных систем. Истинно элегантное решение должно не просто генерировать изображения, но и объяснять их, раскрывая логику и намерения, стоящие за визуальными решениями.
В конечном счете, развитие визуальной персонализации — это не только технологическая задача, но и философский поиск. Мы стремимся создать системы, которые отражают и усиливают человеческую индивидуальность, но не должны забывать, что красота и смысл лежат не в совершенстве имитации, а в неповторимости оригинала. Иначе, мы рискуем построить мир, где все выглядит красиво, но лишено души.
Оригинал статьи: https://arxiv.org/pdf/2601.22680.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
- БиоАгент: Проверка ИИ на прочность в мире геномики
- Иллюзии понимания: Почему нейросети нас обманывают
2026-02-02 21:27