Автор: Денис Аветисян
Новое исследование сравнивает эффективность машинного обучения и традиционных методов в предсказании появления новых связей в экономических и финансовых сетях.
Сравнительный анализ алгоритмов предсказания связей, основанных на машинном обучении и методах теории графов.
Прогнозирование недостающих связей в сетях является сложной задачей, требующей учета как статистических закономерностей, так и специфических характеристик узлов. В работе ‘Missing links prediction: comparing machine learning with physics-rooted approaches’ проводится сравнительный анализ методов предсказания недостающих связей, основанных на подходах статистической физики и алгоритмах машинного обучения. Полученные результаты свидетельствуют о том, что производительность «белых ящиков», основанных на физических принципах, сопоставима, а иногда и превосходит, «черные ящики» машинного обучения, при этом обладая большей скоростью вычислений и интерпретируемостью. Не является ли это свидетельством того, что простые, понятные модели могут эффективно конкурировать со сложными алгоритмами, особенно в условиях ограниченного объема данных?
Предсказание связей: вызовы и возможности
Задача предсказания связей, известная как LinkPrediction, играет критически важную роль в самых разнообразных областях. От анализа социальных сетей, где необходимо понимать, какие пользователи могут установить связь в будущем, до финансовых систем, где выявление потенциальных рисков и мошеннических схем требует прогнозирования взаимосвязей между организациями и индивидуумами, эта задача приобретает особую значимость. По сути, способность предсказывать новые связи позволяет оптимизировать взаимодействие, улучшать рекомендации и повышать устойчивость сложных систем, что делает LinkPrediction ключевым инструментом для понимания и управления взаимосвязанным миром.
Традиционные методы прогнозирования связей в сетях часто демонстрируют ограниченную эффективность, особенно при работе со сложными структурами, характеризующимися тонкими и многогранными взаимосвязями. В то время как алгоритмы, основанные на простой близости или общих соседях, могут успешно идентифицировать очевидные связи, они оказываются неспособными уловить скрытые закономерности и неявные отношения, определяющие целостность и функциональность сложных сетей. Эта проблема особенно актуальна в таких областях, как социальные сети, где связи формируются на основе разнообразных факторов, включая общие интересы, географическую близость и исторические взаимодействия, что делает предсказание будущих связей крайне сложной задачей. Неспособность учесть эти нюансы приводит к снижению точности прогнозов и ограничивает практическое применение этих методов в реальных сценариях.
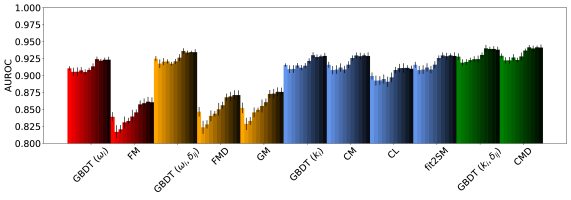
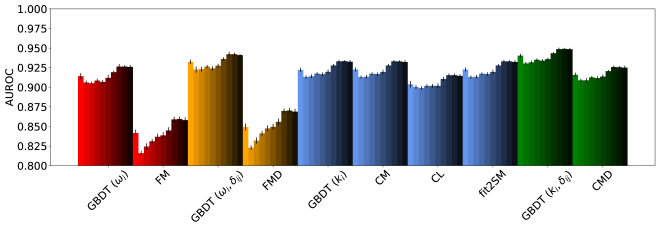
Оценка точности предсказания связей в сложных сетях требует применения надежных метрик. В данном исследовании для проверки эффективности разработанных методов использовались такие показатели, как точность (Accuracy), истинно-положительная доля (TPR) и площадь под ROC-кривой (AUROC). Полученные результаты демонстрируют, что точность варьируется в пределах от 0.7 до 0.9, что указывает на высокую способность модели правильно идентифицировать существующие связи. Истинно-положительная доля показывает диапазон от 0.2 до 0.8, отражая способность модели находить реальные связи среди множества возможных. Значения AUROC в пределах от 0.6 до 0.8 подтверждают приемлемую дискриминационную способность предложенного подхода и его способность отличать истинные связи от случайных, что необходимо для обеспечения надежной работы в различных областях применения.
Эндогенные признаки: взгляд изнутри сети
Эндогенные признаки, такие как степень узла (NodeDegree), предоставляют информацию о непосредственных связях узла и его влиянии в сети. Степень узла представляет собой количество соединений, которые узел имеет с другими узлами в сети. Чем выше степень узла, тем больше непосредственных связей он имеет и, следовательно, потенциально большее влияние на распространение информации или процессов в сети. Анализ степени узла позволяет выявить центральные узлы и оценить их роль в сетевой структуре. Этот показатель является базовым, но важным для понимания сетевой динамики и может использоваться в качестве входных данных для различных сетевых моделей и алгоритмов анализа.
Модели, такие как ConfigurationModel и ChungLuModel, непосредственно используют степень узла (количество связей, приходящихся на узел) в качестве ключевого параметра для предсказания формирования связей в сети. ConfigurationModel генерирует случайные графы, сохраняя заданную последовательность степеней узлов, в то время как ChungLuModel предполагает, что вероятность появления связи между двумя узлами пропорциональна произведению их степеней. Обе модели используют степень узла как индикатор вероятности соединения, позволяя строить сети с заданными характеристиками и исследовать влияние локальной структуры на глобальные свойства графа.
Более сложные модели, такие как DegreeCorrected2StarModel и FitnessInduced2StarModel, улучшают базовые подходы к предсказанию формирования связей, учитывая распределение степеней узлов и параметры пригодности (fitness). Результаты показывают, что производительность этих «белых ящиков» (white-box models) сопоставима с производительностью моделей машинного обучения, особенно при включении в анализ эндогенных признаков, таких как степень узла. Использование распределения степеней и параметров пригодности позволяет более точно моделировать процессы формирования связей в сети, приближая результаты к тем, которые достигаются с помощью более сложных, но менее интерпретируемых методов машинного обучения.

Внешние факторы и продвинутые модели: расширяем горизонты
Внешние факторы, обозначаемые как ExogenousFeatures, представляют собой переменные, не зависящие от исследуемой сети связей, но оказывающие на них влияние. Примерами таких факторов являются валовый внутренний продукт (ВВП) и географическое расстояние между сущностями. ВВП отражает экономическую мощность и потенциал взаимодействия, в то время как географическое расстояние определяет логистические затраты и, следовательно, вероятность установления связи. Использование данных о ВВП и географическом расстоянии позволяет учитывать контекст, в котором формируются связи между объектами, и повышает точность моделирования и прогнозирования.
Гравитационная модель эффективно используется для прогнозирования связей, особенно в торговых сетях, основываясь на двух ключевых параметрах: валовом внутреннем продукте (ВВП) и географической удаленности. Согласно данной модели, интенсивность взаимодействия между двумя сущностями (например, странами) прямо пропорциональна произведению их ВВП и обратно пропорциональна расстоянию между ними. I_{ij} = k \frac{GDP_i \cdot GDP_j}{Distance_{ij}} , где I_{ij} — интенсивность взаимодействия между i и j, k — константа, GDP_i и GDP_j — ВВП i и j, а Distance_{ij} — расстояние между ними. Данный подход позволяет достаточно точно моделировать потоки торговли, инвестиций и миграции, учитывая экономический вес и транспортные издержки между участниками.
Более сложные модели, такие как градиентный бустинг на деревьях решений (GradientBoostingDecisionTree), способны интегрировать как внутренние (EndogenousFeatures), так и внешние (ExogenousFeatures) характеристики, используя обучающий набор данных (TrainingSet) для повышения точности прогнозирования. Проведенное исследование показало, что, несмотря на высокую производительность этих моделей, наблюдаемые показатели по различным метрикам (Accuracy, TPR, AUROC) сопоставимы с результатами, полученными с использованием «белых ящиков» (white-box models). Это указывает на возможность использования более простых, интерпретируемых моделей в качестве надежной альтернативы без существенной потери в качестве прогнозирования.

Реальные данные и проверка моделей: подтверждение эффективности
Для оценки моделей предсказания связей в различных областях используются ценные наборы данных, такие как `WorldTradeWeb` и `ElectronicMarketForInterbankDeposits`. Первый представляет собой сложную сеть международных торговых отношений, позволяющую анализировать динамику связей между странами и компаниями. Второй, охватывающий рынок межбанковских депозитов, предоставляет информацию о кредитных отношениях между финансовыми институтами. Использование этих разнородных данных позволяет проверить универсальность разработанных моделей, выявить их сильные и слабые стороны в различных контекстах и оценить их способность к обобщению. Анализ этих данных демонстрирует, что модели, эффективно работающие в одной области, могут быть успешно адаптированы и применены в другой, что подчеркивает важность разработки гибких и масштабируемых подходов к предсказанию связей.
Применение разработанных моделей к таким наборам данных, как WorldTradeWeb и ElectronicMarketForInterbankDeposits, позволяет провести всестороннюю проверку их работоспособности и оценить способность прогнозировать будущие связи между участниками сети. Этот процесс валидации включает в себя сравнение предсказанных связей с реально возникшими, что дает возможность определить точность и надежность модели в различных экономических контекстах. Успешное предсказание новых связей имеет критическое значение для оптимизации сетевых структур, выявления потенциальных рисков и предотвращения мошеннических действий, поскольку позволяет заранее адаптироваться к изменяющимся условиям и повысить устойчивость системы.
Успешное предсказание связей в сетях имеет существенное значение для управления рисками, выявления мошеннических действий и оптимизации сетевых структур. Исследование показывает, что модели “белого ящика”, основанные на прозрачных алгоритмах, представляют собой надежную альтернативу подходам машинного обучения. В ходе анализа реальных данных, полученных из биржевых и банковских сетей, такие модели продемонстрировали сопоставимую эффективность с передовыми алгоритмами машинного обучения по ключевым показателям, таким как точность Accuracy, истинно-положительная доля TPR и площадь под ROC-кривой AUROC. Это указывает на возможность использования более интерпретируемых и понятных моделей для решения важных практических задач, особенно в областях, требующих высокой степени доверия и контроля.
Исследование, сравнивающее методы предсказания связей в экономических сетях, закономерно показывает, что сложные алгоритмы машинного обучения не всегда превосходят более простые, основанные на теории графов. Порой, кажущаяся элегантность математической модели разбивается о суровую реальность ограниченности данных. Как заметил Григорий Перельман: “Я не думаю, что вообще можно что-то доказать в математике”. Эта фраза, хоть и относится к сфере математических доказательств, удивительно точно отражает суть работы: даже самые сложные модели лишь приближаются к истине, а их предсказательная сила ограничена качеством и объемом исходных данных. Стремление к масштабируемости часто затмевает необходимость в интерпретируемости, но, как показывает практика, понятная и простая модель может оказаться вполне достаточной, особенно когда речь идет о неполных или зашумленных данных.
Что дальше?
Исследование предсказуемости связей в сетях, как и любое другое, выявляет не столько ответы, сколько границы применимости существующих методов. Высокая производительность моделей машинного обучения на экономических и финансовых данных, безусловно, радует, но за ней неизбежно скрывается вопрос: сколько вычислительных ресурсов потрачено ради сомнительного преимущества перед более простыми, интерпретируемыми подходами? Ведь «MVP — это просто способ сказать пользователю: подожди, мы потом исправим». И в данном случае, «потом» может оказаться непозволительно дорогим.
Особое внимание следует уделить проблеме ограниченности данных. В реальных сетях информация всегда неполна, и алгоритмы, демонстрирующие блестящие результаты на синтетических примерах, могут быстро столкнуться с трудностями, когда им приходится работать с «грязными» данными из практики. Потому что если код выглядит идеально — значит, его никто не деплоил. Необходимо сместить фокус с поиска «революционных» алгоритмов на разработку методов, устойчивых к неполноте и шуму.
Вероятно, наиболее перспективным направлением является объединение сильных сторон различных подходов. Простые графовые модели дают понимание структуры сети, а машинное обучение — возможность учитывать сложные нелинейные зависимости. Но прежде чем бросаться в эту сторону, стоит помнить: каждая «революционная» технология завтра станет техдолгом. И, возможно, самый элегантный алгоритм окажется слишком дорогим для поддержания в долгосрочной перспективе.
Оригинал статьи: https://arxiv.org/pdf/2601.23061.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
- БиоАгент: Проверка ИИ на прочность в мире геномики
- Иллюзии понимания: Почему нейросети нас обманывают
2026-02-03 00:47