Автор: Денис Аветисян
Исследователи предлагают инновационный метод обучения масштабных нейросетевых моделей, позволяющий достичь высокой точности при использовании низкоточных вычислений.
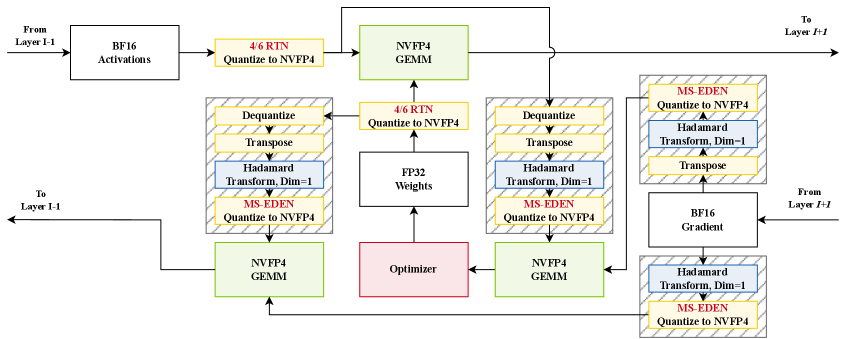
В статье представлена методика Quartet II, использующая формат NVFP4 и улучшенную оценку градиентов для эффективного обучения языковых моделей.
Несмотря на перспективность формата пониженной точности NVFP4 для обучения больших языковых моделей, существующие методы квантования часто приводят к потере точности из-за компромиссов между представлением данных и непредвзятой оценкой градиентов. В статье ‘Quartet II: Accurate LLM Pre-Training in NVFP4 by Improved Unbiased Gradient Estimation’ предложен новый подход, основанный на схеме квантования MS-EDEN и графе вычислений Quartet II, позволяющий значительно повысить точность и скорость обучения моделей в формате NVFP4. Достигнутое более чем двукратное снижение ошибки квантования в сочетании с оптимизированными ядрами для GPU NVIDIA Blackwell обеспечивает ускорение до 4.2x по сравнению с BF16. Сможет ли предложенный подход стать стандартом для эффективного и высокоточного обучения масштабных языковых моделей нового поколения?
Преодолевая Границы Точности: Ограничения Существующей Квантизации
Современные модели глубокого обучения, особенно архитектуры, основанные на трансформерах, предъявляют высокие требования к вычислительной точности для достижения оптимальной производительности. Однако, несмотря на их потенциал, эти модели часто сталкиваются с ограничениями, связанными с вычислительными затратами. Более сложные модели и большие объемы данных требуют значительных ресурсов для обучения и развертывания, что затрудняет их применение на устройствах с ограниченной мощностью или в условиях реального времени. Эта дилемма между точностью и эффективностью представляет собой ключевую проблему в области машинного обучения, стимулируя поиск инновационных методов для снижения вычислительной сложности без существенной потери качества.
Традиционные методы квантизации, такие как округление до ближайшего целого (Round-To-Nearest, RTN), зачастую приводят к существенным ошибкам квантования, что негативно сказывается на конечной производительности моделей глубокого обучения. Это происходит из-за того, что при преобразовании чисел с плавающей точкой в целочисленные форматы, информация теряется, особенно в тех случаях, когда динамический диапазон весов и активаций широк. Потеря точности проявляется в снижении способности модели к обобщению и может приводить к заметному ухудшению метрик качества, таких как точность классификации или BLEU-score в задачах машинного перевода. В результате, несмотря на потенциальные выгоды от снижения вычислительной сложности, простое применение RTN часто не позволяет достичь желаемого баланса между эффективностью и производительностью, требуя разработки более сложных и адаптивных стратегий квантизации.
Воспроизведение полного динамического диапазона весов и активаций является критически важным для сохранения точности нейронных сетей, однако эта задача становится особенно сложной при использовании низкобитовых форматов представления данных. Существующие методы квантизации, стремясь к снижению вычислительных затрат, часто приводят к значительным потерям информации, особенно в тех случаях, когда необходимо представить как очень малые, так и очень большие значения. Это связано с тем, что низкобитовые форматы имеют ограниченное количество дискретных уровней, что затрудняет точное представление широкого диапазона значений без внесения существенной погрешности. В результате, модели могут испытывать снижение производительности, особенно в задачах, требующих высокой чувствительности к небольшим изменениям входных данных, или при обработке данных с большим разбросом значений. Поэтому, разработка эффективных методов квантизации, способных сохранять широкий динамический диапазон при минимальных потерях точности, является ключевой задачей в области оптимизации глубокого обучения.

NVFP4 и Микромасштабирование: Новый Подход к Низкобитной Точности
Формат NVFP4, представляющий собой 4-битный формат чисел с плавающей точкой, является перспективным решением для снижения объема используемой памяти и ускорения обучения глубоких нейронных сетей. Уменьшение разрядности представления чисел позволяет значительно сократить требования к памяти, что особенно важно при работе с большими моделями и на устройствах с ограниченными ресурсами. В контексте обучения глубоких сетей, использование NVFP4 может привести к увеличению скорости вычислений за счет более эффективного использования пропускной способности памяти и снижения энергопотребления. Несмотря на ограниченную точность, NVFP4 в сочетании с техниками, такими как микромасштабирование, демонстрирует потенциал для сохранения приемлемой точности моделей при значительном снижении вычислительных затрат.
Микромасштабирование является ключевой техникой, используемой совместно с форматом NVFP4, позволяющей расширить диапазон представляемых значений при ограниченной разрядности. В стандартных схемах квантования, низкая точность, как в случае 4-битного NVFP4, сильно ограничивает динамический диапазон. Микромасштабирование решает эту проблему путем группировки близких значений и использования специальных коэффициентов масштабирования. Это позволяет представить значения с большей точностью вблизи нуля и эффективно использовать ограниченное количество битов для кодирования информации, минимизируя потери информации, вызванные квантованием, и сохраняя стабильность обучения нейронных сетей. Фактически, микромасштабирование позволяет добиться более высокой точности представления чисел, чем стандартные методы квантования с аналогичной разрядностью.
Микромасштабирование снижает влияние квантования в форматах низкой точности, таких как NVFP4, путем стратегической группировки значений и использования новых коэффициентов масштабирования. Вместо традиционного единого коэффициента масштабирования для всего диапазона значений, микромасштабирование применяет различные коэффициенты к небольшим группам значений. Это позволяет более эффективно представлять как малые, так и большие значения, минимизируя потери точности, вызванные ограниченной шириной битов. Применение разных коэффициентов к локальным группам значений позволяет избежать значительного увеличения ошибки квантования, которая возникала бы при использовании единого коэффициента для всего диапазона, и тем самым повышает общую точность вычислений.
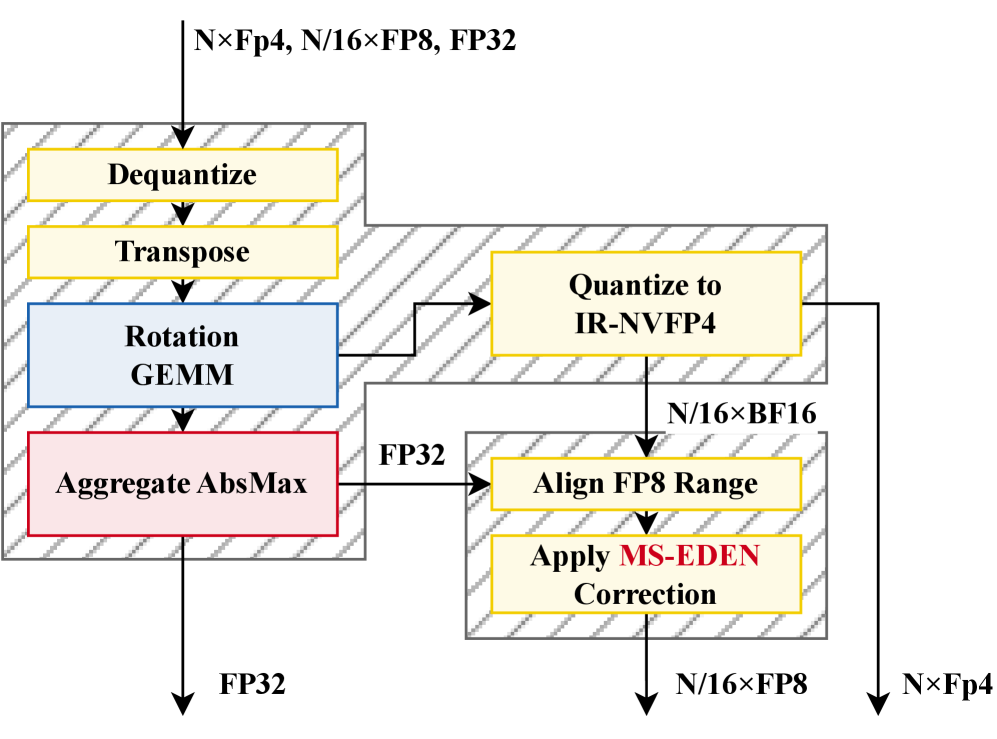
Несмещенная Квантизация с MS-EDEN и Рандомизированными Методами
MS-EDEN — это новый метод квантования, использующий возможности несмещенных оценок для снижения ошибки квантования в микроскопических форматах. В основе MS-EDEN лежит применение статистических методов, позволяющих минимизировать систематическую погрешность, возникающую при представлении данных в пониженной точности. В отличие от традиционных методов квантования, которые могут приводить к смещению статистических характеристик данных, MS-EDEN стремится сохранить их, обеспечивая более точное представление исходной информации при значительном уменьшении объема данных. Это достигается путем применения специализированных алгоритмов, компенсирующих влияние ошибок округления и других неточностей, возникающих в процессе квантования.
Для достижения несмещенной оценки в процессе квантизации применяются методы, такие как рандомизированное преобразование Адамара (RHT) и стохастическое округление. RHT использует случайные матрицы для преобразования данных, что позволяет уменьшить систематическую ошибку, возникающую при квантизации. Стохастическое округление, в свою очередь, добавляет случайный шум к значениям перед округлением, эффективно смещая ошибку округления и предотвращая ее накопление. Комбинация этих техник обеспечивает более точное представление исходных данных после квантизации, минимизируя искажения и повышая надежность полученных результатов.
Вычислительный граф Quartet II, полностью реализованный с использованием формата NVFP4 для линейных слоев, демонстрирует практическое применение методов непредвзятой квантизации. Экспериментальные результаты показывают, что Quartet II обеспечивает ускорение в 4.2 раза по сравнению с обучением в формате BF16. При этом, наблюдается улучшение точности, выраженное в снижении потерь на валидационной выборке на 15-25% по сравнению с существующими методами, использующими формат NVFP4.
Ускорение Предварительного Обучения LLM с Эффективной Квантизацией
Исследования показали, что предварительное обучение больших языковых моделей (LLM) может быть значительно ускорено за счет применения методов эффективной квантизации, таких как MS-EDEN и NVFP4. Эти техники позволяют снизить вычислительную сложность процесса обучения без существенной потери точности модели. Вместо традиционных форматов данных, требующих больше памяти и вычислительных ресурсов, квантизация позволяет представлять параметры модели с меньшей точностью, что приводит к уменьшению потребления памяти и увеличению скорости вычислений. Результаты демонстрируют, что подобный подход не только повышает эффективность обучения, но и открывает возможности для обучения более крупных моделей на доступном оборудовании, расширяя границы возможностей искусственного интеллекта.
Для оценки эффективности 4-битной квантизации в процессе предварительного обучения больших языковых моделей (LLM) используются форматы FP8 и BF16 в качестве базовых показателей. Сравнение с этими форматами позволяет наглядно продемонстрировать значительные выигрыши в производительности, достигаемые за счет снижения точности представления данных. FP8 и BF16, являясь стандартными форматами для обучения LLM, предоставляют отправную точку для измерения ускорения и сохранения точности, в то время как 4-битная квантизация стремится достичь сопоставимых результатов при значительно меньших вычислительных затратах и требованиях к памяти. Такой подход позволяет оптимизировать процесс обучения, делая его более доступным и эффективным для широкого круга исследователей и разработчиков.
Оптимизированные процедуры общего матричного умножения (GEMM), дополненные методом квадратно-блочной квантизации, демонстрируют впечатляющую производительность, достигая скорости обработки в 51 килотокен в секунду при размере микро-пакета в 4. Этот показатель на 245% превышает производительность, обеспечиваемую базовым форматом BF16. Такое значительное ускорение позволяет существенно сократить время предварительного обучения больших языковых моделей, делая процесс более эффективным и доступным.

За Пределами Текущих Границ: Будущее Квантованного Глубокого Обучения
Методики, подобные “Четыре-из-Шести”, представляют собой усовершенствование процесса квантования при прямом проходе (forward-pass quantization) в нейронных сетях. Эти инновации направлены на точное представление весов и активаций с использованием меньшего количества бит, что значительно снижает погрешность квантования — разницу между исходными и квантованными значениями. Снижение этой погрешности критически важно, поскольку она напрямую влияет на точность и производительность модели. В частности, “Четыре-из-Шести” использует специфический подход к выбору уровней квантования, позволяя более эффективно кодировать информацию и минимизировать потери точности, особенно в ситуациях, когда требуется экстремальное сжатие модели для развертывания на устройствах с ограниченными ресурсами. Благодаря подобным оптимизациям, квантованные нейронные сети становятся все более конкурентоспособными по сравнению с полноточными аналогами, открывая новые возможности для применения искусственного интеллекта в различных областях.
Постоянные исследования в области непредвзятых оценок и новых методов квантования открывают возможности для достижения ещё большей точности при использовании низкобитных представлений данных. Суть этих разработок заключается в минимизации погрешностей, возникающих при сокращении разрядности чисел, что позволяет существенно уменьшить объём памяти и вычислительные затраты. Разработка более совершенных оценок позволяет более точно аппроксимировать исходные значения, а инновационные процедуры квантования направлены на создание алгоритмов, способных эффективно работать с ограниченным числом битов без значительной потери производительности. Эти усилия, направленные на повышение эффективности и точности низкобитных вычислений, имеют потенциал для революционного изменения области искусственного интеллекта, позволяя создавать более быстрые, энергоэффективные и доступные модели.
В будущем развитие искусственного интеллекта неразрывно связано с синергией передовых методов квантования и специализированных аппаратных архитектур. Современные нейронные сети требуют огромных вычислительных ресурсов и энергопотребления, что ограничивает их применение в мобильных устройствах и системах с ограниченным энергоснабжением. Квантование, позволяющее снизить точность представления весов и активаций, значительно уменьшает эти требования, однако сопряжено с потерей точности. Новейшие разработки в области квантования, направленные на минимизацию потерь и повышение эффективности, в сочетании с созданием специализированных чипов, оптимизированных для работы с низкоточными данными, открывают путь к созданию более быстрых, энергоэффективных и доступных систем искусственного интеллекта. Такой подход позволит реализовать сложные модели машинного обучения непосредственно на устройствах, расширяя возможности применения ИИ в различных областях, от автономных роботов до персональных ассистентов и систем обработки изображений.
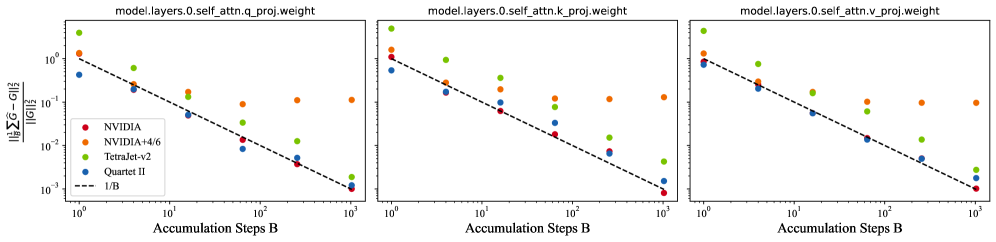
Исследование, представленное в данной работе, демонстрирует, что оптимизация вычислительных графов и схем квантования, таких как Quartet II и MS-EDEN, способна значительно повысить эффективность обучения больших языковых моделей. Подобный подход к управлению вычислительными ресурсами и точностью вычислений напоминает о важности сохранения «памяти системы» даже в процессе её усложнения. Как заметил Андрей Колмогоров: «Математика — это искусство открывать закономерности в хаосе». В контексте обучения LLM, стремление к повышению точности в условиях ограниченных ресурсов — это и есть поиск закономерностей, позволяющих эффективно использовать доступные инструменты. Любое упрощение, будь то снижение точности вычислений или оптимизация графа, неминуемо влечёт за собой определённую цену в будущем, и осознание этого — ключевой аспект успешной разработки.
Что дальше?
Представленная работа, демонстрируя возможности полной пре-тренировки больших языковых моделей в формате NVFP4, не решает, а лишь откладывает неизбежное. Улучшение точности, полученное благодаря Quartet II и схеме MS-EDEN, — это, по сути, замедление энтропии, а не ее отмена. Любое совершенствование, как известно, стареет быстрее, чем ожидается, и вскоре потребует новых оптимизаций, создавая бесконечный цикл. Вопрос не в достижении абсолютной точности, а в том, как долго можно поддерживать её иллюзию.
Очевидным направлением дальнейших исследований представляется не столько повышение точности, сколько разработка методов, позволяющих предсказывать и компенсировать деградацию производительности во времени. Откат — это путешествие назад по стрелке времени, и задача состоит в том, чтобы научиться управлять этим движением, а не пытаться его остановить. Возможно, более перспективным является переход от поиска оптимальных конфигураций к созданию самоадаптирующихся систем, способных к эволюции и регенерации.
В конечном итоге, ценность подобных исследований заключается не в создании более мощных моделей, а в углублении понимания фундаментальных ограничений, присущих любой сложной системе. Все системы стареют — вопрос лишь в том, делают ли они это достойно. Иными словами, не в скорости вычислений, а в изяществе угасания.
Оригинал статьи: https://arxiv.org/pdf/2601.22813.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
- БиоАгент: Проверка ИИ на прочность в мире геномики
- Иллюзии понимания: Почему нейросети нас обманывают
2026-02-02 23:12